1.本说明书实施例涉及应用性能管理领域,具体地,涉及基于软硬件一体化架构的全链路监控方法及装置。
背景技术:
2.现有的apm(application performance management,应用性能管理)技术,虽然具备监控功能,例如主动监控、被动监控、全链路监控等,但其主要面向传统的app(application,应用程序)、pc(personal computer,个人计算机)等产品,并不适合ai(artificial intelligence,人工智能)、边缘等场景下的软硬件一体化方案。
3.因此,迫切需要一种合理、可靠的方案,可以实现面向软硬件一体化方案进行全链路监控。
技术实现要素:
4.本说明书实施例提供了基于软硬件一体化架构的全链路监控方法及装置,可以实现面向软硬件一体化方案进行全链路监控。
5.第一方面,本说明书实施例提供了一种基于软硬件一体化架构的全链路监控方法,包括:获取在目标服务请求处理过程中产出的多个性能指标数据,所述多个性能指标数据通过对所述目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集而获得;对于所述多个性能指标数据中的第一指标数据,确定所述第一指标数据在服务维度下所属的问题类别;响应于所述第一指标数据满足预设的多个告警条件之一,生成所述第一指标数据的问题描述信息,并将所述问题描述信息归入目标知识库,所述问题描述信息包括所述第一指标数据和所述问题类别。
6.在一些实施例中,在所述第一指标数据满足所述多个告警条件之一时,还包括:向告警系统发送与所述第一指标数据有关的告警通知消息。
7.在一些实施例中,在所述生成所述第一指标数据的问题描述信息之前,还包括:确定所述第一指标数据在技术维度下所属的技术类别;所述问题描述信息还包括所述技术类别。
8.在一些实施例中,所述技术类别为应用、容器或物理机。
9.在一些实施例中,在所述获取在目标服务请求处理过程中产出的多个性能指标数据之后,还包括:获取所述目标服务请求对应的跟踪标识;所述问题描述信息还包括所述跟踪标识。
10.在一些实施例中,在将所述问题描述信息归入目标知识库之后,还包括:接收数据查看请求,其中包括所述跟踪标识;从所述目标知识库中获取包括所述跟踪标识的问题描述信息;返回所获取的问题描述信息。
11.在一些实施例中,所述若干个服务端应用包括,用于对所述目标服务请求进行处理的第一服务端应用;所述若干个容器包括,所述第一服务端应用所在的第一容器;所述若
干个物理机包括,所述第一容器所在的第一服务器集群,以及所述第一服务器集群对应的网络交换机。
12.在一些实施例中,所述第一服务器集群为ai服务器集群或边缘服务器集群。
13.在一些实施例中,所述若干个服务端应用还包括,所述第一服务端应用在处理所述目标服务请求的过程中经由的第一中间件和/或第一数据库;所述若干个容器还包括,所述第一中间件所在的第二容器,和/或所述第一数据库所在的第三容器;所述若干个物理机还包括,所述第二容器所在的第二服务器集群,和/或所述第三容器所在的第三服务器集群。
14.在一些实施例中,所述软硬件一体化架构被划分为应用服务层、容器层和硬件层,所述若干个服务端应用位于所述应用服务层,所述若干个容器位于所述容器层,所述若干个物理机位于所述硬件层。
15.在一些实施例中,所述应用服务层中还包括第二数据库和第三数据库,所述第二数据库和第三数据库分别部署在所述容器层的容器中,所述第二数据库存放有,在所述目标服务请求处理过程中从所述若干个服务端应用分别采集的第一组性能指标数据,以及从所述若干个容器分别采集的第二组性能指标数据,所述第三数据库存放有,在所述目标服务请求处理过程中从所述若干个物理机分别采集的第三组性能指标数据;以及所述获取在目标服务请求处理过程中产出的多个性能指标数据,包括:从所述第二数据库获取所述第一组性能指标数据和所述第二组性能指标数据,以及从所述第三数据库获取所述第三组性能指标数据。
16.在一些实施例中,所述若干个服务端应用、所述若干个容器和所述若干个物理机分别部署有代理程序,所述第一组性能指标数据、所述第二组性能指标数据和所述第三组性能指标数据,由相应的代理程序上传至相应的数据库。
17.第二方面,本说明书实施例提供了一种基于软硬件一体化架构的全链路监控装置,包括:获取单元,被配置成获取在目标服务请求处理过程中产出的多个性能指标数据,所述多个性能指标数据通过对所述目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集而获得;分类单元,被配置成对于所述多个性能指标数据中的第一指标数据,确定所述第一指标数据在服务维度下所属的问题类别;处理单元,被配置成响应于所述第一指标数据满足预设的多个告警条件之一,生成所述第一指标数据的问题描述信息,并将所述问题描述信息归入目标知识库,所述问题描述信息包括所述第一指标数据和所述问题类别。
18.在一些实施例中,所述软硬件一体化架构被划分为应用服务层、容器层和硬件层,所述若干个服务端应用位于所述应用服务层,所述若干个容器位于所述容器层,所述若干个物理机位于所述硬件层。
19.第三方面,本说明书实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其中,当该计算机程序在计算机中执行时,令该计算机执行如第一方面中任一实现方式描述的方法。
20.第四方面,本说明书实施例提供了一种计算设备,包括存储器和处理器,其中,该存储器中存储有可执行代码,该处理器执行该可执行代码时,实现如第一方面中任一实现方式描述的方法。
21.第五方面,本说明书实施例提供了一种计算机程序,其中,当该计算机程序在计算机中执行时,令该计算机执行如第一方面中任一实现方式描述的方法。
22.本说明书的上述实施例提供了基于软硬件一体化架构的全链路监控方法及装置。对于该软硬件一体化架构下的目标服务请求,例如ai计算请求或数据查看请求等,可以获取在目标服务请求处理过程中产出的多个性能指标数据,该多个性能指标数据可以通过对目标服务请求在该软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集而获得。而后,对于该多个性能指标数据中的第一指标数据,可以确定第一指标数据在服务维度下所属的问题类别。然后,可以响应于第一指标数据满足预设的多个告警条件之一,生成第一指标数据的问题描述信息,并将问题描述信息归入目标知识库,问题描述信息包括第一指标数据和该问题类别。由此,可以实现面向软硬件一体化方案进行全链路监控。
23.需要说明,问题描述信息中的问题类别可以视为问题或故障,该问题描述信息中的第一指标数据可以视为导致该问题或故障的原因。通过将问题描述信息归入目标知识库,可以方便用户通过查看目标知识库中的问题描述信息,快速了解应用(例如用于对目标服务请求进行处理的第一服务端应用)存在的问题,问题的产生原因,以及性能瓶颈等。
附图说明
24.为了更清楚地说明本说明书披露的多个实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书披露的多个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
25.图1是软硬件一体化架构的一个示意图;
26.图2是本说明书的一些实施例可以应用于其中的一个示例性系统架构图;
27.图3是基于软硬件一体化架构的全链路监控方法的一个实施例的示意图;
28.图4是基于软硬件一体化架构的全链路监控装置的一个结构示意图。
具体实施方式
29.下面结合附图和实施例对本说明书作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。所描述的实施例仅仅是本说明书一部分实施例,而不是全部的实施例。基于本说明书中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
30.需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。在不冲突的情况下,本说明书中的实施例及实施例中的特征可以相互组合。另外,本说明书实施例中的“第一”、“第二”、“第三”等词,仅用于信息区分,不起任何限定作用。
31.如前所述,现有的apm技术虽然具备监控功能,但其主要面向传统的app、pc等产品,并不适合ai、边缘等场景下的软硬件一体化方案。
32.基于此,本说明书的一些实施例提供了基于软硬件一体化架构的全链路监控方法,通过该方法,可以实现面向软硬件一体化方案进行全链路监控。
33.具体地,图1示出了本说明书实施例提供的全链路监控方法所面向的软硬件一体
化架构的一个示意图。
34.实践中,软硬件一体化架构可以包括多个物理机,该多个物理机中的至少部分物理机上可以搭建有容器,该容器中可以部署有服务端应用。任意的服务端应用可以基于java、go或node.js等而开发。换而言之,任意的服务端应用可以是java应用、go应用或node.js应用等。
35.进一步地,如图1所示,软硬件一体化架构可以被划分成多个层,例如硬件层、容器层和应用服务层。其中,上述多个物理机可以位于硬件层,上述至少部分物理机上搭建的容器可以位于容器层,该容器中部署的服务端应用可以位于应用服务层。
36.上述多个物理机例如可以包括若干个服务器集群。该若干个服务器集群例如可以包括ai场景中的服务器集群(可简称为ai服务器集群),边缘场景中的服务器集群(可简称为边缘服务器集群),以及除ai服务器集群和边缘服务器集群以外的其他服务器集群。该其他服务器集群例如可以称为普通服务器集群。
37.通常,边缘服务器集群例如可以由多个边缘设备组成。该多个边缘设备例如可以为多个能联网的摄像头,或者多个边缘盒子等,在此不做具体限定。
38.上述至少部分物理机例如可以是上述若干个服务器集群。上述若干个服务器集群上可以搭建有容器,例如基于k8s(kubernetes)的容器。实践中,k8s是开源的容器编排引擎,它可以支持自动化部署、大规模可伸缩、应用容器化管理。
39.作为示例,ai服务器集群上搭建的一个或多个容器中,可以部署有ai场景下用于提供ai服务的服务端应用,该服务端应用可以称为ai服务端应用。边缘服务器集群上搭建的一个或多个容器中,可以部署有边缘场景下用于提供边缘服务的服务端应用,该服务端应用可以称为边缘服务端应用。普通服务器集群上搭建的一个或多个容器中,可以部署有作为中间件的服务端应用,和/或部署有作为数据库的服务端应用等。需要说明,ai服务端应用和边缘服务端应用可以统称为业务服务端应用。
40.中间件通常具有数据传输、数据搜索、数据可视化和/或数据分析等功能。以数据传输为例,中间件可以接收一方(例如某一业务服务端应用或其他中间件等)发送的数据,并将该数据发送给另一方(例如数据库等);或者,中间件也可以基于数据获取请求,从一方(例如数据库等)获取数据,并将该数据返回给该数据获取请求的发送方。
41.实践中,应用服务层内可以有多种中间件,例如kafka消息中间件,logstash中间件,apm server中间件,grafana中间件,kibana中间件,等等。kafka通常是一种高吞吐量的分布式发布订阅消息系统。logstash通常是一个开源数据收集引擎,具有实时管道功能,能动态地将来自不同数据源的数据统一起来,并将数据标准化到指定的位置。apm server能将所接收的数据传输至指定的位置。grafana通常是开源的功能丰富的数据可视化平台,能用于时序数据的可视化。kibana可以用于对日志进行高效的搜索、可视化、分析等各种操作。
42.另外,应用服务层内也可以有多种数据库,例如关系型数据库(如mysql数据库),非关系型数据库(如es数据库),时间序列数据库(如基于prometheus的数据库,可简称为prometheus数据库)。实践中,es(elasticsearch)一般是分布式、高扩展、高实时的搜索与数据分析引擎。prometheus是一套开源的监控&报警&时间序列数据库的组合。
43.由于kafka、logstash、apm server、grafana、kibana、mysql、es和prometheus是现
有的公知技术,在此不再过多赘述。
44.可选地,上述多个物理机还可以包括,上述若干个服务器集群分别对应的网络交换机,例如rdma(remote direct memory access,远程直接数据存取)网络交换机。
45.下面,结合图2,进一步描述适用于本说明书实施例的示例性系统架构图。如图2所示,系统架构可以包括如前所述的软硬件一体化架构,跟踪系统(也可称为跟踪中心或tracing中心),以及目标知识库。
46.需要说明,为了便于清晰的描述监控过程,在图2中仅示出了简化版的软硬件一体化架构。对于该架构的具体描述,可参看前文中的相关说明。
47.实践中,可以预先在软硬件一体化架构中进行探针埋点,例如在软硬件一体化架构中的服务端应用、容器和物理机内进行探针埋点。可以理解的是,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,可以预先在软硬件一体化架构的多个层中进行探针埋点,例如在硬件层、容器层和应用服务层中均进行探针埋点。
48.具体地,在硬件层中进行探针埋点时,可以在硬件层中的部分或全部物理机中进行探针埋点,以对物理机进行指标采集。例如,通过对服务器集群进行探针埋点,可以采集服务器集群的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括,服务器集群的cpu(central processing unit,中央处理器)利用率,和/或服务器集群的gpu(graphics processing unit,图形处理器)利用率,等等。通过对rdma网络交换机进行探针埋点,可以采集网络交换机的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括rdma网络吞吐量等。
49.在容器层中进行探针埋点时,可以在容器层中的部分或全部容器中进行探针埋点,以对容器进行指标采集。例如,通过对容器进行探针埋点,可以采集容器的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括,容器利用率,容器的内存利用率,容器的cpu利用率,和/或容器的gpu利用率,等等。
50.在应用服务层中进行探针埋点时,可以在应用服务层中的部分或全部服务端应用中进行探针埋点,以对服务端应用进行指标采集。例如,通过对服务端应用进行探针埋点,可以采集服务端应用的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括接口耗时等。
51.应该理解,以上列举的各个性能指标仅是示例性指标。在实际应用中,可根据实际需求设定所要采集的性能指标,在此不做具体限定。
52.另外,进行探针埋点的服务端应用、容器和物理机内,可以部署有相应的代理程序。可以理解的是,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,在进行探针埋点的各个层中,可以部署有相应的代理程序。代理程序可以用于收集性能指标数据,并将性能指标数据上传至相应的数据库。
53.具体地,在硬件层中,进行探针埋点的物理机内,例如进行探针埋点的网络交换机和服务器集群(如图2中示出的ai服务器集群)内,可以部署有oneagent、rdmaexporter或nodeexporter等代理程序。在容器层中,进行探针埋点的容器内,可以部署有filebeat等代理程序。在应用服务层中,进行探针埋点的服务端应用内,例如进行探针埋点的业务服务端应用、中间件和数据库内,可以部署有apm agent等代理程序。需要指出,此处列出的各种代理程序均为目前公知的程序,在此不再赘述。
54.需要说明,图2中仅示出了oneagent、filebeat和apm agent这三种代理程序。应该理解,可以根据实际需求,将这三种代理程序替换成其他的代理程序,在此不做具体限定。
55.实践中,软硬件一体化架构中的业务服务端应用,例如图2中示出的ai服务端应用,可以接收用户发送的目标服务请求,例如ai计算请求,或数据查看请求等。目标服务请求的处理过程,一般会涉及软硬件一体化架构中的若干个服务端应用,若干个容器,以及若干个物理机。具体地,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,目标服务请求的处理过程,一般会涉及应用服务层中的若干个服务端应用,容器层中的若干个容器,以及硬件层中的若干个物理机。该若干个服务端应用可以包括但不限于该业务服务端应用,该若干个容器可以包括但不限于该业务服务端应用所在的容器(下文中称为第一容器),该若干个物理机可以包括但不限于第一容器所在的服务器集群(下文中称为第一服务器集群)。
56.在该业务服务端应用、第一容器和第一服务器集群均进行探针埋点的情况下,在目标服务请求处理过程中,可以对该业务服务端应用、第一容器和第一服务器集群进行指标采集。
57.以该业务服务端应用为ai服务端应用,第一服务器集群为ai服务器集群为例,如图2所示,ai服务端应用中的代理程序apm agent,可以收集在目标服务请求处理过程中针对ai服务端应用采集的性能指标数据,并将性能指标数据上传至相应的数据库。具体地,apm agent可以经由若干个中间件,将性能指标数据上传至相应的数据库。其中,该若干个中间件例如可以包括apm server中间件。该数据库可以为非关系型数据库,例如es数据库。
58.ai服务端应用所在的容器中的代理程序filebeat,可以收集在目标服务请求处理过程中针对该容器采集的性能指标数据,并将性能指标数据上传至相应的数据库。具体地,filebeat可以经由若干个中间件,将性能指标数据上传至相应的数据库。其中,该若干个中间件例如可以包括kafka消息中间件,logstash中间件。该数据库可以为非关系型数据库,例如上述es数据库。
59.ai服务器集群中的代理程序oneagent,可以收集在目标服务请求处理过程中针对ai服务器集群采集的性能指标数据,并将性能指标数据上传至相应的数据库。该数据库可以为时间序列数据库,例如prometheus数据库。
60.后续,跟踪系统可以获取在目标服务请求处理过程中产出的多个性能指标数据。具体地,可以从上述es数据库和上述prometheus数据库中,获取该多个性能指标数据中的性能指标数据。
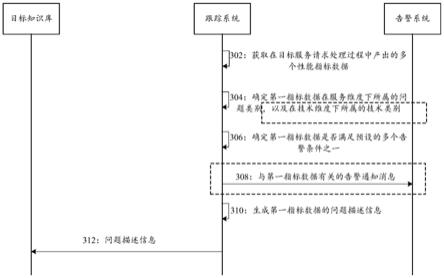
61.接着,跟踪系统可以对上述多个性能指标数据分别进行分类,例如,确定上述多个性能指标数据中的性能指标数据所属的问题类别。实践中,跟踪系统中可以预设有多个问题类别,该多个问题类别例如可以包括,正常,接口耗时久,接口调用异常,函数方法出现循环引用,等等。跟踪系统可以在预设的该多个问题类别中,确定性能指标数据所属的问题类别。
62.再接着,对于上述多个性能指标数据中存在异常情况的至少部分性能指标数据,例如所属的问题类别非正常的至少部分性能指标数据,跟踪系统可以生成该至少部分性能指标数据各自的问题描述信息,并将问题描述信息归入目标知识库。其中,问题描述信息可以包括其对应的性能指标数据,以及该性能指标数据所属的问题类别。目标知识库例如可
以是用于对目标服务请求进行处理的第一服务端应用对应的知识库。
63.在一些实施例中,系统架构还可以包括告警系统(也可以称为告警中心),跟踪系统可以向告警系统发送与上述至少部分性能指标数据分别有关的告警通知消息,以便告警系统周知用户应用出现的问题。
64.通过以上描述的监控过程,可以使得跟踪系统面向软硬件一体化架构进行全链路监控,例如可以对服务端应用、容器和物理机均进行监控,具体地,可以从上层的应用服务层,到中间的容器层,再到底层的硬件层均进行监控。由此,可以通过全链路的视角将用户想要的数据收集起来,最终可以快速帮助用户定位和分析问题。
65.下面,结合具体的实施例,描述上述方法的具体实施步骤。
66.参看图3,其示出了基于软硬件一体化架构的全链路监控方法的一个实施例的示意图。该方法包括以下步骤:
67.步骤302,跟踪系统获取在目标服务请求处理过程中产出的多个性能指标数据,该多个性能指标数据通过对目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集而获得;
68.步骤304,跟踪系统对于多个性能指标数据中的第一指标数据,确定第一指标数据在服务维度下所属的问题类别;
69.步骤306,跟踪系统确定第一指标数据是否满足预设的多个告警条件之一;
70.步骤310,跟踪系统响应于第一指标数据满足预设的多个告警条件之一,生成第一指标数据的问题描述信息,问题描述信息包括第一指标数据,以及第一指标数据所属的问题类别;
71.步骤312,跟踪系统将问题描述信息归入目标知识库。
72.在本实施例中,软硬件一体化架构可以包括多个物理机,该多个物理机中的至少部分物理机上可以搭建有容器,该容器中可以部署有服务端应用。具体地,软硬件一体化架构可以被划分成多个层,例如硬件层、容器层和应用服务层。该多个物理机可以位于硬件层,该至少部分物理机上搭建的容器可以位于容器层,该容器中部署的服务端应用可以位于应用服务层。
73.上述多个物理机例如可以包括若干个服务器集群。该若干个服务器集群例如可以包括ai服务器集群,边缘服务器集群,普通服务器集群。进一步地,上述多个物理机还可以包括,该若干个服务器集群分别对应的网络交换机,例如rdma网络交换机。
74.上述至少部分物理机可以为上述若干个服务器集群。上述若干个服务器集群上可以搭建有容器,例如基于k8s(kubernetes)的容器。作为示例,ai服务器集群上搭建的一个或多个容器中,可以部署有ai服务端应用。边缘服务器集群上搭建的一个或多个容器中,可以部署有边缘服务端应用。普通服务器集群上搭建的一个或多个容器中,可以部署有作为中间件的服务端应用,和/或部署有作为数据库的服务端应用。需要说明,ai服务端应用和边缘服务端应用可以统称为业务服务端应用。
75.另外,软硬件一体化架构中可以已进行探针埋点。具体地,软硬件一体化架构中的服务端应用、容器和物理机内可以已进行探针埋点。可以理解的是,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,软硬件一体化架构的多个层中,例如硬件层、容器层和应用服务层中,可以均已进行探针埋点。
76.应该理解,进行探针埋点的目的是,在目标服务请求处理过程中,采集目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机的某些性能指标的性能指标数据。进一步地,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,进行探针埋点的目的是,在目标服务请求处理过程中,采集目标服务请求涉及的位于应用服务层的若干个服务端应用,位于容器层的若干个容器,以及位于硬件层的若干个物理机的某些性能指标的性能指标数据。
77.关于软硬件一体化架构更为详细的解释,可参看前文中的相关说明,在此不再赘述。
78.下面,对以上各步骤做进一步说明。
79.在步骤302中,跟踪系统(例如图1中示出的跟踪系统)可以获取在目标服务请求处理过程中产出的多个性能指标数据,该多个性能指标数据可以通过对目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集而获得。
80.需要说明,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,该若干个服务端应用可以位于应用服务层,该若干个容器可以位于容器层,该若干个物理机可以位于硬件层。基于此,上述多个性能指标数据可以通过对目标服务请求涉及的位于应用服务层的若干个服务端应用,位于容器层的若干个容器,以及位于硬件层的若干个物理机分别进行指标采集而获得。
81.其中,目标服务请求例如可以是ai计算请求或数据查看请求等,在此不做具体限定。另外,软硬件一体化架构中,例如软硬件一体化架构的应用服务层中,存在目标服务请求所属的业务对应的业务服务端应用。可以理解的是,该业务服务端应用是用于对目标服务请求进行处理的服务端应用。为了便于描述,下文中将该业务服务端应用称为第一服务端应用。
82.上述若干个服务端应用例如可以包括第一服务端应用,上述若干个容器例如可以包括第一服务端应用所在的第一容器,上述若干个物理机例如可以包括第一容器所在的第一服务器集群。其中,第一服务器集群例如可以为ai服务器集群或边缘服务器集群等。
83.上述多个性能指标数据可以包括,在目标服务请求处理过程中,从第一服务端应用中采集的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括接口耗时等;从第一容器中采集的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括,容器利用率,容器的内存利用率,容器的cpu利用率,和/或容器的gpu利用率,等等;从第一服务器集群中采集的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括,服务器集群的cpu利用率,和/或服务器集群的gpu利用率,等等。
84.进一步地,上述若干个物理机还可以包括,第一服务器集群对应的网络交换机,例如rdma网络交换机。基于此,上述多个性能指标数据还可以包括,在目标服务请求处理过程中,从该网络交换机中采集的若干个性能指标的性能指标数据,该若干个性能指标例如可以包括网络吞吐量等。
85.在一些实施例中,若目标服务请求处理过程中涉及对中间件和/或数据库的调用,则上述若干个服务端应用还可以包括,该中间件和/或数据库。为了便于描述,下文中将该中间件称为第一中间件,将该数据库称为第一数据库。换而言之,上述若干个服务端应用还
可以包括,第一服务端应用在处理目标服务请求的过程中经由的第一中间件和/或第一数据库。其中,第一中间件可以是用于数据传输、数据搜索和/或数据分析等的中间件。第一数据库例如可以是mysql数据库或es数据库等。
86.可选地,上述若干个容器还可以包括,第一中间件所在的第二容器,和/或第一数据库所在的第三容器。可选地,上述若干个物理机还可以包括,第二容器所在的第二服务器集群,和/或第三容器所在的第三服务器集群。
87.通常,跟踪系统可以从指定的数据库获取上述多个性能指标数据。作为示例,该指定的数据库可以包含在软硬件一体化架构中。进一步地,该指定的数据库可以包括软硬件一体化架构中的第二数据库和第三数据库。更进一步地,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,该指定的数据库例如可以包括位于应用服务层的第二数据库(例如图2中示出的es数据库)和第三数据库(例如图2中示出的prometheus数据库),该第二数据库和第三数据库可以分别部署在容器层的容器中。
88.第二数据库可以存放有,在目标服务请求处理过程中从上述若干个服务端应用分别采集的若干个性能指标数据(下文中称为第一组性能指标数据),以及从上述若干个容器分别采集的若干个性能指标数据(下文中称为第二组性能指标数据)。第三数据库可以存放有,在目标服务请求处理过程中从上述若干个物理机分别采集的若干个性能指标数据(下文中称为第三组性能指标数据)。
89.基于此,跟踪系统可以从第二数据库获取第一组性能指标数据和第二组性能指标数据,以及从第三数据库获取第三组性能指标数据。
90.在一些实施例中,上述若干个服务端应用、上述若干个容器和上述若干个物理机可以分别部署有代理程序,第一组性能指标数据、第二组性能指标数据和第三组性能指标数据,可以由相应的代理程序上传至相应的数据库。
91.作为示例,上述若干个服务端应用可以分别部署有apm agent等代理程序,上述若干个服务端应用可以由各自的代理程序,将各自的性能指标数据上传至第二数据库。上述若干个容器可以分别部署有filebeat等代理程序,上述若干个容器可以由各自的代理程序,将各自的性能指标数据上传至第二数据库。上述若干个物理机可以分别部署有oneagent、rdmaexporter或nodeexporter等代理程序,上述若干个物理机可以由各自的代理程序,将各自的性能指标数据上传至第三数据库。
92.在一些实施例中,应用服务层可以细分为应用层,以及中间件和数据库层。其中,中间件和数据库层,可以简称为中间件层。软硬件一体化架构中的业务服务端应用可以位于应用层,软硬件一体化架构中的中间件和数据库可以位于中间件层。
93.作为示例,应用层可以引入apm agent代理程序,也即应用层中的业务服务端应用中可以部署有apm agent代理程序,apm agent代理程序可以将收集的性能指标数据上传至第二数据库。中间件层中可以引入telegraf代理程序,也即中间件层中的中间件和/或数据库中可以部署有telegraf代理程序,telegraf代理程序可以将收集的性能指标数据上传至第三数据库。实践中,telegraf是一个插件驱动的服务器代理,用于收集和报告指标。
94.需要说明,代理程序可以直接或经由若干个中间件将性能指标数据上传至相应的数据库。例如,如图2中所示,apm agent代理程序可以经由apm server中间件,将性能指标数据上传至es数据库。filebeat代理程序可以依次经由kafka消息中间件、logstash中间
件,将性能指标数据上传至es数据库。oneagent代理程序可以直接将性能指标数据上传至prometheus数据库。
95.可选地,若在中间件和/或数据库中部署telegraf代理程序,telegraf代理程序例如可以直接将性能指标数据上传至prometheus数据库。
96.为了便于描述,可以将上述多个性能指标数据中的性能指标数据称为第一指标数据。接着,在步骤304中,跟踪系统可以确定第一指标数据在服务维度(也可称为业务维度)下所属的问题类别。
97.具体地,服务维度下可以预设有多个问题类别,该多个问题类别例如可以包括,正常,接口耗时久,接口调用异常,函数方法出现循环引用,等等。另外,该多个问题类别可以分别对应分类规则。对于该多个问题类别中的问题类别,跟踪系统可以根据该问题类别对应的分类规则,确定第一指标数据是否归属于该问题类别。
98.需要指出,第一指标数据可以归属于一个或多个问题类别。通常,对于非正常的问题类别,其可以视为问题或故障,归属于该问题类别的性能指标数据可以视为导致该问题或故障的原因。以故障为例,当第一指标数据归属于多个问题类别时,该多个问题类别可以示出,由该第一指标数据示出的原因导致的直接故障和间接故障。该间接故障可以是由该直接故障导致的故障。
99.在一些实施例中,为了便于技术人员定位问题,在步骤304中,还可以确定第一指标数据在技术维度下所属的技术类别。
100.在一个例子中,技术类别可以根据如前所述的多个层而划分。基于此,单个技术类别可以为应用服务层、容器层或硬件层。例如,当第一指标数据来源于应用服务层时,第一指标数据所属的技术类别可以为应用服务层。当第一指标数据来源于容器层时,第一指标数据所属的技术类别可以为容器层。当第一指标数据来源于硬件层时,第一指标数据所属的技术类别可以为硬件层。进一步地,当应用服务层细分为应用层和中间件层时,单个技术类别可以为应用层、中间件层、容器层或硬件层。
101.在另一个例子中,技术类别可以根据性能指标数据的具体来源(例如服务端应用、容器或物理机)而划分。基于此,单个技术类别例如可以为应用、容器或物理机。或者,单个技术类别例如可以为业务服务端应用、中间件、数据库、容器或物理机。
102.应该理解,问题类别和技术类别可根据实际需求设定,在此不做具体限定。
103.接着,为了便于将某些异常的性能指标数据记录下来,以供实时查看,跟踪系统可以执行步骤306,确定第一指标数据是否满足预设的多个告警条件之一。在第一指标数据满足该多个告警条件之一时,跟踪系统可以执行步骤310,生成第一指标数据的问题描述信息,而后执行步骤312,将问题描述信息归入目标知识库。其中,目标知识库例如可以是用于对目标服务请求进行处理的第一服务端应用对应的知识库。
104.实践中,当性能指标数据满足某个告警条件时,可以表示该性能指标数据是异常且需要特别关注的数据,需要将该性能指标数据记录下来。
105.上述多个告警条件可以基于如前所述的性能指标而设定。例如,上述多个告警条件可以包括,cpu利用率大于第一阈值,gpu利用率大于第二阈值,接口耗时大于耗时阈值,网络吞吐量低于吞吐量阈值,等等。应该理解,上述多个告警条件的具体内容,可根据实际需求设定,在此不做具体限定。
106.问题描述信息可以包括其对应的第一指标数据,以及该第一指标数据所属的问题类别。进一步地,若在步骤304中还确定第一指标数据所属的技术类别,则问题描述信息还可以包括第一指标数据所属的技术类别。
107.以第一指标数据为ai服务器集群的cpu利用率为85%,上述多个告警条件包括cpu利用率大于80%,第一指标数据所属的问题类别包括cpu超负载为例,显然,第一指标数据满足cpu利用率大于80%这一告警条件,可以生成第一指标数据的问题描述信息“由于ai服务器集群的cpu利用率为85%,导致cpu超负载”。
108.在一些实施例中,为了便于用户快速了解整个链路存在的问题,在步骤302之后,以及在步骤310之前,跟踪系统还可以获取目标服务请求对应的跟踪标识(可称为traceid)。基于此,问题描述信息还可以包括该跟踪标识。
109.该跟踪标识可以根据目标服务请求的调用链中的各个调用对象(例如如前所述的第一服务端应用、第一容器、第一服务器集群等)的标识(可称为spanid)而生成,并且该跟踪标识全局唯一。具体地,该跟踪标识可以是第一服务端应用生成的,跟踪系统例如可以从第一服务端应用获取该跟踪标识。
110.后续,跟踪系统例如可以接收包括该跟踪标识的数据查看请求,并从目标知识库中获取包括该跟踪标识的问题描述信息,以及返回所获取的问题描述信息。由此,发送该数据查看请求的用户,便可以看到整个链路下的问题描述信息,并基于查看到的问题描述信息,快速了解到整个链路存在的问题。此外,还能快速了解到该问题的产生原因,以及快速了解到应用的性能瓶颈。
111.在一些实施例中,为了便于告警系统能即时周知用户应用出现的问题,在执行步骤306之后,或者在执行步骤310之前或之时,跟踪系统可以执行步骤308,响应于第一指标数据满足上述多个告警条件之一,向告警系统发送与第一指标数据有关的告警通知消息。
112.作为示例,告警通知消息可以根据第一指标数据所属的问题类别而生成。继续以第一指标数据为ai服务器集群的cpu利用率为85%,上述多个告警条件包括cpu利用率大于80%,第一指标数据所属的问题类别包括cpu超负载为例,显然,第一指标数据满足cpu利用率大于80%这一告警条件,可以向告警系统发送与第一指标数据有关的告警通知消息“ai服务器集群的cpu超负载”。
113.应该理解,问题描述信息和告警通知消息均可以根据预设的生成规则而生成,该生成规则可根据实际需求设定,在此不做具体限定。
114.图3对应的实施例提供的基于软硬件一体化架构的全链路监控方法,通过预先对软硬件一体化架构进行探针埋点,可以在目标服务请求处理过程中,对目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集,例如在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,对该目标服务请求涉及的位于应用服务层的若干个服务端应用,位于容器层的若干个容器,以及位于硬件层的若干个物理机分别进行性能指标采集。而后,可以对采集所得的多个性能指标数据分别进行分类,以及在性能指标数据存在异常时,可以将性能指标数据和其所属的类别形成问题描述信息归入目标知识库,便于用户通过查看目标知识库中的问题描述信息,快速了解应用存在的问题,问题的产生原因,以及性能瓶颈等。由此,可以实现面向软硬件一体化方案进行全链路监控。
115.另外,本说明书实施例提供的全链路监控方案,是一项底层依赖技术,能对上层的多种产品,例如ai训练和推理相关产品,虚拟化开放计算平台,存储超融合相关产品,等等,起到很好的支撑作用,并且能够通过全链路的视角将用户想要的性能指标数据收集起来,最终可以快速帮用户定位和分析问题。
116.此外,如前所述的各种性能指标,是面向ai、边缘等场景的用户比较关注、重视的指标,本说明书实施例提供的全链路监控方案,通过结合应用服务层、容器层和硬件层,实现对该各种性能指标的采集,并基于采集到的性能指标数据进行分类等处理,可以很好的实现在ai、边缘等场景中深度定制客户需求。
117.进一步参考图4,本说明书提供了一种基于软硬件一体化架构的全链路监控装置的一个实施例,该装置可以应用于跟踪系统(例如图2中示出的跟踪系统)。
118.如图4所示,本实施例的基于软硬件一体化架构的全链路监控装置400包括:获取单元401、分类单元402和处理单元403。其中,获取单元401被配置成获取在目标服务请求处理过程中产出的多个性能指标数据,该多个性能指标数据通过对目标服务请求在软硬件一体化架构中涉及的若干个服务端应用,若干个容器,以及若干个物理机分别进行指标采集而获得;分类单元402被配置成对于该多个性能指标数据中的第一指标数据,确定第一指标数据在服务维度下所属的问题类别;处理单元403被配置成响应于第一指标数据满足预设的多个告警条件之一,生成第一指标数据的问题描述信息,并将问题描述信息归入目标知识库,问题描述信息包括第一指标数据和该问题类别。
119.在一些实施例中,软硬件一体化架构可以被划分为应用服务层、容器层和硬件层,上述若干个服务端应用可以位于应用服务层,上述若干个容器可以位于容器层,上述若干个物理机可以位于硬件层。
120.在一些实施例中,处理单元403还可以被配置成:在第一指标数据满足上述多个告警条件之一时,向告警系统发送与第一指标数据有关的告警通知消息。
121.在一些实施例中,分类单元402还可以被配置成:确定第一指标数据在技术维度下所属的技术类别;上述问题描述信息还可以包括该技术类别。
122.在一些实施例中,上述技术类别可以为应用服务层、容器层或硬件层。
123.在一些实施例中,上述技术类别可以为应用、容器或物理机。在一些实施例中,获取单元401还可以被配置成:获取目标服务请求对应的跟踪标识;上述问题描述信息还可以包括该跟踪标识。
124.在一些实施例中,上述装置400还可以包括:接收单元(图中未示出)和发送单元(图中未示出);接收单元可以被配置成在处理单元403将上述问题描述信息归入目标知识库之后,接收数据查看请求,其中包括上述跟踪标识;获取单元401还可以被配置成从目标知识库中获取包括上述跟踪标识的问题描述信息;发送单元可以被配置成返回获取单元401所获取的该问题描述信息。
125.在一些实施例中,上述若干个服务端应用可以包括,用于对目标服务请求进行处理的第一服务端应用;上述若干个容器可以包括,第一服务端应用所在的第一容器;上述若干个物理机可以包括,第一容器所在的第一服务器集群。进一步地,上述若干个物理机还可以包括,第一服务器集群对应的网络交换机。
126.在一些实施例中,第一服务器集群可以为ai服务器集群或边缘服务器集群。
127.在一些实施例中,上述若干个服务端应用还可以包括,第一服务端应用在处理目标服务请求的过程中经由的第一中间件和/或第一数据库;上述若干个容器还可以包括,第一中间件所在的第二容器,和/或第一数据库所在的第三容器;上述若干个物理机还可以包括,第二容器所在的第二服务器集群,和/或第三容器所在的第三服务器集群。
128.在一些实施例中,软硬件一体化架构还可以包括第二数据库和第三数据库。进一步地,在软硬件一体化架构被划分为硬件层、容器层和应用服务层时,应用服务层中还可以包括第二数据库和第三数据库,第二数据库和第三数据库可以分别部署在容器层的容器中。第二数据库可以存放有,在目标服务请求处理过程中从上述若干个服务端应用分别采集的第一组性能指标数据,以及从上述若干个容器分别采集的第二组性能指标数据。第三数据库可以存放有,在目标服务请求处理过程中从上述若干个物理机分别采集的第三组性能指标数据。获取单元401可以进一步被配置成:从第二数据库获取第一组性能指标数据和第二组性能指标数据,以及从第三数据库获取第三组性能指标数据。
129.在一些实施例中,上述若干个服务端应用、上述若干个容器和上述若干个物理机分别部署有代理程序,第一组性能指标数据、第二组性能指标数据和第三组性能指标数据,可以由相应的代理程序上传至相应的数据库。
130.在图4对应的装置实施例中,各单元的具体处理及其带来的技术效果可参考前文中方法实施例中的相关说明,在此不再赘述。
131.本说明书实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,其中,当该计算机程序在计算机中执行时,令计算机执行以上各方法实施例分别描述的基于软硬件一体化架构的全链路监控方法。
132.本说明书实施例还提供了一种计算设备,包括存储器和处理器,其中,该存储器中存储有可执行代码,该处理器执行该可执行代码时,实现以上各方法实施例分别描述的基于软硬件一体化架构的全链路监控方法。
133.本说明书实施例还提供了一种计算机程序,其中,当该计算机程序在计算机中执行时,令计算机执行以上各方法实施例分别描述的基于软硬件一体化架构的全链路监控方法。
134.本领域技术人员应该可以意识到,在上述一个或多个示例中,本说明书披露的多个实施例所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
135.在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
136.以上所述的具体实施方式,对本说明书披露的多个实施例的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本说明书披露的多个实施例的具体实施方式而已,并不用于限定本说明书披露的多个实施例的保护范围,凡在本说明书披露的多个实施例的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本说明书披露的多个实施例的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
