1.本发明属于信息处理技术领域,具体涉及一种基于语义实时分析的热控方法及系统。
背景技术:
2.互联网是现在人们搜索获取关键信息和人们话题的重要途径,在现代信息传播中具有重要的意义。用户通过互联网能够实时大规模的表达自身的观点态度,同时造成实时而巨大的社会舆论影响。当前的热控监测系统在互联网的大规模信息的处理方面,利用了人工智能和分布式大数据技术的监控系统,在公开号为cn109582801a的公开中所述的一种基于情感分析热点事件跟踪及分析的方法,尽管可通过用户操作模块将需要分析的热点事件相关关键词的原始文本输入到整个分析系统内并达到了通过识别关键词文本中情感文本来准确的理解关键词词义的目的,但是不利于对实时的搜索系统的热搜关键词进行高效地信息提取。
技术实现要素:
3.本发明的目的在于提出一种基于语义实时分析的热控方法及系统,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
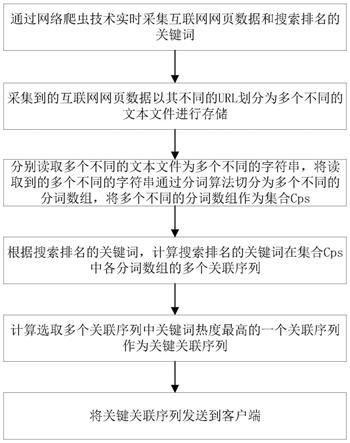
4.本发明提供了一种基于语义实时分析的热控方法及系统,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词并将采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储,将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组得到集合cps,根据计算搜索排名的关键词在集合cps中各分词数组的多个关联序列,选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列发送到客户端,实现了根据实时搜索热词对多个相关文本的信息筛选和信息提取,达到了根据实时的搜索关键词进行实时分析和热控。
5.为了实现上述目的,根据本公开的一方面,提供一种基于语义实时分析的热控方法,所述方法包括以下步骤:
6.s100,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词;
7.s200,采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储;
8.s300,分别读取多个不同的文本文件为多个不同的字符串,将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组,将多个不同的分词数组作为集合cps;
9.s400,根据搜索排名的关键词,计算搜索排名的关键词在集合cps中各分词数组的多个关联序列;
10.s500,计算选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列;
11.s600,将关键关联序列发送到客户端。
12.进一步地,在s100中,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词的方法为:通过网络爬虫技术实时采集互联网网页数据、以及搜索排名的热搜关键词,热搜关键词记作关键词,所述互联网网页数据和搜索排名的关键词的获取来源为百度api接口、搜狗api接口、360搜索api接口、必应搜索api接口中的一个或多个搜索api接口,其中,网络爬虫技术包括主题网络爬虫(topical crawler)、fish search算法、sharksearch算法增量式网络爬虫(incremental web crawler)或者deep web爬虫中任意一种。
13.进一步地,在s200中,采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储的方法为:采集到的互联网网页数据以json格式进行储存为结构化数据,结构化数据中包含对应的网页数据的字符串数据以及其采集网址的url,对不同的结构化数据按照其不同的url分别进行读取各个结构化数据中的字符串数据,对读取到的字符串数据按照不同的url划分为多个不同的文本文件进行存储。
14.进一步地,在s300中,分别读取多个不同的文本文件为多个不同的字符串,将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组,将多个不同的分词数组作为集合cps的方法为:分别读取多个不同的文本文件中的有效字符信息作为多个不同的字符串,将读取到的每个字符串分别通过中文分词算法进行切分得到多个不同的字符串数组记为分词数组,将多个不同的分词数组的集合记为集合cps。
15.进一步地,在s400中,根据搜索排名的关键词,计算搜索排名的关键词在集合cps中各分词数组的多个关联序列的方法为:将搜索排名的关键词的集合记为集合querys,记集合querys中元素的数量为n,集合querys中的元素的序号为i,i∈[1,n],有querys={q(1),q(2),
…
,q(n
‑
1),q(n)},q(i)表示第i个关键词;
[0016]
记集合cps中元素的数量为m,集合cps中的元素的序号为j,j∈[1,m],有cps={cps(1),cps(2),
…
,cps(m
‑
1),cps(m)};
[0017]
记变量k表示集合cps中每个分词数组cps(j)的数组长度,变量h表示分词数组cps(j)中的字符串的序号,cps(j,h)表示集合cps中序号为j的元素中序号为h的字符串,h∈[1,k],有cps(j)=[cps(j,1),cps(j,1),
…
,cps(j,k
‑
1),cps(j,k)];
[0018]
记函数glv()为通过词嵌入算法计算输入的字符串得到其词向量的函数,glv(cps(j,h))表示集合cps中序号为j的元素中序号为h的字符串通过词嵌入算法得到的词向量,记g(j,h)=glv(cps(j,h)),glv(q(i))表示集合querys中序号为i元素的字符串通过词嵌入算法得到的词向量,记gq(i)=glv(q(i)),变量q表示词向量的第q维度,变量p表示词向量的维度数量,g(j,h)[q]表示词向量g(j,h)的第q维度的数值,gq(i)[q]表示词向量gq(i)的第q维度的数值;
[0019]
函数sim()表示计算输入的两个向量之间的倾向度,函数sim(gq(i),g(j,h))表示通过函数sim()计算词向量gq(i)和g(j,h)之间的倾向度,倾向度sim(gq(i),g(j,h))的计算公式为:
[0020][0021]
计算集合querys中的各个搜索排名的关键词在集合cps中各分词数组中的多个关
联序列,包括以下步骤
[0022]
s401,开始程序;令变量i数值为1;创建空集合chianset,集合chianset具有互异性及有序性;转到s402;
[0023]
s402,获取querys中的序号为i的元素q(i);以q(i)通过函数glv()获取gq(i);转到s403;
[0024]
s403,令变量j数值为1;转到s404;
[0025]
s404,获取cps中的序号为j的元素cps(j);创建空数组simset;转到s405;
[0026]
s405,令变量h数值为1;转到s406;
[0027]
s406,获取cps(j)中的序号为h的元素cps(j,h);以cps(j,h)通过函数glv()获取g(j,h);转到s407;
[0028]
s407,获取sim(gq(i),g(j,h));将sim(gq(i),g(j,h))加入数组simset;转到s408;
[0029]
s408,判断是否满足约束条件h≧k,若是则转到s4081,若否则转到s4082;
[0030]
s4081,计算数组simset中各元素的算数平均值sim_avg,将数组simset中数值大于sim_avg的各元素的序号的集合作为集合seq;以集合seq中的各元素作为目标序号,提取出cps(j)中的目标序号的元素作为数组chain,将数组chain加入集合chianset中;转到s409;
[0031]
s4082,将h的数值增加1;转到s406;
[0032]
s409,令h的数值为1;转到s410;
[0033]
s410,判断是否满足约束条件j≧m,若是则转到s411,若否则转到s4101;
[0034]
s4101,将j的数值增加1;转到s404;
[0035]
s411,令j的数值为1;转到s412;
[0036]
s412,判断是否满足约束条件i≧n,若是则转到s413,若否则转到s4121;
[0037]
s4121,将i的数值增加1;转到s402;
[0038]
s413,输出集合chianset;结束程序;
[0039]
集合chianset中的各个数组即为对应集合querys中的各个搜索排名关键词的关联序列,记所得的多个关联序列的集合为集合litset。
[0040]
进一步地,在s500中,计算选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列的方法为:通过搜索api接口获取该时刻在集合querys中的关键词热度最高的关键词qri,获取qri在集合querys中的序号i,根据序号i在集合litset中获取对应的序号为i的元素记为litset(i),litset(i)即为所求的关键关联序列。
[0041]
进一步地,在s600中,将关键关联序列发送到客户端的方法为:将关键关联序列litset(i)发送到客户端,客户端把litset(i)中的元素进行字符串拼接并打印显示。
[0042]
本公开还提供了一种基于语义实时分析的热控系统,所述一种基于语义实时分析的热控系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现权利要求1中的一种基于语义实时分析的热控方法中的步骤,所述一种基于语义实时分析的热控系统可以运行于桌上型计算机、笔记本、移动电话、手提电话、平板电脑、掌上电脑及云端数据中心等计算设备中,可运行的系统可包括,但不仅限于,处理器、存储器、服务器集群,所述处理器执行所述计算机程序运行
在以下系统的单元中:
[0043]
数据采集单元,用于通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词;
[0044]
数据整理单元,用于采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储;
[0045]
分词划分单元,用于分别读取多个不同的文本文件为多个不同的字符串并将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组进而将多个不同的分词数组作为集合cps;
[0046]
关联序列计算单元,用于根据搜索排名的关键词计算搜索排名的关键词在集合cps中各分词数组的多个关联序列;
[0047]
关键关联序列选取单元,用于计算选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列;
[0048]
发送单元,用于将关键关联序列发送到客户端。
[0049]
本发明的有益效果为:本发明提供了一种基于语义实时分析的热控方法及系统,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词,并计算搜索排名的关键词在各分词数组的多个关联序列,进而选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列发送到客户端,实现了根据实时搜索热词对多个相关文本的信息筛选和信息提取,达到了根据实时的搜索关键词进行实时分析和热控。
附图说明
[0050]
通过对结合附图所示出的实施方式进行详细说明,本公开的上述以及其他特征将更加明显,本公开附图中相同的参考标号表示相同或相似的元素,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,在附图中:
[0051]
图1所示为一种基于语义实时分析的热控方法的流程图;
[0052]
图2所示为一种基于语义实时分析的热控系统的系统结构图。
具体实施方式
[0053]
以下将结合实施例和附图对本公开的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本公开的目的、方案和效果。需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
[0054]
在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
[0055]
如图1所示为根据本发明的一种基于语义实时分析的热控方法的流程图,下面结合图1来阐述根据本发明的实施方式的一种基于语义实时分析的热控方法及系统。
[0056]
本公开提出一种基于语义实时分析的热控方法,所述方法具体包括以下步骤:
[0057]
s100,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词;
[0058]
s200,采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储;
[0059]
s300,分别读取多个不同的文本文件为多个不同的字符串,将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组,将多个不同的分词数组作为集合cps;
[0060]
s400,根据搜索排名的关键词,计算搜索排名的关键词在集合cps中各分词数组的多个关联序列;
[0061]
s500,计算选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列;
[0062]
s600,将关键关联序列发送到客户端。
[0063]
进一步地,在s100中,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词的方法为:通过网络爬虫技术实时采集互联网网页数据、以及搜索排名的热搜关键词,热搜关键词记作关键词,所述互联网网页数据和搜索排名的关键词的获取来源为百度api接口、搜狗api接口、360搜索api接口、必应搜索api接口中的一个或多个搜索api接口,其中,网络爬虫技术包括主题网络爬虫(topical crawler)、fish search算法、sharksearch算法增量式网络爬虫(incremental web crawler)或者deep web爬虫中任意一种。
[0064]
其中,热搜关键词也可以为为其中任意一个或多个网页页面数据中的文本数据进行分词后出现的频率最高的字符串。
[0065]
进一步地,在s200中,采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储的方法为:采集到的互联网网页数据以json格式进行储存为结构化数据,结构化数据中包含对应的网页数据的字符串数据以及其采集网址的url,对不同的结构化数据按照其不同的url分别进行读取各个结构化数据中的字符串数据,对读取到的字符串数据按照不同的url划分为多个不同的文本文件进行存储。
[0066]
进一步地,在s300中,分别读取多个不同的文本文件为多个不同的字符串,将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组,将多个不同的分词数组作为集合cps的方法为:分别读取多个不同的文本文件为多个不同的字符串,将读取到的每个字符串分别通过中文分词算法进行切分得到多个不同的字符串数组记为分词数组,将多个不同的分词数组的集合记为集合cps。
[0067]
进一步地,在s400中,根据搜索排名的关键词,计算搜索排名的关键词在集合cps中各分词数组的多个关联序列的方法为:将搜索排名的关键词的集合记为集合querys,记集合querys中元素的数量为n,集合querys中的元素的序号为i,i∈[1,n],有querys={q(1),q(2),
…
,q(n
‑
1),q(n)};
[0068]
记集合cps中元素的数量为m,集合cps中的元素的序号为j,j∈[1,m],有cps={cps(1),cps(2),
…
,cps(m
‑
1),cps(m)};
[0069]
记变量k表示集合cps中每个分词数组cps(j)的数组长度,变量h表示分词数组cps(j)中的字符串的序号,cps(j,h)表示集合cps中序号为j的元素中序号为h的字符串,h∈[1,k],有cps(j)=[cps(j,1),cps(j,1),
…
,cps(j,k
‑
1),cps(j,k)];
[0070]
记函数glv()为通过词嵌入算法计算输入的字符串得到其词向量的函数,glv(cps(j,h))表示集合cps中序号为j的元素中序号为h的字符串通过词嵌入算法得到的词向量,
记g(j,h)=glv(cps(j,h)),glv(q(i))表示集合querys中序号为i元素的字符串通过词嵌入算法得到的词向量,记gq(i)=glv(q(i)),变量q表示词向量的第q维度,变量p表示词向量的维度数量,g(j,h)[q]表示词向量g(j,h)的第q维度的数值,gq(i)[q]表示词向量gq(i)的第q维度的数值;
[0071]
词嵌入算法至少包括word2vec、skip
‑
gram模型或者glove算法中任意一种。
[0072]
函数sim()表示计算输入的两个向量之间的倾向度,函数sim(gq(i),g(j,h))表示通过函数sim()计算词向量gq(i)和g(j,h)之间的倾向度,倾向度sim(gq(i),g(j,h))的计算公式为:
[0073][0074]
计算集合querys中的各个搜索排名的关键词在集合cps中各分词数组中的多个关联序列,包括以下步骤
[0075]
s401,开始程序;令变量i数值为1;创建空集合chianset,集合chianset具有互异性及有序性;转到s402;
[0076]
s402,获取querys中的序号为i的元素q(i);以q(i)通过函数glv()获取gq(i);转到s403;
[0077]
s403,令变量j数值为1;转到s404;
[0078]
s404,获取cps中的序号为j的元素cps(j);创建空数组simset;转到s405;
[0079]
s405,令变量h数值为1;转到s406;
[0080]
s406,获取cps(j)中的序号为h的元素cps(j,h);以cps(j,h)通过函数glv()获取g(j,h);转到s407;
[0081]
s407,以gq(i)和g(j,h)通过函数glv()获取倾向度sim(gq(i),g(j,h));将sim(gq(i),g(j,h))加入数组simset;转到s408;
[0082]
s408,判断是否满足约束条件h≧k,若是则转到s4081,若否则转到s4082;
[0083]
s4081,计算数组simset中各元素的算数平均值sim_avg,将数组simset中数值大于sim_avg的各元素的序号的集合作为集合seq;以集合seq中的各元素作为目标序号,提取出cps(j)中的目标序号的元素作为数组chain,将数组chain加入集合chianset中;转到s409;
[0084]
s4082,将h的数值增加1;转到s406;
[0085]
s409,令h的数值为1;转到s410;
[0086]
s410,判断是否满足约束条件j≧m,若是则转到s411,若否则转到s4101;
[0087]
s4101,将j的数值增加1;转到s404;
[0088]
s411,令j的数值为1;转到s412;
[0089]
s412,判断是否满足约束条件i≧n,若是则转到s413,若否则转到s4121;
[0090]
s4121,将i的数值增加1;转到s402;
[0091]
s413,输出集合chianset;结束程序;
[0092]
集合chianset中的各个数组即为对应集合querys中的各个搜索排名关键词的关联序列,记所得的多个关联序列的集合为集合litset。
[0093]
进一步地,在s500中,计算选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列的方法为:通过搜索api接口获取该时刻在集合querys中的关键词热度最高的关键词qri,获取qri在集合querys中的序号i,根据序号i在集合litset中获取对应的序号为i的元素记为litset(i),litset(i)即为所求的关键关联序列。
[0094]
进一步地,在s600中,将关键关联序列发送到客户端的方法为:将关键关联序列litset(i)发送到客户端,客户端把litset(i)中的元素进行字符串拼接并打印显示。
[0095]
所述一种基于语义实时分析的热控系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于语义实时分析的热控方法实施例中的步骤,所述一种基于语义实时分析的热控系统可以运行于桌上型计算机、笔记本、掌上电脑及云端数据中心等计算设备中,可运行的系统可包括,但不仅限于,处理器、存储器、服务器集群。
[0096]
本公开的实施例提供的一种基于语义实时分析的热控系统,如图2所示,该实施例的一种基于语义实时分析的热控系统包括:处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于语义实时分析的热控方法实施例中的步骤,所述处理器执行所述计算机程序运行在以下系统的单元中:
[0097]
数据采集单元,用于通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词;
[0098]
数据整理单元,用于采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储;
[0099]
分词划分单元,用于分别读取多个不同的文本文件为多个不同的字符串并将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组进而将多个不同的分词数组作为集合cps;
[0100]
关联序列计算单元,用于根据搜索排名的关键词计算搜索排名的关键词在集合cps中各分词数组的多个关联序列;
[0101]
关键关联序列选取单元,用于计算选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列;
[0102]
发送单元,用于将关键关联序列发送到客户端。
[0103]
所述一种基于语义实时分析的热控系统可以运行于桌上型计算机、笔记本、掌上电脑及云端数据中心等计算设备中。所述一种基于语义实时分析的热控系统包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,所述例子仅仅是一种基于语义实时分析的热控方法及系统的示例,并不构成对一种基于语义实时分析的热控方法及系统的限定,可以包括比例子更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述一种基于语义实时分析的热控系统还可以包括输入输出设备、网络接入设备、总线等。
[0104]
所称处理器可以是中央处理单元(central processing unit,cpu),还可以是其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列(field
‑
programmable gate array,fpga)或者其他可编程逻辑器件、分立元器件门电路或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常
规的处理器等,所述处理器是所述一种基于语义实时分析的热控系统的控制中心,利用各种接口和线路连接整个一种基于语义实时分析的热控系统的各个分区域。
[0105]
所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现所述一种基于语义实时分析的热控方法及系统的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
[0106]
本发明提供了一种基于语义实时分析的热控方法及系统,通过网络爬虫技术实时采集互联网网页数据和搜索排名的关键词并将采集到的互联网网页数据以其不同的url划分为多个不同的文本文件进行存储,将读取到的多个不同的字符串通过分词算法切分为多个不同的分词数组得到集合cps,根据计算搜索排名的关键词在集合cps中各分词数组的多个关联序列,选取多个关联序列中关键词热度最高的一个关联序列作为关键关联序列发送到客户端,实现了根据实时的搜索热词对多个相关文本的信息筛选和信息提取,达到了根据实时的搜索关键词进行实时分析和热控。
[0107]
尽管本公开的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,从而有效地涵盖本公开的预定范围。此外,上文以发明人可预见的实施例对本公开进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本公开的非实质性改动仍可代表本公开的等效改动。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。