1.本发明涉及视觉场景识别(visual place recognition,vpr)技术领域,尤其涉及一种基于语义梯度点以及道路幂点的视觉场景识别方法。
背景技术:
2.视觉场景识别(visual place recognition,vpr)或者闭环检测技术是视觉即时定位与地图构建(visual simultaneous localization and mapping,vslam)的重要组成部分。视觉场景识别是检测闭环的关键,有助于提高定位精度并降低所构建地图的不确定性。传统视觉场景识别在一些特定场景下能够达到令人满意的效果,例如短期任务(短时间内重访同一地点),一定程度的场景外表变化,以及一定程度的视角变化等。然而,对于长期任务下的挑战性场景,例如场景外表变化(一天中的不同时间段、不同季节以及不同光照条件)和强相机视角变化,传统视觉场景识别的性能显著下降。
3.机器人领域相关技术与计算机视觉相关技术的不断进步,以及对于长期自主系统的需求,不断推动着视觉场景识别的发展。基于卷积神经网络的视觉场景识别成为当下研究热点,并且在强场景外表变化下的性能上有一定提升。然而在极具挑战场景(强场景外表变化与强相机视角变化相结合)下,其性能仍有极大提升空间。
技术实现要素:
4.为了克服现有技术的不足,本发明提供一种基于语义梯度点以及道路幂点的视觉场景识别方法,利用语义梯度点在强场景外表变化下可被重复检测的特性、语义梯度点不同层特征的不同优势以及场景本身的结构,提升在极具挑战场景下的性能。
5.本发明解决其技术问题所采用的技术方案是:
6.一种基于语义梯度点以及道路幂点的视觉场景识别方法,包括以下步骤:
7.步骤1,语义特征提取,利用语义分割网络对图像进行处理,保留中间层特征、logits层特征以及最后的语义标签;
8.步骤2,语义梯度点检测,计算logits层特征所有通道的绝对梯度和,筛选出绝对梯度和较高的点,保留其在图像中的位置信息;
9.步骤3,语义梯度点特征拼接,根据语义梯度点位置信息,将同一语义梯度点在中间层的特征以及logits层的特征分别进行l2正则化后展开拼接在一起;
10.步骤4,道路幂点检测,利用语义标签得到道路目标与其他静态语义类别目标的边界,然后利用霍夫变换得到图像中的道路线,最后计算道路线的交点并加权得到道路幂点;
11.步骤5,图像描述子生成,根据道路幂点对图像进行区域划分,每个区域分别利用区域内语义梯度点的特征生成一个vlad描述子,称为语义结构化vlad;
12.步骤6,相似度计算,由于每个图像可能存在1个或者2个语义结构化vlad,计算相似度时需要先明确他们之间的对应关系,即使得语义结构化vlad相似度之和最大,然后以该对应关系下语义结构化vlad的平均相似度作为图像的相似度,遍历数据库中的所有图
像,图像以语义结构化vlad形式存储,以相似度最高的图像作为最终结果。
13.进一步地,在所述步骤2中,语义梯度点检测的步骤如下:
14.步骤2-1,计算logits层特征所有通道的绝对梯度和,logits层(w
×h×
c)特征的每个通道可以认为是对应语义类别的概率,但是不同通道间存在相互干扰的情况,因此以所有通道的绝对梯度和来作为筛选语义特征点的依据:
[0015][0016]
其中nc是通道个数,i是通道的标签,gi是通道i的梯度,g
sum
是所有通道的绝对梯度和;
[0017]
步骤2-2,将整个图像划分成ns个正方形小块,若该正方形小块中的最大绝对梯度和大于g
θ
,则将该最大绝对梯度和对应的语义梯度点作为备选;
[0018]
步骤2-3,为使得语义梯度点能够均匀分布在图像各处,将整个图像沿横轴划分成k个直方图,每个直方图按绝对梯度和对备选的语义梯度点排序,筛选出前nk个点作为最终的语义梯度点。
[0019]
再进一步地,在所述步骤4中,道路幂点检测的步骤如下:
[0020]
步骤4-1,利用语义标签得到道路目标与其他静态语义类别的边界,所述其他静态语义类别包括人行道、建筑和交通标志等;
[0021]
步骤4-2,利用霍夫变换将道路边界转化为道路线,即道路在图像中的二维几何表示;
[0022]
步骤4-3,计算道路线的交点,为了防止道路同一侧道路线的相互干扰,只计算角度差大于a
θ
的道路线的交点;
[0023]
步骤4-4,计算所有道路线交点的平均位置,作为最终的道路幂点。
[0024]
更进一步地,在所述步骤5中,若存在道路幂点,则分为两个区域;若不存在道路幂点,则整个图像视为一个区域。
[0025]
所述步骤5中,图像描述子的生成结合了场景的结构,分区生成描述子,过程如下:
[0026]
首先根据道路幂点对图像进行区域划分,若存在道路幂点,则划分为两个区域,若不存在道路幂点,则整个图像视为一个区域;每个区域分别利用区域内语义梯度点的特征生成语义结构化vlad:
[0027]
预先离线训练好的字典树c={c1,c2,
…cw
},用x表示d-维的特征,每一个x都会和与之最近的视觉单词ci相关联(ci=fv(x)),对于每一个视觉单词ci,vlad累积每一个与ci相关联的x与ci的差异:
[0028][0029]
其中i是视觉单词的索引,而j是特征维度的索引;
[0030]
l2正则化每一视觉单词对应的vlad块,即:
[0031][0032]
最后l2正则化整个vlad描述子,最终图像中的每个区域都有一个语义结构化
vlad。
[0033]
进一步地,在所述步骤6中,图像相似度计算需要考虑语义结构化vlad的对应关系,过程如下:
[0034]
每个图像可能存在1个或2个语义结构化vlad,即当计算两个图像相似度时会出现四种情况:1vs1,1vs2,2vs1以及2vs2,前三种情况的对应关系较为直接,只有一种对应关系,而最后一种情况,则有两种对应关系;所述方法选择使得语义结构化vlad相似度之和最大的对应关系来计算最终相似度,即该对应关系下语义结构化vlad的平均相似度。
[0035]
本发明的有益效果主要表现在:利用语义梯度点在强场景外表变化下可被重复检测的特性、语义梯度点不同层特征的不同优势以及场景本身的结构,提升在极具挑战场景下的性能。语义梯度点在强场景外表变化下可被重复检测的特性保证了正确匹配间所采纳特征的交集;将语义梯度点不同层的特征拼接在一起,能够利用不同层特征对于场景外表变化以及相机视角变化的不同特性;根据道路幂点划分区域并且在计算相似度时考虑区域间的对应关系,能够增加视觉重叠部分在相似度计算中的权重,更加专注于视觉重叠部分,排除无关部分的干扰。
附图说明
[0036]
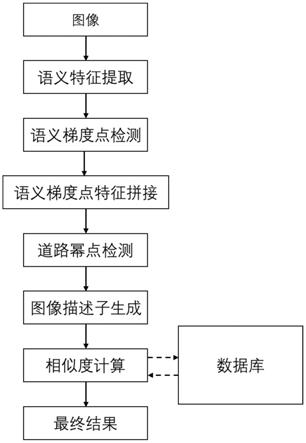
图1为本发明的整体流程图。
[0037]
图2为本专利方法相比于其他方法的性能比较图。
具体实施方式
[0038]
下面结合附图对本发明作进一步描述。
[0039]
参照图1和图2,一种基于语义梯度点以及道路幂点的视觉场景识别方法,包括以下步骤:
[0040]
步骤1,语义特征提取,利用语义分割网络对图像进行处理,保留中间层特征、logits层特征以及最后的语义标签;
[0041]
步骤2,语义梯度点检测,计算logits层特征所有通道的绝对梯度和,筛选出绝对梯度和较高的点,保留其在图像中的位置信息;
[0042]
语义梯度点检测的步骤如下:
[0043]
步骤2-1,计算logits层特征所有通道的绝对梯度和,logits层(w
×h×
c)特征的每个通道可以认为是对应语义类别的概率,但是不同通道间存在相互干扰的情况,因此以所有通道的绝对梯度和来作为筛选语义特征点的依据:
[0044][0045]
其中nc是通道个数,i是通道的标签,gi是通道i的梯度,g
sum
是所有通道的绝对梯度和;
[0046]
步骤2-2,将整个图像划分成ns个正方形小块,若该正方形小块中的最大绝对梯度和大于g
θ
,则将该最大绝对梯度和对应的语义梯度点作为备选;
[0047]
步骤2-3,为使得语义梯度点能够均匀分布在图像各处,将整个图像沿横轴划分成
k个直方图,每个直方图按绝对梯度和对备选的语义梯度点排序,筛选出前nk个点作为最终的语义梯度点;
[0048]
步骤3,语义梯度点特征拼接,根据语义梯度点位置信息,将同一语义梯度点在中间层的特征以及logits层的特征分别进行l2正则化后展开拼接在一起;
[0049]
步骤4,道路幂点检测,利用语义标签得到道路目标与其他静态语义类别目标的边界,然后利用霍夫变换得到图像中的道路线,最后计算道路线的交点并加权得到道路幂点;
[0050]
所述道路幂点检测的步骤如下:
[0051]
步骤4-1,利用语义标签得到道路目标与其他静态语义类别的边界,所述包括人行道、建筑和交通标志等;
[0052]
步骤4-2,利用霍夫变换将道路边界转化为道路线,即道路在图像中的二维几何表示;
[0053]
步骤4-3,计算道路线的交点,为了防止道路同一侧道路线的相互干扰,我们只计算,角度差大于a
θ
的道路线的交点;
[0054]
步骤4-4,计算所有道路线交点的平均位置,作为最终的道路幂点。
[0055]
步骤5,图像描述子生成,根据道路幂点对图像进行区域划分,若存在道路幂点,则分为两个区域;若不存在道路幂点,则整个图像视为一个区域,每个区域分别利用区域内语义梯度点的特征生成一个vlad描述子,称为语义结构化vlad;
[0056]
图像描述子的生成结合了场景的结构,分区生成描述子,过程如下:
[0057]
首先根据道路幂点对图像进行区域划分,若存在道路幂点,则划分为两个区域,若不存在道路幂点,则整个图像视为一个区域。每个区域分别利用区域内语义梯度点的特征生成语义结构化vlad:
[0058]
预先离线训练好的字典树c={c1,c2,
…cw
},用x表示d-维的特征,每一个x都会和与之最近的视觉单词ci相关联(ci=fv(x)),对于每一个视觉单词ci,vlad累积每一个与ci相关联的x与ci的差异:
[0059][0060]
其中i是视觉单词的索引,而j是特征维度的索引。
[0061]
l2正则化每一视觉单词对应的vlad块,即:
[0062][0063]
最后l2正则化整个vlad描述子,最终图像中的每个区域都有一个语义结构化vlad;
[0064]
步骤6,相似度计算,由于每个图像可能存在1个或者2个语义结构化vlad,计算相似度时需要先明确他们之间的对应关系,即使得语义结构化vlad相似度之和最大,然后以该对应关系下语义结构化vlad的平均相似度作为图像的相似度,遍历数据库中的所有图像,图像以语义结构化vlad形式存储,以相似度最高的图像作为最终结果;
[0065]
图像相似度计算需要考虑语义结构化vlad的对应关系,过程如下:
[0066]
每个图像可能存在1个或2个语义结构化vlad,即当计算两个图像相似度时会出现四种情况:1vs1,1vs2,2vs1以及2vs2。前三种情况的对应关系较为直接,只有一种对应关
系,而最后一种情况,则有两种对应关系。所述方法选择使得语义结构化vlad相似度之和最大的对应关系来计算最终相似度,即该对应关系下语义结构化vlad的平均相似度。
[0067]
本实施例所提出的基于语义梯度点以及道路幂点的视觉场景识别方法相比于其他方法,利用语义梯度点在强场景外表变化下可被重复检测的特性、语义梯度点不同层特征的不同优势以及场景本身的结构,提升在极具挑战场景下的性能。同时,本专利所提出的方法还可以与其他序列匹配技术相结合,进一步提升性能。本实施例选择领域内具有代表性的oxford robotcar数据集验证有效性。利用overcast autumn(201412-09-13-21-02(01))序列中的汽车后视图构建数据库,然后用night autumn(2014-12-10-18-10-50(01))序列中的汽车前视图去匹配数据库中的图像,验证在强场景外表变化(白天-黑夜)与强相机视角变化(180度)相结合情况下的性能。
[0068]
从图2中,可以看出,本专利方法相比于其他方法有较大提升,同时本专利方法结合序列匹配方法(隐含马尔科夫模型)能够进一步提升性能。
[0069]
以上实施方式仅用于说明本发明,而非对本发明的限制。尽管参照实施例对本发明进行了详细说明,本领域的技术人员应当理解,对本发明的技术方案进行各种组合、修改或者等同替换,都不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。