1.本发明属于文本分类方法技术领域,具体涉及一种基于协方差度量因子的特征选择方法。
背景技术:
2.随着大数据技术的广泛应用,非结构化文本信息在万维网上大量涌现,并被计算机存储和处理,例如音乐、视频软件上的用户评论;电商平台的用户反馈、采购记录;社交平台的随文、评论等。处理庞大的非结构化文本数据必须利用数据挖掘以及自然语言处理等技术,其中文本分类被广泛应用,通过模型的学习将文本数据划分为不同的类别,方便了数据的进一步处理。文本类型数据常常由数以万计的特征词组成,其中包含大量不相关的以及冗余的特征,它们对分类性能产生消极的影响。特征空间维数过大反而降低了分类器的分类性能,出现hughes现象。因此在数据预处理阶段进行特征降维操作是必不可少的。
3.特征选择是常用的降维技术,依据一定的判别准则来衡量特征所包含的分类信息的大小,从特征空间中选择出最优特征子集,减少了特征空间的维度,避免了“过拟合”现象的发生,提高了分类的效率和准确率。特征选择算法通常可以分为三种类型:过滤式、包装式以及嵌入式。
4.由于过滤式特征选择独立于学习算法,具有高计算效率、低成本的特点,被广泛应用于文本类型数据的处理上。许多基于文档频率的过滤式特征选择方法被提出。jieming yang等人提出类内和类间的综合度量方法(cmfs),同时考虑特征词在一个类中以及整个数据集中的分布情况;alper kursat u ysal等人提出一种基于概率的过滤式特征选择器(dfs),可以对特征词在整个数据集上的全局类别分辨能力进行有效的评估;hiroshi等人提出基于泊松偏离度度量的特征选择算法,利用特征词在每个类中的实际概率分布与标准泊松分布之间的偏差程度来衡量特征词所携带的类别相关信息量。最大最小比率算法(mmr)用来处理具有高度稀疏性且类别高度倾斜的文本数据。三角比较度量算法(tcm)考虑类和类之间特征词的文档频率的相对大小,对只在一个类中频繁出现、其他类中几乎不出现的特征词赋予更高的分数。本发明在三角比较度量算法的基础上引入协方差的概念,提出基于协方差度量因子的特征选择方法,通过计算特征词与对应类别的协方差值,在文档频率层面进一步衡量两者的相关性大小。
技术实现要素:
5.本发明的目的在于提供一种基于协方差度量因子的特征选择方法,在三角比较度量算法的基础上进一步计算特征词与对应类别的协方差值,最终选择出与类别高度相关的词语,实现降维的目的。
6.本发明所采用的技术方案是:基于协方差度量因子的特征选择方法,包括以下步骤:
7.步骤1、选取不同的文本类型数据集进行预处理操作,利用向量空间模型对文本数
据进行表示,将数据中出现的文档数多于总数的25%或少于3篇的特征词去掉,之后将数据集划分为训练集和测试集;
8.步骤2、设置最优特征子集的大小为c,使用特征排序函数计算训练集数据每个特征词的得分,按照分数对特征词进行降序排列,选择排名为前c的特征词作为最优特征子集的元素,根据得到的最优特征子集分别完成对训练集和测试集数据的降维处理;
9.步骤3、利用步骤2得到的训练集数据d
train
对朴素贝叶斯分类器进行训练,并将训练好的模型对测试集数据d
test
中的每一个样本x预测其对应的类别完成对降维后的测试集样本的分类操作。
10.本发明的特点还在于,
11.步骤1中的预处理操作包括分词操作,并去除文本中的停用词。
12.步骤1中将数据集划分为训练集和测试集具体为:随机选取数据集中90%的样本作为训练集数据,将剩下的10%的样本作为测试集数据。
13.步骤2具体包括以下步骤:
14.步骤2.1、根据公式(1)计算训练集特征词t
i
与类别c
k
的协方差度量因子cov(t
i
,c
k
);
[0015][0016]
式(1)中,tp表示类c
k
中特征词t
i
出现的文档数量,fn表示类c
k
中特征词t
i
没有出现的文档数量,fp表示非c
k
类中特征词t
i
出现的文档数量,n表示数据集的文档总数;
[0017]
步骤2.2、根据公式(2)计算训练集特征词t
i
的三角比较度量因子tcm(t
i
,c
k
)得分;
[0018]
tcm(t
i
,c
k
)=(2 max(sin2θ,cos2θ)
‑
1)
m
|tpr
‑
fpr|
ꢀꢀ
(2)
[0019]
式(2)中,tpr和fpr分别表示特征词t
i
在类c
k
中的真正率和假正率θ表示特征词t
i
对应的向量(tpr,fpr)与距离最近的坐标轴之间的夹角,参数m控制着tcm算法中三角度量因子对特征词整体分数的影响;
[0020]
步骤2.3、根据公式(3)计算特征词t
i
的全局得分cov
‑
tcm(t
i
),得到带有权值的特征集合;
[0021][0022]
式(3)中,k表示类别编号,p(c
k
)表示属于类c
k
的文档数量在整个数据集中所占的比例;
[0023]
步骤2.4、根据训练集中每个特征词的cov
‑
tcm得分对特征进行降序排序,选择排名前c的特征词作为最优特征;
[0024]
步骤2.5、分别对训练集和测试集数据进行处理,删去文档中最优特征子集不包含的特征词,保留最优特征子集包含的特征词,得到降维处理的训练集数据d
train
和测试集数据d
test
。
[0025]
步骤3具体包括以下步骤:
[0026]
步骤3.1、根据公式(4)计算训练集中类别c
k
的先验概率
[0027][0028]
式(4)中,n
k
表示类c
k
中所包含的文档总数,n表示数据集的文档总数;
[0029]
步骤3.2、根据公式(5)计算训练集中类别c
k
的样本均值
[0030][0031]
式(5)中,d
k
表示类别为c
k
的文档的集合,d
k
={x
j
|y
j
=c
k
},x
j
表示d
k
中第j个文档,y
j
表示样本x
j
对应的标签;
[0032]
步骤3.3、根据公式(6)计算训练集中类别c
k
的居中数据矩阵z
k
;
[0033][0034]
步骤3.4、根据公式(7)计算训练集中类别c
k
针对特征t
i
,i=1,2,...,c的方差;
[0035][0036]
式(7)中,z
ki
表示类别c
k
中特征t
i
的居中数据,c表示降维后的训练集样本特征维度大小;
[0037]
步骤3.5、根据公式(8)和(9)对测试集数据中样本x,x={t1,t2,...,t
c
}进行类别的预测,返回具有最大后验概率的类,即样本对应的类别完成对测试集样本的分类操作;
[0038][0039][0040]
本发明的有益效果是:本发明基于协方差度量因子的特征选择方法,在原有的tcm算法基础上,引入协方差度量因子的概念,通过计算特征词与类别的协方差值,在文档频率层面进一步衡量特征与类别之间的相关性。本发明更好地筛选出与类别高度相关的特征词,是可靠的特征选择算法。
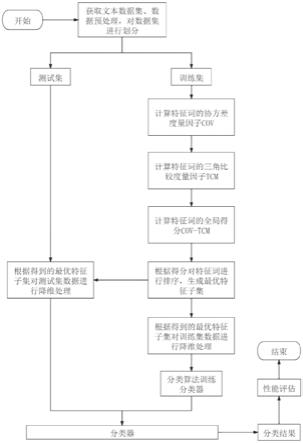
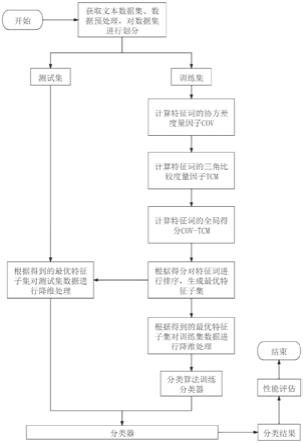
附图说明
[0041]
图1是本发明基于协方差度量因子的特征选择方法的流程图;
[0042]
图2(a)
‑
图2(b)是在re1数据集上,使用朴素贝叶斯分类器进行分类时,本发明基
于协方差度量因子的特征选择方法与现有技术在不同特征维数下的macro
‑
f1、micro
‑
f1对比结果;
[0043]
图3(a)
‑
图3(b)是在k1b数据集上,使用朴素贝叶斯分类器进行分类时,本发明与现有技术在不同特征维数下的macro
‑
f1、micro
‑
f1对比结果;
[0044]
图4(a)
‑
图4(b)是在r52数据集上,使用朴素贝叶斯分类器进行分类时,本发明与现有技术在不同特征维数下的macro
‑
f1、micro
‑
f1对比结果;
[0045]
图5(a)
‑
图5(b)是在r8数据集上,使用朴素贝叶斯分类器进行分类时,本发明与现有技术在不同特征维数下的macro
‑
f1、micro
‑
f1对比结果;
[0046]
图6(a)
‑
图6(b)是在20newsgroups数据集上,使用朴素贝叶斯分类器进行分类时,本发明与现有技术在不同特征维数下的macro
‑
f1、micro
‑
f1对比结果。
具体实施方式
[0047]
下面结合附图以及具体实施方式对本发明进行详细说明。
[0048]
本发明提供了一种基于协方差度量因子的特征选择方法,如图1所示,具体按照以下步骤实施:
[0049]
步骤1、选取不同的文本类型数据集,并进行预处理操作,即进行分词操作,并去除文本中的停用词。利用向量空间模型对文本数据进行表示,将数据中出现的文档数多于总数的25%或少于3篇的特征词去掉。对数据集按照9:1的比例进行划分,即随机选取数据集中90%的样本作为训练集数据,将剩下的10%的样本作为测试集数据。
[0050]
步骤2、设置最优特征子集的大小为c,使用特征排序函数计算训练集数据每个特征词的得分,按照分数对特征词进行降序排列,选择排名为前c的特征词作为最优特征子集的元素,根据得到的最优特征子集分别完成对训练集和测试集数据的降维处理;具体如下:
[0051]
步骤2.1、根据公式(1)计算训练集特征词t
i
与类别c
k
的协方差度量因子cov(t
i
,c
k
);
[0052][0053]
其中,tp表示类c
k
中特征词t
i
出现的文档数量,fn表示类c
k
中特征词t
i
没有出现的文档数量,fp表示非c
k
类中特征词t
i
出现的文档数量,n表示数据集的文档总数;
[0054]
步骤2.2、根据公式(2)计算训练集特征词t
i
的三角比较度量因子tcm(t
i
,c
k
)得分;
[0055]
tcm(t
i
,c
k
)=(2 max(sin2θ,cos2θ)
‑
1)
m
|tpr
‑
fpr|
ꢀꢀ
(2)
[0056]
其中,tpr和fpr分别表示特征词t
i
在类c
k
中的真正率和假正率θ表示特征词t
i
对应的向量(tpr,fpr)与距离最近的坐标轴之间的夹角,参数m控制着tcm算法中三角度量因子对特征词整体分数的影响,m取100时算法效果最优。
[0057]
步骤2.3、根据公式(3)计算特征词t
i
的全局得分cov
‑
tcm(t
i
),得到带有权值的特征集合;
[0058][0059][0060]
其中,k表示类别编号,p(c
k
)表示属于类c
k
的文档数量在整个数据集中所占的比例。
[0061]
步骤2.4、根据训练集中每个特征词的cov
‑
tcm得分对特征进行降序排序,选择排名前c的特征词作为最优特征;
[0062]
步骤2.5、分别对训练集和测试集数据进行处理,删去文档中最优特征子集不包含的特征词,保留最优特征子集包含的特征词,得到降维处理的训练集数据d
train
和测试集数据d
test
。
[0063]
步骤3、利用步骤2得到的训练集数据d
train
对朴素贝叶斯分类器进行训练,并将训练好的模型对测试集数据d
test
中的每一个样本x预测其对应的类别完成对降维后的测试集样本的分类操作;具体包括以下步骤:
[0064]
步骤3.1、根据公式(4)计算训练集中类别c
k
的先验概率
[0065][0066]
式(4)中,n
k
表示类c
k
中所包含的文档总数,n表示数据集的文档总数;
[0067]
步骤3.2、根据公式(5)计算训练集中类别c
k
的样本均值
[0068][0069]
式(5)中,d
k
表示类别为c
k
的文档的集合,d
k
={x
j
|y
j
=c
k
},x
j
表示d
k
中第j个文档,y
j
表示样本x
j
对应的标签;
[0070]
步骤3.3、根据公式(6)计算训练集中类别c
k
的居中数据矩阵z
k
;
[0071][0072]
步骤3.4、根据公式(7)计算训练集中类别c
k
针对特征t
i
,i=1,2,...,c的方差;
[0073][0074]
式(7)中,z
ki
表示类别c
k
中特征t
i
的居中数据,c表示降维后的训练集样本特征维度大小;
[0075]
步骤3.5、根据公式(8)和(9)对测试集数据中样本x,x={t1,t2,...,t
c
}进行类别的预测,返回具有最大后验概率的类,即样本对应的类别完成对测试集样本的分类操
作;
[0076][0077][0078]
结果分析
[0079]
利用macro
‑
f1以及micro
‑
f1评估指标对分类结果进行评估,macro
‑
f1和micro
‑
f1分数越高,则证明分类的效果越好,进而证明特征选择算法性能越好,具体如下:
[0080]
在对比实验中,使用re1、k1b、r8、r52、20 newsgroups数据集进行测试。它们是机器学习领域常用的文本分类测试集。为了验证基于协方差度量因子的特征选择算法的性能,将本发明与优势率(odds)、最大最小比率(mmr)、互信息(mi)、卡方检验(chi)、类内和类间的综合度量方法(cmfs)、基尼系数(gini)、信息增益(ig)七种已有的特征选择算法进行对比。从图2(a)
‑
图2(b)可以看到,在re1数据集上,当使用朴素贝叶斯分类器时,除了在10维度对比点处本发明的micro
‑
f1得分略低于ig算法,取得第二的位次,在其它所有对比点处,本发明的macro
‑
f1与micro
‑
f1评估结果均取得最优值。从图3(a)
‑
图3(b)可以看到,在k1b数据集上,本发明的性能在大部分对比点处均优于其他对比算法,最优情况占比75%。从图4(a)
‑
图4(b)可以看出,在r52数据集上,当使用朴素贝叶斯分类器时,本发明的macro
‑
f1结果在所有对比点处均为最高值,而micro
‑
f1得分在较高维度范围内达到最高。从图5(a)
‑
图5(b)可以看到,在r8数据集上,本发明整体性能表现较好,且在多个对比点处取得最高的分数。从图6(a)
‑
图6(b)可以看到,在20newsgroups数据集上,本发明在所有的对比点处性能均优于所有对比算法。本发明性能表现较好,是可靠的特征选择算法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。