一种基于xml电子病历自动解析方法
技术领域
1.本发明涉及电子病历技术领域,特别涉及一种基于xml电子病历自动解析方法。
背景技术:
2.现阶段状况电子病历解析,存在以下问题:
3.(1)不同his存储全病案数据采用的数据格式多数是不同的。
4.(2)同一家医院,数据格式模板是一样的。
5.(3)在业务应用系统中,通常需要将his存储的数据转换为结构化数据,便于更好的利用数据价值。
6.针对上述状况或诉求,目前常用的数据组解析的方法是对纯文本数据进行自动解析。专利(申请号cn202110618183.3,一种自动化电子病历解析方法与装置)公开的电子病历解析方法存在的问题:每家医院都需人工进行数据分析、配置,人工成本大;不同医院的数据格式可能存在相同的规律,但同样需人工分析处理;人工分析效率低;仅能处理纯文本。
技术实现要素:
7.本发明的目的旨在至少解决所述技术缺陷之一。
8.为此,本发明的目的在于提出一种基于xml电子病历自动解析方法,以解决背景技术中所提到的问题,克服现有技术中存在的不足。
9.为了实现上述目的,本发明的实施例提供一种基于xml电子病历自动解析方法,包括如下步骤:
10.步骤s1,输入xml电子病历数据集d1;
11.步骤s2,对所述电子病历数据集进行数据清洗,生成清洗后的数据集d2;
12.步骤s3,对所述清洗后的数据集d2自动生成配置,包括:
13.对数据集d2中的所有行数据,按照文本内容长度大小降序排序,得到数据
14.集d3;
15.遍历数据集d3,对相同的元组取文本内容最长的行,构成数据集d4;
16.遍历数据集d4中的每一行数据,将该行数据的文本内容值解析得到xml树;
17.对列表中的元素按进行统计,取出现次数最多的嵌套解析的文本名称取值方
18.式,记为x1;
19.遍历数据集d4中的每一行数据,将该行数据的文本内容值解析得到xml树;
20.分别对所有的名称节点、内容节点按照tag名称统计,分别取tag名称出现次数最多的节点做平铺名称节点、平铺内容节点;如果平铺名称节点与平铺内容节点的tag名称一致,则生成平铺解析的文本名称、文本内容定位和取值方式,记为x3;
21.根据x3文本内容的取值方式,生成嵌套解析文本内容定位及取值方式,记为x2;
22.对x1和x2进行拼接,得到嵌套解析的文本名称、文本内容定位及取值方式,然后与
x3一并写入数据库中;
23.完成自动解析配置生成;
24.步骤s4,在配置完成后,解析电子病历数据,包括:
25.从数据库中获取电子病历解析配置列表c1;
26.遍历数据集d2中的每一行数据,由解析配置列表c1中解析器对数据进行处理,其中,所述解析器包括平铺解析器和嵌套解析器;根据数据的配置信息选择对应的解析器进行解析;合并每个解析器处理得到的结果列表,将结果列表添加到数据集d3中;
27.将数据集d3写入到csv文件中,解析完成。
28.由上述任一方案优选的是,在所述步骤s1中,所述电子病历数据集d1包括:病案号、病案名称、文本名称和文本内容。
29.由上述任一方案优选的是,在所述步骤s2中,所述数据清洗,包括如下步骤:删除字段缺失的数据、删除取值不在字段合理取值范围内的数据。
30.由上述任一方案优选的是,在所述步骤s3中,遍历数据集d3,对相同的病案名称和文本名称,取文本内容最长的行,构成数据集d4。
31.由上述任一方案优选的是,在所述步骤s3中,所述遍历数据集d4中的每一行数据,将该行数据的文本内容值解析得到xml树,包括如下步骤:
32.通过深度优先遍历dfs方式递归遍历xml树的所有非叶节点;
33.对每个节点判断其所有属性值,是否存在标准文本名称集合中,若存在,则添加到列表l1,终止遍历该节点的所有子节点,若不存在,则继续递归遍历该节点的子节点;
34.重复上述步骤,直到处理完所有节点。
35.由上述任一方案优选的是,所述遍历数据集d4中的每一行数据,将该行数据的文本内容值解析得到xml树,包括如下步骤:
36.由x1定位到xml树中的第一个元素节点,取该节点的所有兄弟叶节点,以兄弟叶节点的顺序遍历,将兄弟叶节点分为两类:名称节点和内容节点,分类的依据是判断节点文本值或属性值中是否存在标准文本名称字典中。
37.重复上述步骤,直到处理完所有节点。
38.由上述任一方案优选的是,在所述步骤s4中,所述平铺解析器解析过程如下:
39.初始化平铺解析器,初始信息从解析配置列表c1中获取;
40.将行数据的文本内容解析成xml树;
41.通过名称xpath查找xml树,得到所有名称节点,记为s1;通过内容xpath查找xml树,得到所有内容节点,记为s2;
42.顺序遍历名称节点的同级节点,并维护名称变量keyname和列表l,若当前节点在s1中,将keyname及拼接后的l作为已确定解析结果添加到解析结果列表中,更新keyname、置空l;若当前节点在s2中,通过内容取值xpath获取到当前节点的值,追加到l中;
43.重复上述步骤,直到处理完所有同级节点。
44.由上述任一方案优选的是,在所述步骤s4中,所述嵌套解析器解析过程如下:
45.初始化嵌套解析器,初始信息从解析配置列表c1中获取;
46.将行数据的文本内容解析成xml树;
47.通过名称xpath查找xml树,得到所有名称节点;
48.对每个名称节点根据名称取值xpath,获得名称值,再根据内容xpath、内容取值xpath,获得内容值,将二元组添加到解析结果列表中;
49.重复上述步骤,直到处理完所有名称节点。
50.由上述任一方案优选的是,对所述数据集配置的解析器方式包括如下几种形式:
51.(1)平铺解析器;
52.(2)嵌套解析器;
53.(3)平铺解析器和嵌套解析器;
54.(4)不需要解析。
55.本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
56.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
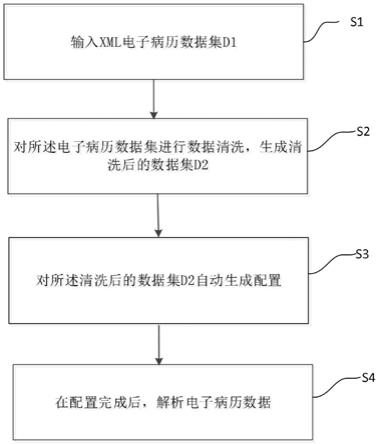
57.图1为根据本发明实施例的基于xml电子病历自动解析方法的流程图。
具体实施方式
58.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
59.下面首先对本发明中涉及的多个技术术语进行说明。
60.电子病历:电子病历是一个人在医疗机构历次就诊过程中产生和被记录的完整、详细的临床信息资源,是目前医疗数据主要的组成部分。但是目前电子病历多以文本、xml形式为主,并不能直接用于分析研究。因此,如何将电子病历准确有效解析,并提取出数据组内容用于分析研究是医疗数据治理中亟待解决的问题。
61.xml:可扩展标记语言(英语:extensible markup language,简称:xml)是一种标记语言,主要由标签、元素、属性构成,被设计用来传送及携带数据信息。
62.xpath:xpath即为xml路径语言(xml path language),它是一种用来确定xml文档中某部分位置的计算机语言,xpath基于xml的树状结构,提供在数据结构树中寻找节点的能力。
63.如图1所示,本发明实施例的基于xml电子病历自动解析方法,包括如下步骤:
64.步骤s1,输入xml电子病历数据集d1。
65.在步骤s1中,电子病历数据集d1至少包括如下关键字段:病案号(单次住院唯一标识)、病案名称(如入院记录、出院记录等)、文本名称(如首次病程记录、手术记录等)和文本内容(xml数据内容)。
66.步骤s2,对电子病历数据集进行数据清洗,生成清洗后的数据集d2。
67.具体的,对于数据集d1,检查关键字段值进行清洗,得到数据集d2。在本发明的实施例中,数据清洗包括如下国超:删除字段缺失的数据;删除取值不在字段合理取值范围内的数据。
68.步骤s3,对清洗后的数据集d2自动生成配置,对数据集d2中的数据,进行以下操作:
69.步骤s31,对数据集d2中的所有行数据,按照文本内容长度大小降序排序,得到数据集d3。
70.步骤s32,遍历数据集d3,对相同的(病案名称、文本名称)元组,取文本内容最长的行,构成数据集d4。
71.步骤s33,遍历数据集d4中的每一行数据,将该行数据的文本内容值解析得到xml树,包括如下步骤:
72.步骤s331,通过深度优先遍历dfs方式递归遍历xml树的所有非叶节点;
73.步骤s332,对每个节点判断其所有属性值,是否存在标准文本名称集合中,若存在,则将(文本名称,名称xpath,名称取值xpath)添加到列表l1,终止遍历该节点的所有子节点,若不存在,则继续递归遍历该节点的子节点;
74.步骤s333,重复步骤s332,直到处理完所有节点。
75.步骤s34,对列表l1中的元素按(名称xpath,名称取值xpath)进行统计,取出现次数最多的(名称xpath,名称取值xpath)做嵌套解析的文本名称取值方式,记为x1。
76.步骤s35,遍历数据集d4中的每一行数据,将该行数据的文本内容值解析得到xml树,包括如下步骤:
77.步骤s351,由x1定位到xml树中的第一个元素节点,取该节点的所有兄弟叶节点,以兄弟叶节点的顺序遍历,将兄弟叶节点分为两类:名称节点、内容节点,分类的依据是判断节点文本值或属性值中是否存在标准文本名称字典中。
78.步骤s352,重复步骤s351,直到处理完所有节点。
79.步骤s36,分别对所有的名称节点、内容节点按照tag名称统计,分别取tag名称出现次数最多的节点做平铺名称节点、平铺内容节点。如果平铺名称节点与平铺内容节点tag一致,生成平铺解析的文本名称、文本内容定位及取值方式,记为x3。
80.步骤s37,根据x3文本内容取值方式,生成嵌套解析文本内容定位及取值方式,记为x2。
81.步骤s38,将x1和x2拼接在一起,得到嵌套解析的文本名称、文本内容定位及取值方式,与x3一并写入数据库中。
82.步骤s39,完成自动解析配置生成。
83.在本发明的实施例中,对数据集配置的解析器方式包括如下几种形式:
84.(1)平铺解析器;
85.(2)嵌套解析器;
86.(3)平铺解析器和嵌套解析器;
87.(4)不需要解析。
88.步骤s4,在配置完成后,解析电子病历数据,包括如下步骤:
89.步骤s41,从数据库中获取电子病历解析配置列表c1;
90.步骤s42,遍历数据集d2中的每一行数据,执行如下操作,得到数据集d3,包括如下步骤:
91.步骤s421,每行数据由配置列表c1中每个解析器处理。在本发明的实施例中,解析
器包括:平铺解析器和嵌套解析器。下面分别对每种解析器的处理逻辑说明如下:
92.步骤s4211,嵌套解析器,执行流程如下:
93.步骤s42111,初始化嵌套解析器,初始信息(名称xpath,名称取值xpath,内容xpath,内容取值xpath)从c1中获取;
94.步骤s42112,将行数据的文本内容解析成xml树;
95.步骤s42113,通过名称xpath查找xml树,得到所有名称节点;
96.步骤s42114,对每个名称节点根据名称取值xpath,获得名称值,再根据内容xpath、内容取值xpath,获得内容值,将(名称值,内容值)二元组添加到解析结果列表中;
97.步骤s42115,重复步骤s42114,直到处理完所有名称节点。
98.步骤s4212,平铺解析器,执行流程如下:
99.步骤s42121,初始化平铺解析器,初始信息(名称xpath,名称取值xpath,内容xpath,内容取值xpath)从c1中获取。
100.步骤s42122,将行数据的文本内容解析成xml树。
101.步骤s42123,通过名称xpath查找xml树,得到所有名称节点,记为s1;通过内容xpath查找xml树,得到所有内容节点,记为s2。
102.步骤s42124,顺序遍历名称节点的同级节点,并维护名称变量keyname和列表l,若当前节点在s1中,将keyname及拼接后的l作为已确定解析结果添加到解析结果列表中,更新keyname、置空l;若当前节点在s2中,通过内容取值xpath获取到当前节点的值,追加到l中。
103.步骤s42125,重复步骤s42121,,直到处理完所有同级节点。
104.步骤s422,合并每个解析器处理得到的结果列表,将结果列表添加到数据集d3中。
105.步骤s43,将数据集d3写入到csv文件中,至此解析完成。
106.本发明实施例的基于xml电子病历自动解析方法通过假设、统计方法相结合,自动解析xml电子病历,具有以下特点:应用范围广,能适用所有xml电子病历数据,通用性高;部署效率高,无需人工介入。
107.在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
108.本领域技术人员不难理解,本发明包括上述说明书的发明内容和具体实施方式部分以及附图所示出的各部分的任意组合,限于篇幅并为使说明书简明而没有将这些组合构成的各方案一一描述。凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
109.尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求及其等同限定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。