1.本发明涉及深度学习技术领域,尤其涉及一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法。
背景技术:
2.近年来,深度学习技术发展迅速,在计算机视觉(compupter vision)、自然语言处理(natural language processing)等领域取得了极大的成功。但是,深度学习模型在不断改进,提升准确率的同时,也带来了庞大的计算量和参数量,如目前最常用的骨干模型resnet50就有25.56m参数量,以及4.14g乘加操作计算量,这给深度学习模型的部署带来了很大的挑战,特别是面向资源有限的端侧设备。
3.为了能够降低模型的参数量和计算量,提高模型运行效率,模型压缩技术应运而生,主要包括低比特量化(low-bit quantization)、网络剪枝(network pruning)、知识蒸馏(knowledge distillation)等。低比特量化作为模型压缩技术中最直接也最有效的一种方式,被学术界和工业界广泛地研究和使用,其核心思想是将深度学习模型中32比特浮点(fp32)数据用更低比特的定点数据来表示,如int8、int4,不仅可以降低内存带宽,同时还能提高计算效率,降低功耗。
4.现有量化方法基本上可以分为两大类:均匀量化和非均匀量化,其中均匀量化是指将原始浮点数据按缩放系数统一地映射为均匀分布的整型数据,而非均匀量化主要指的是对数量化,也就是将浮点数据映射为2的幂指数。虽然均匀量化是目前研究比较充分、应用更加广泛的一种方式,但是其存在两个问题:一是浮点数据和整型数据的分布差异较大,不可以避免地会造成更大的量化误差;二是虽然均匀量化可以使深度学习模型中的浮点计算变为定点计算,但是仍然依赖大量的矩阵乘法操作,硬件资源消耗比较高。而普通的对数量化虽然可以将乘法转变成移位和加法,但是因其取值过于离散,不能很好地保证精度损失,所以目前没有大规模的使用。
5.在背景技术部分中公开的上述信息仅仅用于增强对本发明背景的理解,因此可能包含不构成本领域普通技术人员公知的现有技术的信息。
技术实现要素:
6.本发明的目的是提供一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法,为了实现上述目的,本发明提供如下技术方案:
7.本发明的一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法包括:
8.第一步骤,根据预定比特位宽构建整型数值集合v,位表示2的偶数幂,n=bit-m-1位表示2的奇数幂,剩下1位表示符号位,得到v
′
=
±
(2m 2n),其中,m=2k,k∈0,1,...,2
m-2,n=2k 1,k∈0,1,...,2
n-2;
9.第二步骤,将浮点数据根据量化系数映射为整型数据,t表示任意待量化的浮点张量,c表示所述浮点张量的动态范围:c=max(abs(t),求得缩放系数为:scale
t
=c/v
max
,量
化得到整型张量:其中,round()函数将输入数据取整到距离最近的v中的整型数值,clip()函数将输入数据截断在v
min
和v
max
之间;
10.第三步骤,将整型数据根据量化系数映射为离散的浮点数据,tq=t
int
*scale
t
,tq为经过量化再反量化后得到的用于近似浮点张量t的离散数据,用tq与t的均方误差表示量化误差:其中numel()函数返回输入的元素总数;
11.第四步骤,利用所述第一步骤至第三步骤实现低比特无乘法深度神经网络,卷积计算y=conv(w,x) b,其中,conv()表示卷积计算,x/y表示输入/输出浮点数据,w/b表示权重/偏置浮点参数,x/y/w/b进行量化和反量化得到离散数据,用来近似卷积计算:yq=conv(wq,xq) bq,所述近似卷积计算等价变换成纯整型卷积计算公式:并且将卷积计算中的输入数据与权重参数的乘法计算替换成移位操作和加法计算。
12.所述的一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法中,采集数据包括形成待量化的浮点模型及其训练集。
13.所述的一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法中,两个移位器和一个加法器替换一个乘法器以无乘法的卷积运算。
14.所述的一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法中,四个加法器替换一个乘法器以无乘法的卷积运算。
15.在上述技术方案中,本发明提供的一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法具有以下有益效果:本发明所述的一种基于奇偶性对数量化的无乘法深度神经网络模型压缩方法可以用成本较低的移位器和加法器替代了成本更高的乘法器。本方法不仅很好地解决传统均匀量化整型数据分布和浮点数据分布不一致的问题,还克服了普通对数量化数值分布太过离散表达能力较低的弊端,从而极大地降低了量化误差,提高了低bit神经网络的准确性。适用于深度神经网络中常见的卷积(convolution)和全连接(fully-connected)等依赖密集的矩阵乘法计算的算子。
附图说明
16.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
17.图1为本发明中基于奇偶性对数量化的无乘法深度神经网络模型压缩方法的resnet18第一层卷积的权重参数的浮点数据(a),以及使用均匀量化(b)、对数量化(c),还有本发明提出的eolq算法(d)量化的离散数据分布直方图;
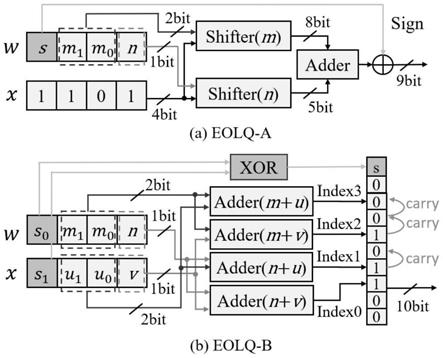
18.图2是本发明中基于奇偶性对数量化的无乘法深度神经网络模型压缩方法的用移位器和加法器替代乘法器的计算原理示意图。
具体实施方式
19.为使本发明实施方式的目的、技术方案和优点更加清楚,下面将结合本发明实施
方式对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
20.应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
21.为了使本领域的技术人员更好地理解本发明的技术方案,下面将结合附图对本发明作进一的详细介绍。如图1至图2,基于奇偶性对数量化的无乘法深度神经网络模型压缩方法包括,
22.首先根据预定比特位宽(bit)构建整型数值集合v,用位表示2的偶数幂,n=bit-m-1位表示2的奇数幂,剩下1位表示符号位,得到v=
±
(2m 2n),其中,m=2k,k∈0,1,...,2
m-2,n=2k 1,k∈0,1,...,2
n-2。令也就是m或n位全为1时表示数值0。可以得到v的最小值和最大值分别为:
23.例如b=5,m=2,n=2,那么有:
24.v=
±
{0,1,2,3,4,6,8,9,12,16,18,24,32,33,36,48},
25.例如b=4,m=2,n=1,那么有:
26.v=
±
{0,1,2,3,4,6,16,18}。
27.将浮点数据根据量化系数映射为整型数据,t表示任意待量化的浮点张量,c表示该浮点张量的动态范围:c=max(abs(t),可以求得缩放系数为:scale
t
=c/v
max
,量化得到整型张量:其中,round()函数将输入数据取整到距离最近的v中的整型数值,clip()函数将输入数据截断在v
min
和v
max
之间。
28.将整型数据根据量化系数映射为离散的浮点数据,tq=t
int
*scale
t
,tq为经过量化再反量化后得到的用于近似浮点张量t的离散数据,一般用tq与t的均方误差表示量化误差:其中numel()函数返回输入的元素总数。
29.利用上述量化方法实现低比特无乘法深度神经网络,以最常见的卷积计算为例:y=conv(w,x) b,其中,conv()表示卷积计算,x/y表示输入/输出浮点数据,w/b表示权重/偏置浮点参数,卷积计算可以更具体地表示为:用上述方法对x/y/w/b量化得到离散数据,用来近似卷积计算:yq=conv(wq,xq) bq,该近似计算等价于:y
int
*scaley=conv(w
int
*scalew,x
int
*scale
x
) b
int
*scalewscale
x
,然后变换成纯整型计算公式:并且可以将卷积计算中大量存在的输入数据与权重参数的乘法计算替换成移位操作和加法计算。假设w是w
int
的一个元素,x是x
int
的一个元素。如果我们将w量化为
±
(2m 2n),那么w*x可以用两次对x的移位和一次加法来实现,
30.w*x=
±
(2m 2n)*x=
±
(x<<m x<<n)
31.如果我们将x也量化为
±
(2u 2v),那么w*x可以用4次移位来实现,
32.w*x=
±
(2m 2n)(2u 2v)
33.=
±
(1<<(m u) 1<<(n u) 1<<(m v) 1<<(n v))。
34.一个实施例中,方法包括,
35.准备将要量化的浮点模型(如resnet18),及其在训练集(如imagenet)上训练完成的全精度参数。
36.根据分配给各参数的比特位数b构建整型数值集合v,然后量化参数。例如,我们想用5bit来表示resnet18第一层的权重参数,可以比较传统的均匀量化和对数量化以及本发明所提出的eolq量化算法之间的性能差异。如图1(a)是resnet18模型的第一层卷积层的权重参数的全精度浮点数据的分布直方图,可以看出浮点数据分布呈中部密集两端稀疏的特点;图1(b)是用传统的均匀量化后的离散数据的分布直方图,明显看到,由于均匀量化在数值表示范围内有着均匀一致的分辨率,与原始浮点数据的分布有着较大的差异,所以两端绝对值较大处的数值表示能力被浪费,而0附近稠密的数据不能得到更好的表示;图1(c)是用传统的对数量化得到的离散数据的分布直方图,由于对数量化只能用2的幂指数来表示数据,所以其取值过于离散,而且对原始浮点数据的分布造成了一定的畸变;图1(d)是本发明提出的eolq算法量化后的离散数据的分布直方图,整体上来看最大程度上还原了浮点数据的分布状态,保证信息不损失。另外定量分析的结果显示,本发明的量化损失eq也仅约为均匀量化的1/5,对数量化的约1/3。
37.得到量化后的数据后,即可用无乘法的整型运算替换原本依赖乘法的浮点运算。图2中表示了本发明提出的两种无乘法计算的原理图,图2(a)中eolq-a仅用两个移位器和一个加法器即可替换一个乘法器,图2(b)中eolq-b仅用四个加法器即可替换一个乘法器。为了验证本发明替换乘法器带来的硬件收益,我们将上述两种无乘法计算方案与传统的booth乘法器进行对比,从表1中的结果来看,eolq可以减少60%的资源占用和36%的功耗,同时也带来了1.7倍的速度提升。
38.表1:用乘法器和加法器替换乘法器的功耗、硬件资源占用、延时对比。
[0039][0040]
将本发明所提出的eolq量化算法应用在imagenet大规模分类任务上,量化resnet18/34/50等模型,对比其他经典算法结果。从表2中的实验结果可以看出,eolq算法的top-1和top-5准确率要明显高于大多数已有均匀量化和对数量化算法。
[0041]
表2:在imagenet分类任务上的量化结果
[0042][0043]
一个实施例中,方法中,首先根据预定比特位宽(bit)构建整型数值集合v:v=
±
(2m 2n),其中,m=2k,k∈0,1,...,2
m-2,n=2k 1,k∈0,1,...,2
n-2,n=bit-m-1;然后将浮点数据根据量化系数映射为整型数据,如用t表示任意待量化的全精度浮点张量,c表示该浮点张量的动态范围:c=max(abs(t),那么可以求得缩放系数为:scale
t
=c/v
max
,根据缩放系数将浮点数据量化到成低比特整型数据t
int
:其中,round()函数将输入数据取整到距离最近的v中的整型数值,clip()函数将输入数据截断在v
min
和v
max
之间;接着再反量化得到浮点离散数据tq:tq=t
int
*scale
t
,用于近似代替全精度浮点张量t,一般用tq与t的均方误差来表示量化误差:其中numel()函数返回输入数据的元素总数;最后,用上述量化方法构建低比特无乘法的深度神经网络,以最常见的卷积计算为例:y=conv(w,x) b,其中,conv()表示卷积计算,x/y表示输入/输出浮点数据,w/b表示权重/偏置浮点参数,对x/y/w/b进行量化和反量化得到离散数据,用来近似卷积计算:yq=conv(wq,xq) bq,该近似计算可以等价变换成纯整型卷积计算公式:并且可以将卷积计算中大量存在的输入数据与权重参数的乘法计算替换成移位操作和加法计算。
[0044]
最后应该说明的是:所描述的实施例仅是本技术一部分实施例,而不是全部的实施例,基于本技术中的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其它实施例,都属于本技术保护的范围。
[0045]
以上只通过说明的方式描述了本发明的某些示范性实施例,毋庸置疑,对于本领
域的普通技术人员,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式对所描述的实施例进行修正。因此,上述附图和描述在本质上是说明性的,不应理解为对本发明权利要求保护范围的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。