1.本发明涉及一种基于深度学习的大跨度网壳结构形态创建方法。
背景技术:
2.随着人们对建筑美学的不断追求、结构设计技术不断提高、计算机性能的日益完善,近年来越来越多的大跨度网壳结构被应用于实际工程中。在进行大跨度网壳结构设计时,不仅要追求建筑形式多样化,同时也要实现力学性能的合理性。因为大跨度网壳结构不再局限于传统规则形状,开始向“自由曲面”方向发展,而“自由曲面”是一种无法用解析公式描述的曲面结构,所以大跨度网壳结构形态设计有很大的挑战。
3.目前已有国内外学者对大跨度网壳结构形态创建与力学性能优化进行了研究,但因影响大跨度网壳结构形态的变量较多,数据处理繁琐庞大,使大跨度网壳结构形态创建效率较低,且存在计算结果精度无法保证的问题,而深度学习对复杂的非线性数据具有很强的分析和拟合能力,能提高大跨度网壳结构形态优化效率和精度,实现大跨度网壳结构形态多样性和结构受力合理性有机结合。深度学习可预测大跨度网壳结构应变能、承载力和稳定性,无需建立模型,可由数据直接计算,减少工作量,提高工程效率。
技术实现要素:
4.针对上述技术问题,本发明提出一种基于深度学习的大跨度网壳结构形态创建方法,该方法基于多层神经网络的深度学习,发掘自由曲面控制点几何特征变量与结构应变能之间的映射关系,搭建适用拟合结构应变能最小的大跨度网壳结构的深度学习网络模型,能快速高效地分析拟合自由曲面控制点几何特征变量与结构应变能之间的非线性关系。该方法结果准确、计算效率高,利用python编程语言和ansys有限元分析软件予以实现。
5.本发明为解决上述技术问题采用技术方案:
6.一种基于深度学习的大跨度网壳结构形态创建方法,步骤如下:
7.步骤1,特征参数初步筛选。搜集国内外文献资料,结合实际工程经验,初步筛选出可收集性强且对大跨度网壳结构应变能影响性较大的控制点几何特征变量,并根据可接受计算量大小和实际工程特征,控制点几何特征变量限定在合理的变量范围内,满足设计规范要求。
8.步骤2,建立深度神经网络的数据集。收集步骤1典型大跨度网壳结构模型的控制点几何特征变量和相应的大跨度网壳结构应变能数据,分别作为深度神经网络的输入特征和标签数据,将数据集80%的数据作为训练集,20%的数据作为测试集,数据集应涵盖工程设计中常见的大跨度网壳结构形式。
9.步骤3,搭建适用于大跨度网壳结构形态创建的深度学习网络模型。
10.步骤4,训练深度学习网络模型参数,即权重和偏置,在所有参数上用梯度下降,使深度学习网络模型在训练集上的损失函数最小,然后反向传播对所有参数更新推导。
11.步骤5,利用步骤4中的控制点几何特征变量预测模型预测得到的控制点几何特征
变量,采用nurbs技术进行大跨度网壳结构的几何建模,得到应变能最小的大跨度网壳结构。
12.步骤6,利用ansys有限元软件对创建的大跨度网壳结构力学性能分析,并对薄弱区加强,使其受力合理。
13.进一步,所述步骤2具体为:
14.(2-1)设计单个神经元,神经元的活性值x1,x2...xd为神经元的输入,d为控制点几何特征变量个数,w1,w2...wd为x1,x2...xd对应的权重,b是偏置,激活函数f(
·
)选用relu函数;
15.(2-2)基于(2-1)中的神经元,设计深度前馈神经网络模型,包括输入层、隐藏层和输出层;
16.所述深度前馈神经网络模型通过以下公式进行信息传播:
17.a
(k)
=fk(w
(k)
·a(k-1)
b
(k)
)
18.其中,k=1,2
…
,l,l表示深度前馈神经网络模型的层数;z
(k)
表示第k层神经元的净输入,即净活性值;w
(k)
表示第k-1层到第k层的权重矩阵;a
(k-1)
表示第k-1层神经元的输出,即活性值;b
(k)
表示第k-1层到第k层的偏置;a
(k)
表示第k层神经元的输出,即活性值;fk(
·
)表示第k层神经元的激活函数;
19.(2-3)自定义损失函数为:
[0020][0021]
其中,表示自定义损失函数,x表示控制点几何特征变量,y表示控制点几何特征变量x对应的大跨度网壳结构应变能,表示x对应的大跨度网壳结构应变能的预测值。
[0022]
进一步,所述步骤4中,在训练时,对误差进行反向传播,并采用梯度下降的方法使得权重和偏置沿着误差减小的方向进行更新:
[0023]
第一步,前馈计算每一层的净输入和活性值,直到最后一层;
[0024]
第二步,反向传播计算每一层的误差项,其中第k层的误差项为:
[0025]
δ
(k)
=f
′k(z
(k)
)
⊙
((w
(k 1)
)
t
·
δ
(k 1)
)
[0026]
式中,δ
(k)
表示第k层的误差项,δ
(k 1)
表示第k 1层的误差项,w
(k 1)
表示第k 1层的权重矩阵,(
·
)
′
表示求导,
⊙
表示向量的点积运算;
[0027]
第三步,计算每一层参数的梯度,并更新参数,所述参数包括权重和偏置;其中关于w
(k)
的梯度为关于b
(k)
的梯度为
[0028]
本发明与现有技术相比,其显著特点在于:
[0029]
1.影响大跨度网壳结构力学性能优化设计的变量较多,但现有的技术在大跨度网壳结构形态创建时考虑的影响变量具有一定的片面性,只针对某一特定的变量,而深度学习适用于拟合大跨度网壳结构控制点几何特征多个变量与结构应变能的非线性复杂关系,
具有较强数值拟合能力;
[0030]
2.现有的技术在大跨度网壳结构形态创建和力学性能优化时,设计者需自己操作编程、设计计算,工作量大且存在一定的误差,而深度学习具备很强的自我学习能力,减小优化目标的误差,实现大跨度网壳结构形态创建和力学性能优化的效率和精度;
[0031]
3.深度学习能在短时间内分析大量大跨度网壳结构形态创建数据,精确判断变量与优化目标的关系,并找到最佳的大跨度网壳结构形态,使结构造型美观,受力合理;
[0032]
4.对深度学习网络模型部分修改,现有深度学习网络模型常用的损失函数有均方误差、交叉熵等,这些损失函数使用时有部分缺点,且在大跨度网壳结构形态创建和力学性能优化时具有一定的局限性,所以本发明根据大跨度网壳结构形态创建和力学性能优化的实际情况自定义了损失函数,自定义损失函数与已有损失函数相比更合理;
[0033]
5.深度学习可预测大跨度网壳结构应变能、承载力和稳定性,无需建立模型,可由数据直接计算,减少工作量,提高工程效率。
附图说明
[0034]
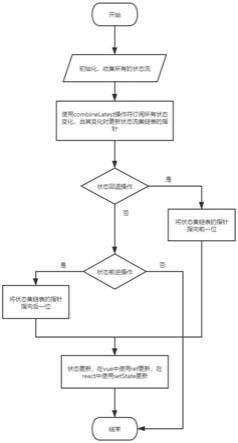
图1为基于深度学习的大跨度网壳结构形态创建和力学性能分析流程图;
[0035]
图2为单个神经元结构示意图;
[0036]
图3为前馈神经网络示意图;
[0037]
图4为大跨度柱面网壳结构网格划分和约束布置;
[0038]
图5为基于深度学习的大跨度柱面网壳结构创建结果。
[0039]
具体实施方法
[0040]
下面结合附图以及具体实施例对本发明的技术方案作进一步阐述。
[0041]
本发明一种基于深度学习的大跨度网壳结构形态创建和力学性能分析方法,如图1所示,具体步骤如下:
[0042]
步骤1,特征参数初步筛选。
[0043]
大跨度网壳结构形态优化的问题可用下式表达:
[0044][0045]
其中,x为大跨度网壳结构控制点几何特征变量;y(x)为输出层目标函数,本发明中为大跨度网壳结构应变能;s为大跨度网壳结构形状;ω0为设计允许的调整空间,根据建筑意图、实际环境、设备材料等各种因素满足s、ω0的关系式;w
max
、σ
max
分别代表最大位移与最大应力;w0、σ0分别表示允许位移与允许应力,表示应力和变形条件。选择控制点几何特征变量,如高度、坐标等,控制点几何特征变量限定在合理的变量范围内。
[0046]
步骤2,收集步骤1典型大跨度网壳结构模型的控制点几何特征变量和相应的大跨度网壳结构应变能数据,为避免神经网络由于过拟合导致泛化能力不足,从而影响预测精度,收集试验数据时,应保证选取的控制点几何特征变量和大跨度网壳结构应变能在合理范围内,控制在工程设计应用常见的范围内,建立深度神经网络的数据集。将数据集80%的
数据作为训练集,训练深度学习网络模型,20%的数据作为测试集,检测搭建的深度学习网络模型的准确性。
[0047]
步骤3,搭建适用于大跨度网壳结构形态优化的深度网络模型,本发明选择深度前馈网络模型。
[0048]
(3-1)设计单个神经元
[0049]
神经元是构成神经网络的基本单元,其主要是模拟生物神经元的结构和特性,接受一组输入信号并产出输出。
[0050]
假设单个神经元接受控制点几何特征变量输入x1,x2...xd,d由控制点几何特征变量个数决定。令向量x=[x1,x2...xd]来表示这组输入,并用净输入z∈r表示一个神经元所获得的输入信号x的加权和:
[0051][0052]
其中w=[w1,w2...wd]
t
∈rd是d维的权重向量,b∈r是偏置。
[0053]
净输入z在经过一个非线性函数f(
·
)后,得到神经元的活性值a,
[0054][0055]
其中非线性函数f(
·
)为激活函数。
[0056]
构建单个神经元结构如图2所示。
[0057]
激活函数在神经元中非常重要的。为了增强网络的表示能力和学习能力,激活函数为连续并可导的非线性函数。激活函数及其导函数要尽可能的简单,利于提高网络计算效率。激活函数的导函数的值域要在一个合适的区间内,确保训练的效率和稳定性。综合考虑以上因素,选用f(
·
)激活函数选用relu函数,定义为:
[0058][0059]
采用relu的神经元只需要进行加、乘和比较的操作,计算上更加高效。会处于激活状态。在x》0时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
[0060]
(3-2)设计神经网络架构
[0061]
单个神经元是远远不够的,需要通过很多神经元一起协作实现大跨度网壳结构应变能最小的优化目标。前馈神经网络由各神经元组成不同的层。每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层。第0层为输入层,最后一层为输出层,其它中间层为做隐藏层。
[0062]
本发明采用前馈网络能通过简单非线性函数的多次复合,实现大跨度网壳结构输入层几何特征变量到输出层结构应变能的复杂映射。这种网络结构简单,易于实现。
[0063]
前馈神经网络涉及到的参数含义如下:
[0064]
l:表示神经网络的层数;
[0065]m(k)
:表示第k层神经元的个数;
[0066]fk
(
·
):表示第k层神经元的激活函数;
[0067]
表示k-1层到第k层的权重矩阵;
[0068]
表示k-1层到第k层的偏置;
[0069]
表示第k层神经元的净输入(净活性值);
[0070]
表示第k层神经元的输出(活性值)。
[0071]
如图3所示的前馈神经网络通过以下公式进行信息传播:
[0072]z(k)
=w
(k)
·a(k-1)
b
(k)
[0073]a(k)
=fk(z
(k)
)
[0074]a(k)
=fk(w
(k)
·a(k-1)
b
(k)
)
[0075]
整个网络可以看作一个复合函数将向量x作为第1层的输入a
(0)
,将第l层的输出a
(l)
作为整个函数的输出:
[0076][0077]
其中w,b表示网络中所有层的连接权重和偏置。
[0078]
(3-3)自定义损失函数
[0079]
损失函数表示神经网络的预测值与实际值之间的误差,在训练神经网络时,通过网络中参数学习,使损失函数不断减小,从而得到准确率更高的深度学习网络模型,拟合数值非线性复杂关系。
[0080]
给定一个训练样本(x,y),先利用多层前馈神经网络将x映射到φ(x),然后再将φ(x)输入到分类器g(
·
)。当网壳结构应变能预测值等于网壳结构应变能的实际值时
[0081][0082]
其中g(
·
)为线性或非线性的分类器θ为分类器g(
·
)的参数,y为分类器的输出,为网壳结构应变能的实际值,x为控制点几何特征变量。
[0083]
当预测值和实际值存在误差时,当预测值和实际值存在误差时,为分类器的输出,即网壳结构应变能的预测值,x0为x附近的值。应变能y在控制点几何特征变量x0附近进行泰勒展开可得引入自定义损失函数,对于样本(x,y),因为x-x0是很小的值,可以不考虑高阶项。其自定义损失函数为
[0084][0085]
矩阵形式
[0086][0087]
为自定义损失函数,为网壳结构应变能实际值与预测值的差值的绝对值。
[0088]
深度学习网络模型通过不断参数学习,找到所有合适的参数权数w和偏置b,使损
失函数不断最小,从而得到更高准确率的深度学习网络模型。
[0089]
(3-4)反向传播误差
[0090]
为了使得误差最小化,对误差进行反向传播,计算每一个控制点输入值、权重和偏置对于误差的敏感度大小,并采用梯度下降的方法让权重和偏置沿着误差减小的方向进行更新。
[0091]
对第k层中的参数w
(k)
和b
(k)
计算偏导数。因为的计算涉及向量对矩阵的微分,十分繁琐,因此先计算关于参数矩阵中每个元素的偏导数则
[0092][0093]
只需要计算三个偏导数,分别为和
[0094]
计算偏导数因为z
(k)
=w
(k)
·a(k-1)
b
(k)
,所以偏导数
[0095][0096]
其中为权重矩阵w
(k)
的第i行,表示第i个元素为其余为0的行向量。表示第k-1层的第j个元素到第k层第i个元素连接的权重;表示第k层第i个元素的偏置。
[0097]
因为z
(k)
和b
(k)
的函数关系为z
(k)
=w
(k)
·a(k-1)
b
(k)
,因此偏导数为单位矩阵,
[0098][0099]
是m
(k)
×m(k)
的单位矩阵,m
(k)
表示k层神经元共m个。
[0100]
计算误差项首先引入中间量δ
(k)
定义第k层神经元的误差项,
[0101]
[0102]
误差项δ
(k)
来表示第k层神经元对最终损失的影响,反映了最终损失对第k层神经元的敏感程度,也间接反映了不同神经元对网络能力的贡献程度。
[0103]
根据z
(k 1)
=w
(k 1)
·a(k)
b
(k 1)
,有
[0104][0105]
又因为a
(k)
=fk(z
(k)
)因此有
[0106][0107]
则第k层的误差项为
[0108][0109]
其中
⊙
是向量的点积运算符号,表示每个元素相乘。第k层的误差项可以通过第k 1层的误差项计算得到,实现反向传播。其含义是:第k层的一个神经元的误差项是所有与该神经元相连的第k 1层的神经元的误差项的权重和,然后再乘上该神经元激活函数的梯度。
[0110]
在计算三个偏导数和后,可以得到
[0111][0112]
关于第k层权重w
(k)
的梯度为
[0113][0114]
关于第k层偏置b
(k)
的梯度为
[0115][0116]
计算出每一层的误差项之后,就可以得到每一层参数的梯度。
[0117]
整个反向传播分为三步:
[0118]
第一步,前馈计算每一层的净输入z
(k)
和激活值a
(k)
,直到最后一层;
[0119]
第二步,反向传播计算每一层的误差项δ
(k)
;
[0120]
第三步,计算每一层参数的偏导数,并更新参数。
[0121]
(3-5)权重梯度下降
[0122]
(3-4)得到权重及偏置对于误差的影响敏感度以后,就可以对权重采用梯度下降法进行更新,来实现训练学习的效果。所谓梯度下降,即沿着误差负梯度方向对权重进行更
新,以达到降低标签值与计算值之间误差的目的。本发明采用小批量梯度下降,每次迭代以一定的学习率沿着梯度下降,能使权重沿着误差负梯度较大的方向进行更新,具有一定跃迁能力,同时能提高收敛成功率。η为学习率,n为某批次中训练集数量,对每个训练样本x,则梯度下降法对权重和偏置的更新过程为
[0123][0124][0125]
(3-6)深度前馈网络设计
[0126]
本发明使用tensorflow框架对深度神经网络进行建模。tensorflow深度学习框架集成了大量机器学习方面的算法,特别在数据量充足且对自动化要求较高的应用场景中,具有良好的性能。
[0127]
深度前馈网络设计容包含输入输出层节点数、隐藏层数及节点数、激活函数等。深度前馈网络的输入层及输出层的节点数与输入向量及输出向量相匹配。为了唯一确定深度神经网络的规模,还需要进一步训练,确定隐藏层的数量以及每个隐藏层的节点数。
[0128]
隐藏层数越多,隐藏层节点数越多,对训练数据的拟合效果越好,但是同时会引起过拟合的问题,所谓过拟合,随着训练过程的进行,模型复杂度增加,在训练集上的误差渐渐减小,但是在测试集上的误差却反而渐渐增大。隐藏层数及隐藏层节点数过少,又使得深度神经网络非线性表达能力欠缺,导致欠拟合的情况。因此,需要建立不同神经网络模型进行对比分析,以求确定较为合适的隐藏层数及隐藏层节点数。
[0129]
在训练时,隐藏层从一两层开始尝试,尽量不要使用太多的层数,搭配适当的激活函数,选择激活函数时靠训练比较预测与实际的结果。常用的激励函数有:relu和sigmoid,但sigmoid在深度学习中的传播梯度较差,所以本发明采用relu作为激活函数,同时不能不考虑训练结果而直接堆砌多层神经网络,应尝试迁移和微调目前建立的预训练模型。
[0130]
神经元数量通常根据以下几个原则大致确定:由于输入输出层神经元个数,以及问题的复杂度和激活函数等都可能影响隐含层节点数的确定,使隐藏层神经元个数确定有了更多的不确定性。隐藏层神经元数量的范围区间的端点值分别为和log2p,p为输入层神经元个数,q为输出层神经元个数,h为[1,10]之间的常数。
[0131]
隐藏层神经元是最佳数量需要自己通过不断试验获得,由上述确定的范围,从最小神经元个数开始训练网络,逐个增加,验证到最大神经元个数,如果过拟合就减小层数和神经元。
[0132]
步骤4,训练深度学习网络模型参数,即权重和偏置,在所有参数上用梯度下降,使深度学习网络模型在训练集上的损失函数最小,然后反向传播对所有参数更新推导。
[0133]
在实际训练过程中,只有训练集数据会被用于深度前馈网络的训练,验证集数据用于反映模型训练效果,测试集数据用于测试模型泛化能力和评估模型预测结果的精度。每当所有训练集数据被完整地在模型中传递一次,称为一轮训练。
[0134]
评估模型训练的效果,计算预测结果与实际结果的损失函数,对训练集的预测结果进行误差分析。随后,采用测试集数据对训练好的模型进行验证,分析测试集预测结果与实际结果之间的误差。
[0135]
步骤5,根据深度学习网络模型确定的控制点几何特征变量,由工程经验,建筑规范和工程实际条件,确定控制点几何特征变量的初始值范围,在此范围内采用二分法,选取两端点作为控制点几何特征变量初始值输入预测模型,得到对应的结构应变能,选取靠近对应结构应变能较小的端点的一半范围为新的范围,再次采用二分法,直至新的范围内两端点对应的结构应变能差值不超过设定阈值0.5%,实现收敛,达到结构应变能最小的目的,此时的控制点几何特征数值输入到nurbs方法创建的曲面,即为大跨度网壳结构最优形态,最后通过ansys有限元软件对优化后的大跨度网壳结构力学分析,并对薄弱区加强。
[0136]
下面,以单个大跨度柱面网壳结构形态优化工程为例:
[0137]
如图4所示,该结构平面投影为矩形,长度为80米,跨度为40米,杆件数为1584,节点个数为561,杆件长度在2.5米左右。有限元模型采用beam188单元,考虑杆件的弯矩与轴力。网壳材料为结构钢,弹性模量e=2.06
×
105mpa,泊松比v=0.3,密度为7850kg/m3;杆件截面形式为圆管,规格为φ168mm
×
6mm。曲面四周设支座且固接,节点为刚性连接,结构承受竖直向下均布荷1.6kn/m2(含自重)。以控制点的纵坐标为控制点几何特征变量,以结构应变能最小为优化目标,通过调整控制点的竖向高度进行形状优化。根据《空间网壳结构技术规程》,沿两纵向边支承的圆柱面网壳,壳体的矢高可取跨度的1/2~1/5,所以矢高的范围可以取5米~8米。
[0138]
采用二分法,取控制点2、5、8、11、14纵坐标的初始值z=5、8米,其他控制点坐标始终保持为0,将5、8米代入训练好的深度前馈网络模型,比较得到的结构应变能大小,较小结构应变能对应的是8米,取6.5米~8米为新的范围,将6.5、8米代入训练好的深度前馈网络模型,重复之前的操作,直至新的范围两端点对应的结构应变能差值不超过设定阈值0.5%。此时新的范围为7.368米和7.370米,整体应变能从最大的1889.60knm下降到37.08knm,下降了98.04%。
[0139]
最后,取控制点2、5、8、11、14纵坐标值为7.369m,其他控制点坐标始终保持为0m,采用nurbs技术创建曲面作为大跨度柱面网壳结构,如图5所示。
[0140]
本发明方案所公开的技术手段不仅限于上述技术手段所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。
[0141]
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。