1.本发明涉及信息处理装置、信息处理系统以及信息处理方法。
背景技术:
2.通过机器学习而构建的学习模型例如用于执行推测与数据建立对应的标签的分类任务等。在日本特开2019-3568号公报中记载了学习模型的构建的步骤。在该步骤中,通过对处理对象数据进行预处理,将处理对象数据转换为由处理服务器装置容易处理的数据形式。接着,通过进行数据处理,处理对象数据被分割成模型构建用数据集和模型验证用数据集。
3.接着,通过使用模型构建用数据集来执行机器学习算法,从而获取学习结果。然后,使用模型验证用数据集来评价获取到的学习结果。通过重复执行机器学习算法直到学习结果的评价值大于规定的阈值为止,从而构建学习模型。
4.构建的学习模型的结构因使用的机器学习算法不同而不同。另外,标签的推测的精度因输入处理对象数据的学习模型的结构不同而不同。因此,优选构建结构不同的多个学习模型,从构建的多个学习模型中选出适合处理对象数据的处理的学习模型。然而,构建多个学习模型需要较长时间。因此,期待高效地构建学习模型。
技术实现要素:
5.本发明的目的在于,提供一种能够高效地构建学习模型的信息处理装置、信息处理系统以及信息处理方法。
6.(1)本发明的一方面的信息处理装置,具有:获取部,获取表示解释变量与目标变量的关系的学习用数据;层级决定部,在由获取部获取到的学习用数据中,决定目标变量所含的多个项目的层级关系;算法决定部,基于由层级决定部决定的层级关系,决定用于构成学习模型的多个构建算法中应该执行的构建算法;以及学习部,通过执行由算法决定部决定的构建算法,从而构建第一学习模型。
7.在该信息处理装置中,通过执行基于学习用数据的目的变量所含的多个项目的层级关系而决定的构建算法,从而进行学习用数据的学习,构建第一学习模型。在该情况下,无需执行多个构建算法的全部,而且不执行不必要的构建算法。由此,能够高效地构建第一学习模型。
8.(2)多个构建算法的每个包括:用于从学习用数据提取特征量的特征量提取算法、以及用于基于学习用数据进行学习的学习算法,算法决定部也可以通过基于由层级决定部决定的层级关系决定多个构建算法中的多个学习算法中应该执行的学习算法,从而决定应该执行的构建算法。在该情况下,能够容易地决定应该执行的构建算法。
9.(3)层级决定部也可以基于学习用数据中的多个项目的包含关系,自动地决定层级关系。在该情况下,能够降低使用者的负担。
10.(4)层级决定部也可以通过接受层级关系的指定或编辑,从而决定层级关系。在该
情况下,能够更准确地决定层级关系。
11.(5)信息处理装置也可以还具有预测部,该预测部使用用于预测处理时间的第二学习模型,预测与所决定的构建算法对应的第一学习模型的构建所需的时间。在该情况下,使用者能够容易确认第一学习模型的构建所需的时间。
12.(6)信息处理装置也可以还具有更新部,当结束与所决定的构建算法对应的第一学习模型的构建时,更新部基于实际的经过时间更新第二学习模型。在该情况下,能够以更高的精度预测第一学习模型的构建所需的时间。
13.(7)本发明的另一方面的信息处理系统具有:本发明的一方面的信息处理装置、以及显示装置,该显示装置显示在信息处理装置中使用的学习用数据中的多个项目。在该信息处理系统中,使用者能够容易地确认学习用数据中的多个项目。
14.(8)显示装置也可以以能够编辑多个项目的层级关系的方式显示。在该情况下,能够更准确地决定层级关系。
15.(9)本发明的又一方面的信息处理方法,包括:获取表示解释变量与目标变量的关系的学习用数据的步骤;在获取到的学习用数据中,决定目标变量所含的多个项目的层级关系的步骤;基于所决定的层级关系,决定用于构建学习模型的多个构建算法中应该执行的构建算法的步骤;以及通过执行所决定的构建算法,从而构建第一学习模型的步骤。
16.根据该信息处理方法,通过执行基于学习用数据的目的变量所含的多个项目的层级关系而决定的构建算法,从而进行学习用数据的学习,构建第一学习模型。在该情况下,无需执行多个构建算法的全部,而且不执行不必要的构建算法。由此,能够高效地构建第一学习模型。
17.(10)多个构建算法的每个包括:用于从学习用数据提取特征量的特征量提取算法、以及用于基于学习用数据进行学习的学习算法,决定构建算法的步骤也可以包括,基于所决定的层级关系,通过决定多个构建算法中的多个学习算法中应该执行的学习算法,从而决定应该执行的构建算法。在该情况下,能够容易地决定应该执行的构建算法。
18.(11)决定层级关系的步骤也可以包括:基于学习用数据中的多个项目的包含关系,自动地决定层级关系。在该情况下,能够降低使用者的负担。
19.(12)决定层级关系的步骤也可以包括接受层级关系的指定或编辑。在该情况下,能够更准确地决定层级关系。
20.(13)信息处理方法也可以还包括:使用用于预测处理时间的第二学习模型,预测与所决定的构建算法对应的第一学习模型的构建所需的时间的步骤。在该情况下,使用者能够容易地确认第一学习模型的构建所需的时间。
21.(14)信息处理方法也可以还包括:当结束与所决定的构建算法对应的第一学习模型的构建时,基于实际的经过时间来更新第二学习模型的步骤。在该情况下,能够以更高的精度预测第一学习模型的构建所需的时间。
附图说明
22.图1是表示本发明的一个实施方式的信息处理系统的图。
23.图2是表示信息处理装置的结构的图。
24.图3是表示学习用数据的一例的图。
25.图4是图3的学习用数据的简图。
26.图5是表示层级关系指定画面的一例的图。
27.图6是表示算法画面的一例的图。
28.图7是表示学习开始画面的一例的图。
29.图8是表示基于图2的信息处理装置的模型构建处理的流程图。
30.图9是表示基于图2的信息处理装置的模型构建处理的流程图。
具体实施方式
31.(1)信息处理系统的结构
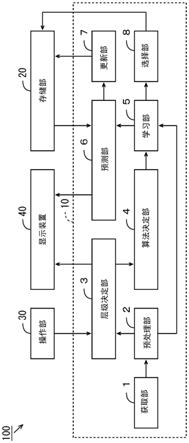
32.以下,使用附图对本发明的实施方式的信息处理装置、信息处理系统、以及信息处理方法进行说明。图1是表示本发明的一个实施方式的信息处理系统的结构的图。如图1所示,信息处理系统100由信息处理装置10、存储装置20、操作部30、以及显示装置40构成。信息处理装置10、存储装置20、操作部30、以及显示装置40与总线101连接。
33.信息处理装置10包括:cpu(中央运算处理装置)11、ram(随机存取存储器)12、以及rom(只读存储器)13。ram12用作cpu11的操作区域。rom13存储系统程序。信息处理装置10通过学习表示解释变量与目标变量之间的关系的学习用数据,从而构建用于根据解释变量来推测目标变量的标签的各种学习模型。关于信息处理装置10的细节将在后面说明。以下,将由信息处理装置10构建的学习模型称为推测模型。
34.存储装置20包括硬盘或半导体存储器等的存储介质,存储用于使信息处理装置10执行后述的构建处理的构建程序。构建程序也可以存储于rom13或其他的外部存储装置。存储装置20也可以存储由信息处理装置10构建的构建程序。另外,存储装置20预先存储用于预测基于信息处理装置10的处理时间的多个学习模型(以下称为预测模型)。
35.操作部30是键盘、鼠标或触摸面板等输入设备。使用者通过操作操作部30,在学习用数据中,能够指定或编辑目标变量所含的项目的层级关系。显示装置40是液晶显示装置等的显示设备,显示学习用数据中的多个项目等。
36.(2)信息处理装置的结构
37.图2是表示信息处理装置10的结构的图。如图2所示,信息处理装置10包括获取部1、预处理部2、层级决定部3、算法决定部4、学习部5、预测部6、更新部7、以及选择部8作为功能部。通过图1的cpu11执行存储于rom13或存储装置20等的构建程序,从而实现信息处理装置10的功能部。信息处理装置10的功能部的一部分或全部也可以由电子电路等的硬件来实现。
38.获取部1获取表示解释变量与目标变量的关系的多个学习用数据。预处理部2通过对由获取部1获取到的多个学习用数据进行预处理,将多个学习用数据转换为层级决定部3或学习部5可读取的形式。
39.层级决定部3决定由预处理部2预处理后的学习用数据中的目标变量所含的多个项目的层级关系。层级关系可以基于学习用数据中的多个项目的包含关系而自动地决定,也可以通过接受基于使用者的指定或编辑来决定。在层级关系被自动地决定的情况下,降低使用者的负担。另一方面,在显示装置40中,以能够编辑层级关系的方式显示学习用数据中的多个项目。使用者通过操作操作部30,能够指定或编辑项目的层级关系。在该情况下,
能够更准确地决定层级关系。
40.算法决定部4基于由层级决定部3决定的层级关系,决定用于构建推测模型的多个构建算法中应该执行的一个以上的构建算法。在此,多个构建算法中的每个包括:用于从学习用数据提取特征量的特征量提取算法、以及用于基于学习用数据进行学习的学习算法。
41.在本例中,基于由层级决定部3决定的层级关系,决定预定的多个学习算法中应该执行的一个以上的学习算法。应该执行的一个以上的构建算法通过预定的一个以上的特征量提取算法和应该执行的一个以上的学习算法的组合来决定。
42.学习部5通过依次执行由算法决定部4决定的一个以上的构建算法,从而学习由预处理部2进行了预处理的多个学习用数据。由此,构建一个以上的构建算法分别对应的一个以上的推测模型。在各推测模型的构建中,使参数变化并重复学习,以使参数达到最优。
43.预测部6在存储于存储装置20的多个预测模型中获取与由算法决定部4决定的构建算法对应的预测模型。另外,在执行各构建算法时,预测部6使用获取到的预测模型来预测与该构建算法对应的推测模型的构建所需的时间,使构建成推测模型为止的剩余时间显示于显示装置40。预测部6也可以与剩余时间一起或者代替剩余时间,使推测模型的构建的进度(%)显示于显示装置40。
44.需要说明的是,预测模型是将与学习相关的属性作为解释变量输入时以处理时间作为目标变量而输出的学习模型,由随机森林、svm(support vector machine)或深度学习等回归模型构建。作为解释变量的与学习相关的属性例如包括:学习用数据的容量、cpu11的核数、ram12的容量、用于参数最优化的学习重复次数、特征量提取算法的参数探索范围、以及学习算法的参数探索范围。
45.在本例中,每当用于参数最优化的学习重复被执行,预测时间被修正。修正后的预测时间t由下述式(1)表示。在式(1)中,t0是当前时间点的处理时间。n是当前时间点下用于参数最优化的学习执行次数。nm是当前时间点下用于参数最优化的学习重复的最大执行次数。
46.数式1
[0047][0048]
每当结束与由算法决定部4决定的构建算法对应的推测模型的构建时,更新部7基于实际的经过时间而更新存储于存储装置20的预测模型。在该情况下,能够以更高精度预测推测模型的构建所需的时间。在本例中,更新部7进一步基于构建算法的构建所用的与学习相关的属性来更新预测模型。选择部8从由学习部5构建的一个以上的推测模型中选择具有最高精度的推测模型。选择部8也可以将选择出的推测模型存储于存储装置20中。
[0049]
(3)层级关系的决定
[0050]
图3是表示学习用数据的一例的图。在图3的例子中,图示了“学习用数据1”~“学习用数据10”的10个学习用数据。在各学习用数据中,解释变量是“灾害状况”,目标变量包括“项目1”~“项目5”这五个项目。“项目1”~“项目5”分别是“行业大分类名”、“行业中分类名”、“行业小分类名”、“起因物大分类名”、以及“起因物中分类名”。
[0051]
在图3的例子中,“项目1”处于“项目2”的上位层级,“项目2”处于“项目3”的上位层级,“项目4”处于“项目5”的上位层级。另一方面,“项目1”、“项目2”和“项目3”与“项目4”和“项目5”不具有层级关系。多个项目间的层级关系的有无能够通过基于多个项目的包含关系的判定式来判定。在判定为在多个项目间存在层级关系的情况下,层级关系被自动地决定。
[0052]
用于判定“项目a”和“项目b”之间有无层级关系的判定式由下述式(2)表示。在式(2)中,n1是“项目a”的标签与“项目b”的标签的组合的总数。n2是成为“项目a”“项目b”的标签的组合的总数。α是表示判定的严格度的阈值,在比0大且比1小的范围内由使用者设定。在式(2)成立的情况下,在“项目a”与“项目b”之间存在层级关系,判定为“项目a”处于“项目b”的上位层级。
[0053]
数式2
[0054][0055]
以下,作为例子,对图3的“项目2”与“项目3”之间有无层级关系的判定进行说明。图4是图3的学习用数据的简图。在图4中,从图3的学习数据中仅提取“项目2”以及“项目3”。另外,为了容易理解,将各项目的标签简称“a”~“l”。在本例中,“项目2”的标签的数量是“a”~“e”这五个,“项目3”的标签的数量是“f”~“l”这七个。因此,“项目2”的标签和“项目3”的标签的组合的总数n1是5
×
7=35种。
[0056]
另外,成为“项目2”“项目3”的标签组合的总数n2为{“a”,“f”}、{“a”,“g”}、{“a”,“h”}、{“b”,“i”}、{“c”,“j”}、{“d”,“k”}以及{“e”,“l”}这7种。在该情况下,上述式(2)的左边的值为0.2。因此,在右边的阈值α设定为小于0.2的情况下,判定为在“项目2”与“项目3”之间存在层级关系,“项目2”处于“项目3”的上位层级。使用者通过操作图2的操作部30,能够编辑被判定的层级关系。
[0057]
另外,层级关系也可以不是自动地决定,而是通过使用者指定而决定。在图2的显示装置40上显示有用于接受层级关系的指定的层级关系指定画面。使用者通过使用图2的操作部30来操作层级关系指定画面,能够指定层级关系。
[0058]
图5是表示层级关系指定画面的一例的图。如图5所示,在层级关系指定画面50显示有开关51。在开关51关闭的情况下,不接受层级关系的指定。在开关51打开的情况下,与项目间的多个层级关系分别对应的多个复选框52进一步显示在层级关系指定画面50上。使用者通过勾选所期望的复选框52,从而能够指定与该复选框52对应的层级关系。
[0059]
另外,在接受了层级关系的指定的情况下,表示多个项目的层级关系的树状的结构图53进一步显示在层级关系指定画面50上。使用者通过操作结构图53,能够进一步编辑层级关系。在结构图53中,能够对每个层级在项目的显示与不显示之间进行切换。因此,在层级的数量较多的情况下,使用者通过不显示在结构图53中不需要的层级的项目,能够容易地识别所期望的项目的层级关系。
[0060]
(4)构建算法的决定
[0061]
在学习用数据中,通过决定层级关系,从而决定应该执行的一个以上的构建算法。具体而言,通过决定层级关系,从预定的多个学习算法中决定不需要执行的学习算法。因此,通过从预定的多个学习算法排除不需要执行的学习算法,从而决定应该执行的一个以上的学习算法。应该执行的一个以上的构建算法通过预定的一个以上的特征量提取算法与被决定的一个以上的学习算法的组合来决定。
[0062]
将可见地表示所决定的一个以上的构建算法的算法画面显示于图2的显示装置40。图6是表示算法画面的一例的图。如图6所示,算法画面60包括特征量提取算法显示栏61以及学习算法显示栏62。在特征量提取算法显示栏61上显示有与预定的多个特征量提取算法分别对应的多个复选框61a。预定的多个特征量提取算法包括:word2vec、bow(bag of words)、以及tf-idf(term frequency-inverse document frequency)。
[0063]
在学习算法显示栏62中显示有与预定的多个学习算法分别对应的多个复选框62a。预定的多个学习算法包括:mlp(multilayer perceptron)、rfc(random forest classifier)、swem nn(simple word-embedding-based methods neural network)、cnn(convolutional neural network)、lightgbm(light gradient boosting machine)以及svm。
[0064]
在算法画面60中,与应该执行的特征量提取算法(在本例中word2vec、bow、以及tf-idf)分别对应的复选框61a被勾选。另外,与应该执行的学习算法(在本例中mlp、swem nn、以及cnn)分别对应的复选框62a被勾选。使用者通过操作所期望的复选框61a、62a,能够变更应该执行的特征量提取算法或学习算法。
[0065]
复选框61a被勾选的特征量提取算法与复选框62a被勾选的学习算法的组合,表示为应该执行的一个以上的构建算法。由于swem nn包含用于从学习用数据提取特征量的算法,因此在执行swem nn的情况下,不使用特征量提取算法。因此,在图6的例子中,示出了3
×
2 1=7种构建算法。
[0066]
此外,在不进行上述的层级关系的决定的情况下,执行全部的特征量提取算法以及全部的学习算法。在该情况下,通过勾选全部的复选框61a、62a,示出了3
×
5 1=16种构建算法。
[0067]
在决定了构建算法之后,学习开始画面显示在显示装置40。图7是表示学习开始画面的一例的图。如图7所示,在学习开始画面70上显示有开始按钮71。另外,在学习开始画面70上显示有学习中的解释变量、目标变量、特征量提取算法、以及学习算法,并且显示有表示学习流程的图。使用者通过操作开始按钮71,能够指示学习的开始。
[0068]
(5)模型构建处理
[0069]
图8和图9是表示基于图2的信息处理装置10的模型构建处理的流程图。图8和图9的模型构建处理通过图1的cpu11在ram12上执行rom13或存储装置20等中存储的构建程序来进行。以下,使用图2的信息处理装置10以及图8和图9的流程图对模型构建处理进行说明。
[0070]
首先,获取部1获取多个学习用数据(步骤s1)。多个学习用数据可以从存储装置20中获取,也可以从外部的存储介质中获取。接着,预处理部2对在步骤s1中获取到的各学习用数据进行预处理(步骤s2)。接着,层级决定部3在步骤s2中预处理后的学习用数据中,基于式(2)来判定目标变量所含的多个项目间有无层级关系(步骤s3)。在层级关系不被自动地决定的情况下,省略步骤s3。
[0071]
之后,层级决定部3判定是否指示了层级关系的指定或编辑(步骤s4)。在未指示层级关系的指定或编辑的情况下,层级决定部3进入步骤s6。使用者在图5的层级关系指定画面50中,能够指示层级关系的指定或编辑。在指示了层级关系的指定或编辑的情况下,层级决定部3基于指定或编辑变更层级关系(步骤s5),进入步骤s6。在步骤s6中,层级决定部3决
定层级关系(步骤s6)。
[0072]
接着,算法决定部4基于在步骤s6中所决定的层级关系,决定预定的多个学习算法中应该执行的一个以上的学习算法(步骤s7)。接下来,算法决定部4通过预定的一个以上的特征量提取算法与在步骤s7中所决定的一个以上的学习算法的组合,来决定应该执行的一个以上的构建算法(步骤s8)。在本例中,对所决定的n个(n是1以上的整数)构建算法分别标注1~n固有的识别号。
[0073]
然后,算法决定部4判定是否指示了学习的开始(步骤s9)。使用者通过在图7的学习开始画面70上操作开始按钮71,能够指示学习的开始。另一方面,使用者能够在不指示学习开始的情况下操作图6的算法画面60的复选框61a、62a。在该情况下,算法决定部4返回步骤s8,基于复选框61a、62a的操作内容再次决定构建算法。重复步骤s8、s9直到指示学习的开始为止。
[0074]
在指示了学习的开始的情况下,学习部5将表示构建算法的识别号的变量i的值设定为1(步骤s10)。接着,学习部5选择第i号的构建算法(步骤s11)。接下来,预测部6使用与在步骤s11中所决定的构建算法对应的预测模型,预测与该构建算法对应的推测模型的构建所需要的时间(步骤s12)。然后,预测部6基于在步骤s12中预测的时间或后述的步骤s17中修正的预测时间,使构建成推测模型为止的剩余时间显示于显示装置40(步骤s13)。
[0075]
之后,学习部5通过执行在步骤s11中选择的构建算法,从而学习在步骤s2中进行了预处理的多个学习用数据(步骤s14)。由此,构建与所选择的构建算法对应的推测模型。接着,学习部5判定参数最优化是否结束了(步骤s15)。
[0076]
在参数的最优化未结束的情况下,学习部5变更参数(步骤s16)。另外,预测部6基于式(1)来修正预测时间(步骤s17),返回步骤s13。在预定的学习重复的最大执行次数的范围内,重复步骤s13~s17,直到结束参数的最优化为止。
[0077]
在结束了参数的最优化的情况下,更新部7基于实际的经过时间以及与学习相关的属性来更新存储于存储装置20中的预测模型(步骤s18)。接下来,学习部5判定变量i的值是否为n(步骤s19)。在变量i的值不是n的情况下,学习部5将变量i的值增加1(步骤s20),返回步骤s11。重复步骤s11~s20,直到变量i的值成为n为止。
[0078]
在变量i的值是n的情况下,选择部8从由步骤s14的学习构建的n个推测模型中,选择具有最高精度的推测模型(步骤s21),结束模型构建处理。选择部8也可以将在步骤s21中所选择的推测模型存储于存储装置20。
[0079]
(6)效果
[0080]
在本实施方式的信息处理装置10中,通过执行基于学习用数据的目标变量中所含的多个项目的层级关系而决定的构建算法,从而进行学习用数据的学习,构建推测模型。在该情况下,无需执行多个构建算法的全部,而且不执行不必要的构建算法。另外,防止进行对于不可能的层级关系的学习。由此,能够提高学习的精度,并且高效地构建推测模型。
[0081]
另外,使用预测模型,预测与所决定的构建算法对应的推测模型的构建所需的时间。根据该结构,即使在与学习相关的属性与处理时间的关系为非线性的情况下,能够预测推测模型的构建所需的时间。因此,使用者能够容易地确认推测模型的构建所需的时间。
[0082]
进而,每次执行用于参数最优化的学习重复时,基于实际的经过时间修正预测时间。因此,能够以更高的精度来预测推测模型的构建所需的时间。其结果是,能够更准确地
进行信息处理装置10的管理以及推测模型的构建的规划。
[0083]
(7)其他实施方式
[0084]
(a)在上述实施方式中,当结束各推测模型的构建时,基于实际的经过时间更新预测模型,但实施方式并不限定于此。预测模型也可以不被更新。在该情况下,信息处理装置10也可以不包括更新部7。
[0085]
(b)在上述实施方式中,预测推测模型的构建所需的时间,但实施方式并不限定于此。推测模型的构建所需的时间也可以不被预测。在该情况下,信息处理装置10可以不包括预测部6以及更新部7,也可以不在存储装置20中存储预测模型。
[0086]
(c)在上述实施方式中,信息处理装置10包括选择部8,但实施方式并不限定于此。在由学习部5构建的多个推测模型存储于存储装置20中的情况下,或者在仅构建一个推测模型的情况下等,信息处理装置10也可以不包括选择部8。
[0087]
(8)权利要求的各结构要素与实施方式的各部的对应关系
[0088]
以下,对权利要求的各结构要素与实施方式的各要素的对应的例子进行说明,本发明并不限定于下述的例子。作为权利要求的各结构要素,能够使用具有权利要求所记载的结构或功能的其他各种要素。
[0089]
在上述实施方式中,获取部1是获取部的例子,层级决定部3是层级决定部的例子,算法决定部4是算法决定部的例子,学习部5是学习部的例子。信息处理装置10是信息处理装置的例子,预测部6是预测部的例子,更新部7是更新部的例子,显示装置40是显示装置的例子,信息处理系统100是信息处理系统的例子。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。