技术特征:
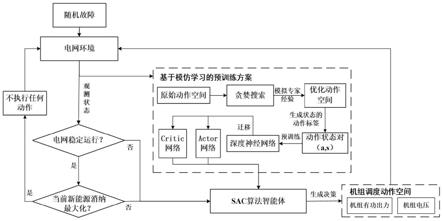
1.一种基于深度强化学习的电网实时自适应决策方法,其特征在于:包括如下步骤:步骤1、将新型电力系统机组自适应调度问题建模为马尔科夫决策过程;步骤2、研究sac算法的基础原理,包括其5个网络即策略actor网络、“软”v网络、2个“软”q网络、目标v网络的更新流程和更新公式,并在sac算法的基础上设计具体的算法参数及神经网络架构参数如折扣因子γ、温度系数α和网络宽度深度,求解使得步骤1中mdp模型累计奖励值最大的策略;步骤3、设计基于il中行为克隆的神经网络预训练方案,模拟专家经验,优化原始动作空间,提出il-sac算法,并基于il-sac算法以及105个真实电网场景数据训练相应的电网优化调度智能体,在测试时该智能体应对不同的电网场景数据能够输出实时决策方案,实现新型电网系统的智能调控。2.根据权利要求1所述的一种基于深度强化学习的电网实时自适应决策方法,其特征在于:所述步骤1的具体步骤包括:用4维元组描述(s,a,p,r),其中s表示该电网系统的状态集,a表示该电网系统的动作集,p:s
×
a
×
s
→
[0,1]表示状态转移概率,r:s
×
a
→
r表示奖励机制:(1-1)状态变量s在t时段的grid2op电网系统状态s
t
∈s如式(1)所示其中,n,j,k分别表示该电网系统中有n条电力传输线,j个发电机组节点,k个负载节点;分别表示第j个发电机组节点上的有功出力、无功出力以及电压大小;表示第m个新能源机组节点上下一时刻的有功出力上限预测值,m表示j个机组种有m个新能源机组,m<j;分别表示第k个负载节点上的有功需求、无功需求以及电压大小;表示第k个负载节点上下一时刻的有功需求预测值,以上变量都是可以通过grid2op电网系统仿真模型直接观测或调用的系统观测状态量;f
i
表示第i条电力传输线上的开断状态,是一个布尔值变量,当f
i
=1时表示传输线为断开状态,当f
i
=0时表示传输线为连接状态;rho
i
表示第i条电力传输线上的负载率;(1-2)动作变量a动作变量即系统可调整变量,t时刻该系统的动作变量a
t
∈a如式(2)所示
其中,x表示该电网系统有x个可控机组;表示第x个机组节点上的有功出力调节值;表示第x个机组节点上的电压调整值;由于机组的有功出力和电压皆是连续变化的动作,本发明欲将其离散化;设离散化的最小间隔分别为δ
dp
和δ
dv
,则,则其中,y,z都为整数;根据式(3)和(4),将动作变量a
t
离散化之后可以表示为(1-3)状态转移概率p状态转移概率表示给定当前状态s
t
∈s以及动作a
t
∈a,状态从s
t
变换到s
t 1
的概率值,可以表示为采用深度强化学习算法从历史数据中采样从而隐式学习得到该概率分布;(1-4)奖励机制r本发明设置了6个类型奖励r1,r2,r3,r4,r5,r6∈r,具体描述如下:1)根据输电线路越限情况设置奖励函数r1,其中,rho
max
表示n条传输线路上最大的rho值;2)根据新能源机组消纳总量设置正奖励函数r2,其中,表示新能源机组m当前时间步的实际有功出力,表示新能源机组m在当前
时间步的最大出力;3)根据平衡机组功率越限情况设置负奖励r3,,其中,u表示平衡机个数,表示平衡机u的实际有功出力,分别表示平衡机的出力的上下限;4)根据机组运行费用设置负奖励r4,其中,a
j
,b
j
,c
j
表示为对应不同机组的发电成本曲线系数;5)根据机组的无功出力越限情况设置负奖励r5,,其中,分别表示机组无功出力的上下限;6)根据机组节点和负载节点电压越限情况设置负奖励r6,,,
其中,分别表示各个发电机节点和负载节点电压的上下限;对上述奖励函数r4,r5,r6使用如下公式进行归一化处理r=e
r-1
ꢀꢀ
(17)综上所述,奖励函数r1的值域为(-1,1)、r1的值域为[0,1],r3,r4,r5,r6的域值为(-1,0),奖励函数r3属于该取值范围是由于该仿真环境中u=1;故t时时刻的整体奖励函数r
t
∈r如下所示r
t
=c1r1 c2r2 c3r3 c4r4 c
51
r5 c6r
61
ꢀꢀ
(18)其中,c
i
(i=1,2,..,6)表示各奖励函数的系数,本发明将各个系数具体取值为c2=4,c3=2,c1=c4=c5,=c6=1,该取值说明了本发明模型构过程中的奖励侧重点在于新能源消纳以及有功功率平衡。3.根据权利要求1所述的一种基于深度强化学习的电网实时自适应决策方法,其特征在于:所述步骤2的具体步骤包括:(2-1)sac算法最优策略的公式如下1)sac算法最优策略的公式如下其中,r(s
t
,a
t
)表示状态为s
t
时进行动作a
t
得到的奖励值;h(π(
·
|s
t
))表示状态为s
t
时控制策略π的熵值;表示当状态动作对(s
t
,a
t
)概率分布为ρ
π
时的期望奖励值;α表示鼓励新策略探索的程度,被称作温度系数;(2-2)sac算法在构造其值函数v
ψ
(s
t
)和q函数q
θ
(s
t
,a
t
)时,分别使用神经网络参数ψ和θ来表示;sac算法中使用了2个值函数,其中一个值函数称为“软”值函数,基于如下公式中的误差平方值可以来更新“软”值函数神经网络的权重其中,d表示先前采样状态的分布空间;表示对误差平方的期望值;表示控制策略π
φ
下控制动作a
t
的期望;下一步即可使用下式来计算式(21)中的概率梯度其中,表示对参数ψ求梯度;(2-3)同理,可通过最小化“软”贝尔曼残差的方式来更新“软”q函数的神经网络权重,计算公式如下计算公式如下其中,γ表示折扣因子;表示满足概率分布ρ的状态s
t 1
的期望值;而式(23)的优化求解与(21)同理可由下式中的概率梯度进行计算
其中,表示对参数θ求梯度;表示目标值函数网络,定期更新;(2-4)sac算法的控制策略输出值是由平均值和协方差组成的随机高斯分布表示出来的,通过最小化预期kullback-leibler(kl)偏差来更新其控制策略的神经网络参数,以φ作为参数的控制策略π的目标函数可以根据式(20)具体化为式(26)的优化求解过程可由下式中的概率梯度计算得出其中,表示对参数φ求梯度;表示对参数a
t
求梯度;ε
t
表示输入噪声向量,f
φ
(ε
t
,s
t
)表示神经网络变换,是对a
t
的重新参数化。4.根据权利要求1所述的一种基于深度强化学习的电网实时自适应决策方法,其特征在于:所述步骤3的具体步骤包括:(3-1)根据当前电网工况,在gird2op电网仿真环境中添加随机故障,以模拟实际运行情况,在该仿真环境进行过潮流计算之后,通过调用程序接口获取相应的观测状态空间;在该预训练方案中首先是一个模拟专家经验的过程,从电网仿真环境中采样大量场景即大量的观测状态空间作为输入量,在本发明中是105个场景作为输入量,然后在式(5)离散化之后的动作空间中基于贪婪算法贪婪搜索最优的动作,贪婪的最优指标是在保证各条传输线路上最大rho不超过100%的情况下使得式(8)中的新能源消纳率指标最大化,在进行贪婪算法之后能得到一个模拟的专家动作空间,相对于原始动作空间有所缩减;(3-2)模仿学习中行为克隆的过程,使用105个电网场景作为输入量,在专家动作空间中基于步骤(3-1)的贪婪优化准则贪婪搜索最优的动作,并将对应的电网场景状态与动作组合形成动作状态对(a,s),即给每一个状态找到一个较优的动作标签;最终应用该动作状态对设计好的深度神经网络进行监督学习预训练,并迁移至sac算法中的actor网络和critic网络中;(3-3)基于(3-2)中预训练的深度神经网络参数,构建il-sac算法为基础的电网调度智能体,使用105个真实电网场景数据作为智能体的输入,训练该智能体至算法参数收敛,最终将得到的电网调度智能体应用至真实电网场景数据下,能够实时输出电网调度相应的动作策略。
技术总结
本发明涉及一种基于深度强化学习的电网实时自适应决策方法,包括如下步骤:步骤1、将新型电力系统机组自适应调度问题建模为马尔科夫决策过程;步骤2、研究SAC算法的基础原理,求解使得步骤1中MDP模型累计奖励值最大的策略;步骤3、设计基于IL中行为克隆的神经网络预训练方案,模拟专家经验,优化原始动作空间,提出IL-SAC算法,并基于IL-SAC算法以及105个真实电网场景数据训练相应的电网优化调度智能体,在测试时该智能体应对不同的电网场景数据能够输出实时决策方案,实现新型电网系统的智能调控。本发明能够实时地输出电网调度策略。本发明能够实时地输出电网调度策略。本发明能够实时地输出电网调度策略。
技术研发人员:马世乾 陈建 商敬安 崇志强 王天昊 韩磊 吴彬 李昂 张志军 董佳 孙峤 郭凌旭 黄家凯 袁中琛 穆朝絮 韩枭赟 徐娜
受保护的技术使用者:国网天津市电力公司 国家电网有限公司
技术研发日:2021.11.18
技术公布日:2022/3/21
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。