1.本发明涉及一种神经网络的针对模型并行的动态负载均衡方法,属于深度学习模型并行技术领域。
背景技术:
2.如今的深度学习模型往往因为体量巨大而必须做并行化,分布式扩展技术可以有效的提高大规模数据的处理能力,目前深度学习分布式并行扩展模式主要包括数据并行、模型并行以及混合并行。
3.尽管数据并行应用最为广泛,但是对于某些模型参数太大,单个节点无法全部容纳的用例,就需要优先考虑模型并行的方法;模型并行模式的分布式训练将单个模型拆分到不同的节点上去,根据粒度的大小又分为将不同的网络层拆分到对应的节点,以及将同一层的不同参数切分到不同的节点中,并相应地实现不同节点间的中间输出的传递。
4.对于线性模型,可以将对应于不同数据维度的模型参数划分到不同的节点上,对于高度非线性的神经网络,各个工作节点不能相对独立地完成对自己负责的参数训练的更新,必须依赖与其他工作节点的协作,因此,需要寻找一个合适的切分方法才能以最小的代价实现。
5.当前主流的模型并行切分方法都是粗粒度的切分,仅仅将模型按照网络层划分分布到节点上,往往不能保证节点上的负载维持平衡。此外,由于模型的框架和系统的架构各不相同,应用模型并行时往往需要算法工程师手工确定,这意味着需要进行反复的优化才能寻找到最低代价的负载均衡切分方法。同时对于不同的模型和系统又要求算法工程师重新掌握,大大降低了优化效率。
技术实现要素:
6.本发明的目的是提供一种神经网络的针对模型并行的动态负载均衡方法,以解决神经网络模型中模型并行的切分问题。
7.为达到上述目的,本发明采用的技术方案是:提供一种神经网络的针对模型并行的动态负载均衡方法,根据不同的模型和系统的相应参数给出切分策略,并在训练过程中进一步迭代更新;根据不同的模型和系统的相应参数,给出对模型网络的切分策略,具体包括以下步骤:s1、基于模型类型、参数量、网络集群拓扑带宽和节点数信息构建代价模型,用于评估每个算子的输入、输出和运行所需的计算时间,还用于评估相邻算子以及算子内部存在的通信时间;s2、根据s1中得到的代价模型,为所有节点分配应计算的算子,具体步骤如下:s21、代价模型对当前系统中的所有可用的计算节点进行状态模拟,然后依次遍历代价模型的整个计算图,针对每个算子获得至少一个用于完成当前算子的可用节点作为计
算节点;s22、对于具有多个可用节点的算子,节点分配算法使用贪婪启发式算法来评估将其放置在每个可用节点上的预计完成时间,选取出预计最快完成当前算子的可用节点作为其映射的计算节点;s23、对于每个算子,重复s22,继续为其余算子分配计算节点,直至为计算图中的每个算子完成计算节点分配;在训练过程中进一步迭代更新,具体包括以下步骤:s3、训练前为每个计算节点分配一个权重参数,用来表示分配到的负载量,权重越大分配到的负载量越多,初始时各个节点的权重参数相等;s4、每轮训练时,首先根据上一步骤得到的当前节点的权重参数,通过代价模型找出所有计算节点的切分策略并开始训练,每个计算节点在计算完成后统计自身的等待时间;s5、一轮训练完后,根据s4中得到的各个计算节点的最大等待时间和平均等待时间,判断当前的负载均衡是否最优,如果是,则保持当前的切分策略继续训练,如果不是最优,将根据各个计算节点间的等待时间的比重,调整各自的权重,从而改变每个计算节点应当分配到的负载量,随后通过代价模型重新计算出切分策略并执行下一轮训练;s6、重复s4-s5直至在数次训练中不改变当前切分策略,即证明该切分策略在训练中动态达到最优。
8.上述技术方案中进一步改进的方案如下:1. 上述方案中,s21中,对于每个遍历到的算子,首先考虑其可用的节点列表,如果某个节点不提供当前算子的内核实现,那么当前设备对该算子就是不可用的。
9.2. 上述方案中,s22中,在评估过程中,贪婪启发式算法不仅考虑每个当前可用节点中等待执行的算子的预计完成时间,从而估算出当前算子的预计完成时间,还要考虑如果将算子放置在当前节点,那么将该算子的输入从其他节点传输过来的通信时间。
10.由于上述技术方案的运用,本发明与现有技术相比具有下列优点:本发明实现了通用的基于神经网络模型并行的动态负载均衡,当应用模型并行方法时,能够根据不同的模型和系统的相应参数自动给出较好的切分策略,无需手动调整模型,保证计算节点的负载均衡,大大提高了优化效率。
附图说明
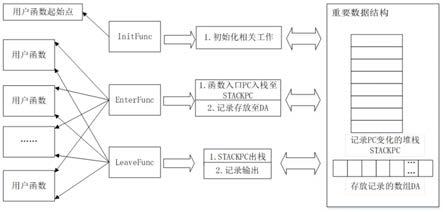
11.附图1 为现有技术中模型并行方法示意图。
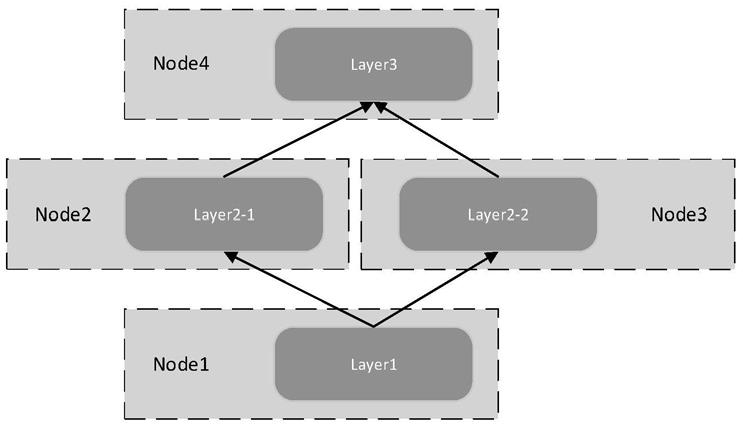
12.附图2为本发明一种针对模型并行的动态负载均衡方法的示意图。
具体实施方式
13.实施例:本发明提供一种神经网络的针对模型并行的动态负载均衡方法,根据不同的模型和系统的相应参数给出切分策略,并在训练过程中进一步迭代更新;根据不同的模型和系统的相应参数,给出对模型网络的切分策略,具体包括以下步骤:s1、基于模型类型、参数量、网络集群拓扑带宽和节点数信息构建代价模型,用于
评估每个算子的输入、输出和运行所需的计算时间,还用于评估相邻算子以及算子内部存在的通信时间;s2、根据s1中得到的代价模型,为所有节点分配应计算的算子,具体步骤如下:s21、代价模型对当前系统中的所有可用的计算节点进行状态模拟,然后依次遍历代价模型的整个计算图,针对每个算子获得至少一个用于完成当前算子的可用节点作为计算节点;s22、对于具有多个可用节点的算子,节点分配算法使用贪婪启发式算法来评估将其放置在每个可用节点上的预计完成时间,选取出预计最快完成当前算子的可用节点作为其映射的计算节点;s23、对于每个算子,重复s22,继续为其余算子分配计算节点,直至为计算图中的每个算子完成计算节点分配;在训练过程中进一步迭代更新,具体包括以下步骤:s3、训练前为每个计算节点分配一个权重参数,用来表示分配到的负载量,权重越大分配到的负载量越多,初始时各个节点的权重参数相等;s4、每轮训练时,首先根据上一步骤得到的当前节点的权重参数,通过代价模型找出所有计算节点的切分策略并开始训练(即计算图中算子的分配方案,s2步骤),每个计算节点在计算完成后统计自身的等待时间;s5、一轮训练完后,根据s4中得到的各个计算节点的最大等待时间和平均等待时间,判断当前的负载均衡是否最优,如果是,则保持当前的切分策略继续训练,如果不是最优,将根据各个计算节点间的等待时间的比重,调整各自的权重,从而改变每个计算节点应当分配到的负载量,随后通过代价模型重新计算出切分策略并执行下一轮训练;s6、重复s4-s5直至在数次训练中不改变当前切分策略,即证明该切分策略在训练中动态达到最优。
14.s21中,对于每个遍历到的算子,首先考虑其可用的节点列表,如果某个节点不提供当前算子的内核实现,那么当前设备对该算子就是不可用的。
15.s22中,在评估过程中,贪婪启发式算法不仅考虑每个当前可用节点中等待执行的算子的预计完成时间,从而估算出当前算子的预计完成时间,还要考虑如果将算子放置在当前节点,那么将该算子的输入从其他节点传输过来的通信时间。
16.对上述实施例的进一步解释如下:本发明能够在训练过程中根据各个节点计算完成后的等待时间,结合网络模型的类型、参数数据量和系统的可用内存、节点数等参数,自动分析出更优的模型切分策略,从而减少下一轮训练的节点等待时间,直至各个节点的负载达到平衡。
17.本发明提出基于模型并行的动态负载均衡,首先构建了基于模型类型、参数量、网络集群拓扑带宽、节点数等信息的代价模型,基于内存的计算开销和通信开销来对时间建模,通过贪婪式启发算法为每个节点分配算子,并计算出不同的切分策略下模型在系统中不同节点的近似训练时间,评估当前策略的负载均衡程度。
18.通过代价模型,能够读入每个算子的输入、输出和运行所需的计算时间,然后运行整个计算图,最终使用贪婪的启发式算法为每个节点分配算子,并且此分配方案会作为最终的实际执行中的分配方案。
19.代价模型方案对当前节点中的所有可用的计算节点进行状态模拟,然后依次遍历整个计算图,对于每个遍历到的算子,首先考虑其可用的节点列表,如果某个节点不提供当前算子的内核实现,那么当前设备对该算子就是不可用的,对于具有多个可用节点的算子,节点分配算法使用贪婪启发式算法来评估将其放置在每个可用节点上的预计完成时间,从而选取出预计最快完成当前算子的可用节点作为其映射的计算节点。
20.在此过程中,该算法不仅考虑每个当前可用节点中等待执行的算子的预计完成时间,从而估算出当前算子的预计完成时间,而且还要考虑如果将算子放置在当前节点,那么将该算子的输入从其他节点传输过来的通信成本,然后重复该映射过程继续为其余算子分配计算节点,直至为图中的每个算子完成节点分配。
21.训练前为各个节点分配一个权重参数,用来表示分配到的负载量,权重越大分配到的负载量越多,初始时各个节点的权重参数相等。
22.每轮训练时,首先根据当前节点的权重,通过代价模型找出不同节点的切分策略并开始训练,每个节点在计算完成后会统计自身的等待时间。
23.一轮训练完后,根据各个节点的最大等待时间和平均等待时间判断当前的负载均衡是否最优,如果是,则保持当前的切分策略继续训练,如果不是最优,将用各个节点间的等待时间的比重来调整各自的权重,从而改变分配到的负载量,随后通过代价模型重新计算出切分策略并执行下一轮训练。
24.采用上述一种神经网络的针对模型并行的动态负载均衡方法时,其实现了通用的基于神经网络模型并行的动态负载均衡,当应用模型并行方法时,能够根据不同的模型和系统的相应参数自动给出较好的切分策略,无需手动调整模型,保证计算节点的负载均衡,大大提高了优化效率。
25.为了便于更好的理解本发明,下面将对本文中使用的术语进行简要的解释:模型并行:不同计算节点负责网络模型的不同部分,共同训练同一批数据,计算过程中的中间数据需要在不同计算节点之间传递。
26.负载均衡:按照模型的计算成本、计算时间和系统的节点数等参数来维持各个节点上的计算量的平衡。
27.batch_size:深度学习模型进行训练时一次训练所选取的样本数量。
28.上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。