1.本发明涉及一种针对深度学习半精度算子数据访存对界处理方法,属于深度学习技术领域。
背景技术:
2.半精度数据类型占用内存较少,计算时间较短,能够有效地提升深度学习训练模型的性能,因而使用半精度数据类型实现算子对加速深度学习模型训练有重要作用。
3.异构众核平台的控制核与计算核之间的数据传输主要通过dma请求实现,dma仅支持4b粒度的对界,这意味着dma请求需要保证主存地址、计算核局存地址、传输数据量、跨步大小和跨步向量块大小等参数均需满足4b粒度对界的要求,而半精度浮点类型数据的长度为2b,因此对半精度数据的dma读取可能存在不对界的问题。
4.深度学习模型训练过程中的计算数据以多维张量的格式分布,通常情况下的不对界处理会对每一维度做对界处理,这种方法虽然简单易用,但会增加内存占用和对界处理时间。
技术实现要素:
5.本发明的目的是针对深度学习算子实现中常见的半精度数据类型,提供一种简易通用的对界处理方法,解决异构众核平台上半精度算子dma访存的不对界问题。
6.为达到上述目的,本发明采用的技术方案是:提供一种针对深度学习半精度算子数据访存对界处理方法,针对深度学习中算子的计算特点和张量空间分布,对多维张量的特定维度做4b对界处理,将四维张量的输入数据按照实际参与计算的维度分为不同的类,分别使用不同的半精度数据对界处理方法;具体为,根据输入的算子类型和输入数据的计算维度,选择不同的对界方法:s1、对于一维计算,计算总数据量len=n*c*h*w,若len为奇数,单个半精度浮点数为2b,不满足对界要求,在len的最末尾添加一个0,使之满足对界同时不影响计算结果;s2、对于包括softmax、fc、pool、spatialbn的二维计算,实际计算是以二维的方式计算,对于一个n*m的二维张量,在二维张量增加一行0或增加一列0 ,使得m或n为偶数以满足对界,分别为:当需要增加一行0时,设m=c*h*w,则在n*c*h*w的末尾增加c*h*w个0;二维张量增加一列0的对界方法在四维张量中对界策略分为以下三种:1、对于fc和softmax算子,设m=c*h*w,在四维张量中,在每个c*h*w后末尾加一个0;2、 对于spatialbn算子,在每个h*w*的末尾添加一个0,以满足跨步大小对界;3、对于pool算子,在每个w末尾添加一个0,以满足w维度4b对界,;s3、对于三维计算,实际计算是以三维张量参与实际计算,为n、c、h*w,其中,h*w维度的对界策略可归为s2中的二维数组对界,c维度的对界策略为在每个c*h*w末尾增加h*w
个0,使得c和h*w均为偶数以便满足4b对界。
7.由于上述技术方案的运用,本发明与现有技术相比具有下列优点:本发明一种针对深度学习半精度算子数据访存对界处理方法,对深度学习算子的半精度类型张量的运算有较好的支持,四维以下的张量数据都可以在异构众核平台实现半精度类型的运算,解决了异构众核平台上半精度算子dma访存的不对界问题,且不仅能降低内存空间的占用,还能有效减少对界处理的时间,提升对界处理的性能。
附图说明
8.附图1为本发明对界处理方法的示意图;附图2为本发明对界处理方法的示意图;附图3为本发明对界处理方法的示意图;附图4为本发明对界处理方法的示意图;附图5为本发明对界处理方法的示意图;附图6为本发明对界处理方法的示意图;附图7为本发明对界处理方法的示意图;附图8为本发明对界处理方法的示意图。
具体实施方式
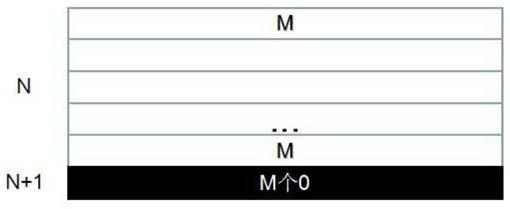
9.实施例:本发明提供一种针对深度学习半精度算子数据访存对界处理方法,针对深度学习中算子的计算特点和张量空间分布,对多维张量的特定维度做4b对界处理,将四维张量的输入数据按照实际参与计算的维度分为不同的类,分别使用不同的半精度数据对界处理方法;具体为,根据输入的算子类型和输入数据的计算维度,选择不同的对界方法:s1、对于一维计算(如激活函数,四维张量在激活函数中的计算实际是按照一维计算),计算总数据量len=n*c*h*w,若len为奇数,单个半精度浮点数为2b,不满足对界要求,在len的最末尾添加一个0,使之满足对界同时不影响计算结果;s2、对于包括softmax、fc、pool、spatialbn的二维计算,实际计算是以二维的方式计算,对于一个n*m的二维张量,在二维张量增加一行0或增加一列0 ,使得m或n为偶数以满足对界,分别为:当需要增加一行0时,设m=c*h*w,则在n*c*h*w的末尾增加c*h*w个0,如图4所示;二维张量增加一列0的对界方法在四维张量中对界策略分为以下三种:1、对于fc和softmax算子,设m=c*h*w,在四维张量中,在每个c*h*w后末尾加一个0,如图5所示;2、 对于spatialbn算子,在每个h*w*的末尾添加一个0,以满足跨步大小对界,如图6所示;3、对于pool算子,在每个w末尾添加一个0,以满足w维度4b对界,如图7所示;s3、对于三维计算(spatial bn算子,某些情况下spatialbn算子是以三维张量参与实际计算),实际计算是以三维张量参与实际计算,为n、c、h*w,其中,h*w维度的对界策略可归为s2中的二维数组对界,c维度的对界策略为在每个c*h*w末尾增加h*w个0,使得c和h*
w均为偶数以便满足4b对界,如图8所示。
10.对上述实施例的进一步解释如下:提供了不同维度的深度学习算子半精度类型张量数据的对界处理策略,针对深度学习中算子的计算特点和张量空间分布,对多维张量的特定维度做4b对界处理,将四维张量的输入数据按照实际参与计算的维度分为不同的类,分别使用不同的半精度数据对界处理方法,该方法对深度学习算子的半精度类型张量的运算有较好的支持,四维以下的张量数据都可以在异构众核平台实现半精度类型的运算。
11.半精度数据长度大小为2b,异构众核加速平台的4b大小对界要求,在实现半精度数据类型算子时,就要求总数据量必须为偶数,同时在张量的计算维度上也需要保证对界,而实际算子的计算是任意数据量大小,因此需要设计一套基于不同维度的半精度数据的对界策略。
12.深度学习算子计算以乘法和加法为主,张量中补零不会改变算子的计算结果,因此主要采用在相应维度补零实现dma存取的4b粒度对界;通过对界处理后,运算核心能够使用dma加载半精度类型数据进行半精度算子的运算过程。
13.以深度学习中的卷积神经网络模型为例,输入数据为nchw格式的四维张量,模型中算子按照实际计算的维度分为三类:激活函数等算子实际是以一维的形式进行计算;softmax、fc和pool等算子实际是以二维的形式参与计算;spatialbn等算子以三维的形式参与计算;针对这三类算子,本发明提供了三种对界处理方法,如下所示:(一)一维(激活函数等)四维张量在激活函数中的计算实际是按照一维计算,计算总数据量len=n*c*h*w,若len为奇数,单个半精度浮点数为2b,不满足对界要求,在len的最末尾添加一个0,使之满足对界,如图1所示。
14.(二)二维(softmax、fc、pool、spatialbn等)softmax和fc算子的输入输出是以四维张量的形式存储,实际计算是以二维的方式计算,对于一个n*m的二维张量,m或n需为偶数以满足对界,即在二维张量增加一行0或增加一列0 ;fc和softmax在某些方式对界处理时需要增加一行0,令m=c*h*w,在n*c*h*w的末尾增加c*h*w个0,如图4所示;二维张量增加一列0的对界方法在四维张量中对界策略具体分三种:1、fc和softmax算子在某些方式对界处理时需要增加一列0,令m=c*h*w,在四维张量中是在每个c*h*w后末尾加一个0,如图5所示;2、 spatialbn在计算时需要满足跨步大小对界,其四维对界形式是在每个h*w*的末尾添加一个0,如图6所示;3、pool在计算时w维度需要4b对界,在每个w末尾添加一个0,若图7所示。
15.(三)三维(spatial bn)spatialbn算子是以三维张量参与实际计算,分为n、c、h*w、c和h*w均应为偶数以便满足4b对界,h*w维度的对界策略可归为上图二维数组对界,c维度的对界策略是在每个
c*h*w末尾增加h*w个0,如图8所示。
16.采用上述一种针对深度学习半精度算子数据访存对界处理方法时,其对深度学习算子的半精度类型张量的运算有较好的支持,四维以下的张量数据都可以在异构众核平台实现半精度类型的运算,解决了异构众核平台上半精度算子dma访存的不对界问题,且不仅能降低内存空间的占用,还能有效减少对界处理的时间,提升对界处理的性能。
17.为了便于更好的理解本发明,下面将对本文中使用的术语进行简要的解释:异构众核平台:一种包含数个控制核和众多计算核的通用处理器,控制核与计算核之间共享内存,计算核主要通过dma方式将数据从主存传输到局部存储。
18.上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。