具有拜占庭攻击弹性的分布式安全边缘异构存储网络
1.相关申请的交叉引用
2.本技术涉及2019年10月31日提交的标题为“distributed secure edge storage network utilizing cost function to allocate heterogeneous storage”的美国专利申请号16/669,696[案卷号stl 074555],以及2019年10月31日提交的标题为“distributed secure edge storage network utilizing redundant heterogeneous storage”的美国专利申请号16/669,712[案卷号stl 074556],这些专利申请所公开和教导的所有内容具体以引用方式并入本文。
背景技术:
[0003]
本公开整体涉及分布式数据存储系统。由于移动设备和“物联网”(iot)的广泛普及等原因,数据生成呈指数级增长。据一个来源估计,到2025年,数据创建量将增长到163泽字节,相当于2017年创建的数据量的十倍。该存储数据可以包括大量的自动生成的数据,例如由传感器生成的数据。传感器数据可以包括由终端设备捕获的原始数据以及作为分析原始数据的结果而生成的数据。一种用于存储和分析大量数据的解决方案涉及将其传输到通常被称为云存储的大型数据中心。
[0004]
假设网络流量呈指数级增长,将越来越难以将所有创建的数据发送到云进行存储,尤其是对于时间紧迫的应用。在一些新兴技术中,诸如智能城市和自动驾驶汽车,可能需要对数据进行实时分析和存储,这可能难以在云中实现。此外,云计算可能受到相对高的延迟(例如,云存储设施距生成数据的位置可以很远)以及由于网络连接的不可预测性(例如,由于需求激增、中断等)造成的影响。
技术实现要素:
[0005]
本公开呈现了安全的分布式异构边缘存储方法,该方法提供了针对窃听攻击和拜占庭攻击的弹性,以用于在分布式边缘存储节点中存储文件。在一个方面,对文件进行分区,生成密钥,并且将包括被密钥掩蔽的文件信息的分组存储在分布式节点中。此外,生成附加数据,该附加数据可用于在节点中的一个节点被拜占庭对手损坏的情况下进行纠错。该方式包括选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络中的大小为|f|的文件的任何部分信息进行解码,该网络将文件分布式存储在ze以上的存储节点中。该方法还包括选择值zb,使得可以通过将纠错码应用于存储在存储节点中的信息来纠正来自zb存储节点的损坏的数据分组。该方法包括选择存储节点中最小化成本函数的n
*
存储节点,该成本函数包括|f|、ze、zb、初始数据访问成本c
t
,以及传输和下载成本cd。纠错码可以基于zb和|f|,用于从检索到的关于文件f的信息中纠正错误。最初,从存储节点中的n
*
存储节点分配相等的存储器大小以存储文件、冗余纠错数据和一组线性码密钥。继而,该方法包括迭代地确定将更多存储节点添加到n
*
存储节点的第一成本以及从n
*
存储节点的子集分配更多存储器的第二成本。该方法包括基于将纠错码应用于线性码密钥集和用线性码密钥集掩蔽的文件分区来构建冗余数据分组,并且基于根据迭代确定来确定的最小成本在存储节
点中的n≥n
*
存储节点中存储文件、线性码密钥和冗余数据分组,存储节点按存储容量从大到小排序,使得最大的ze存储节点存储线性码密钥,最小的n-z
e-2zb存储节点存储文件分区,并且冗余数据分组存储在其余的2zb存储节点中。
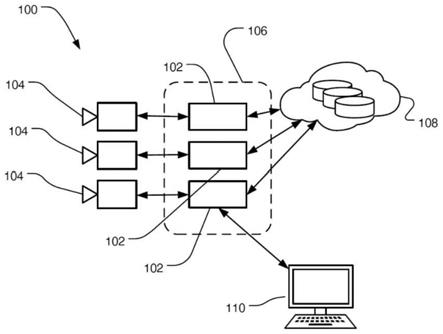
[0006]
在另一种方法中,文件信息以足够的冗余存储,使得当从分布式边缘存储节点检索分组时,创建用于解决文件信息的等式的过度配置系统。继而,本文中称为分组kaczmarz方法的唯一解决方案用于从边缘存储节点中的一个或多个边缘存储节点标识损坏的块。继而,来自边缘存储节点的块可以被省略,并且方程组的迭代解可被构建为根据从分布式边缘存储库检索的信息复制文件。具体地,该方法包括选择经由网络耦合的n存储节点,以存储大小为|f|的文件和大小为|f
red
|的冗余数据。虽然该方法可以与同质存储节点一起使用,但在一个示例中,n存储节点中的至少两个存储节点分配不同大小的存储器来存储文件,n存储节点从第一存储节点处的最大存储容量|s1|到第n存储节点的最小容量|sn|排序。存储节点的数量n可以基于针对从最大数量的zb损坏节点中的n节点中选择的许多t随机节点的数量的平均误差计算。该方式还包括选择ze<n的值,其中能够访问ze存储节点的攻击者无法对文件进行解码。该方法包括将文件划分成文件分区,从而生成存储在n存储节点的前ze中的密钥,以及创建包括密钥和文件分区的独立线性组合的存储块。继而,该方法包括在ze 1至第n存储节点中存储包括密钥和文件分区的独立线性组合的存储分组。
[0007]
本发明内容被提供来以简化形式引入在下面在具体实施方式中进一步描述的一些概念。本发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于限制所要求保护的主题的范围。
[0008]
本文还描述并且叙述了其他实施方式。
附图说明
[0009]
图1是根据一个示例性实施方案的边缘存储系统的框图。
[0010]
图2是示出根据一个示例性实施方案的窃听对手和拜占庭对手的框图。
[0011]
图3是示出根据一个示例性实施方案的节点存储容量可用性的框图。
[0012]
图4是示出针对一个或多个窃听对手和一个或多个拜占庭对手提供弹性的安全的分布式边缘存储方案的框图。
[0013]
图5是示出节点选择的示例的流程图。
[0014]
图6是根据一个示例性实施方案的设备的框图。
[0015]
图7是用于从边缘存储节点标识损坏的数据的分组kaczmarz方法的示例性算法。
[0016]
图8是用于执行分组kaczmarz方法以恢复来自从边缘存储节点检索的分组的文件信息的示例性流程图。
[0017]
图9是关于授权用户在边缘存储系统中能够访问的随机边缘存储节点的数量的平均绝对误差的图表的示例。
[0018]
图10是从分布式边缘存储系统检索数据的示例性算法,该分布式边缘存储系统标识损坏的节点以针对拜占庭对手提供弹性。
[0019]
图11是用于从对拜占庭对手具有弹性的边缘存储节点检索文件分区值的示例性流程图。
[0020]
图12是用于在分布式边缘存储系统中存储数据以向一个或多个拜占庭对手提供
弹性的示例性流程图。
[0021]
图13描绘了用于执行本公开的方面的示例性处理装置。
具体实施方式
[0022]
在上文中以引用方式并入的应用中,提供了用于将数据存储在异构边缘节点中的方法。这些方法允许文件f被分布式存储在多个存储边缘节点中,使得系统对能够访问给定数量的存储节点(ze)的窃听攻击者具有弹性(即,窃听对手无法获得关于文件f的任何信息)。本公开对这些先前应用中论述的那些提出了修改的方法,以提供针对拜占庭攻击者(zb)的进一步的保护。拜占庭攻击基于提供数据的一个或多个节点可能被损坏的拜占庭错误问题。继而,在没有反制措施的情况下,损坏数据可以导致系统故障。在分布式边缘存储系统的上下文中,这可意指鉴于来自被拜占庭对手损坏的边缘节点的数据,分布式存储在多个边缘节点中的文件f可以不被授权用户复制。
[0023]
一般来讲,用于在异构节点之间进行安全的分布式存储以抵御窃听对手的先前方法被修改成使得除了先前方法的密钥分组和掩蔽的文件分组之外,附加的冗余数据也存储在分布式边缘节点中。虽然附加的冗余数据为系统提供了附加的计算复杂性,但益处在于系统可以被设计和部署成向可以不受拜占庭攻击者(zb)影响的文件提供稳健、安全的边缘节点存储,并且提供对先前系统所提供的窃听者(ze)的弹性。
[0024]
在分布式边缘存储库中存储文件f的一种方法涉及授权用户能够访问给定系统中的所有边缘存储节点的场景。本公开大体上不同于并入的申请的现有方法,本公开鉴于存储附加数据来对从边缘存储节点检索的分组进行纠错的需要,修改存储选择过程来优化所选择的存储。此外,修改了对文件进行分区以用于分布式存储的方式,以允许对附加的冗余数据进行分区和存储。因此,以下讨论大体上描述了用于在多个边缘存储节点之间安全地分布式存储文件f的方法,包括经过修改的存储选择和文件分区以提供针对zb损坏节点的弹性。此外,本公开包括关于线性编码密钥的构建和分组生成的讨论。
[0025]
在图1中,框图示出了示例边缘存储系统100。多个存储节点102存储来自传感器104(例如,相机)或一些其他数据生成器的数据。总之,至少存储节点102形成物理上靠近传感器104的边缘层106,并且还可以将一些或全部数据发送至云存储108。需注意,传感器104也可以被认为是边缘层106的一部分,并且在一些情况下,传感器104中的一些或全部可以例如在相同的装置内与存储节点102集成在一起。
[0026]
分布式边缘存储可以提供更靠近需要数据的位置的数据可用性并且降低延迟。例如,邻近边缘层106的用户终端110可以主动监测传感器104和/或存储节点102,寻找近乎实时发生的模式和/或事件。然而,将数据存储在边缘装置上可危及数据安全。例如,边缘装置可具有有限的能力(例如,计算、存储器),并且因此可能无法在不过度限制性能的情况下实施多层的安全性。边缘装置也可能不受单个实体的控制,这可使执行安全策略变得困难。本公开描述了一种安全方案,解决了边缘装置所特有但可适用于其他装置,例如中央分布式存储系统的安全挑战。
[0027]
对于分布式边缘存储设置,一种合适的攻击模型是许多边缘装置被损坏的情况。更具体地,一种潜在攻击模式是窃听攻击,其中攻击者(窃听者)控制一组边缘装置,并且监视存储在其中的数据。在另一种攻击模式中,攻击者(拜占庭攻击者)可损坏一个或多个边
缘装置,使得从此类受损装置检索的数据可被损坏。该第二攻击模式有时被称为基于其中来自攻击者的损坏数据导致系统故障的分布式计算系统的拜占庭故障的拜占庭攻击。因此,本公开呈现一种系统,其中目标是使数据对受攻击装置保密,并且解决来自用作分布式存储节点的装置的损坏的数据。
[0028]
根据一个示例性实施方案,窃听攻击者206和拜占庭攻击者210正在主动攻击边缘装置202的场景也在图2的框图中示出。数据200(例如,文件f)以分布式方式存储在能够经由网络访问的一组边缘存储节点202中。最终用户可能希望经由网络连接的计算机装置,诸如图1中独立示出的用户终端110存储文件f,出于本公开的目的,存储节点是可独立操作的、自包含的计算单元,包括至少一些可用存储。这种独立性意味着,能够访问一个存储节点的窃听攻击者206或拜占庭攻击者210不一定能够访问互操作以存储数据200的部分的其他节点。这不同于其他分布式存储方案,诸如磁盘阵列,其中数据文件部分可以分布在不同磁盘之间。一般来讲,可以访问阵列中的一个磁盘(例如,通过访问主计算机或存储控制器卡)的攻击者通常可以访问所有磁盘。还需注意,边缘存储节点202不一定需要彼此通信来实现本文所述的分布式存储,但所有存储通常可由单个实体例如授权用户终端访问。
[0029]
在该示例中,边缘存储节点202的第一子集204可由窃听攻击者206访问,使得窃听攻击者206可查看存储在第一子集204上的感兴趣数据。出于本公开的目的,值ze表示窃听攻击者206能够访问的具有系统保护的节点的最大数量。另外,边缘存储节点202的第二子集208可由拜占庭攻击者210访问,使得拜占庭攻击者210可损坏存储在第二子集208上的感兴趣数据。出于本公开的目的,值zb表示拜占庭攻击者210可以在保持系统可操作性的同时损坏数据的最大数量的节点。系统被设计成使得窃听攻击者206无法读取只能够访问ze个节点的数据文件200的任何部分信息。此外,系统被设计成使得拜占庭攻击者210无法阻止授权用户检索仅zb个节点被拜占庭攻击者210损坏的数据文件200的足够信息。授权用户将能够访问节点202的ze以上的节点,并且因此可以读取数据文件200。此外,授权用户将能够纠正从节点202中的zb个节点接收的信息中的错误。在该示例中,授权用户将需要访问所有边缘节点202以读取数据文件200。此外,可以理解的是,授权用户可能无法区分已经被窃听攻击者206或拜占庭攻击者210损坏的节点。此外,情况可能是ze个节点和zb个节点可以共享被窃听攻击者206和拜占庭攻击者210两者损坏的至少一个节点。
[0030]
使用线性编码密钥的秘密共享方案解决窃听攻击,其中数据被分成具有相同大小的份额,并且每个份额被线性编码密钥掩蔽并且存储在可用存储节点中的一者中。例如,假设存在的可用存储节点。数据f首先被分成f1和f2两个相等的份额,并且生成密钥k1和k2。然后,创建四个分组并且将其存储在的四个存储节点中。需注意,分组的值按指示进行算术组合,并且截断以拟合到分组中。该系统设置使f1和f2两个份额对可能受到窃听攻击的任何ze=2存储节点保密。
[0031]
为了提供对拜占庭攻击者的弹性,冗余地存储有关文件f的附加信息。附加信息可以用于纠错方法(例如,(n,k))纠错码)。继而,当从存储节点检索数据时,纠错码可应用于检索到的数据,使得从被拜占庭攻击者损坏的存储节点接收的任何损坏的数据可被纠正。具体地,对于给定的能够纠正e错误的(n,k)纠错码,可以在分布式存储节点中存储每k条信息n-k数量的附加冗余数据。
[0032]
边缘装置存储节点202可以与不同的存储器、计算、带宽、功率等异构。直接应用现有的秘密共享方案导致分布式边缘存储的性能不佳,因为它们未考虑到存储节点的异构性。例如,如果四个存储节点性。例如,如果四个存储节点被分配的存储容量可用性不同,那么和的存储的分组应该具有不同的大小。出于本公开的目的,术语“存储容量可用性”用于描述存储节点满足符合一些最低要求的请求的能力。存储节点不仅应该具有存储数据的可用容量,还应该在写入(包括网络通信的)存储并且从存储读取时具有满足为系统定义的最低标准的性能。在图3中,示出了根据一个示例性实施方案的不同存储节点的存储容量可用性如何不同。
[0033]
在图3中,矩形300和矩形302表示两个不同异构存储节点s1和s2随时间推移的数据传输。节点s1具有比以速率r2传输数据的节点s2更高的传输速率r1。如果数据存储节点可以在时间t内传输和接收分区,则大小为|f|的分区可用。块300和块302的面积大小均为|f|,因此这两个节点具有至少一个分区的存储容量可用性。如框304所示,假设节点s1在容量可用时也具有足够的存储容量,节点s1在理论上可以具有四个大小为|f|的分区的存储容量可用性。在该示例中,即使节点s2具有比节点s2高得多的存储容量,也仍具有四分之一的存储容量可用性。
[0034]
为了使实体利用异构边缘存储节点进行安全的存储,实体还可以定义(i)如何从所有候选者中选择存储节点,(ii)如何对文件进行分区,(iii)如何生成密钥,以及(iv)如何创建待存储在所选择的存储节点中的分组,等等。这些问题在本公开中得到解决,以及如何针对成本优化存储分配。
[0035]
在图4中,框图示出了根据一个示例性实施方案的分布式边缘存储方案。文件400由存储处理设备402处理,该存储处理设备可包括常规计算硬件,诸如处理器、存储器、输入/输出总线等,以及专用硬件,例如专用集成电路、数字信号处理器等。存储处理单元包括功能单元(例如,软件模块、逻辑电路),诸如文件分区器404,该文件分区器可以被配置为查询边缘存储节点的边缘网络406以确定单个存储节点的存储容量可用性。使用下文将讨论的技术,文件分区器404选择节点的子集408,并且为文件400创建存储配置的定义410。该定义410包括对所选择的存储节点、每个节点上的分区/分组大小、每个分区中排列的数据和密钥等的标识。
[0036]
密钥生成部分412包括为文件400生成密钥集的模块414和将集合的密钥线性组合成线性编码密钥的模块416,g
i’s。分组生成模块418使用定义410和线性编码密钥来生成文件400并且将其存储在网络406上。类似的模块集合可用于基于定义410从网络406读取数据,下载分区/分组,解锁分区/分组,并且重新组装文件。
[0037]
使用文件分区和所生成的密钥创建每个分组。文件分区器404有效地使用可用异构资源,使得所设计的分布式边缘存储系统针对在最多ze存储节点处攻击的窃听者对手420和在最多zb存储节点处攻击的拜占庭对手422是安全的。考虑一种系统模型,其中存在可用作分布式存储节点的个异构边缘装置。网络406中的所有候选存储节点的集合由个异构边缘装置。网络406中的所有候选存储节点的集合由表示。选择所有可用存储节点的子集408用于安全地存储数据f。
[0038]
所选择的存储节点的集合由表示,其中然后,创建分组的集合以存储在所选择的存储节点的集合408中,其中存储
在存储处。
[0039]
假设系统易受攻击,其中根据参数ze<n来表征窃听攻击者420的能力。更具体地,窃听攻击者420可以访问存储在最多ze存储节点中的数据。然而,防御方不知道关于哪些存储节点受到攻击的信息,因此,目标是使数据f对任何ze存储节点保密。ze的值也可以被认为是安全参数,其中ze的较高值可以为系统提供更高的安全性,并且ze的较小值使系统更容易受到攻击。
[0040]
还假设系统容易受到攻击,其中根据参数zb<n来表征拜占庭攻击者422的能力。更具体地,拜占庭攻击者422可损坏存储在最多zb存储节点中的数据。与窃听攻击者420一样,防御者也不知道关于哪些存储节点受到拜占庭攻击者422的攻击的信息。因此,目标是在任何zb存储节点向授权用户424提供损坏的数据时能够纠正数据f的错误。zb的值也可以被认为是安全参数,其中zb的较高值可以为系统提供更高的安全性,并且zb的较小值使系统更容易受到攻击。
[0041]
从防御者的角度来看,ze和zb的值更大的更稳健系统的存储使用量增加(分布式存储节点的数量增加)并且设计安全系统的复杂性也增加。换句话讲,通过考虑系统对攻击的脆弱性状态,参数ze和zb可以被视为提供更高的安全性与系统复杂性增加之间的折衷。
[0042]
一个目标是储存数据,使得攻击者无法获得任何关于数据的有意义的信息。更具体地,所提出的解决方案提供了定义为的信息理论保密性,其中h()是信息理论熵,并且是存储在任何大小为的存储集中的数据。在信息理论保密性的一个应用中,数据分区的线性组合可以揭示关于整个数据集的一些有意义的信息。在所提出的方法中,数据分区的任何线性组合对数量为ze的存储节点的任何子集保密。授权用户可以通过访问存储在存储集中的所有分组来提取数据f。
[0043]
在本公开中,描述了有助于在设计阶段降低计算复杂度以及在检索数据阶段降低授权用户的计算复杂度和通信成本的特征。再次参考图4,选择所有候选存储节点的子集以分布式存储文件f。所选择的存储集应该满足提供安全性的最低要求。在第二步骤中,文件f被分成分区。在第三步骤中,生成密钥并且将g
i’s构建为所生成的密钥的线性组合,其中gi值用于掩蔽文件分区。在第四步骤中,文件分区和所构建的g
i’s用于生成分组并且将其存储在所选择的存储节点的集合中。下文描述了每个步骤的细节以及互补示例。
[0044]
存储选择
[0045]
需要检索所有密钥和文件分区,以按照该方法恢复文件。因此,选择一组存储,使得所有存储节点的总存储大小等于|f|(文件f的大小)和|k|(使数据对ze存储保密所需的密钥大小)之和。即,密钥的大小可描述为或窃听攻击者能够访问的节点数量乘以超出窃听攻击者能够访问的节点数量的第一节点的分组大小。因此,出于纠错码的目的,消息长度的大小k=|k| |f|是检索和恢复文件所需的数据。
[0046]
本公开还考虑了数据从zb节点被损坏的可能性,其中zb再次成为系统的设计参数。本文所述的方法通过使用对检索到的文件分组的纠错码使系统针对拜占庭攻击具有稳健性。例如,可以使用纠错码,该纠错码为(n,k)纠错码,如上所述k=|k| |f|。即,对于给定的消息长度k,可以提供块长度n以用于纠正所接收的块中的错误。消息长度和块长度包括呈位形式的附加信息,以用于纠错。消息长度可以是密钥k和文件f的大小的函数。因此,存储
在存储节点中的数据的总大小可以增加n-k,这表示纠错所需的附加信息。
[0047]
(n,k)纠错码可能能够纠正错误,其中是存储在所有存储中的最大分组。原因在于损坏的存储的最大数量为zb,并且因此损坏的信息的最大大小是所有存储中的最大分组大小的倍数乘以拜占庭攻击者所损坏的节点数量。例如,里德-所罗门码可用作(n,k)纠错码。在该示例中,n-k等于2e,这可用于如下所述的成本函数以确定存储大小为|f|的文件所需的存储数量。其他纠错码可具有不同的纠错能力,这将基于本公开理解以适当地修改成本函数。
[0048]
为了提供安全性,用密钥掩蔽文件分区(包括用于纠错的冗余数据),因此,应该将一些可用存储器资源分配给存储密钥。满足在存储节点中存储文件分区f的信息理论隐私的最低要求是用具有与f相同大小的随机密钥对其进行掩蔽,例如f k,其中|k|=|f|。此外,为了使数据对任何ze存储节点保密,存储在任何ze存储节点中的分组应该是线性独立的。若要满足此约束,一个要求是,对于任何大小为的存储分组(存储在存储si中),至少应该存在ze个其他存储分(其中每一个存储在另一个存储中)的大小大于或等于换句话讲,如果存储节点按所分配的存储大小降序排列,使得一个最低要求是存储在前ze 1存储节点中的分组具有相同大小。此外,任何ze存储节点都应该包含线性独立的分组。
[0049]
因此,存储选择的第一要求是其中|f|是文件f的大小。另一个要求是所有存储节点上分配的总存储大小应该等于这意味着为了分布式分配数据f,需要额外的存储器来存储密钥并且保证数据安全。然而,为了使授权用户能够检索数据f,应该能够访问存储在所有存储节点中的数据并且下载它们,然后应该减去密钥部分并且提取有用信息f。
[0050]
此外,如上所述,使用纠错码需要存储用于执行纠错的附加信息。具体地,在最大的ze存储之后的接下来的2zb最大存储用于存储为纠错提供的附加信息,或最后,其余的n-z
e-2zb最小存储用于存储用密钥掩蔽的文件分区。因此用密钥掩蔽的文件f的最大部分对应于存储在存储中的文件分组。需注意,储存在最大的ze 2zb 1存储库中的所有分组可具有相同的大小。
[0051]
授权用户从存储节点检索数据的成本是存储节点的数量以及其他参数(诸如存储类型、带宽、功率等,对于不同的存储节点,这些参数是不同的)的函数。应该选择所选择的存储节点的集合以最小化成本。即使存储节点在存储类型、带宽和功率方面是同质的,但仅在可用存储大小方面是异构的,因此最小化成本仍然很重要。在下文中,通过使用下面的等式(1)集中优化此简化场景的成本,找到了一组所选择的优化的存储节点,该等式考虑了保护数据免受受到窃听攻击的ze节点的影响的成本,并且提供了足够的信息来纠正被拜占庭攻击者损坏的zb节点中的错误:
[0052][0053]
如等式(1)所示,成本包括两个部分:(i)nc
t
,其中c
t
是访问存储在每个存储节点的数据的初始成本,并且nc
t
是所有存储节点的总成本,以及(ii)其中cd是传输和下载一条信息的成本,并且所有数据的总成本为一般来讲,c
t
包括网络发现、设置和释放连接等动作。需注意,在简化模型中,对于每个候选存储节点,可以认为c
t
和cd是恒定的。在一些变型形式中,针对每个节点,c
t
和cd可以不同,使得等式(1)中的成本值为平均值,更具体地,对于cd,为加权平均并且对于c
t
,为平均值其中和c
t,i
分别是第i存储节点的下载成本值和访问存储在存储节点i处的数据的初始成本。
[0054]
目标是选择一组存储节点使得最小化等式(1)中定义的成本。为解决此问题,确定等式(1)中对成本的影响,然后找到成本的下限和对应的n的优化值。等于在所有存储节点处存储的所有分组中用密钥掩蔽并且存储在存储处的文件f的最大部分。为了降低成本,应该将选择为尽可能小。在另一方面,如下文将在“文件分区”部分中解释的,文件分区分布在最后的n-z
e-2zb存储节点中,因此,最大部分的最小大小等于|f|/(n-z
e-2zb),即文件分区均等地分布在最后的n-z
e-2zb存储节点中的情况。同样,这不同于单独的窃听安全性的方法,因为用于纠错的附加信息将被存储在2zb存储节点中。
[0055]
最佳成本解决方案可能并不总是可能的,因为包含文件分区的不同部分的存储节点是异构的,具有不同的|si|,并且因此具有不同的然而,这可以提供成本下限,如下面的等式(2)所示。
[0056]
等式2
[0057][0058]
如等式(2)所示,通过增加n,下限的第一部分增加并且第二部分减小。因此,存在最小化下限的n的最佳值,其计算如下等式(3)所示,其中n
*
四舍五入为优化的整数。具体地,n1为n
*
四舍五入为最接近的较小整数,并且n2为n
*
四舍五入为最接近的较大整数。
[0059][0060]
当边缘装置异构时,所计算的优化的存储节点数量n
*
的成本大于等式(2)中计算出的下限。然而,该线索可用于为异构分布式边缘存储选择集合策略是最初使用来自前n
*
存储节点(具有最大可用存储大小的存储节点)的相同存储器大小,并且如果需要更多存
储器来存储f,则迭代地决定(i)添加更多的存储节点或(ii)使用来自每个可用存储的更多存储器。这两个选项之间的决定是基于将成本降到最低。在下文提供了细节并且在图5中大体示出,该图是示出根据一个示例性实施方案的节点选择的流程图。需注意,|si|表示存储si处的最大可用存储器大小,并且表示从存储si用于存储文件f的一部分,即分组的存储器大小。
[0061]
存储选择的初始化500涉及在以可用存储大小降序排列节点之后选择前n
*
存储节点作为在这些存储节点中可以均等地分布式存储的文件f的最大大小为(n-z
e-2zb)|sn|。因此,如果确定501文件f的大小大于此,则进入“修改”阶段,其中添加510个以上的存储节点或使用来自可用存储节点n-n的512个以上的存储器。如果文件f的大小小于前n
*
存储节点中可用的大小,则最初选择的存储节点的集合最终确定502为并且其中存储在每个存储si中的每个分组的大小等寸
[0062]
修改阶段涉及确定这些选项510、512中的一个选项,其中选择具有最小成本的选项。对于修改阶段,可通过以下方式向分布式存储系统添加另外的info=(n-z
e-2z
b-n)(|s
n-n
|-|s
n-n 1
|)信息:(i)将存储在前n-n存储节点中的每个分组的大小增加503|s
n-n
|-|s
n-n 1
|,更新为1≤i≤n-n,或者(ii)添加504接下来的n
add
存储节点,使得需注意,n在步骤500处初始化为1,并且n
add
应该尽可能小以减少成本的增加。每个选项503、504增加不同的成本。更具体地,第一选项使成本增加cost
add,1
=(ze 2zb)(|s
n-n
|-|s
n-n 1
|)cd,因为在等式(1)中的大小增加了|s
n-n
|-|s
n-n 1
|,并且第二选项504使成本增加cost
add,2
=n
addct
,因为在等式(1)中存储节点的数量增加了n
add
。根据系统参数,选择成本较低的选项(参见操作508)。
[0063]
需注意,如果info=(n-z
e-2z
b-n)(|s
n-n
|-|s
n-n 1
|)等于0,则第一选项503不可用,并且因此通过根据需要添加尽可能多的附加存储节点来选择第二选项504,使得并且在该选择之后,变量被更新,如图5中详述的操作所示。
[0064]
在涉及修改从每个存储或所选择的存储节点的集合使用的存储器大小的修改阶段之后,应该更新参数。如果在修改阶段选择了第一选项503,则更新505涉及将参数和参数n更新为n=n 1。如果在修改阶段选择了第二选项504,应该通过按所分配的存储大小降序排序并且将n
add
存储节点添加到所选择的存储节点集合存储节点添加到所选择的存储节点集合n=n n
add
来更新506所选择的存储节点集合。此外,应该被设定为需注意,根据info的量,可能会选择使得并非使用存储sn的所有可用大小,即,此外,参数n应该被更新为n=n n
add
。
[0065]
在进行所需更新之后,如果针对最低成本选项仍不满足条件507
则可以顺序地重复阶段“修改”和“更新”,直到满足条件。当满足条件507时,类似于最终确定502来最终确定514存储配置,但是使用在“修改”和“更新”阶段中确定的节点和分组大小。
[0066]
文件分区
[0067]
前ze存储节点被分配用于仅存储密钥,接下来的2zb存储节点被分配用于存储条冗余信息,用于密钥和用密钥掩蔽的文件分区的纠错,并且其余的n-z
e-2zb存储节点存储用密钥掩蔽的文件分区。
[0068]
因此,存储在最大的ze存储和最小的n-z
e-2zb存储中的分组如在上文以引用方式并入的美国专利申请号16/669,696的文件分区部分中所述进行分配。
[0069]
储存在其余的2zb存储中的分组是纠错码用于检测和纠正损坏的分组所需的冗余信息。使用纠错码的生成矩阵乘以包括密钥和用密钥掩蔽的文件分区的向量构建这些分组,即,所有信息共同存储在前ze和最后的n-z
e-2zb存储中。
[0070]
此外,密钥生成和构建g
i’s以及分组生成也根据美国专利申请号16/669,696中的公开内容。即,密钥信息存储在最大的ze存储节点中,并且用密钥掩蔽的文件分区存储在最小的n-z
e-2zb存储节点中,其余的2zb存储节点存储使用纠错码生成矩阵乘以包括密钥和用密钥掩蔽的文件分区的向量构建的分组。
[0071]
就此而言,为了检索文件f,授权用户从分布式存储库检索所有存储的分组。可使用密钥解除对文件分区的掩蔽,并且可以通过应用纠错码来纠正数据中的任何错误。
[0072]
在图6中,框图示出了根据一个示例性实施方案的设备600。该设备600可如上所述配置为用户终端,但存储节点也可以具有类似的硬件。设备包括处理器602(例如,cpu)、存储器604和输入/输出电路606。存储器604可包括易失性存储器(例如,ram)和非易失性指令存储器(例如,闪存存储器、磁性存储装置)两者,并且可存储指令608,在这种情况下,这有助于经由网络612进行分布式存储。设备600具有用于访问网络612的网络接口610。网络612包括多个存储节点614,例如如上文所述的边缘存储节点。
[0073]
指令608可操作以使处理器602选择值ze(例如,由系统设计者经由设备选择),使得能够访问存储节点614的ze的攻击者无法对存储在网络612中的大小为|f|的文件616进行解码,该网络将文件分布式存储在ze以上的存储节点中。指令608还可操作以使处理器602选择值zb(例如,由系统设计者经由设备选择),使得授权用户能够纠正来自存储节点614的zb的错误。指令608使处理器602选择最小化成本函数的存储节点的n
*
,该成本函数包括|f|、ze、zb、初始数据访问成本c
t
,以及传输和下载成本cd。指令608使处理器602最初从最大的(具有最大可用容量的)n
*
存储节点分配相等的存储器大小以存储文件和线性码密钥的集合618。
[0074]
指令608使处理器602迭代地确定将更多存储节点添加到n
*
存储节点的第一成本以及从n
*
存储节点中的每一个存储节点分配更多存储器的第二成本。基于根据迭代确定来确定的最小成本,指令608使处理器602将文件616和线性码密钥618存储在n≥n
*
的存储节点中,密钥618存储在第一至z
eth
存储节点中,并且文件616的分区用存储在ze 2zb 1
th
至n
th
存储节点中的密钥618的独立线性组合掩蔽。此外,应用程序使用纠错码的生成矩阵乘以包括密钥和用密钥掩蔽的文件分区的向量生成的冗余数据存储在其余的2zb存储中。
[0075]
在边缘存储节点中安全地存储数据的另一种方法提供了数据冗余,使得即使在授权用户能够访问系统中不到全部的可用存储节点时,也可以检索数据。例如,在上文以引用方式并入的美国专利申请号16/669,712中描述了一种这样的方法。这种方法反映了系统中的存储节点可随时间推移而变化的事实(例如,由于系统中的存储节点的丢失和/或添加)。即,系统可以被设计成使得可以通过访问存储在t装置中的数据来检索数据f,其中ze<t≤n。这种考虑背后的原因是边缘装置是可移动的,并且授权用户与存储节点的相遇时间可随时间推移而变化,例如,存储节点可以时不时地离线。此外,边缘装置并非出于用于企业的目的而设计,因此其针对故障的容忍度阈值可能较低。因此,目标是通过访问不到所有n存储节点来提供检索数据的能力,以防一些存储节点由于移动性或故障而变得不可用。
[0076]
如关于提供具有边缘节点丢失的安全分布式文件存储的先前方法所述,在可用存储节点之间存储冗余量的数据|f
red
|。这提供了冗余并且允许根据检索到的数据分组重建文件f,即使在例如由于存储数据分组的一个或多个边缘节点在存储分组后变得不可用,存储与文件f相关的分组的边缘节点的身份发生变化的情况下。
[0077]
一般来讲,当从分布式存储节点检索分组时,结果是ax=b形式的线性方程组,其中a的每一行是密钥和对应于相关分组块的文件分区的系数向量,x是密钥和文件分区的向量,并且b是从授权用户能够访问的存储节点收集的分组块的值的向量。在拜占庭攻击者正在损坏从边缘存储节点检索到的数据的场景中,错误参数e被添加到方程组以创建描述为ax=b e的方程组。对于尚未被拜占庭攻击者损坏的存储节点,错误参数e将为零。然而,授权用户并不具有对哪些节点可能受到攻击的先验知识。
[0078]
继而,本公开呈现了一种方法,其中使用本文中称为分组kaczmarz(gk)方法的方法迭代地求解由从存储节点检索到的分组创建的线性方程组,该gk方法是对加窗的kaczmarz(wk)方法的修改。随机kaczmarz(rk)方法以指数方式收敛到最佳解,期望获得没有损坏的等式的线性方程组。如果一些等式有噪声,即其结果偏离正确结果并且存在一些小错误,诸如通过从以小裕度修改分组的拜占庭攻击者引入损坏的数据,rk收敛到最小二乘解。已针对一些等式被损坏的情况(即,它们的结果值偏离了具有较大裕度的正确结果值,诸如从受损存储节点检索到的数据的情况)提出了wk方法。然而,本文中呈现的gk方法修改了wk方法,然后应用rk。在分布式存储系统的上下文中,已发现gk方法优于wk方法。在下文中,描述了gk方法,并且随后描述了用于使用gk使安全分布式边缘节点存储系统针对拜占庭攻击更具稳健性的算法。
[0079]
按照前面的示例,其中可以构建ax=b e形式的线性方程组,用于从检索到的密钥信息和文件信息的分组中重新创建文件f,a可以是线性方程组的系数矩阵,并且x是未知数向量。此外,b是结果的向量。就此而言,如果ax-bb未损坏,则等式等于零向量。否则,即,在至少一个损坏的节点的情况下,b等于非零向量。在与分布式边缘存储节点系统中文件f的信息分组的存储有关的方法中,x表示密钥和文件分区的向量,a是用于生成待存储在存储节点中的分组的密钥和文件分区的系数矩阵,并且b是授权用户从存储节点检索到的值的向量。对于恶意存储节点si,满足ajx苹bj,不等式,其中aj是矩阵a的j
th
行,bj是向量x的j
th
元素,并且是对应于存储节点si中存储的分组块的矩阵a的行的索引集。在gk方法中,如图7中的算法定义所示,检测到恶意节点。继而,从线性方程组中省略来自损坏的节点的对应的损坏的块,并且来自检测到未损坏的节点的其余分组用于检索密钥和文件分区。
[0080]
wk算法基于在a和b上应用rk进行多次(k)迭代以获得矩阵xk。然后计算从向量axk中减去向量b的元素的残差,并且标识d最大残差。即,wk方法执行解的迭代以确定相对于方程组中每个输入的收敛解的残差。继而,对应于d最大残差的方程被标识为损坏,并且在线性方程组的解的后续迭代中,没有被标识为损坏的方程的其余方程用于(i)对解进行进一步迭代并且标识另外的损坏的方程或(ii)提取未知数作为解(例如,在系统中具有足够低的残差)。然而,与wk在从存储在所有存储节点中的所有分组块获得的所有等式上的蛮力应用相比,可以通过使用gk来提高系统性能。
[0081]
在gk方法中,计算存储在特定存储节点si中的分组的所有块的残差平均值。在计算所有存储节点(即,所有节点si、i∈n)的这些平均残差之后,将平均残差最大的d存储节点标识为恶意节点。即,与损坏的方程(即,方程组的单个输入)被标识为损坏的wk方法相反,gk方法利用分布式边缘存储系统上下文的理解,即如果给定的存储节点损坏,则从该损坏的存储节点检索到的所有分组也可能损坏,或者至少是可疑的。因此,给定节点的平均残差的计算(这可贡献许多块,从而为系统创建多个输入或等式)允许标识损坏的节点,使得从该节点对方程组做出贡献的所有信息可因损坏而从系统中省略。因此,根据平均残差标识损坏的节点可用于从系统中省略许多等式,系统输入全部从基于平均残差值标识为损坏的d节点检索而来。
[0082]
继而,在gk方法的后续迭代中,系统省略对应于所检测到的恶意存储节点的所有块。因此,使用gk方法检测损坏的节点的过程不断迭代,直到kbzb分组被检测为损坏或等效的kbzb节点被检测为恶意为止。需注意,根据拜占庭攻击模型,最多zb分组损坏,并且kb是系统参数,该系统参数被确定为保证裕度以在检测为损坏的分组中有一些正确分组的情况下将更多分组检测为损坏。
[0083]
最终,从线性方程组中移除所有检测到损坏的分组块,并且将rk应用于其余等式以获得未知数的向量,该向量为可用于重建文件f的密钥和文件分区。需注意,使用rk有助于捕获由恶意节点应用的可能尚未通过计算平均残差来捕获的可能的小损坏。图7中所示的算法总结了gk的步骤。
[0084]
图8描绘了在分布式边缘存储系统中应用gk方法的示例性操作800。在初始化操作802处,将迭代数设置为零。在迭代计数器操作804处,确定当前迭代次数是否小于保证裕度参数kb乘以zb。如果迭代次数小于保证裕度参数乘以zb,则定义操作806定义线性方程组,以获得ax=b-e形式的上述检索到的分组的解。求解操作808尝试求解线性方程组。如上文所述,冗余信息的使用可以允许为线性方程创建过度配置系统。因此,解析操作808可包括使用过度配置系统进行迭代,使得可以计算来自存储节点的每个数据块的残差值。平均操作810基于来自给定存储节点的每个块的单个残差来对每个存储节点的残差进行平均。即,可以基于从给定存储节点检索到的每个单个块的残差来确定给定存储节点的平均残差。继而,移除操作812从具有最高平均残差的给定数量(d)的存储节点中移除线性方程组中的所有块。参数d可以是被选择为大于1的系统的设计参数。
[0085]
操作800可以在每个移除操作812之后添加到迭代次数并且继续直到迭代次数等于保证裕度参数乘以zb,此时,求解操作814使用来自未被移除操作812移除的存储节点的其余块从线性方程返回解。
[0086]
如上所述,kb是设计参数,可以由系统设计者调整以平衡系统性能与针对系统中
的损坏信息的稳健性。因此,图9示出了与wk相比,选择保证裕度参数kb对示例性场景的wk性能的影响和最优解。
[0087]
具体地,图9示出了与wk相比的gk的性能和最优解(其中损坏的块是先验已知的)。反映在图9中的绘图的系统模型针对存储节点的数量n=50和窃听对手能够访问的最大节点数量ze=3设计。绘图中的每个点由能够访问t存储节点的授权用户获得,其中zb=3是恶意的,即损坏的分组。计算所有未知数的绝对误差总和的对数,并且通过100次随机实验计算平均值。在每个随机实验中,zb=3随机节点被选择为恶意,并且通过向块添加随机错误而损坏存储在恶意节点处的每个分组。误差范围在从实际值减去50%到向实际值添加1000%之间。用于模拟的gk方法遵循图7中所示的算法细节,参数为k=20,、kb=3和d=1。
[0088]
使用许多其他绘制的基线来评估gk的性能,包括wk1、wk2、理想gk和最优解。wk1将wk方法应用于从t所选择的节点的分组接收的块,直到检测到来自zb节点的一个或多个块被损坏。然后,省略检测到损坏的块,并且将具有20,000次迭代的rk应用于其余的块。
[0089]
wk2将wk方法应用于从t所选择的节点的分组接收的块,直到检测到来自zb节点的一个或多个块被损坏。然后,检测到具有至少一个受损块的任何节点都是恶意的。与wk1相反,仅省略被检测为恶意节点的所有块,并且具有20,000次迭代的rk应用于来自其余节点的所有块。
[0090]
理想的gk图应用具有在二至十七范围内的保证度量参数kb的不同值的gk,并且选择对于图中的每个点具有最佳性能的保证度量参数kb。
[0091]
最佳解决方案是一种不现实的解决方案,即假设授权用户先验地知道恶意节点,并且对从非恶意节点接收的块应用具有20,000次迭代的rk。这对于实际解决方案而言不是有效的假设,因为现实世界环境中无法获得对损坏的节点的先验知识,然而,这可以用作在将rk应用于未损坏的块时对误差下限的反映。
[0092]
如图9所示,wk2略微优于wk1,其性能改进可忽略不计,通过省略至少一个块被检测为损坏的所有分组块而不是仅丢弃损坏的分组来实现。这种稍加改进意味着,通过利用关于损坏的状态或不在一个特定分组的块中的相关性,检测损坏的分组和恶意节点的概率将增加,然而,wk的蛮力应用仍然不是捕获这种相关性的适当方法。因此,gk有效地捕获这种相关性,并且因此显著优于wk1和wk2。这证明,计算每个分组的所有块上的残差平均值而不是计算每个单个块的残差,并且使用该平均值作为检测恶意节点的度量,为wk方法提供了显著的性能改进。换句话讲,在gk中,中间解和与节点相关的块之间的平均距离是标识恶意节点的度量,而在wk中,中间解和每个块之间的距离是标识wk1的受损分组或wk2的恶意节点的度量。
[0093]
在保证度量参数kb的值较大的情况下,gk检测到恶意节点的可能性更大(即,增加正真率),存在将诚实节点检测为恶意(即,增加正负率)并且从分组集忽略有效分组的风险,这降低在gk的最后一步应用的rk的性能。因此,作为另一个基线,针对每个t执行不同的kb∈{2,3,...,17}值,并且将最佳的kb用于理想的gk图。从选择最佳kb可以看出,允许将对数误差减少最多5个点。需注意,gk对t的不同值使用保证度量参数的固定值kb=3。因此,虽然理想的gk不切实际,但理想的gk的图确实示出,具有系统设计人员所选择的kb的静态值的gk的性能差距与理想的gk解之间几乎没有区别。评估gk的性能的另一有用基线是最优解,其中rk应用于未受损分组。如所示出的,gk的性能接近理想的gk的性能界限和最优解,
特别是在考虑wk1和wk2的性能的情况下。
[0094]
返回参考用于处理文件f以存储在多个分布式边缘节点中的系统设计,图12的流程图包括以下阶段:存储节点选择1200、文件分区和构建文件块1201、密钥生成和构建密钥块1202,以及分组生成1203。与先前针对拜占庭攻击者不具稳健性的方法相比,在本发明的方法中,存储选择有所不同,以适应对拜占庭攻击者具有稳健性的系统。具体地,由于设想从分布式存储节点检索的一些块将损坏,用于重建文件的块的初始分布需要分布附加的冗余数据。因此,所需的存储节点的最小数量取决于应用程序的可接受错误。
[0095]
在第一阶段1200中,选择所有候选存储节点的子集来分布式存储文件f。为此,通过计算1204每个t值的平均误差来获得误差相对于t值(授权用户能够访问的存储节点的数量)的图,诸如在图9中的示例性场景中所示。即,对于所选择的存储节点集合在每次迭代时选择t随机存储节点,并且计算迭代的平均误差。该过程针对t的不同值重复,并且基于相对于t的不同值的计算误差来绘制图形。然后选择1206存储节点集,使得所获得的所选择的集合的图形满足与t的特定值的平均误差相关的系统要求小于或等于可接受误差。在选择1206存储节点集之后,在第二阶段1201中,将文件f分成分区1208,并且将文件块构建1210为文件分区的线性组合,其中文件块用于增加冗余。在第三阶段1202中,生成密钥1212,并且将密钥块构建1214为所生成的密钥的线性组合,其中密钥块用于掩蔽文件分区。在第四阶段1203中,所构建的文件块和密钥块用于生成1216存储分组,并且将存储分组存储1218在所选择的存储节点的集合中。
[0096]
进一步参考图10,示出了用于从分布式边缘存储节点检索数据的算法。该方法从损坏的分组中系统地恢复,并且提取在可接受的错误范围内的密钥和文件分区。图11中的示例性操作1100中示出了此类算法在分布式边缘存储系统中恢复文件的一个示例性应用。在恢复数据的操作1100中,首先随机地选择1102小于t的随机存储节点(例如,t-∈存储节点)的子集。gk方法(例如,如上文关于图7和图8所描述的)应用1104于从存储节点的子集检索的分组。需注意,t是根据系统要求确定的系统参数。例如,可以设计分布式存储系统,使得t的平均误差小于或等于由系统管理员确定的可接受误差(例如,使用图9中的图表)。在图11的检索算法中,针对第一轮选择小于t的存储节点,即选择t-∈允许通过访问少于t的节点来确定是否可以使用少于t的节点来对文件分区进行解码。对于随机选择的节点,确定当前迭代的平均绝对值(maf1)1106。继而,随机地作出一个附加存储节点的选择1108。即,该方法包括迭代地添加另一个存储节点,并且包括从对应用gk的分组集添加的存储节点接收的分组。因此,操作1100包括将gk方法应用1110于具有附加随机节点的存储节点的新子集。确定新的平均绝对值(maf2)1114。比较操作1116将先前迭代的平均绝对值(maf1)与当前迭代的平均绝对值(maf2)之间的差进行比较。如果maf1和maf2之间的差大于迭代参数(δ),则操作不断迭代,直到根据maf1与maf2之间的差小于δ(系统设计人员可选择的参数)确定没有进一步的改进。一旦达到这样的条件,操作1100就包括将从gk方法的应用检索的文件分区的最新值返回1118到存储节点的最新子集。
[0097]
图13示出了适合于实现所公开的技术的各方面的处理装置1300的示例性示意图。例如,处理装置1300可包括存储处理模块1350,该存储处理模块包括如上所述的存储处理设备。因此,处理装置1300可包括存储处理设备,以用于根据前述讨论中的任一个处理文件的目的。处理系统1300包括一个或多个处理器单元1302、存储器1304、显示器1306和其他接
口1308(例如,按钮)。存储器1304通常包括易失性存储器(例如,ram)和非易失性存储器(例如,闪速存储器)两者。操作系统1310,诸如microsoft操作系统、apple macos操作系统或linux操作系统,驻留在存储器1304中并且由处理器单元1302执行,但应当理解,可以采用其他操作系统。
[0098]
一个或多个应用程序1312被加载在存储器1304中并且由处理器单元1302在操作系统1310上执行。应用程序1312可以从各种输入本地装置,诸如麦克风1334、输入附件1335(例如,小键盘、鼠标、触控笔、触摸板、操纵杆、安装在仪器上的输入件等)接收输入。另外,应用程序1312可以通过使用更多的通信收发器1330和天线1338来提供网络连接(例如,移动电话网络、),通过有线或无线网络与此类装置进行通信来从一个或多个远程装置诸如远程定位的智能装置接收输入。处理装置1300还可以包括各种其他部件,诸如定位系统(例如,全球定位卫星收发器)、一个或多个加速度计、一个或多个相机、音频接口(例如,麦克风1334、音频放大器和扬声器和/或音频插孔),以及存储装置1328。也可以采用其他配置。
[0099]
处理装置1300还包括电源1316,该电源由一个或多个电池或其他功率源供电并且向处理装置1300的其他部件提供电力。电源1316也可以连接到重写内置电池或其他功率源或对其再充电的外部功率源(未示出)。
[0100]
示例实施方式可以包括通过存储在存储器1304和/或存储装置1328中并由处理器单元1302处理的指令所体现的硬件和/或软件。存储器1304可以是主机设备或耦合到主机的附件的存储器。
[0101]
处理系统1300可以包括各种有形处理器可读存储介质和无形处理器可读通信信号。有形处理器可读存储可通过可由处理系统1300访问的任何可用的介质来体现并且包括易失性存储介质和非易失性存储介质、可移动存储介质和非可移动存储介质两者。有形处理器可读存储介质不包括无形通信信号并且包括以任何方法或技术实现以用于存储信息诸如处理器可读指令、数据结构、程序模块或其他数据的易失性和非易失性、可移动和非可移动存储介质。有形处理器可读存储介质包括但不限于ram、rom、eeprom、闪速存储器或其他存储器技术、cdrom、数字通用盘(dvd)或其他光盘存储装置、磁盒、磁带、磁盘存储装置或其他磁存储装置,或者可用于存储期望的信息并且可由处理系统1300访问的任何其他有形介质。与有形处理器可读存储介质相反,无形处理器可读通信信号可以体现驻留在诸如载波或其他信号传输机制的已调制数据信号中的处理器可读指令、数据结构、程序模块或其他数据。术语“已调制数据信号”是指一个或多个特性以在信号中编码信息的方式设定或改变的无形通信信号。作为示例而非限制,无形通信信号包括通过有线介质诸如有线网络或直接有线连接以及无线介质诸如声学、rf、红外和其他无线介质传播的信号。
[0102]
一些实施方式可以包括制品。制品可以包括用于存储逻辑的有形存储介质。存储介质的示例可以包括能够存储电子数据的一种或多种类型的处理器可读存储介质,包括易失性存储器或非易失性存储器、可移动或非可移动存储器、可擦除或非可擦除存储器、可写或可重写存储器等。逻辑的示例可包括各种软件元素,诸如软件组件、程序、应用、计算机程序、应用程序、系统程序、机器程序、操作系统软件、中间件、固件、软件模块、例程、子例程、操作段、方法、过程、软件接口、应用程序接口(api)、指令集、计算代码、计算机代码、代码段、计算机代码段、字词、值、符号或它们的任何组合。在一个实施方式中,例如,制品可以存
储可执行计算机程序指令,这些可执行计算机程序指令当由计算机执行时,使计算机执行依照所描述的实施方式的方法和/或操作。可执行计算机程序指令可以包括任何合适类型的代码,诸如源代码、编译代码、解释代码、可执行代码、静态代码、动态代码等。可以根据预定义计算机语言、方式或语法来实现可执行计算机程序指令,以用于指示计算机执行某个操作段。可以使用任何合适的高级、低级、面向对象的、可视的、编译的和/或解译的编程语言来实现指令。
[0103]
本公开的一个一般方面包括一种用于安全分布式存储关于多个分布式边缘存储节点中的文件的信息的方法。该方法包括选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络中的大小为|f|的文件的任何部分信息进行解码,该网络将文件分布式存储在ze以上的存储节点中。该方法还包括选择值zb,使得可通过将纠错码应用于从存储节点检索的信息来纠正来自zb存储节点的损坏的数据分组。该方法包括选择存储节点中最小化成本函数的n
*
,该成本函数包括|f|、ze、zb、初始数据访问成本c
t
,以及传输和下载成本cd。该方法包括最初从存储节点中的n
*
分配相等的存储器大小以存储文件、冗余纠错数据和一组线性码密钥。该方法还包括迭代地确定向n
*
存储节点添加更多存储节点的第一成本和从n
*
存储节点的子集分配更多存储器的第二成本。该方法包括基于将纠错码应用于线性码密钥集和用线性码密钥集掩蔽的文件分区来构造冗余数据分组,并且基于根据迭代确定来确定的最小成本,在存储节点的n≥n
*
中存储文件、线性码密钥和冗余数据分组。存储节点按照存储容量从大到小排序,使得最大的ze存储节点存储线性码密钥,最小的n-z
e-2zb存储节点存储文件分区,并且其余的2zb存储节点存储冗余分组。
[0104]
实施方式可以包括以下特征中的一个或多个特征。例如,n存储节点中的至少两个存储节点可以分配不同大小的存储器来存储文件。n存储节点可以从第一存储节点的最大存储容量到第n存储节点的最小容量排序。
[0105]
在一个示例中,成本函数包括等式式在一个示例中,根据四舍五入为整数来选择n
*
。
[0106]
在一个示例中,冗余量的数据存储在2zb存储中。冗余数据可以由纠错码的生成矩阵乘以包括线性码密钥和用线性码密钥掩蔽的文件分区的向量而生成。
[0107]
在一个示例中,该方法还可以包括从存储节点检索数据分组并且将(n,k)纠错码应用于数据分组。
[0108]
本公开的另一个一般方面包括分布式安全边缘存储系统。该系统包括可操作以访问具有多个边缘存储节点的网络的网络接口。存储处理设备耦合到网络。存储处理设备可操作以选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络内的大小为|f|的文件的任何部分信息进行解码,该网络将文件分布式存储在ze以上的存储节点中。存储处理设备还选择值zb,使得可以通过将纠错码应用于从存储节点检索的信息来纠正来自zb存储节点的损坏的数据分组。存储处理设备可操作以选择存储节点中最小化成本函数的n
*
存储节点,该成本函数包括|f|、ze、zb初始数据访问成本c
t
,以及传输和下载成本cd。存储处理设备最初从存储节点的n
*
存储节点分配相等的存储器大小以存储文件、冗余纠错数据和
一组线性码密钥。继而,存储处理设备迭代地确定将更多存储节点添加到n
*
存储节点的第一成本以及从n
*
存储节点的子集分配更多存储器的第二成本,并且基于将纠错码应用于线性码密钥集和用线性码密钥集掩蔽的文件分区来构建冗余数据分组。存储处理设备还基于根据迭代确定来确定的最小成本将文件、线性码密钥和冗余数据分组存储在存储节点中的n≥n
*
存储节点中。存储节点按照存储容量从大到小排序,使得最大的ze存储节点存储线性码密钥,最小的n-z
e-2zb存储节点存储文件分区,并且其余的2zb存储节点存储冗余分组。
[0109]
实施方式可以包括以下特征中的一个或多个特征。例如,n存储节点中的至少两个存储节点可以分配不同大小的存储器来存储文件。就此而言,n存储节点可以从第一存储节点处的最大存储容量到第n存储节点处的最小容量排序。
[0110]
在一个示例中,成本函数包括等式式n
*
的值可以根据四舍五入为整数来选择。冗余量的数据可以存储在其余的2zb存储中。冗余数据可以由纠错码的生成矩阵乘以包括线性码密钥和用线性码密钥掩蔽的文件分区的向量而生成。
[0111]
在一个示例中,存储处理设备进一步操作以从存储节点检索数据分组,并且将(n,k)纠错码应用于数据分组。
[0112]
本公开的另一个一般方面包括一种或多种有形处理器可读存储介质,该一种或多种有形处理器可读存储介质以用于在装置的一个或多个处理器和电路上执行用于在多个分布式边缘存储节点中安全分布式存储关于文件的信息的过程的指令来体现。该过程包括选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络内的大小为|f|的文件的任何部分信息进行解码,该网络将文件分布式存储在ze以上的存储节点中。该过程还包括选择值zb,使得可以通过将纠错码应用于从存储节点中检索的信息来纠正来自zb存储节点的损坏的数据分组。该过程还包括选择存储节点中最小化成本函数的n
*
存储节点,该成本函数包括|f|、ze、zb初始数据访问成本c
t
,以及传输和下载成本cd。继而,该过程包括最初分配来自存储节点的n
*
存储节点的相等存储器大小以存储文件、冗余纠错数据和一组线性码密钥,以及迭代地确定将更多存储节点添加到n
*
存储节点的第一成本,以及从n
*
存储节点的子集分配更多存储器的第二成本。冗余数据分组的构建基于将纠错码应用于线性码密钥的集合和用线性码密钥的集合掩蔽的文件的分区。基于根据迭代确定来确定的最小成本,该过程包括将文件、线性码密钥和冗余数据分组存储在存储节点中的n≥n
*
存储节点中。存储节点按存储容量从大到小排序,使得最大的ze存储节点存储线性码密钥,最小的n-z
e-2zb存储节点存储文件分区,并且冗余分组存储在其余的2zb存储节点中。
[0113]
实施方式可以包括以下特征中的一个或多个特征。例如,n存储节点中的至少两个存储节点可以分配不同大小的存储器来存储文件。就此而言,n存储节点可以从第一存储节点处的最大存储容量到第n存储节点处的最小容量排序。
[0114]
在一个示例中,成本函数可包括等式式n
*
的值可以根据四舍五入为整数来选择。
冗余量的数据可以存储在其余的2zb存储中。在一个示例中,冗余数据由纠错码的生成矩阵乘以包括线性码密钥和用线性码密钥掩蔽的文件分区的向量而生成。
[0115]
在一个示例中,该过程还包括从存储节点检索数据分组并且将(n,k)纠错码应用于数据分组。
[0116]
本公开的另一个一般方面包括一种用于安全地分布式存储关于多个分布式边缘存储节点中的文件的信息的方法。该方法包括选择经由网络连接的n存储节点,以存储大小为|f|的文件和大小为|f
red
|的冗余数据。n存储节点中的至少两个存储节点分配不同大小的存储器来存储文件。继而,n存储节点从第一存储节点处的最大存储容量|s1|到第n存储节点处的最小容量|sn|排序。n存储节点至少部分地基于对从最大数量的zb损坏的节点的n存储节点中选择的许多t随机节点的平均误差计算。该方法还包括选择ze<n的值,其中能够访问ze存储节点的攻击者无法对文件进行解码。该方法还包括将文件划分为文件分区,生成存储在n存储节点的前ze中的密钥,以及创建包括密钥和文件分区的独立线性组合的存储块。继而,该方法包括在ze 1至第n存储节点中存储包括密钥和文件分区的独立线性组合的存储分组。
[0117]
实施方式可以包括以下特征中的一个或多个特征。例如,存储块可包括作为文件分区的函数的第一部分和作为密钥的函数的第二部分。
[0118]
该方法还可以包括针对t的不同值计算从zb损坏的节点的n中选择的许多t随机节点的平均误差计算。该方法还包括建立可接受的误差值。继而,选择n的值,使得n所选择的节点的t随机节点的平均误差计算小于可接受误差。
[0119]
在一个示例中,该方法包括由授权用户通过选择小于t的n存储节点的子集来检索文件f的数据,以及从n存储节点的子集中检索存储分组,这些存储分组包括密钥和由来自n存储节点的子集t的每个相应节点的密钥掩蔽的文件分区的独立线性组合。该方法还包括建立多个线性方程,使用于生成被线性密钥码掩蔽的文件部分的线性密钥码的系数与所检索到的值相等。可以确定n存储节点的子集中的每个相应存储节点的平均残差。继而,该方法可包括从具有存储节点子集的最大平均残差的存储节点子集中移除所选择的数量的存储节点。该方法可包括针对预先确定的次数的迭代迭代地执行建立、确定和移除操作,并且从最终迭代的多个线性方程中提取文件部分的值。预先确定的迭代次数可以基于保证裕度参数kb和最大数量的zb损坏的节点。
[0120]
在一个示例中,检索操作还包括向n存储节点的子集中再添加一个随机存储节点并且从多个线性方程中提取文件部分的值。该方法还可以包括计算n存储节点的子集的先前迭代的第一平均绝对误差和包括另外的一个随机存储节点的n存储节点的子集的当前迭代的第二平均绝对误差。该方法还包括确定第一平均绝对误差和第二平均绝对误差之间的差是否低于迭代阈值。虽然第一平均绝对误差和第二平均绝对误差之间的差高于迭代阈值,但该方法可包括通过向n存储节点的子集添加一个附加存储节点来继续迭代。当第一平均绝对误差和第二平均绝对误差之间的差低于迭代阈值时,该方法可以包括根据从来自多个线性方程的解的最后一次迭代的多个线性方程的解中提取的文件信息来重建文件。
[0121]
另一个一般方面包括分布式安全边缘存储系统。该系统包括至少n存储节点,这些存储节点经由网络耦合以存储大小为|f|的文件和大小为|f
red
|的冗余数据。n存储节点中的至少两个存储节点分配不同大小的存储器来存储文件。n存储节点从第一存储节点的最
大存储容量|s1|到第n存储节点的最小容量|sn|排序。n存储节点至少部分地基于对从最大数量的zb损坏的节点的n存储节点中选择的许多t随机节点的平均误差计算。该系统还包括耦合到网络并且可操作以选择值ze<n的存储处理设备,其中能够访问ze存储节点的攻击者无法对文件进行解码。存储处理设备还可操作性以将文件划分为文件分区,生成存储在n存储节点中的前ze中的密钥,并且创建包括密钥和文件分区的独立线性组合的存储块。存储处理设备进一步操作以在ze 1至第n存储节点中存储包括密钥和文件分区的独立线性组合的存储分组。
[0122]
实施方式可以包括以下特征中的一个或多个特征。例如,存储块可包括作为文件分区的函数的第一部分和作为密钥的函数的第二部分。此外,存储处理设备可进一步操作以针对t的不同值计算从zb损坏的节点的n中选择的许多t随机节点的平均误差计算,并且建立可接受误差值。因此,可以选择n的值,使得n所选择的节点的t随机节点的平均误差计算小于可接受误差。
[0123]
在一个示例中,存储处理设备进一步操作以通过由授权用户选择小于t的n存储节点的子集检索文件f的数据,从包括密钥和由来自n存储节点的子集t的每个相应节点的密钥掩蔽的文件分区的独立线性组合的n存储节点的子集检索存储分组,并且建立多个线性方程,使用于生成由线性密钥码掩蔽的文件部分的线性密钥码的系数与所检索到的值相等。文件f的数据检索还可以包括确定n存储节点的子集中的每个相应存储节点的平均残差以及从存储节点子集的具有最大平均残差的存储节点子集中移除所选择的数量的存储节点。检索可以包括针对预先确定的次数的迭代迭代地执行建立、确定和移除操作,并且从最终迭代的多个线性方程中提取文件部分的值。预先确定的迭代次数可以基于保证裕度参数kb和最大数量的zb损坏的节点。
[0124]
在一个示例中,存储处理设备可进一步操作以通过向n存储节点的子集添加另外的一个随机存储节点并且从多个线性方程中提取文件部分的值来检索存储分组。继而,存储处理设备可操作以通过计算n存储节点子集的先前迭代的第一平均绝对误差和包括另一个随机存储节点的n存储节点的子集的当前迭代的第二平均绝对误差,以及确定第一平均绝对误差与第二平均绝对误差之间的差是否低于迭代阈值。当第一平均绝对误差和第二平均绝对误差之间的差高于迭代阈值时,存储处理设备通过向n存储节点的子集添加另外的一个存储节点来继续迭代。当第一平均绝对误差与第二平均绝对误差之间的差低于迭代阈值时,存储处理设备操作以根据从来自多个线性方程的解的最后一次迭代的多个线性方程的解中提取的文件信息来重建文件。
[0125]
本公开的另一个一般方面包括一种或多种有形处理器可读存储介质,该一种或多种有形处理器可读存储介质以用于在装置的一个或多个处理器和电路上执行用于在多个分布式边缘存储节点中安全分布式存储关于文件的信息的过程的指令来体现。该过程包括选择经由网络连接的n存储节点,以存储大小为|f|的文件和大小为|f
red
|的冗余数据。n存储节点中的至少两个存储节点分配不同大小的存储器用于存储文件,n存储节点从第一存储节点的最大存储容量|s1|到第n存储节点的最小容量|sn|重新排序,并且n存储节点至少部分地基于对于从最大数量zb损坏的节点的n中选择的许多t随机节点的平均误差计算。该过程还包括选择ze<n的值,其中能够访问ze存储节点的攻击者无法对文件进行解码。该过程还包括将文件划分为文件分区,生成存储在n存储节点的前ze中的密钥,以及创建包括密
钥和文件分区的独立线性组合的存储块。该过程还包括在ze 1至第n存储节点中存储包括密钥和文件分区的独立线性组合的存储分组。
[0126]
实施方式可以包括以下特征中的一个或多个特征。例如,存储块可包括作为文件分区的函数的第一部分和作为密钥的函数的第二部分。
[0127]
在一个示例中,该过程还可以包括针对t的不同值计算从zb损坏的节点的n节点中选择的许多t随机节点的平均误差计算,以及确定可接受误差值。n的值可以被选择为使得对于n所选择的节点的t随机节点的平均误差计算小于可接受误差。
[0128]
在一个示例中,该过程还包括由授权用户检索用于文件f的数据。检索可以包括选择小于t的n存储节点的子集,并且从n存储节点的子集中检索存储分组,该存储分组包括密钥和由来自n存储节点的子集t的每个相应节点的密钥掩蔽的文件分区的独立线性组合。检索可包括建立多个线性方程,使用于生成被线性密钥码掩蔽的文件部分的线性密钥码的系数与所检索到的值相等,并且确定n存储节点的子集中的每个相应存储节点的平均残差。该过程可以包括从存储节点子集的具有最大平均残差的存储节点子集中移除所选择的数量的存储节点,并且针对预先确定的次数的迭代迭代地执行建立、确定和移除操作。继而,该过程可以包括从最终迭代的多个线性方程提取文件部分的值。预先确定的迭代次数可以基于保证裕度参数kb和最大数量的zb损坏的节点。
[0129]
继而,检索操作还可以包括向n存储节点的子集中添加另外一个随机存储节点并且从多个线性方程中提取文件部分的值。检索可以包括计算n存储节点的子集的先前迭代的第一平均绝对误差和包括另外一个随机存储节点的n存储节点的子集的当前迭代的第二平均绝对误差,并且确定第一平均绝对误差和第二平均绝对误差之间的差是否低于迭代阈值。当第一平均绝对误差与第二平均绝对误差之间的差高于迭代阈值时,该过程包括通过将另外一个存储节点添加到n存储节点的子集而继续迭代。当第一平均绝对误差与第二平均绝对误差之间的差低于迭代阈值时,该过程包括根据从来自多个线性方程的解的最后一次迭代的多个线性方程的解中提取的文件信息来重建文件。
[0130]
本文所述的实施方式在一个或多个计算机系统中作为逻辑步骤实现。逻辑操作可以被实现为(1)在一个或多个计算机系统中执行的一系列处理器实现的步骤,并且实现为(2)一个或多个计算机系统内的互连机器或电路模块。实现方式是选择问题,取决于所利用的计算机系统的性能要求。因此,组成本文所述的实施方式的逻辑操作被不同地称为操作、步骤、对象或模块。此外,应当理解,除非另外明确地要求保护或者权利要求语言固有地需要特定顺序,否则可以任何顺序执行逻辑操作。
[0131]
进一步的示例
[0132]
示例1.一种用于安全分布式存储关于多个分布式边缘存储节点中的文件的信息的方法,包括:
[0133]
选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络中的大小为|f|的文件的任何部分信息进行解码,所述网络将所述文件分布式存储在所述ze以上的存储节点中;
[0134]
选择值zb,使得能够通过将纠错码应用于从所述存储节点中检索的信息来纠正来自zb存储节点的损坏的数据分组;
[0135]
选择所述存储节点中最小化成本函数的n
*
存储节点,所述成本函数包括|f|、ze、zb初始数据访问成本c
t
,以及传输和下载成本cd;
[0136]
最初从所述存储节点中的n
*
分配相等的存储器大小以存储所述文件、冗余纠错数据和一组线性码密钥;
[0137]
迭代地确定将更多存储节点添加到所述n
*
存储节点的第一成本以及从所述n
*
存储节点的子集分配更多存储器的第二成本;
[0138]
基于将纠错码应用于所述线性码密钥集和用所述线性码密钥集掩蔽的所述文件的分区来构建所述冗余数据分组;以及
[0139]
基于根据迭代确定来确定的最小成本在所述存储节点中的n≥n
*
存储节点中存储所述文件、所述线性码密钥和所述冗余数据分组,所述存储节点按存储容量从大到小排序,使得最大的ze存储节点存储所述线性码密钥,最小的n-z
e-2zb存储节点存储所述文件的所述分区,并且所述冗余数据分组存储在其余的2zb存储节点中。
[0140]
示例2.如示例1所述的方法,其中所述n存储节点中的至少两个存储节点分配不同大小的存储器以用于存储所述文件,所述n存储节点从所述第一存储节点的最大存储容量到所述第n存储节点的最小容量排序。
[0141]
示例3.如示例1所述的方法,其中所述成本函数包括括
[0142]
示例4.如示例1所述的方法,其中根据四舍五入为整数来选择n
*
。
[0143]
示例5.如示例1所述的方法,其中冗余量的数据存储在所述2zb存储中。
[0144]
示例6.如示例5所述的方法,其中所述冗余数据由所述纠错码的生成矩阵乘以包括所述线性码密钥和用所述线性码密钥掩蔽的所述文件分区的向量而生成。
[0145]
示例7.如示例1所述的方法,还包括:
[0146]
从所述存储节点检索数据分组;以及
[0147]
将(n,k)纠错码应用于所述数据分组。
[0148]
示例8.一种分布式安全边缘存储系统,包括:
[0149]
网络接口,所述网络接口可操作以访问具有多个边缘存储节点的网络;
[0150]
存储处理设备,所述存储处理设备耦合到所述网络并且能够操作以进行以下操作:
[0151]
选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络中的大小为|f|的文件的任何部分信息进行解码,所述网络将所述文件分布式存储在所述ze以上的存储节点中;
[0152]
选择值zb,使得能够通过将纠错码应用于从所述存储节点中检索的信息来纠正来自zb存储节点的损坏的数据分组;
[0153]
选择所述存储节点中最小化成本函数的n
*
存储节点,所述成本函数包括|f|、ze、zb初始数据访问成本c
t
,以及传输和下载成本cd;
[0154]
最初从所述存储节点中的n
*
存储节点分配相等的存储器大小以存储所述文件、冗
余纠错数据和一组线性码密钥;
[0155]
迭代地确定将更多存储节点添加到n
*
存储节点的第一成本以及从n
*
存储节点的子集分配更多存储器的第二成本;
[0156]
基于将纠错码应用于所述线性码密钥集和用所述线性码密钥集掩蔽的所述文件的分区来构建所述冗余数据分组;以及
[0157]
基于根据迭代确定来确定的最小成本在存储节点中的n≥n
*
存储节点中存储所述文件、所述线性码密钥和所述冗余数据分组,所述存储节点按存储容量从大到小排序,使得最大的ze存储节点存储所述线性码密钥,最小的n-z
e-2zb存储节点存储所述文件的所述分区,并且所述冗余数据分组存储在其余的2zb存储节点中。
[0158]
示例9.如示例8所述的系统,其中所述n存储节点中的至少两个存储节点分配不同大小的存储器以用于存储所述文件,所述n存储节点从所述第一存储节点的最大存储容量到所述第n存储节点的最小容量排序。
[0159]
示例10.如示例8所述的系统,其中所述成本函数包括,其中所述成本函数包括
[0160]
示例11.如示例8所述的系统,其中根据四舍五入为整数来选择n
*
。
[0161]
示例12.如示例8所述的系统,其中冗余量的数据存储在所述其余的2zb存储中。
[0162]
示例13.如示例12所述的系统,其中所述冗余数据由所述纠错码的生成矩阵乘以包括所述线性码密钥和用所述线性码密钥掩蔽的所述文件分区的向量而生成。
[0163]
示例14.如示例8所述的系统,其中所述存储处理设备进一步操作以进行以下操作:
[0164]
从所述存储节点检索数据分组;以及
[0165]
将(n,k)纠错码应用于所述数据分组。
[0166]
示例15.一种或多种有形处理器可读存储介质,所述一种或多种有形处理器可读存储介质以用于在装置的一个或多个处理器和电路上执行用于在多个分布式边缘存储节点中安全分布式存储关于文件的信息的过程的指令来体现,所述过程包括:
[0167]
选择值ze,使得能够访问ze存储节点的窃听攻击者无法对存储在网络中的大小为|f|的文件的任何部分信息进行解码,所述网络将所述文件分布式存储在所述ze以上的存储节点中;
[0168]
选择值zb,使得能够通过将纠错码应用于从所述存储节点中检索的信息来纠正来自zb存储节点的损坏的数据分组;
[0169]
选择所述存储节点中最小化成本函数的n
*
存储节点,所述成本函数包括|f|、ze、zb初始数据访问成本c
t
,以及传输和下载成本cd;
[0170]
最初从所述存储节点中的n
*
分配相等的存储器大小以存储所述文件、冗余纠错数据和一组线性码密钥;
[0171]
迭代地确定将更多存储节点添加到所述n
*
存储节点的第一成本以及从所述n
*
存储
节点的子集分配更多存储器的第二成本;
[0172]
基于将纠错码应用于所述线性码密钥集和用所述线性码密钥集掩蔽的所述文件的分区来构建所述冗余数据分组;以及
[0173]
基于根据迭代确定来确定的最小成本在所述存储节点中的n≥n
*
存储节点中存储所述文件、所述线性码密钥和所述冗余数据分组,所述存储节点按存储容量从大到小排序,使得最大的ze存储节点存储所述线性码密钥,最小的n-z
e-2zb存储节点存储所述文件的所述分区,并且所述冗余数据分组存储在其余的2zb存储节点中。
[0174]
示例16.如示例15所述的一个或多个有形处理器可读存储介质,其中所述n存储节点中的至少两个存储节点分配不同大小的存储器以用于存储所述文件,所述n存储节点从所述第一存储节点的最大存储容量到所述第n存储节点的最小容量排序。
[0175]
示例17.如示例16所述的一种或多种有形处理器可读存储介质,其中所述成本函数包括
[0176]
示例18.如示例17所述的一个或多个有形处理器可读存储介质,其中根据四舍五入为整数来选择n
*
。
[0177]
示例19.如示例15所述的一个或多个有形处理器可读存储介质,其中冗余量的数据存储在所述其余的2zb存储中。
[0178]
示例20.如示例19所述的一个或多个有形处理器可读存储介质,其中所述冗余数据由所述纠错码的生成矩阵乘以包括所述线性码密钥和用所述线性码密钥掩蔽的所述文件分区的向量而生成。
[0179]
示例21.如示例15所述的一个或多个有形处理器可读存储介质,其中所述过程还包括:
[0180]
从所述存储节点检索数据分组;以及
[0181]
将(n,k)纠错码应用于所述数据分组。
[0182]
示例22.一种用于安全分布式存储关于多个分布式边缘存储节点中的文件的信息的方法,包括:
[0183]
选择经由网络耦合的n存储节点以存储大小为|f|的文件和大小为|f
red
|的冗余数据,其中所述n存储节点中的至少两个存储节点分配不同大小的存储器用于存储所述文件,所述n存储节点从所述第一存储节点的最大存储容量|s1|到所述第n存储节点的最小容量|sn|排序,并且所述n存储节点至少部分地基于对从最大数量的zb损坏的节点的n随机节点中选择的许多t随机节点的平均误差计算;
[0184]
选择ze<n的值,其中能够访问ze存储节点的攻击者无法对所述文件进行解码;
[0185]
将所述文件分成文件分区;
[0186]
生成存储在所述n存储节点的前ze存储节点中的密钥;
[0187]
创建包括所述密钥和所述文件分区的独立线性组合的存储块;以及
[0188]
在ze 1至第n存储节点中存储包括所述密钥和所述文件分区的独立线性组合的所述存储分组。
[0189]
示例23.如示例22所述的方法,其中所述存储块包括作为所述文件分区的函数的
第一部分和作为所述密钥的函数的第二部分。
[0190]
示例24.如示例23所述的方法,还包括
[0191]
针对t的不同值,计算从zb损坏的节点的n随机节点中选择的许多t随机节点的平均误差计算;
[0192]
确定可接受的误差值;并且
[0193]
其中选择n,使得所述n所选择的节点的t随机节点的所述平均误差计算小于所述可接受误差。
[0194]
示例25.如示例23所述的方法,还包括:
[0195]
授权用户通过以下方式检索所述文件f的数据:
[0196]
选择小于t的所述n存储节点的子集;
[0197]
从包括密钥和用来自所述n存储节点的所述子集t的每个相应节点的密钥掩蔽的文件分区的独立线性组合的所述n存储节点的所述子集中检索存储分组;
[0198]
建立多个线性方程,所述多个线性方程使用于生成用所述线性密钥码掩蔽的所述文件部分的所述线性密钥码的系数与所检索的值相等;
[0199]
确定所述n存储节点的所述子集中的每个相应存储节点的平均残差;
[0200]
从所述存储节点的所述子集的平均残差最大的所述存储节点的所述子集中移除所选择的数量的存储节点;
[0201]
针对预先确定的次数的迭代迭代地执行建立、确定和移除操作;以及
[0202]
从最终迭代的所述多个线性方程中提取所述文件部分的所述值。
[0203]
示例26.如示例25所述的方法,其中所述预先确定的数量的迭代基于保证裕度参数kb和最大数量的zb损坏的节点。
[0204]
示例27.如示例25所述的方法,其中所述检索操作还包括:
[0205]
向所述n存储节点的所述子集添加另一个随机存储节点;
[0206]
从所述多个线性方程中提取所述文件部分的所述值;
[0207]
计算所述n存储节点的所述子集的先前迭代的第一平均绝对误差和包括所述另一个随机存储节点的n存储节点的所述子集的当前迭代的第二平均绝对误差;以及
[0208]
确定所述第一平均绝对误差与所述第二平均绝对误差之间的差是否低于迭代阈值。
[0209]
示例28.如示例27所述的方法,其中虽然所述第一平均绝对误差与所述第二平均绝对误差之间的所述差高于迭代阈值,但通过向所述n存储节点的所述子集添加一个附加的存储节点来继续迭代。
[0210]
示例29.如示例28所述的方法,其中当所述第一平均绝对误差与所述第二平均绝对误差之间的差低于迭代阈值时,根据从来自所述多个线性方程的解的最后一次迭代的所述多个线性方程的所述解中提取的文件信息来重建所述文件。
[0211]
示例30.一种分布式安全边缘存储系统,包括:
[0212]
至少n存储节点经由网络耦合以存储大小为|f|的文件和大小为|f
red
|的冗余数据,其中所述n存储节点中的至少两个存储节点分配不同大小的存储器用于存储所述文件,所述n存储节点从所述第一存储节点的最大存储容量|s1|到第n存储节点的最小容量|sn|排序,并且所述n存储节点至少部分地基于对从最大数量的zb损坏的节点的n中选择的许多t
随机节点的平均误差计算;
[0213]
存储处理设备,所述存储处理设备耦合到所述网络并且能够操作以进行以下操作:
[0214]
选择值ze<n,其中能够访问ze存储节点的攻击者无法对所述文件进行解码;
[0215]
将所述文件分为文件分区;
[0216]
生成存储在所述n存储节点的前ze存储节点中的密钥;
[0217]
创建包括所述密钥和所述文件分区的独立线性组合的存储块;以及
[0218]
在ze 1至第n存储节点中存储包括所述密钥和所述文件分区的独立线性组合的所述存储分组。
[0219]
示例31.如示例30所述的系统,其中所述存储块包括作为所述文件分区的函数的第一部分和作为所述密钥的函数的第二部分。
[0220]
示例32.如示例30所述的系统,其中所述存储处理设备进一步操作以进行以下操作:
[0221]
针对t的不同值,计算从zb损坏的节点的n中选择的许多t随机节点的平均误差计算;
[0222]
确定可接受的误差值;并且
[0223]
其中选择n,使得所述n所选择的节点的t随机节点的所述平均误差计算小于所述可接受误差。
[0224]
示例33.如示例30所述的系统,其中所述存储处理设备进一步操作以进行以下操作:
[0225]
授权用户通过以下方式检索所述文件f的数据:
[0226]
选择小于t的所述n存储节点的子集;
[0227]
从包括密钥和用来自所述n存储节点的所述子集t的每个相应节点的密钥掩蔽的文件分区的独立线性组合的所述n存储节点的所述子集中检索存储分组;
[0228]
建立多个线性方程,所述多个线性方程使用于生成用所述线性密钥码掩蔽的所述文件部分的所述线性密钥码的系数与所检索的值相等;
[0229]
确定所述n存储节点的所述子集中的每个相应存储节点的平均残差;
[0230]
从所述存储节点的所述子集的平均残差最大的所述存储节点的所述子集中移除所选择的数量的存储节点;
[0231]
针对预先确定的次数的迭代迭代地执行建立、确定和移除操作;以及
[0232]
从最终迭代的所述多个线性方程中提取所述文件部分的所述值。
[0233]
示例34.如示例33所述的系统,其中所述预先确定的数量的迭代基于保证裕度参数kb和最大数量的zb损坏的节点。
[0234]
示例35.如示例34所述的系统,其中所述存储处理设备进一步操作以通过以下方式检索存储分组:
[0235]
向所述n存储节点的所述子集添加另一个随机存储节点;
[0236]
从所述多个线性方程中提取所述文件部分的所述值;
[0237]
计算所述n存储节点的所述子集的先前迭代的第一平均绝对误差和包括所述另一个随机存储节点的n存储节点的所述子集的当前迭代的第二平均绝对误差;以及
[0238]
确定所述第一平均绝对误差与所述第二平均绝对误差之间的差是否低于迭代阈值。
[0239]
示例36.如示例35所述的系统,其中当所述第一平均绝对误差与所述第二平均绝对误差之间的差高于迭代阈值时,通过向所述n存储节点的所述子集添加另外一个存储节点来继续迭代。
[0240]
示例37.如示例36所述的系统,其中当所述第一平均绝对误差与所述第二平均绝对误差之间的所述差低于迭代阈值时,根据从来自所述多个线性方程的解的最后一次迭代的所述多个线性方程的所述解中提取的文件信息来重建所述文件。
[0241]
示例38.一种或多种有形处理器可读存储介质,所述一种或多种有形处理器可读存储介质以用于在装置的一个或多个处理器和电路上执行用于在多个分布式边缘存储节点中安全分布式存储关于文件的信息的过程的指令来体现,所述过程包括:
[0242]
选择经由网络耦合的n存储节点来存储大小为|f|的文件和大小为|f
red
|的冗余数据,其中所述n存储节点中的至少两个存储节点分配不同大小的存储器用于存储所述文件,所述n存储节点从所述第一存储节点的最大存储容量|s1|到第n存储节点的最小容量|sn|排序,并且所述n存储节点至少部分地基于对从最大数量的zb损坏的节点的n中选择的许多t随机节点的平均误差计算;
[0243]
选择ze<n的值,其中能够访问ze存储节点的攻击者无法对所述文件进行解码;
[0244]
将所述文件分成文件分区;
[0245]
生成存储在所述n存储节点的前ze存储节点中的密钥;
[0246]
创建包括所述密钥和所述文件分区的独立线性组合的存储块;以及
[0247]
在ze 1至第n存储节点中存储包括所述密钥和所述文件分区的独立线性组合的所述存储分组。
[0248]
示例39.如示例38所述的一个或多个有形处理器可读存储介质,其中所述存储块包括作为所述文件分区的函数的第一部分和作为所述密钥的函数的第二部分。
[0249]
示例40.如示例38所述的一个或多个有形处理器可读存储介质,其中所述过程还包括:
[0250]
针对t的不同值,计算从zb损坏的节点的n随机节点中选择的许多t随机节点的平均误差计算;
[0251]
确定可接受的误差值;并且
[0252]
其中选择n,使得所述n所选择的节点的t随机节点的所述平均误差计算小于所述可接受误差。
[0253]
示例41.如示例38所述的一个或多个有形处理器可读存储介质,其中所述过程还包括:
[0254]
授权用户通过以下方式检索所述文件f的数据:
[0255]
选择小于t的所述n存储节点的子集;
[0256]
从包括密钥和用来自所述n存储节点的所述子集t的每个相应节点的密钥掩蔽的文件分区的独立线性组合的所述n存储节点的所述子集中检索存储分组;
[0257]
建立多个线性方程,所述多个线性方程使用于生成用所述线性密钥码掩蔽的所述文件部分的所述线性密钥码的系数与所检索的值相等;
[0258]
确定所述n存储节点的所述子集中的每个相应存储节点的平均残差;
[0259]
从所述存储节点的所述子集的平均残差最大的所述存储节点的所述子集中移除所选择的数量的存储节点;
[0260]
针对预先确定的次数的迭代迭代地执行建立、确定和移除操作;以及
[0261]
从最终迭代的所述多个线性方程中提取所述文件部分的所述值。
[0262]
示例42.如示例41所述的一个或多个有形处理器可读存储介质,其中所述预先确定的次数的迭代基于保证裕度参数kb和所述最大数量的zb损坏的节点。
[0263]
示例43.如示例41所述的一种或多种有形处理器可读存储介质,其中所述检索操作还包括:
[0264]
向所述n存储节点的所述子集添加另一个随机存储节点;
[0265]
从所述多个线性方程中提取所述文件部分的所述值;
[0266]
计算所述n存储节点的所述子集的先前迭代的第一平均绝对误差和包括所述另一个随机存储节点的n存储节点的所述子集的当前迭代的第二平均绝对误差;以及
[0267]
确定所述第一平均绝对误差与所述第二平均绝对误差之间的差是否低于迭代阈值。
[0268]
示例44.如示例43所述的一个或多个有形处理器可读存储介质,其中当所述第一平均绝对误差与所述第二平均绝对误差之间的差高于迭代阈值时,通过向所述n存储节点的所述子集添加另外一个存储节点来继续迭代。
[0269]
示例45.如示例44所述的一个或多个有形处理器可读存储介质,其中当所述第一平均绝对误差与所述第二平均绝对误差之间的差低于迭代阈值时,根据从来自所述多个线性方程的解的最后一次迭代中的所述多个线性方程的所述解中提取的所述文件信息来重建所述文件。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
