1.本发明涉及在秘密计算中对梯度下降法进行计算的技术。
背景技术:
2.梯度下降法是在深度学习或逻辑回归这样的机器学习中经常使用的学习算法。作为用于在秘密计算上进行使用梯度下降方法的机器学习的现有技术,有secureml(非专利文献1)和securenn(非专利文献2)。
3.最基本的梯度下降法虽然实现比较容易,但已知有容易陷入局部解、收敛慢等问题。为了解决这些问题,提出了针对梯度下降法的各种优化方法,特别是已知被称为adam的方法的收敛快。
4.现有技术文献
5.非专利文献
6.非专利文献1:payman mohassel and yupeng zhang,“secureml:a system for scalable privacy-preserving machine learning,”in ieee symposium on security and privacy,sp2017,pp.19-38,2017.
7.非专利文献2:sameer wagh,divya gupta,and nishanth chandran,“securenn:3-party secure computation for neural network training,”proceedings on privacy enhancing technologies,vol.1,p.24,2019.
技术实现要素:
8.发明要解决的课题
9.但是,由于在adam的处理中包含平方根的计算和除法运算,所以秘密计算中的处理成本变得非常大。另一方面,在通过单纯的梯度下降法来实现的现有技术中,由于在收敛之前所需的学习次数多,所以还存在整体的处理时间变长这样的问题。
10.鉴于如上所述的技术课题,本发明的目的在于提供一种能够在保持精度的状态下高速地进行秘密计算上的梯度下降法的计算的技术。
11.用于解决课题的手段
12.为了解决上述课题,本发明的第一方式的秘密梯度下降法计算方法是由包括多个秘密计算装置的秘密梯度下降法计算系统执行的、至少在将梯度g和参数w隐匿的状态下对梯度下降法进行计算的秘密梯度下降法计算方法,其中,设β1、β2、η、ε为预先确定的超参数(hyperparameter),
○
为每个元素的积,t为学习次数,[g]为梯度g的隐匿值,[w]为参数w的隐匿值,[m]、[m^]、[v]、[v^]、[g^]为元素数量与梯度g相等的矩阵m、m^、v、v^、g^的隐匿值,并设β^
1,t
、β^
2,t
、g^为下式,
[0013]
[公式7]
[0014][0015]
设adam为对将值v^的矩阵v^的隐匿值[v^]作为输入而输出值g^的矩阵g^的隐匿值[g^]的秘密批量映射(写像)进行计算的函数,各秘密计算装置的参数更新部计算[m]
←
β1[m] (1-β1)[g],参数更新部计算[v]
←
β2[v] (1-β2)[g]
○
[g],参数更新部计算[m^]
←
β^
1,t
[m],参数更新部计算[v^]
←
β^
2,t
[v],参数更新部计算[g^]
←
adam([v^]),参数更新部计算[g^]
←
[g^]
○
[m^],参数更新部计算[w]
←
[w]-[g^]。
[0016]
为了解决上述课题,本发明的第二方式的秘密深度学习方法是由包括多个秘密计算装置的秘密深度学习系统执行的、至少在将学习数据的特征量x、学习数据的正确答案数据t和参数w隐匿的状态下对深度神经网络进行学习的秘密深度学习方法,其中,设β1、β2、η、ε为预先确定的超参数,
·
为矩阵的积,
○
为每个元素的积,t为学习次数,[g]为梯度g的隐匿值,[w]为参数w的隐匿值,[x]为学习数据的特征量x的隐匿值,[t]为学习数据的正确答案标签t的隐匿值,[m]、[m^]、[v]、[v^]、[g^]、[u]、[y]、[z]为元素数量与梯度g相等的矩阵m、m^、v、v^、g^、u、y、z的隐匿值,并设β^
1,t
、β^
2,t
、g^为下式,
[0017]
[公式8]
[0018][0019]
设adam为对将值v^的矩阵v^的隐匿值[v^]作为输入而输出值g^的矩阵g^的隐匿值[g^]的秘密批量映射进行计算的函数,rshift为算术右移位,m为在一次学习中使用的学习数据的数量,h’为下式,
[0020]
[公式9]
[0021][0022]
设n为深度神经网络的隐藏层的数量,activation为隐藏层的激活函数,activation2为深度神经网络的输出层的激活函数,activation2’为与激活函数activation2对应的损失函数,activation’为激活函数activation的微分,各秘密计算装置的正向传播部计算[u1]
←
[w0]
·
[x],正向传播部计算[y1]
←
activation([u1]),正向传播部针对1以上且n-1以下的各i计算[u
i 1
]
←
[wi]
·
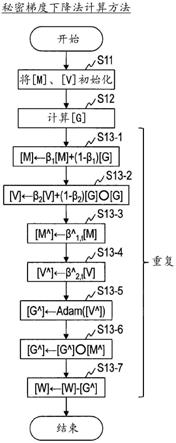
[yi],正向传播部针对1以上且n-1以下的各i计算[y
i 1
]
←
activation([u
i 1
]),正向传播部计算[u
n 1
]
←
[wn]
·
[yn],正向传播部计算[y
n 1
]
←
activation2([u
n 1
]),各秘密计算装置的反向传播部计算[z
n 1
]
←
activation2’([y
n 1
],[t]),反向传播部计算[zn]
←
activation’([un])
○
([z
n 1
]
·
[wn]),反向传播部针对1以上且n-1以下的各i计算[z
n-i
]
←
activation’([u
n-i
])
○
([z
n-i 1
]
·
[w
n-i
]),各秘密计算装置的梯度计算部计算[g0]
←
[z1]
·
[x],梯度计算部针对1以上且n-1以下的各i计算[gi]
←
[z
i 1
]
·
[yi],梯度计算部计算[gn]
←
[z
n 1
]
·
[yn],各秘密计算装置的参数更新部计算[g0]
←
rshift([g0],h’),参数更新部针对1以上且n-1以下的各i计算[gi]
←
rshift([gi],h’),参数更新部计算[gn]
←
rshift([gn],h’),参数更新部针对0以上且n以下的各i,通过第一方式的秘密梯度下降法计算方法,使用i层与i 1层之间的梯度[gi]来学习i层与i 1层之间的参数[wi]。
[0023]
发明效果
[0024]
根据本发明,能够在保持精度的状态下高速地进行秘密计算上的梯度下降法的计算。
附图说明
[0025]
图1是例示秘密梯度下降法计算系统的功能结构的图。
[0026]
图2是例示秘密计算装置的功能结构的图。
[0027]
图3是例示秘密梯度下降法计算方法的处理步骤的图。
[0028]
图4是例示秘密梯度下降法计算方法的处理步骤的图。
[0029]
图5是例示秘密深度学习系统的功能结构的图。
[0030]
图6是例示秘密计算装置的功能结构的图。
[0031]
图7是例示秘密深度学习方法的处理步骤的图。
[0032]
图8是例示计算机的功能结构的图。
具体实施方式
[0033]
首先,对本说明书中的表述方法和术语的定义进行说明。
[0034]
《表述方法》
[0035]
文中使用的记号
“→”
、“^”原本应该记载于紧前面的文字的正上方,但由于文本记法的限制而记载于该文字的紧后面。在公式中,这些记号记述于原本的位置、即文字的正上方。例如,“a
→”“a^”在公式中用下式表示。
[0036]
[公式10]
[0037][0038]
脚标中的“_(下划线)”表示下标。例如,x
y_z
表示yz是针对x的上标,x
y_z
表示yz是针对x的下标。
[0039]
将向量书写为a
→
:=(a0,
…
,a
n-1
)。将a用b定义的情况书写为a:=b。将相同的元素数量的两个向量a
→
与b
→
的内积书写为a
→
·b→
。另外,将两个矩阵的积书写为(
·
),将两个矩阵或向量的每个元素的积书写为(
○
)。没有书写运算符的是标量倍数。
[0040]
[a]表示通过秘密分散等加密后的a,称为“份额(share)”。
[0041]
《秘密批量映射》
[0042]
秘密批量映射是计算查找表的功能,是可以任意决定定义域和值域的技术。在秘密批量映射中以向量为单位进行处理,因此具有针对多个输入进行相同的处理时的效率高这样的性质。以下,示出秘密批量映射的具体的处理。
[0043]
将份额的列[a
→
]:=([a0],
…
,[a
m-1
])、定义域(x0,
…
,x
l-1
)及值域(y0,
…
,y
l-1
)作为输入,输出使各输入值映射后的份额、即对于0≤i<m为xj≤ai<xj 1且bi=yj那样的份额的列([b0],
…
,[b
m-1
])。秘密批量映射的详细情况参照参考文献1。
[0044]
〔参考文献1〕濱田浩気,五十嵐大,千田浩司,“秘匿計算上
の
一括写像
アルゴリズム”
,電子情報通信学会論文誌(滨田浩气,五十岚大,千田浩司,“隐匿计算上的批量映射算法”,电子信息通信学会论文志)a,vol.96,no.4,pp.157-165,2013.)
[0045]
《算术右移位》
[0046]
将份额的列[a
→
]:=([a0],
…
,[a
m-1
])和公开值t作为输入,输出将[a
→
]的各元素
算术右移位t位(bit)的[b
→
]:=([b0],
…
,[b
m-1
])。以下,将右移位表示为rshift。算术右移位是用符号位而不是0来填充左侧的移位,使用逻辑右移位rlshift,如式(1)~(3)那样构成rshift([a
×2n
],n-m)=[a
×2m
]。另外,逻辑右移位rlshift的详细情况参照参考文献2。
[0047]
[公式11]
[0048]
[a
′×2n
]=[a
×2n
] a
×2n
(a≥|a|)
…
(1)
[0049]
[a
′×2m
]=rlshift([a
′×2n
],n-m)
…
(2)
[0050]
[a
×2m
]=[a
′×2m
]-a
×2m
…
(3)
[0051]
〔参考文献2〕三品気吹,五十嵐大,濱田浩気,菊池亮,“高精度
かつ
高効率
な
秘密
ロジスティック
回帰
の
設計
と
実装”(三品气吹,五十岚大,滨田浩气,菊池亮,“高精度且高效率的秘密逻辑回归的设计与实现”),incss,2018.
[0052]
《优化方法adam》
[0053]
在单纯的梯度下降法中,对计算出的梯度g进行w=w-ηg(η为学习率)这样的处理来更新参数w。另一方面,在adam中对梯度进行式(4)~(8)的处理来更新参数。到计算梯度g为止的处理无论是在单纯的梯度下降法的情况下还是应用了adam的情况下都是相同的处理。另外,t是表示第几次学习的变量,g
t
表示第t次的梯度。另外,m、v、m^、v^是与g相同大小的矩阵,全部被初始化为0。
·
t(上标t)表示t次幂。
[0054]
[公式12]
[0055]mt 1
=β1m
t
(1-β1)g
t
…
(4)
[0056][0057][0058][0059][0060]
这里,β1、β2是接近1的常数,η是学习率,ε是用于防止在√v^
t 1
=0的情况下无法计算式(8)的情况的值。在adam的提议论文(参考文献3)中,β1=0.9,β2=0.999,η=0.001,ε=10-8
。
[0061]
〔参考文献3〕diederik p kingma and jimmy ba,“adam:a method for stochastic optimization,”arxiv preprint arxiv:1412.6980,2014.
[0062]
在adam中,与单纯的梯度下降法相比处理增加,因此一次学习所需的处理时间增加。另一方面,到收敛为止所需的学习次数大幅减少,因此学习所需的整体的处理时间变短。
[0063]
以下,对本发明的实施方式进行详细说明。另外,对附图中具有相同功能的结构部标注相同的标号,并省略重复说明。
[0064]
[第一实施方式]
[0065]
在第一实施方式中,使用秘密批量映射,在将梯度、参数、计算过程中的值隐匿的
状态下,实现梯度下降法的优化方法adam。
[0066]
在以下的说明中,用下式定义β^
1,t
、β^
2,t
、g^。
[0067]
[公式13]
[0068][0069][0070][0071]
预先针对各t计算β^
1,t
和β^
2,t
。g^的计算使用将v^作为输入并输出η/(√v^ ε)的秘密批量映射来实现。将该秘密批量映射表述为adam(v^)。设常数β1、β2、η、ε为明文。由于在g^的计算中包含平方根或除法运算,所以秘密计算中的处理成本较大。但是,通过使用秘密批量映射,一次处理即可,所以效率高。
[0072]
参照图1,说明第一实施方式的秘密梯度下降法计算系统的结构例。如图1所示,秘密梯度下降法计算系统100例如包括n(≥2)台秘密计算装置11、
…
、1n。在本实施方式中,秘密计算装置11、
…
、1n分别与通信网络9连接。通信网络9是构成为使相连接的各装置能够相互进行通信的电路交换方式或分组交换方式的通信网络,例如可以使用因特网或lan(local area network:局域网)、wan(wide area network:广域网)等。另外,各装置不一定需要能够经由通信网络9在线通信。例如,也可以构成为将向秘密计算装置11、
…
、1n输入的信息存储于磁带或usb存储器等便携式记录介质,并从该便携式记录介质向秘密计算装置11、
…
、1n离线输入。
[0073]
参照图2,说明第一实施方式的秘密梯度下降法计算系统100所包含的秘密计算装置1i(i=1,
…
,n)的结构例。如图2所示,秘密计算装置1i例如具备参数存储部10、初始化部11、梯度计算部12和参数更新部13。该秘密计算装置1i(i=1,
…
,n)通过一边与其他秘密计算装置1
i’(i’=1,
…
,n,其中i≠i’)协调一边进行后述的各步骤的处理,由此实现本实施方式的秘密梯度下降法计算方法。
[0074]
秘密计算装置1i例如是向具有中央运算处理装置(cpu:central processing unit,中央处理单元)、主存储装置(ram:random access memory,随机存取存储器)等的公知或专用的计算机读入特别的程序而构成的特别的装置。秘密计算装置1i例如在中央运算处理装置的控制下执行各处理。输入到秘密计算装置1i的数据和在各处理中得到的数据例如被存放于主存储装置,存放在主存储装置中的数据根据需要被读出到中央运算处理装置而用于其他处理。秘密计算装置1i的各处理部的至少一部分也可以由集成电路等硬件构成。秘密计算装置1i所具备的各存储部例如可以包括:ram(random access memory:随机存取存储器)等主存储装置;由硬盘、光盘或闪存(flash memory)那样的半导体存储器元件构成的辅助存储装置;或者关系型数据库、键值存储等中间件。
[0075]
参照图3,说明第一实施方式的秘密梯度下降法计算系统100执行的秘密梯度下降法计算方法的处理过程。
[0076]
在参数存储部10存储有预先确定的超参数β1、β2、η、ε。这些超参数只要设定为例如
参考文献3所记载的值即可。另外,在参数存储部10存储有预先计算出的超参数β^
1,t
、β^
2,t
。而且,在参数存储部10还存储有预先设定了定义域和值域的秘密批量映射adam。
[0077]
在步骤s11中,各秘密计算装置1i的初始化部11将矩阵m、v的隐匿值[m]、[v]初始化为0。矩阵m、v是与梯度g相同大小的矩阵。初始化部11将矩阵m、v的隐匿值[m]、[v]输出到参数更新部13。
[0078]
在步骤s12中,各秘密计算装置1i的梯度计算部12计算梯度g的隐匿值[g]。梯度g只要通过在应用梯度下降法的对象的处理(例如,逻辑回归或神经网络的学习等)中通常进行的方法求出即可。梯度计算部11将梯度g的隐匿值[g]输出到参数更新部13。
[0079]
在步骤s13-1中,各秘密计算装置1i的参数更新部13使用存储在参数存储部10中的超参数β1来计算[m]
←
β1[m] (1-β1)[g],更新矩阵m的秘密值[m]。
[0080]
在步骤s13-2中,各秘密计算装置1i的参数更新部13使用存储在参数存储部10中的超参数β2来计算[v]
←
β2[v] (1-β2)[g]
○
[g],更新矩阵v的隐匿值[v]。
[0081]
在步骤s13-3中,各秘密计算装置1i的参数更新部13使用存储在参数存储部10中的超参数β^
1,t
来计算[m^]
←
β^
1,t
[m],生成矩阵m^的隐匿值[m^]。矩阵m^成为元素数量与矩阵m相同(即,元素数量也与梯度g相同)的矩阵。
[0082]
在步骤s13-4中,各秘密计算装置1i的参数更新部13使用存储在参数存储部10中的超参数β^
2,t
来计算[v^]
←
β^
2,t
[v],生成矩阵v^的隐匿值[v^]。矩阵v^成为元素数量与矩阵v相同(即,元素数量也与梯度g相同)的矩阵。
[0083]
在步骤s13-5中,各秘密计算装置1i的参数更新部13使用秘密批量映射adam来计算[g^]
←
adam([v^]),生成矩阵g^的隐匿值[g^]。矩阵g^成为元素数量与矩阵v^相同(即,元素数量也与梯度g相同)的矩阵。
[0084]
在步骤s13-6中,各秘密计算装置1i的参数更新部13计算[g^]
←
[g^]
○
[m^],更新梯度g^的隐匿值[g^]。
[0085]
在步骤s13-7中,各秘密计算装置1i的参数更新部13计算[w]
←
[w]-[g^],更新参数w的隐匿值[w]。
[0086]
将本实施方式的参数更新部13在步骤s13-1至步骤s13-7中执行的参数更新的算法表示为algorithm1。
[0087]
algorithm1:使用秘密批量映射的秘密计算adam算法
[0088]
输入1:梯度[g]
[0089]
输入2:参数[w]
[0090]
输入3:用0初始化后的[m]、[v]
[0091]
输入4:超参数β1、β2、β^
1,t
、β^
2,t
[0092]
输入5:学习次数t
[0093]
输出1:更新后的参数[w]
[0094]
输出2:更新后的[m]、[v]
[0095]
1:[m]
←
β1[m] (1-β1)[g]
[0096]
2:[v]
←
β2[v] (1-β2)[g]
○
[g]
[0097]
3:[m^]
←
β^
1,t
[m]
[0098]
4:[v^]
←
β^
2,t
[v]
[0099]
5:[g^]
←
adam([v^])
[0100]
6:[g^]
←
[g^]
○
[m^]
[0101]
7:[w]
←
[w]-[g^]
[0102]
[第一实施方式的变形例1]
[0103]
在变形例1中,在构成在第一实施方式中所使用的秘密批量映射adam时,研究由定义域和值域构成的表的创建方法。
[0104]
输入到秘密批量映射adam的v^一定为正。另外,秘密批量映射adam是单调减少的函数,具有在v^接近0的部分斜率非常大、若v^变大则adam(v^)缓慢地接近0的特征。在秘密计算中,从处理成本的观点出发,以定点数进行处理,所以不能处理以浮点数处理那样的非常小的小数。即,由于不会输入非常小的v^,因此不需要将adam(v^)的输出的值域设定得那么大。例如,只要如参考文献3那样设定各超参数,使v^的小数点以下的精度为20比特的情况下的adam(v^)的最大值为1左右即可。另外,adam(v^)的最小值只要根据所需的adam(v^)的精度来决定即可,因此通过决定输入v^和输出adam(v^)的精度,能够决定映射表的大小。
[0105]
[第一实施方式的变形例2]
[0106]
在变形例2中,在第一实施方式中,进一步如表1那样设定各变量的精度。
[0107]
[表1]
[0108]
变量精度(比特)wbwβ1,β2b
β
β^
1,tbβ^_1
β^
2,tbβ^_2
g^b
g^
[0109]
如图4所示,本变形例的参数更新部13在步骤s13-1之后执行步骤s13-11,在步骤s13-2之后执行步骤s13-12,在步骤s13-6之后执行步骤s13-13。
[0110]
在步骤s13-11中,各秘密计算装置1i的参数更新部13将矩阵m的隐匿值[m]算术右移位b
β
位。即,计算[m]
←
rshift([m],b
β
),更新矩阵m的隐匿值[m]。
[0111]
在步骤s13-12中,各秘密计算装置1i的参数更新部13将矩阵v的隐匿值[v]算术右移位b
β
位。即,计算[v]
←
rshift([v],b
β
),更新矩阵v的隐匿值[v]。
[0112]
在步骤s13-13中,各秘密计算装置1i的参数更新部13将矩阵g^的隐匿值[g^]算术右移位b
g^
b
β^_1
位。即,计算[g^]
←
rshift([g^],b
g^
b
β^_1
),更新矩阵g^的隐匿值[g^]。
[0113]
将本变形例的参数更新部13在步骤s13-1~s13-7和s13-11~s13-13中执行的参数更新的算法表示为algorithm2。
[0114]
algorithm2:使用秘密批量映射的秘密计算adam算法
[0115]
输入1:梯度[g]
[0116]
输入2:参数[w]
[0117]
输入3:用0初始化后的[m]、[v]
[0118]
输入4:超参数β1、β2、β^
1,t
、β^
2,t
[0119]
输入5:学习次数t
[0120]
输出1:更新后的参数[w]
[0121]
输出2:更新后的[m]、[v]
[0122]
1:[m]
←
β1[m] (1-β1)[g]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
β
)
[0123]
2:[m]
←
rshift([m],b
β
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0124]
3:[v]
←
β2[v] (1-β2)[g]
○
[g]
ꢀꢀꢀꢀ
(精度:2bw b
β
)
[0125]
4:[v]
←
rshift([v],b
β
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw)
[0126]
5:[m^]
←
β^
1,t
[m]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
β^_1
)
[0127]
6:[v^]
←
β^
2,t
[v]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
β^_2
)
[0128]
7:[g^]
←
adam([v^])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:b
g^
)
[0129]
8:[g^]
←
[g^]
○
[m^]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:b
g^
bw b
β^_1
)
[0130]
9:[g^]
←
rshift([g^],b
g^
b
β^_1
)
ꢀꢀ
(精度:bw)
[0131]
10:[w]
←
[w]-[g^]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0132]
在本变形例中,以如下方式对精度的设定进行研究。这里的精度表示小数点部分的比特数,例如在将变量w设定为精度bw比特(bit)的情况下,实际的值为w
×2b_w
。另外,由于每个变量的值域不同,所以可以根据各个值域来决定精度。例如,w容易成为小的值,并且在机器学习中参数是非常重要的值,所以增大小数点部分的精度更为优选。另一方面,超参数β1、β2等在参考文献3中被设定为0.9或0.999左右,因此增大小数点部分的精度的必要性低。通过这样的研究,能够尽量抑制整体的比特数,即使在处理成本大的秘密计算中也能够高效地进行计算。
[0133]
在本变形例中,对右移位进行了如下的研究。在秘密计算中,从处理成本的观点出发,不是以浮点数而是以定点数进行处理的情况更为高速,但在定点数中,小数点位置在每次乘法运算时发生变化,因此需要通过右移位来进行调节。但是,在秘密计算中右移位是成本较高的处理,因此尽量减少进行右移位的次数更优。另外,秘密批量映射具有能够任意地设定值域和定义域的性质,因此也能够如右移位那样调节位数。根据这样的秘密计算和秘密批量映射的特征,如本变形例那样进行处理时效率更高。
[0134]
[第二实施方式]
[0135]
在第二实施方式中,通过使用秘密批量映射而实现的优化方法adam进行深度学习。在该例中,在将学习数据、学习标签和参数隐匿的状态下进行深度学习。在隐藏层和输出层中使用的激活函数可以使用任何函数,神经网络的模型的形式也是任意的。在此,对隐藏层的数量为n层的深度神经网络进行学习。即,将l设为层的编号,输入层为l=0,输出层为l=n 1。根据第二实施方式,与使用单纯的梯度下降法的现有技术相比,即使学习次数少也能够得到良好的学习结果。
[0136]
参照图5,说明第二实施方式的秘密深度学习系统的结构例。如图5所示,秘密深度学习系统200例如包括n(≥2)台秘密计算装置21、
…
、2n。在本实施方式中,秘密计算装置21、
…
、2n分别与通信网络9连接。通信网络9是构成为使相连接的各装置能够相互进行通信的电路交换方式或分组交换方式的通信网络,例如可以使用因特网或lan(local area network:局域网)、wan(wide area network:广域网)等。另外,各装置不一定需要能够经由通信网络9在线通信。例如,也可以构成为将向秘密计算装置21、
…
、2n输入的信息存储于磁带或usb存储器等便携式记录介质,并从该便携式记录介质向秘密计算装置21、
…
、2n离线输入。
[0137]
参照图6,说明第二实施方式的秘密深度学习系统200所包含的秘密计算装置2i(i=1,
…
,n)的结构例。如图6所示,秘密计算装置2i例如与第一实施方式同样地具备参数存储部10、初始化部11、梯度计算部12及参数更新部13,还具备学习数据存储部20、正向传播计算部21及反向传播计算部22。该秘密计算装置2i(i=2,
…
,n)通过一边与其他秘密计算装置2
i’(i’=1,
…
,n,其中i≠i’)协调一边进行后述的各步骤的处理,由此实现本实施方式的秘密深度学习方法。
[0138]
参照图7,说明第二实施方式的秘密深度学习系统200执行的秘密深度学习方法的处理过程。
[0139]
在学习数据存储部20存储有学习数据的特征量x的隐匿值[x]及学习数据的正确答案标签t的隐匿值[t]。
[0140]
在步骤s11中,各秘密计算装置2i的初始化部11将参数w的隐匿值[w]:=([w0],
…
,[wn])初始化。参数的初始化方法按照激活函数等来选择。例如,已知在中间层的激活函数使用relu函数的情况下,如果使用参考文献4所记载的初始化方法,则容易得到良好的学习结果。
[0141]
〔参考文献4〕kaiming he,xiangyu zhang,shaoqing ren,and jian sun,“delving deep into rectifiers:surpassing human-level performance on imagenet classification,”in proceedings of the ieee international conference on computer vision,pp.1026-1034,2015.
[0142]
在步骤s21中,各秘密计算装置2i的正向传播计算部21使用学习数据的特征量的隐匿值[x]来计算正向传播,求出各层的输出的隐匿值[y]:=([y1],
…
,[y
n 1
])。具体而言,计算[u1]
←
[w0]
·
[x]、[y1]
←
activation([u1]),针对1以上且n-1以下的各整数i计算[u
i 1
]
←
[wi]
·
[yi]、[y
i 1
]
←
activation([u
i 1
]),并计算[u
n 1
]
←
[wn]
·
[yn]、[y
n 1
]
←
activation2([u
n 1
])。其中,activation表示任意隐藏层的激活函数,activation2表示任意输出层的激活函数。
[0143]
在步骤s22中,各秘密计算装置2i的反向传播计算部22使用学习数据的正确答案标签的隐匿值[t]来计算反向传播,求出各层的误差的隐匿值[z]:=([z1],
…
,[z
n 1
])。具体而言,计算[z
n 1
]
←
activation2’([y
n 1
],[t])、[zn]
←
activation’([un])
○
([z
n 1
]
·
[wn]),并针对1以上且n-1以下的各整数i计算[z
n-i
]
←
activation’([u
n-i
])
○
([z
n-i 1
]
·
[w
n-i
])。这里,activation’表示激活函数activation的微分,activation2’表示与激活函数activation2对应的损失函数。
[0144]
在步骤s12中,各秘密计算装置2i的梯度计算部12使用学习数据的特征量的隐匿值[x]、各层的误差的隐匿值[z]和各层的输出的隐匿值[y]来计算各层的梯度的隐匿值[g]:=([g0],
…
,[gn])。具体而言,计算[g0]
←
[z1]
·
[x],针对1以上且n-1以下的各整数i计算[gi]
←
[z
i 1
]
·
[yi],并计算[gn]
←
[z
n 1
]
·
[yn]。
[0145]
在步骤s13中,各秘密计算装置2i的参数更新部13在将各层的梯度的隐匿值[g]以移位量h’右移位之后,按照第一实施方式的秘密梯度下降法计算方法,更新各层的参数的隐匿值[w]:=([w0],
…
,[wn])。具体而言,首先,计算[g0]
←
rshift([g0],h’),针对1以上且n-1以下的各整数i计算[gi]
←
rshift([gi],h’),并计算[gn]
←
rshift([gn],h’)。接着,针对0以上且n以下的各整数i计算[mi]
←
β1[mi] (1-β1)[gi]、[vi]
←
β2[vi] (1-β2)[gi]
○
[gi]、
[m^i]
←
β^
1,t
[mi]、[v^i]
←
β^
2,t
[vi]、[g^i]
←
adam([v^i])、[g^i]
←
[g^i]
○
[m^i]、[wi]
←
[wi]-[g^i]。
[0146]
将本实施方式的秘密深度学习系统200执行的基于使用秘密批量映射的adam的深度学习的算法表示为algorithm3。
[0147]
algorithm3:基于使用秘密批量映射的adam的深度学习算法
[0148]
输入1:学习数据的特征量[x]
[0149]
输入2:学习数据的正确答案标签[t]
[0150]
输入3:l层与l 1层之间的参数[w
l
]
[0151]
输出:更新后的参数[w
l
]
[0152]
1:将所有的[w]初始化
[0153]
2:(1)正向传播的计算
[0154]
3:[u1]
←
[w0]
·
[x]
[0155]
4:[y1]
←
activation([u1])
[0156]
5:for i=1to n-1do
[0157]
6:[u
i 1
]
←
[wi]
·
[yi]
[0158]
7:[y
i 1
]
←
activation([u
i 1
])
[0159]
8:end for
[0160]
9:[u
n 1
]
←
[wn]
·
[yn]
[0161]
10:[y
n 1
]
←
activation2([u
n 1
])
[0162]
11:(2)反向传播的计算
[0163]
12:[z
n 1
]
←
activation2’([y
n 1
],[t])
[0164]
13:[zn]
←
activation’([un])
○
([z
n 1
]
·
[wn])
[0165]
14:for i=1to n-1do
[0166]
15:[z
n-i
]
←
activation’([u
n-i
])
○
([z
n-i 1
]
·
[w
n-i
])
[0167]
16:end for
[0168]
17:(3)梯度的计算
[0169]
18:[g0]
←
[z1]
·
[x]
[0170]
19:for i=1to n-1do
[0171]
20:[gi]
←
[z
i 1
]
·
[yi]
[0172]
21:end for
[0173]
22:[gn]
←
[z
n 1
]
·
[yn]
[0174]
23:(4)参数的更新
[0175]
24:[g0]
←
rshift([g0],h’)
[0176]
25:for i=1to n-1do
[0177]
26:[gi]
←
rshift([gi],h’)
[0178]
27:end for
[0179]
28:[gn]
←
rshift([gn],h’)
[0180]
29:for i=0to n do
[0181]
30:[mi]
←
β1[mi] (1-β1)[gi]
[0182]
31:[vi]
←
β2[vi] (1-β2)[gi]
○
[gi]
[0183]
32:[m^i]
←
β^
1,t
[mi]
[0184]
33:[v^i]
←
β^
2,t
[vi]
[0185]
34:[g^i]
←
adam([v^i])
[0186]
35:[g^i]
←
[g^i]
○
[m^i]
[0187]
36:[wi]
←
[wi]-[g^i]
[0188]
37:end for
[0189]
在实际的深度学习中,执行algorithm3的步骤1的参数的初始化以外的处理,直到预先设定的学习次数或参数的变化量充分变小等收敛为止。
[0190]
在(1)正向传播的计算中按输入层、隐藏层、输出层的顺序进行计算,在(2)反向传播的计算中按输出层、隐藏层、输入层的顺序进行计算,但由于(3)梯度计算和(4)参数更新可以按各层并行地处理,所以通过汇总处理能够提高处理的效率。
[0191]
在本实施方式中,输出层和隐藏层的激活函数只要以如下方式设定即可。输出层中使用的激活函数根据想要进行的分析来选择。如果是数值预测(回归分析)则使用恒等函数f(x)=x,如果是疾病的诊断或垃圾邮件判定这样的2值的分类则使用s型函数1/(1 exp(-x)),如果是图像分类等3值以上的分类问题则使用归一化指数函数softmax(ui)=exp(ui)/∑
j=1k
exp(uj)等。隐藏层中使用的激活函数选择非线性函数,近年来频繁使用relu函数relu(u)=max(0,u)。已知relu函数即使在深度网络中也能够获得良好的学习结果,从而被频繁地用于深度学习领域。
[0192]
在本实施方式中,只要以如下方式设定批量大小即可。在计算梯度时,如果用rshift来处理批量大小为m的除法运算,则效率高。因此,批量大小m可以为2的幂数的值,此时的偏移量h’由式(9)求出。所谓批量大小,是在一次学习中使用的学习数据的件数。
[0193]
[公式14]
[0194][0195]
[第二实施方式的变形例1]
[0196]
在第二实施方式的深度学习中,如表2那样设定学习所使用的各值的精度。w是各层之间的参数,x是学习数据,t是与各学习数据对应的正确答案数据(教师数据)。隐藏层的激活函数的输出以与正确答案数据的精度相同的方式进行处理。另外,g^是通过秘密批量映射adam的计算而得到的值。
[0197]
[表2]
[0198]
变量精度(比特)wbwxb
x
tbyβ1,β2b
β
β^
1,tbβ^_1
β^
2,tbβ^_2
g^b
g^
[0199]
本变形例的正向传播计算部21在针对1以上且n-1以下的各整数i计算i 1层的输出的隐匿值[y
i 1
]之后,将[y
i 1
]右移位bw位。即,计算[y
i 1
]
←
rshift([y
i 1
],bw)。
[0200]
本变形例的反向传播计算部22在计算出n层的误差的隐匿值[zn]之后,将[zn]算术右移位by位。即,计算[zn]
←
rshift([zn],by)。另外,在针对1以上且n-1以下的各整数i计算出n-i层的误差的隐匿值[z
n-i
]之后,将[z
n-i
]算术右移位bw位。即,计算[z
n-i
]
←
rshift([z
n-i
],bw)。
[0201]
本变形例的参数更新部13使输入层与1层隐藏层之间的梯度的隐匿值[g0]以移位量b
x
h’算术右移位,使从1层到n层的隐藏层之间的梯度的隐匿值[g1]、
…
、[g
n-1]以移位量bw b
x
h’算术右移位,并使n层隐藏层与输出层之间的梯度的隐匿值[gn]以移位量b
x
by h’算术右移位。另外,各层的参数的隐匿值[w]:=([w0],
…
,[wn])按照第一实施方式的变形例2的秘密梯度下降法计算方法进行更新。
[0202]
将本变形例的秘密深度学习系统200执行的基于使用秘密批量映射的adam的深度学习的算法表示为algorithm4。
[0203]
algorithm4:基于使用秘密批量映射的adam的深度学习算法
[0204]
输入1:学习数据的特征量[x]
[0205]
输入2:学习数据的正确答案标签[t]
[0206]
输入3:l层与l 1层之间的参数[w
l
]
[0207]
输出:更新后的参数[w
l
]
[0208]
1:将所有的[w]初始化
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0209]
2:(1)正向传播的计算
[0210]
3:[u1]
←
[w0]
·
[x]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
x
)
[0211]
4:[y1]
←
relu([u1])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
x
)
[0212]
5:for i=1to n-1do
[0213]
6:[u
i 1
]
←
[wi]
·
[yi]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
x
)
[0214]
7:[y
i 1
]
←
relu([u
i 1
])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
x
)
[0215]
8:[y
i 1
]
←
rshift([y
i 1
],bw)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
x
)
[0216]
9:end for
[0217]
10:[u
n 1
]
←
[wn]
·
[yn]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
x
)
[0218]
11:[y
n 1
]
←
softmax([u
n 1
])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:by)
[0219]
12:(2)反向传播的计算
[0220]
13:[z
n 1
]
←
[y
n 1
]-[t]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:by)
[0221]
14:[zn]
←
relu’([un])
○
([z
n 1
]
·
[wn])
ꢀꢀꢀꢀꢀ
(精度:bw by)
[0222]
15:[zn]
←
rshift([zn],by)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0223]
16:for i=1to n-1do
[0224]
17:[z
n-i
]
←
relu’([u
n-i
])
○
([z
n-i 1
]
·
[w
n-i
])
ꢀꢀ
(精度:2bw)
[0225]
18:[z
n-i
]
←
rshift([z
n-i
],bw)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0226]
19:end for
[0227]
20:(3)梯度的计算
[0228]
21:[g0]
←
[z1]
·
[x]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
x
)
[0229]
22:for i=1to n-1do
[0230]
23:[gi]
←
[z
i 1
]
·
[yi]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
x
)
[0231]
24:end for
[0232]
25:[gn]
←
[z
n 1
]
·
[yn]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
x
by)
[0233]
26:(4)参数的更新
[0234]
27:[g0]
←
rshift([g0],b
x
h’)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0235]
28:for i=1to n-1do
[0236]
29:[gi]
←
rshift([gi],bw b
x
h’)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0237]
30:end for
[0238]
31:[gn]
←
rshift([gn],b
x
by h’)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0239]
32:for i=0to n do
[0240]
33:[mi]
←
β1[mi] (1-β1)[gi]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
β
)
[0241]
34:[mi]
←
rshift([mi],b
β
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0242]
35:[vi]
←
β2[vi] (1-β2)[gi]
○
[gi]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
β
)
[0243]
36:[vi]
←
rshift([vi],b
β
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw)
[0244]
37:[m^i]
←
β^
1,t
[mi]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw b
β^_1
)
[0245]
38:[v^i]
←
β^
2,t
[vi]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:2bw b
β^_2
)
[0246]
39:[g^i]
←
adam([v^i])
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:b
g^
)
[0247]
40:[g^i]
←
[g^i]
○
[m^i]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:b
g^
bw b
β^_1
)
[0248]
41:[g^i]
←
rshift([g^i],b
g^
b
β^_1
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0249]
42:[wi]
←
[wi]-[g^i]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(精度:bw)
[0250]
43:end for
[0251]
与第二实施方式同样地,通过将algorithm4中的步骤1的参数初始化以外的处理重复到收敛为止、或者重复所设定的学习次数,能够进行深度学习。针对进行精度的设定或右移位的部位,采用与第一实施方式的变形例2相同的办法。
[0252]
在(1)正向传播的计算中,在特征量x的精度b
x
不太大的情况下(例如若是图像数据的像素值则8比特就足够),bw b
x
在比特数上有余量,所以省略了右移位。另外,在(4)参数更新的计算中,用h’位的算术右移位来近似学习率和批量大小的除法运算,而且与用于精度调节的算术右移位同时地进行该除法运算,从而实现了效率化。
[0253]
《发明的要点》
[0254]
在本发明中,通过将梯度下降法的优化方法adam所包含的平方根或除法运算这样的秘密计算不擅长的计算汇总而视为一个函数,能够通过一次秘密批量映射来高效地进行优化方法adam的处理。由此,能够以比在秘密计算上进行机器学习的现有技术少的次数进行学习,能够将整体的处理时间抑制得较短。该优化方法与机器学习模型的形式无关,只要是使用梯度下降法进行学习的情况,则可以应用于任何模型。例如,可以在神经网络(深度学习)、逻辑回归、线性回归之类的各种机器学习中使用。
[0255]
这样,根据本发明,通过在秘密计算上实现梯度下降法的优化方法adam,即使在秘密计算中也能够以较少的学习次数进行具有较高预测性能的机器学习模型的学习。
[0256]
以上,对本发明的实施方式进行了说明,但具体的结构并不限于这些实施方式,即
使在不脱离本发明的主旨的范围内有适当的设计的变更等,也包含在本发明中,这是理所当然的。另外,实施方式中所说明的各种处理不仅可以按照记载的顺序以时间序列被执行,还可以根据执行处理的装置的处理能力或根据需要而并行地或单独地被执行。
[0257]
[程序、记录介质]
[0258]
在通过计算机来实现上述实施方式中所说明的各装置中的各种处理功能的情况下,各装置应具有的功能的处理内容通过程序来记述。并且,通过将该程序读入到图8所示的计算机的存储部1020中,使控制部1010、输入部1030、输出部1040等进行动作,由此在计算机上实现上述各装置中的各种处理功能。
[0259]
记述了该处理内容的程序可以记录于计算机可读取的记录介质。作为计算机可读取的记录介质,例如是磁记录装置、光盘、光磁记录介质、半导体存储器等任意介质。
[0260]
另外,该程序的流通例如通过对记录有该程序的dvd、cd-rom等便携式记录介质进行销售、转让、出借等来进行。而且,也可以形成为如下结构:将该程序存放于服务器计算机的存储装置,并经由网络,将该程序从服务器计算机转发到其他计算机,由此使该程序流通。
[0261]
执行这样的程序的计算机例如首先将记录在便携式记录介质中的程序或从服务器计算机转发的程序暂时存放于自己的存储装置。然后,在执行处理时,该计算机读取存放在自己的记录装置中的程序,并执行按照所读取的程序的处理。另外,作为该程序的其他执行方式,计算机也可以从便携式记录介质直接读取程序,并执行按照该程序的处理,而且,也可以在每次从服务器计算机向该计算机转发程序时,逐次执行按照所接受的程序的处理。另外,也可以形成为如下结构:利用不进行从服务器计算机向该计算机的程序的转发而仅通过该执行指示和结果取得来实现处理功能的、所谓asp(application service provider:应用服务提供商)型的服务,来执行上述的处理。此外,本方式中的程序包含供电子计算机的处理用且基于程序的信息(虽然不是对计算机的直接的指令,但是具有规定计算机的处理的性质的数据等)。
[0262]
另外,在本方式中,通过在计算机上执行规定的程序来构成本装置,但是也可以硬件性地实现这些处理内容的至少一部分。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。