1.本发明涉及一种基于机器学习的流程工业能耗评估及优化方法。
背景技术:
2.节能减排已是我国的一项基本国策,是可持续发展的必经之路;据了解,流程工业耗能是整个工业的70%左右,说明我国流程工业在节能降耗方面有着很大潜力,发展节能降耗在为企业减低成本、提高效益的同时,对社会、生态环境也有着重要意义,更符合我国经济的发展方向。
3.流程生产过程有着明显的多工况和不稳定性,每次调整控制量,工况都会有不一样和不稳定的变化,且多个控制量之间具有耦合性,因此,传统的数据分析方法很难剔除不稳定工况。
4.目前市场上有不少节能降耗的产品,但是大多是固态的模型或专家经验,对新的稳定工况和生产模式缺乏动态的灵活适用性。
技术实现要素:
5.针对上述现有技术的现状,本发明所要解决的技术问题在于提供一种能自动剔除不稳定工况并能定时更新以适用于新的生产工况,进而能灵活且实时评估当前能耗状态并输出调整建议以大幅提升适用性的基于机器学习的流程工业能耗评估及优化方法。
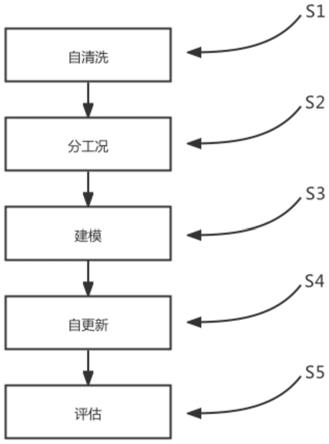
6.本发明解决上述技术问题所采用的技术方案为:一种基于机器学习的流程工业能耗评估及优化方法,其特征在于,包括以下步骤:
7.s1:自清洗,使用机器学习和特征配置对不同类型的数据进行清洗;
8.所述s1包括:
9.s11剔除停机和噪声,使用屏蔽测点与去噪算法相结合的方法剔除各个特征的停机和噪声数据;
10.s12:模式划分,区分不同生产工艺的数据;
11.s13:质量判断与特征筛选,剔除每种模式下不合格的质量数据和噪声过多的特征;
12.s2:分工况,主要使用机器学习将数据划分为不同工况,使用多维去噪算法进行数据的二次清洗;
13.所述s2包括:
14.s21:分工况,通过聚类或专家经验等方式,对模式数据集中的工况特征进行分类,得到不同模式下的各工况数据集;
15.s22:多维去噪,将每种工况下的台时和能耗进行多维密度去噪,使数据分布相对集中稳定;
16.s3:建模,根据权重确定该工况的产能最优点,并建立能耗的评估模型;
17.所述s3包括:
18.s31:工况寻优,基于台时与能耗的权重建立评价函数,从工况数据集中评价值最高的样本作为工况最优点;
19.s32:构建评估模型,根据台时与能耗的分布,用机器学习或专家经验确定其产能关系模型,并在关系模型的基础上定义不同能耗等级的评估方式;
20.s4:自更新,为适用于新的工况,选择性或定时的更新模型参数;
21.所述s4包括:
22.s41:制定模型更新触发机制;
23.s42:模型训练;
24.s5:评估,基于模型对数据进行实时评估;
25.所述s5包括:
26.s51:识别当前数据状态,根据屏蔽测点和特征的正常范围,识别当前是否为运行状态的正常数据;
27.s52:评估能耗水平;
28.s53:推送调整建议。
29.优选地,所述s11中的剔除停机和噪声,使用屏蔽测点和去噪算法相结合的方法剔除各个特征的噪声数据,包括但不限于以下步骤:
30.s111、对屏蔽测点中的每个特征变量先采用中值平滑剔除突变点,再用前值填充突变点,有效防止了假停机或假开机;再基于用户设置或自计算得到的开机门限和屏蔽规则得到整体的运行时间段,以此剔除所有其它变量的停机时段数据;
31.s112、在步骤s111的基础上,对每个特征从物理阈值、变化幅度、数据分布、数据稳定性等角度进行组合去噪。
32.优选地,所述步骤s12中的模式划分,区分不同生产工艺的数据,包括但不限于以下步骤:
33.s121:基于生产模式的组合条件将数据划分为不同生产工艺的模式数据集;
34.s122:在步骤s121的基础上,提取模式数据集的每个特征范围。
35.优选地,所述步骤s13中的质量判断与特征筛选,剔除每种模式下不合格的质量数据和噪声过多的特征,包括但不限于以下步骤:
36.s131:基于每种模式关注质量的合格条件,删除不合格的质量数据及其样本;
37.s132:在步骤s131的基础上,判断每个特征的噪声情况,剔除噪声数据较多的特征。
38.优选地,所述步骤s41包括以下方式:(1)配置信息更新触发训练;(2)按照模型更新周期触发训练;(3)模型训练失败触发的多次再训练。
39.优选地,所述步骤s52的评估能耗水平,包括但不限于以下步骤:
40.s521:在步骤s52的基础上,判断所属生产模式及其工况,计算同台时下的正常能耗水平;
41.s522:在步骤s521的基础上,输出同台时下的能耗评价、相对最优状态下的提升空间和质量是否合格等评估结果。
42.优选地,所述步骤s53的推送调整建议,包括但不限于以下步骤:s531:若质量合格,便在步骤s522的基础上,推送相对工况最优点下的可控变量的调整方向;若质量不合
格,便不推送此调整建议。
43.与现有技术相比,本发明的有益效果如下:
44.1、本发明具有自适应性,可在部署到新的生产系统后自动学习该系统工况并立刻应用;还可通过定时自动更新模型以迅速适应于新工况的应用。
45.2、本发明具有高效稳定的数据清洗算法,能自动清洗异常数据和不稳定工况。
46.3、本发明能关联质量下的能耗分析以更贴合用户需求。
47.4、本发明能实时输出节能降耗的操作方向性建议。
附图说明
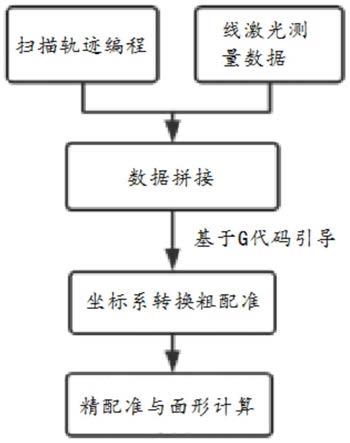
48.图1为本发明的框架流程图;
49.图2为本发明的基于屏蔽测点判断的运行状态图;
50.图3为本发明的操纵变量的清洗示意图;
51.图4为本发明的被控变量的清洗示意图;
52.图5为本发明的质量数据的清洗示意图;
53.图6为本发明的聚类分工况示意图;
54.图7为本发明的工况训练结果示意图;
55.图8为本发明的能耗报警评估结果示意示意图。
具体实施方式
56.除非另外定义,本发明使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。本发明中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
57.为了保持本发明实施例的以下说明清楚且简明,本发明省略了已知功能和已知部件的详细说明。
58.如图1所示,本实施例以某水泥厂某产线水泥磨为例,一种基于机器学习的流程工业能耗评估及优化方法,包括建模和评估两个步骤。
59.建模步骤:
60.(1)从数据库自动下载一定时间的历史数据,基于屏蔽测点的组合判断得到运行标志位label,如图2所示:标志位为1表示运行状态,0表示停机。
61.(2)针对每一个特征,分别剔除其停机数据,用上下限剔除异常,再用去噪算法对不同类型的数据进行清洗,本案例用到的去噪算法有:中值去噪、方差去噪、密度去噪、标准分数去噪,算法内容如下:中值去噪,配置中的有效字段有:kernel、e_limit。该方法是从数据连续变化的角度将中值平滑前后差值较大的点视为噪声,变量p=[p1,p2,
…
,pi,
…
pn],其中pi为变量p的第i个数值,该变量经中值平滑后为变量其中是
基于公式(1)以窗长为kernel所计算的pi对应的中值(kernel为奇数,用2k 1表示):
[0062][0063]
e_limit为变量p平滑前相对平滑后的幅度最大百分比,根据公式(2)计算差值门限limit=[l1,l2,
…
li,
…
ln]:
[0064][0065]
设中大于对应limit的数据视为噪声。
[0066]
方差去噪,配置中的有效字段有:kernel、zscore。该方法是从正常连续数据变化缓慢的角度将方差较大的点视为噪声,变量p对应的方差为s=[s1,s2,
…
si,
…
sn],其中si是基于公式(3)以窗长为kernel所计算的pi对应的方差(kernel为奇数,用2k 1表示):
[0067]
si=std([p
i-k
,
…
pi,
…
p
i k
])
ꢀꢀꢀ
(3)
[0068]
将方差s作为标准分数去噪。
[0069]
密度去噪(对dbscan改进后的算法),配置中的有效字段有:密度半径eps、邻域最小样本量n,首先为便于对稀疏度相同的变量做通用性的eps调整,基于公式(4)对变量p做最小最大归一化得到m=[m1,m2,
…
mi,
…mn
],。
[0070][0071]
其中,mi为变量m的第i个数值,min是求最小值的函数,max是求最大值的函数。基于欧式距离确定每个样本的n个最近邻样本集ns=[ns1,ns2,
…
nsi,
…
nsn],将与最近邻样本集的最大距离小于密度半径eps的样本视为邻域中心数据集,将中心数据集及其最近邻样本视为正常数据,其它数据视为噪声。
[0072]
标准分数去噪,配置中的有效字段有:zscore。该方法是从数据分布的角度将相对均值偏离较大的点视为噪声,变量p对应的标准值为z=[z1,z2,
…
zi,
…zn
],其中zi是基于公式(5)计算的pi偏离均值的大小:
[0073]
zi=|p
i-mean(p)|/std(p)
ꢀꢀꢀ
(5)
[0074]
zscore为偏离阈值,将z中大于zscore所对应的数据视为噪声。
[0075]
基于以上算法有很好的清洗效果:操控变量的清洗如图3所示,被控变量的清洗如图4所示,质量数据的清洗如图5所示,图中红色数据是被清洗掉的噪声。完成去噪后的数据集对齐合并为一个有效数据集d。
[0076]
(3)根据生产模式特征对清洗后的特征进行模式划分,每种模式下使用自动调参的聚类算法分工况,如图6所示,label表示聚类结果,也是工况类别。
[0077]
(4)针对每种工况,基于密度去噪算法等将原数据划分为三种类型数据:稀疏数据(蓝色点)、邻域中心数据(绿色点)、中心近邻点数据(橘色点),从邻域中心数据中选择评价函数最大值对应的样本为最优点,根据非稀疏数据集生成产耗关系曲线和包络线如图7所示。
[0078]
评估步骤:
[0079]
(1)判断出当前状态为运行的正常数据。
[0080]
(2)判断所属生产模式为半终粉的第一种工况,质量合格,输出对应工况下的提升空间为17.8%,如图8所示。
[0081]
(3)输出能耗评估和调整建议,如图8所示。
[0082]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的技术人员应当理解,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行同等替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神与范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。