1.本发明涉及大数据技术领域,具体涉及一种基于大数据的体育资讯推荐方法。
背景技术:
2.当前,互联网以及十分普及,人们获取体育资讯的方式已经发生了巨大改变,已经从平面媒体转向了互联网上的新媒体,越来越多的用户已经把网络作为获取体育资讯的第一选择,相关应用程序、网站的使用率出现持续性的增长。
3.于此同时,互联网巨大的承载能力也造成了在这些平台中每天用户能接收到的信息空前庞大,结合当前体育文化产业的蓬勃发展。越来越多的体育项目、运动员、运动队伍受到人们的关注,体育资讯的如何做到个性化推荐的问题日益凸显。面对这么多不同类目的资讯内容,用户每天将耗费大量时间来寻找自己感兴趣的内容,将直接影响到用户对于体育资讯平台的使用黏性,所以对平台来说解决这一需求也是十分必要的。
4.目前,许多平台的体育赛事和体育新闻资讯内容主要是靠事件热度和用户手动选择的兴趣标签作为推送依据,资讯分发系统多是基于此作为用户偏好依据向用户推荐相关体育赛事进程或是相关新闻资讯内容。但这样的推荐方式,分类比较粗糙且不够智能,已经无法满足用户日益多元且要求个性化、场景精准的体育信息需求,无法彻底解决个性化问题,影响用户的使用体验。
5.针对体育资讯的分发方式,许多体育资讯app也提出了很多解决方案:
6.一是将最新或最热门的新闻作为排序依据,在用户浏览新闻后,就会被系统记录下来,如果有许多用户作出浏览操作,将会被系统标记为热门新闻,从而推荐到资讯推荐列表当中,用户打开列表就可以看到热点和最新的体育新闻资讯。但是通过最新或热门方式进行排序推荐其缺点是太强调资讯内容的热门程度,而没有办法照顾到用户个性化的阅读需求。
7.二是通过搜索引擎来搜索感兴趣的内容关键词,通过用户主动的搜索如球队、运动员、运动项目等关键词的方式,搜索得出相关的体育资讯内容。通过搜索的方式比较适合用户主动获取感兴趣的新闻,不足之处在于需要用户主动提出自己的兴趣,过于依赖用户的主动操作,无法智能主动的向用户推荐其感兴趣的内容。
8.三是通过新闻类别模块分类的方式,这种方式将不同类别的新闻区分开,让用户可以根据自己感兴趣的类目,进行筛选阅读。通过新闻类别模块分类的方式,可以实现一定的个性化分类但还是比较粗糙,且也需要用户主动操作,无法直接替用户发现其已知或还未知的潜在兴趣内容。
9.四是通过个性化推荐算法,如根据不同人口统计数据如年龄、地域、职业、性别等。根据用户的阅读情况结合与其相似特征的用户进行协同推荐,让用户可以看到自己也可能感兴趣的新闻内容。通过通用的个性化推荐算法,虽然在电商、新闻、社交等诸多领域有所应用。但此类推荐系统多是针对综合类的新闻资讯内容,通用的推荐方法,在结合体育垂直类资讯平台上也面临着效果不佳的情况。比如体育类资讯中包含的球员、球队、多种运动项
目中的独特运动知识,无法做到对体育垂直领域的专精,并且此类用户身上所带有的体育垂直领域的用户标签也无法做到十分详细。
技术实现要素:
10.本发明的目的在于提供一种基于大数据的体育资讯推荐方法,以针对体育用户使用场景,提供个性化、实时精准推荐。为实现上述目的,本发明采用以下技术方案:
11.本发明公开了一种基于大数据的体育资讯推荐方法,包括以下过程:
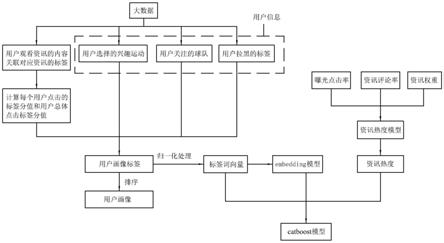
12.a.采集信息,获取用户浏览观看新闻或视频的相关信息。
13.b.存储信息,将a过程获得的相关信息集成至数据仓库中。
14.c.生成用户画像
15.c1.大数据分析:在云端对用户点击阅读行为日志进行精准分析,提取用户信息及用户观看资讯的内容,关联对应资讯的标签,根据一定时间内观看的资讯内容计算出每个用户点击的标签分值,和用户总体点击标签分值。
16.c2.建立用户画像标签:关联用户信息,根据总体标签分值衰减排序得到每个用户的画像标签,从而生成用户画像。
17.d.构建训练模型
18.d1.计算生成标签词向量和模型:对用户画像标签进行归一化处理,把每个画像标签归一化到0-1之间,转成对应的标签词向量,汇总用户在一段时间内点击的资讯的标签,训练得到对应的embedding模型。
19.d2.生成资讯热度模型:根据大数据实时计算资讯的曝光点击率、资讯评论率和人工设置的资讯权重生成资讯热度模型;根据资讯热度模型计算资讯热度。
20.d3.生成catboost模型:根据资讯热度、资讯的标签词向量、embedding模型进行离线训练,生成catboost模型。
21.e.资讯推荐
22.根据得到的catboost模型预测资讯候选池里用户喜好的资讯,精准推荐给用户。
23.其中,过程a中,通过用户授权获取用户浏览观看新闻或视频的相关信息,所述的相关信息包括:设备标识、新闻id、视频id、时间、进入页面次数、停留时长、标签、内容类别、播放百分比中的若干种信息。
24.优选的,过程b中,基于slb将数据分发到采集服务集群;采集服务集群将数据发布到kafka,再通过数据集成实时订阅kafka数据至数据仓库中。
25.优选的,过程c1中根据观看的资讯内容计算出每个用户点击的标签分值的方法为:
26.根据资讯内容标签频次衰减来计算,即用户观看一定时间对应的资讯中含有标签的总数为t个,其中内容a的标签出现的次数为s次,则内容a的标签分值x=s/t。
27.进一步的,过程c1中根据观看的资讯内容计算出每个用户点击的标签分值的方法还包括:根据资讯的观看时间衰减来计算,即定义初始的时间为t0,初始的时间t0内用户观看的资讯的标签的分数为f0,定义一个时间段,新的时间tn与初始的时间t0内有n个时间段,则时间tn内用户观看的资讯的标签的分数fn=(1 n)f0。
28.进一步的,过程c中用户信息包括:用户选择的兴趣运动、用户关注的球队、用户拉
黑的标签中的若干种。
29.优选的,过程d2中将重要新闻或视频设置资讯权重。资讯热度r采用如下计算公式计算:r=x y z,其中,x为资讯的曝光点击率、y为资讯评论率、z为资讯权重率;
[0030][0031]
其中,n1为用户从推荐列表浏览资讯内页的次数,n为资讯在推荐列表展示的次数;n为资讯的评论数,q为人工设置的资讯权重,t为从发布到当下的时间间隔,g为时间衰减因子。
[0032]
优选的,过程e中利用catboost模型进行树模型构建,基于资讯的热度排序后推荐给用户
[0033]
由于采用了上述方法,本发明具有以下有益效果:
[0034]
1、本发明可以依托平台内海量的体育用户的大数据,根据用户在体育资讯方面的使用习惯,大数据收集和分析用户对体育资讯阅读的行为喜好,通过大量的通用和体育领域专属的行为标签,形成体育用户的特征画像。通过协同catboost模型过滤推荐、embedding模型标签推荐,计算预测用户对不同资讯内容的喜好程度,结合资讯热度模型,进而从资讯候选池中向用户推送其更有可能喜欢的个性化阅读内容。最终达到解决体育资讯内容分发过程中无法满足用户个性化需求的问题。通过满足不同用户的个性化的体育资讯需求,减少用户筛选过滤感兴趣内容所耗费的时间。与此同时也提升了用户的阅读体验,可增加了用户阅读体育资讯的时长以及数量。
[0035]
2、本发明中将用户标签转成对应的词向量,方便后序计算新资讯的相似度,实现精准预测推荐。
[0036]
3、本发明基于大数据分析,实现了即时、热门资讯优先推荐,而后根据用户喜好智能精准预测用户感兴趣的资讯,从而实现体育资讯垂直领域的实时精准推荐。
[0037]
4、本发明采用大数据实时计算资讯的曝光点击率,结合大数据实时计算新闻评论率,把热度高的资讯实时、优先推送给用户。由于有些新发布的新闻比较重要,刚开始没有热度,没法优先推荐出来,为解决这个问题,本发明采用人工设置对应的权重,高权重的新闻将加上对应的热度,结合曝光点击率、资讯评论率计算出最终的资讯热度,从而实现智能精准实时推荐。
[0038]
5、本发明采用实用性极强的catboost算法,catboost能够直接处理类别型特征,同时提升了预测精度,具有较强的泛化性及较低的时间复杂度,还能兼顾分类问题与回归问题。但要实现精准的推荐,单一的类别特征还是远远不够的,本发明通过catboost的特征组合功能,增加用户点击标签特征词向量,用户总体点击标签embedding模型等组合特征,catboost在建模中还会根据特征的内在联系将原有类别型特征进行组合,从而丰富了特征维度。
[0039]
6、利用catboost排序的功能,在处理类别型变量和进行树模型构建时,基于资讯的热度排序,对资讯样本进行加工和计算,以获取目标变量统计值和模型梯度值的无偏估计,有效避免了预测偏移,达到新闻资讯尽最大限度的提升了资讯预测结果的实时性和精确性。
附图说明
[0040]
图1是本发明的推荐方法的流程示意图。
具体实施方式
[0041]
为了使本领域的技术人员更好地理解本发明的技术方案,下面结合附图和具体实施例对本发明作进一步详细的描述。
[0042]
本发明公开了一种基于大数据的体育资讯推荐方法,包括以下过程:
[0043]
a.采集信息
[0044]
通过用户授权获取用户浏览观看新闻或视频的相关信息。相关信息包括:设备标识、新闻id、视频id、时间、进入页面次数、停留时长、标签、内容类别、播放百分比中的若干种信息。
[0045]
b.存储信息
[0046]
将a过程获得的相关信息集成至数据仓库中,具体为:基于slb将数据分发到采集服务集群;采集服务集群将数据发布到kafka,再通过数据集成实时订阅kafka数据至数据仓库中。slb为服务负载均衡,通过对多台云服务器进行均衡的流量分发调度,以消除单点故障提升应用系统的可靠性与吞吐力。kafka是一种分布式的发布/订阅消息系统,具有高吞吐、低延迟、可扩展的性能优势。
[0047]
c.生成用户画像
[0048]
c1.大数据分析:如图1所示,在云端对用户点击阅读行为日志进行精准分析,提取用户信息,以及用户观看资讯的内容,关联对应资讯的标签,根据一定时间内观看的资讯内容计算出每个用户点击的标签分值,和用户总体点击标签分值。用户信息包括:用户选择的兴趣运动、用户关注的球队、用户拉黑的标签。
[0049]
每个用户点击标签分值的计算可以采用标签频次衰减,资讯观看时间衰减来计算,以下进行举例说明。
[0050]
(1)标签频次衰减
[0051]
用户观看一定时间对应的资讯中含有标签的总数为t个,其中内容a的标签出现的次数为s次,则内容a的标签分值x=s/t。
[0052]
如用户在某一天内看了资讯a,资讯b,资讯c。资讯a的标签有:“湖人”、“詹姆斯”。资讯b的标签有:“湖人”、“凯尔特人”、“詹姆斯”。资讯c的标签有:“詹姆斯”。
[0053]
则标签的总数为6个,即t=6,“詹姆斯”标签出现的次数为3次,即s=3,则“詹姆斯”标签分值x=s/t=3/6=0.5。
[0054]
同理,“湖人”标签分值x=2/6=0.33;“凯尔特人”标签分值x=1/6=0.17。
[0055]
(2)资讯观看时间衰减
[0056]
定义初始的时间为t0,初始的时间t0内用户观看的资讯的标签的分数为f0,定义一个时间段,新的时间tn与初始的时间t0内有n个时间段,则时间tn内用户观看的资讯的标签的分数fn=(1 n)f0。。
[0057]
如初始的时间为2021年11月1日(t0),定义初始的时间内用户观看的资讯的标签的分数f0=0.1。用户在2021年11月1日看了资讯a,资讯a的标签有:“库里”。设定时间段为1天,在2021年11月2日(t1,n=1)时用户看了资讯b,资讯b的标签有:“詹姆斯”。则“库里”标
签分值y=f0=0.1,“詹姆斯”标签分值y=f1=(1 1)
×
0.1=0.2。
[0058]
同理,若用户在2021年11月6日看了资讯c,资讯c的标签有“湖人”,此时n=5,则“湖人”标签分值y=f5=(1 5)
×
0.1=0.6。
[0059]
用户总体点击标签分值的计算为将每个用户同一个标签得到的所有分值相加得到该标签的总分值。
[0060]
比如通过上述标签频次衰减和资讯观看时间衰减计算得到的“詹姆斯”标签的总体标签分值z=0.5 0.2=0.7。
[0061]
c2.建立用户画像标签:关联用户信息,根据总体标签分值衰减排序得到每个用户的画像标签,从而生成用户画像。用户信息包括:用户选择的兴趣运动、用户关注的球队、用户拉黑的标签中的若干种。
[0062]
如:用户选择的兴趣运动为篮球,关注的球队有湖人、勇士、篮网,用户之前阅读过资讯标签按总体标签分值衰减有篮网、湖人、广东。那么用户的标签画像是篮网、湖人、勇士、广东。
[0063]
d.构建训练模型
[0064]
d1.计算生成标签词向量和模型
[0065]
对用户画像标签进行归一化处理,把每个画像标签归一化到0-1之间,转成对应的标签词向量,汇总用户在一段时间内点击的资讯的标签,训练得到对应的embedding模型。
[0066]
在过程c中得到的标签为汉字,无法直接参与计算和模型训练,所以需要转成对应的词向量,方便之后计算新资讯的相似度,实现精准预测推荐。
[0067]
d2.生成资讯热度模型:根据大数据实时计算资讯的曝光点击率、资讯评论率和人工设置的资讯权重生成资讯热度模型。根据资讯热度模型计算资讯热度。
[0068]
资讯热度r采用如下计算公式计算:r=x y z,其中,x为资讯的曝光点击率、y为资讯评论率、z为资讯权重率;
[0069][0070]
其中,n1为用户从推荐列表浏览资讯内页的次数,n为资讯在推荐列表展示的次数;n为资讯的评论数,q为人工设置的资讯权重,t为从发布到当下的时间间隔,g为时间衰减因子。
[0071]
实践中,q值可以根据资讯的重要程度进行设置,越重要的资讯(如重要的新闻或视频)设置的资讯权重值越大。g值可以根据ab测试得出,通过测试不同值下的推荐效果(如哪个资讯的阅读时长、点击率、互动率表现比较好)来得出一个比较合理的g值,g值用于人为控制时间对排序产生的影响。g的数值大小决定了排名随时间下降的速度快慢。
[0072]
体育资讯实时性要求是比较高的,所以需要把即时的、热门的新闻优先推送给用户。本发明采用大数据实时计算资讯的曝光点击率,结合大数据实时计算资讯评论率,把热度高的资讯优先推送给用户。由于有些新发布的新闻比较重要,刚开始没有热度,智能推荐没法优先推荐出来,为解决这个问题,本发明采用重要资讯人工设置对应的资讯权重,高权重的资讯将加上对应的热度,结合曝光点击率、资讯评论率计算出最终的资讯热度,从而实现智能精准实时推荐。
[0073]
d3.生成catboost模型:根据资讯热度、资讯的标签词向量、embedding模型进行离
线训练,生成catboost模型。
[0074]
catboost模型采用catboost算法,依赖于catboost算法的快速精准预测。catboost使用oblivious树作为基本预测器,这种树是平衡的,不太容易过拟合,在oblivious树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。catboost首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值,这种方法增加了可靠性,并且能大大加速预测,在性能方面可以匹敌先进的机器学习算法,对系统的稳定性提供可靠的支撑。
[0075]
e.资讯推荐
[0076]
根据得到的catboost模型预测资讯候选池里用户喜好的资讯,利用catboost模型进行树模型构建,基于资讯的热度排序,对资讯样本进行加工和计算后推荐给用户。
[0077]
综上,本发明整合大数据行为数据资源,根据丰富的体育用户和内容标签体系,以此形成精准且垂直于体育领域的用户画像。通过个性化推荐系统向用户精准、实时地推荐其更加感兴趣的个性化体育资讯内容。更好地解决在体育垂直资讯阅读场景下的个性化资讯推荐问题。
[0078]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
