1.本技术涉及数据处理领域,具体地,涉及一种基于深度学习的骨髓象细胞影像图检测分类方法及其系统。
背景技术:
2.骨髓细胞形态学方法主要是将患者骨髓涂片和血涂片分别进行瑞氏-吉姆萨染色、镜下分析,按照国内或国际标准对急性白血病类型进行判定。主要用于白血病、淋巴瘤、各类贫血等血液系统疾病的诊断及鉴别诊断以及血液病治疗中的定期复查及化疗疗效观察。其中细胞形态学是各类白血病诊断中应用最多、最广泛、最直接和经济的一种诊断手段,是形态学、免疫学、细胞遗传学、分子生物学分型诊断的重要组成部分。细胞形态学检验内容是多方面的,对于血液常规来说,主要是指外周血细胞涂片的形态分类。现代血液分析仪可以通过流式细胞、化学染色等技术对细胞进行分类,甚至可以识别异常的细胞,但目前仍需要人工分类复核。对于血液病诊断来说,更重要的是骨髓细胞形态学检查。因为外周血细胞一般来自于骨髓,部分血液病细胞形态、成分的变化不能反映在外周血中。骨髓液抽吸出后,涂成薄的片子染色后在显微镜下进行细胞分类和形态观察,从而对疾病进行诊断。由于骨髓正常细胞形态多样,而且不同疾病可以出现多种多样的细胞形态变化,因此如何在骨髓涂片中准确识别各种骨髓细胞类型并统计分布比例成为该领域的技术难点。
3.传统的骨髓细胞的识别需要检验专家人工识别,但是骨髓细胞形态多样,不同疾病可以出现多种多样的细胞形态变化,因此骨髓细胞形态学检查需要丰富的经验。目前骨髓专家人才培养时间长,流动大,医院面临着培养人才难,成本高的问题。
4.因此,如何开发出智能化的骨髓细胞检测方法,是本领域技术人员急需解决的问题。
技术实现要素:
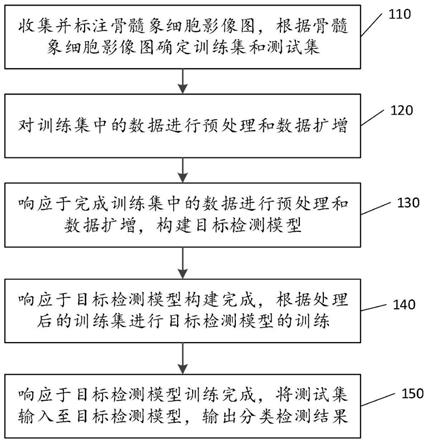
5.本技术提供了一种基于深度学习的骨髓象细胞影像图检测分类方法,具体包括以下步骤:收集并标注骨髓象细胞影像图,根据骨髓象细胞影像图确定训练集和测试集;对训练集中的数据进行预处理和数据扩增;响应于完成训练集中的数据进行预处理和数据扩增,构建目标检测模型;其中构建目标检测模型包括引入一般性评分损失,根据一般性评分损失优化目标检测模型;响应于目标检测模型构建完成,根据处理后的训练集进行目标检测模型的训练;响应于目标检测模型训练完成,将测试集输入至目标检测模型,输出分类检测结果。
6.如上的,其中,骨髓象细胞影像图是显微镜下真实骨髓象细胞影像图,根据真实骨髓象细胞影像图随机划分训练集和测试集。
7.如上的,其中,收集并标注骨髓象细胞影像图还包括,利用标注工具标记出真实骨髓象细胞影图像中所有细胞的目标矩形框,生成目标矩形框左上角顶点和右下角顶点在像
素坐标系下的坐标,并标注相应的类别,从而生成的标注文件。
8.如上的,其中,对训练集中的数据进行预处理和数据扩增包括,对训练集的样本进行筛选,去掉无标注及非设定标注类别的样本,取细胞样例数量大于100的类别构建数据集。
9.如上的,其中,构建目标检测模型包括,将faster r-cnn模型作为基础模型,对faster r-cnn模型进行优化,将优化后的faster r-cnn模型作为本实施例中目标检测模型。
10.如上的,其中,faster r-cnn由rpn和fast r-cnn两个网络部分构成;
11.定义rpn网络的完整损失函数为:
[0012][0013]
其中,l({pi},{ti})为加权求和,l
cls
为分类任务的损失函数,l
reg
为回归任务的损失函数,ti为第i个模版框参数化处理后坐标向量,为第i个模版框对应的目标矩形框参数化处理后坐标向量,pi为第i个模版框的预测概率,为第i个模版框对应的真实标签,n
cls
为所有模版框的数目,n
reg
为所有正例模版框的数目,{pi}代表所有模版框的预测概率集合,{ti}代表所有模版框的预测坐标向量集合,λ1为加权系数。
[0014]
如上的,其中,分类任务的损失函数l
cls
具体表示为:
[0015][0016]
pi为第i个模版框的预测概率,n为预测的模版框个数。
[0017]
如上的,其中,回归任务的损失函数l
reg
具体表示为:
[0018][0019]
其中对于c,d,w,h中的任意一个参数z,定义:
[0020][0021]
回归任务的损失采用函数进行计算,其中c,d为候选矩形框的中心点坐标,w,h分别为候选矩形框的长度宽度,指为第u类目标的预测矩形框第i个坐标值,vi指目标矩形框对应的第i个坐标值。
[0022]
如上的,其中,对rpn网络预测出的候选矩形框进行处理,具体为对候选矩形框的中心点坐标和候选矩形框的长度宽度进行参数化处理,生成4维向量t。
[0023]
一种基于深度学习的骨髓象细胞影像图检测分类系统,具体包括:数据获取单元、处理单元、模型构建单元、训练单元以及输出单元。
[0024]
数据获取单元,用于获取收集并标注骨髓象细胞影像图,根据骨髓象细胞影像图确定训练集和测试集;
[0025]
处理单元,用于对训练集中的数据进行预处理和数据扩增;
[0026]
模型构建单元,用于构建目标检测模型;
[0027]
训练单元,用于根据处理后的训练集进行目标检测模型的训练;
[0028]
输出单元,用于将测试集输入至目标检测模型,得到检测结果。
[0029]
本技术具有以下有益效果:
[0030]
本技术中构建目标检测模型所用的数据来源简单,所需的数据来源于真实显微镜视野下的骨髓象细胞,无需复杂实验过程,成本低廉。本技术构建的目标检测模型设计是基于深度学习目标检测及分类算法,能够自动准确标定目标细胞并对21类细胞进行分类,分类结果高效且准确。
附图说明
[0031]
为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
[0032]
图1是根据本技术实施例提供的基于深度学习的骨髓象细胞影像图检测分类方法的流程图;
[0033]
图2是根据本技术实施例提供的基于深度学习的骨髓象细胞影像图检测分类系统的内部结构图;
[0034]
图3是根据本技术实施例提供的基于深度学习的骨髓象细胞影像图检测方法中的显微镜视野骨髓细胞真实影像;
[0035]
图4根据本技术实施例提供的基于深度学习的骨髓象细胞影像图检测方法获得的骨髓象细胞分析结果图。
具体实施方式
[0036]
下面结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0037]
本技术涉及一种基于深度学习的骨髓象细胞影像图检测分类方法及其系统。根据本技术,能够自动准确标定目标细胞并对21类细胞进行分类。
[0038]
实施例一
[0039]
如图1所示,是本技术提供的一种基于深度学习的骨髓象细胞影像图检测分类方法,具体包括以下步骤:
[0040]
步骤s110:收集并标注骨髓象细胞影像图,根据骨髓象细胞影像图确定训练集和测试集。
[0041]
其中,骨髓象细胞影像图是显微镜下真实骨髓象细胞影像图,本实施例以统一格式存储数据和标注信息,并随机划分训练集和测试集。
[0042]
其中,本实施例采集海德星hds-bfs高速显微扫描影像系统的骨髓细胞真实图像共计4451张,分辨率为4000
×
3000,显微镜下真实骨髓象细胞影图像如图3所示。将4451张骨髓细胞真实图像分别作为训练集和测试集中的样本。
[0043]
进一步地,利用标注工具标记出真实骨髓象细胞影图像中所有细胞的目标矩形框,生成目标矩形框左上角顶点和右下角顶点在像素坐标系下的坐标,并标注所有细胞相应的类别,从而生成的标注文件。其中标注文件中包括该目标矩形框左上角顶点x轴坐标和y轴坐标,以及右下角顶点x轴坐标和y轴坐标。
[0044]
具体地,目标的21个类别分别是嗜酸性分叶核粒细胞、早幼红细胞、原始浆细胞、早幼粒细胞、巨中幼红细胞、异型淋巴细胞、巨晚幼红细胞、中性分叶核粒细胞、中幼红细胞、中性晚幼粒细胞、中性中幼粒细胞、幼稚淋巴细胞、幼稚浆细胞、中性杆状核粒细胞、幼稚单核细胞、晚幼红细胞、原始淋巴细胞、成熟淋巴细胞、原始粒细胞、异常早幼粒细胞、原始单核细胞。
[0045]
在进一步地,随机选择80%张图像作为训练集的样本,余下20%张图像作为测试集的样本。
[0046]
步骤s120:对训练集中的数据进行预处理和数据扩增。
[0047]
具体地,首先对训练集的样本进行筛选,去掉无标注及非设定标注类别的样本,取细胞样例数量大于100的类别构建数据集,其中数据集中需包含21个类别。
[0048]
进一步地,对剩余3653例训练集中的样本通过图像水平翻转、竖直翻转、图片旋转、图片平移、图片添加高斯噪声5种数据增强方法对训练数据集扩充。
[0049]
其中上述数据增强方法为现有技术中涉及的方法,具体怎样操作在此不进行赘述。
[0050]
步骤s130:响应于完成训练集中的数据进行预处理和数据扩增,构建目标检测模型。
[0051]
其中本实施例构建的目标检测模型为基于深度学习技术建立骨髓形态学图形分类的数学模型,通过构建的识别模型,对进入视野的细胞进行分类和检测。
[0052]
具体地,其中本实施例采用faster r-cnn模型作为基础模型,在此模型基础上对其进行优化,将优化后的faster r-cnn模型作为本实施例中目标检测模型。实际应用中输入骨髓细胞图像,即可输出检测到的每个细胞类别及位置。
[0053]
其中,faster r-cnn由rpn(区域提案网络,region proposal network)和fast r-cnn两个网络部分构成,其中rpn用于选出候选矩形框,fast r-cnn用于目标精确分类和回归。
[0054]
其中候选矩形框是与上述骨髓细胞真实图像中多个类别对应的候选矩形框,具体一个类别对应一个候选矩形框。本实施例中候选矩形框的数量为多个。
[0055]
其中rpn网络的损失函数具体表示为:
[0056]
rpn网络的完整损失函数为分类任务的损失函数和回归函数的加权求和,rpn网络的完整损失函数具体表示如下:
[0057][0058]
其中,l({pi},{ti})为加权求和,为分类任务的损失函数,为回归任务的损失函数,ti为第i个模版框参数化处理后坐标向量,为第i个模版框对应的真实目标矩形框参数化处理后坐标向量,pi为第i个模版框的预测概率,为第i个模版框对
应的真实标签(如果模版框为正例值,为1,反之为0),n
cls
为所有模版框的数目,n
reg
为所有正例模版框的数目,{pi}代表所有模版框的预测概率集合,{ti}代表所有模版框的预测坐标向量集合,λ为加权系数,在本发明中默认为1。
[0059]
具体地,分类任务的损失函数l
cls
具体表示为:
[0060][0061]
pi为第i个模版框的预测概率,n为预测的模版框个数。该分类任务是一个二分类任务,即根据损失函数预测出当前预测区域属于前景细胞或背景的概率。
[0062]
其中回归任务的损失函数l
reg
具体表示为:
[0063][0064]
其中对于c,d,w,h中的任意一个参数z,定义:
[0065][0066]
其中c,d,w,h分别为候选矩形框的中心点坐标和候选矩形框的长度宽度,指为第u类目标的候选矩形框第i个坐标值,vi指目标矩形框对应的第i个坐标值。
[0067]
进一步地,为了保证坐标的平移不变性和长宽的一致性,对候选矩形框的中心点坐标和候选矩形框的长度宽度进行参数化处理,生成4维向量t,由于4维向量中有4个坐标,其中处理后的候选矩形框的中心点坐标(tc,t
*c
,td,t
*d
)表示为:
[0068][0069][0070]
其中,其中,(c,d)表示参数化处理前候选矩阵框的重心坐标,其中c表示参数化处理前候选矩阵框的的x轴的坐标,d表示参数化处理前候选矩阵框的y轴的坐标,(ca,da)表示模板框(anchor)的坐标,(c
*
,d
*
)表示目标矩形框的坐标,(wa,ha)表示模板框的长度和宽度。
[0071]
处理后的矩形框的长度宽度(tw,t
*w
,th,t
*h
)表示为:
[0072][0073][0074]
其中,w,h表示参数化处理前的候选矩形框的长度和宽度,(w
*
,y
*
)表示目标矩形框的长度和宽度,(wa,ha)表示模板框的长度和宽度。
[0075]
其中根据rpn网络预测出候选矩形框的概率,此概率模型认为预测的候选矩形框为真实目标的概率。
[0076]
进一步地,fast r-cnn网络部分,由于faster r-cnn网络使用rpn网络选出了候选
矩形框,因此在fast r-cnn网络中加入roi pooling层,roi pooling层进行感兴趣区域池化(region of interest)下采样,获得相同大小的特征,具体为7
×
7的特征图。然后将特征图展平处理后在经过一系列全连接层得到输出向量。
[0077]
进一步地,对得到的特征向量进行分类预测和回归预测,其中分类预测其中分类任务在本发明中为二分类任务,即获取前景细胞与背景两类,分类预测得方法可通过现有技术获取。fast r-cnn网络具有得到目标类别的能力。
[0078]
其中回归预测中的损失函数具体表示为:
[0079]
l(p,u,tu,v)=l
cls
(p,u) λ2[u≥1]l
reg
(tu,v)
[0080]
其中,l(p,u,tu,v)是损失函数,l
cls
是分类任务的损失函数,l
reg
是回归任务的损失函数,p是分类器预测的softmax概率分布,u是对应目标的真实分类标签,tu是对应预测矩形框的回归器预测的对应类别u的坐标向量v是对应真实目标矩形框的坐标向量(v
x
,vy,vw,vh),λ2是加权系数,在本发明中默认为1。
[0081]
rpn网络和fast r-cnn网络构成faster r-cnn网络,通过faster r-cnn网络,预测了两次骨髓象细胞中候选矩形框的概率。
[0082]
其中,在预测候选矩形框后,本实施例引入一般性评分损失。
[0083]
由于骨髓象细胞不同类别出现频率差别较大,为了处理比较极端的数据不平衡问题,本实施例提出一般性评分损失,将一般性评分损失加入原本的faster r-cnn网络中,即通过分类概率值对正负样本进行评估,而不需要采用启发式采样训练的方法,更有利于解决骨髓象细胞的数据长尾分布问题。
[0084]
其中获得一般性评分损失具体包括以下步骤:
[0085]
步骤s1301:确定评分任务。
[0086]
其中评分任务具体为划分正负样本。
[0087]
具体地,由于上述得到了候选矩形框和目标矩形框,因此将候选矩形框和目标矩形框的交并比(iou)作为指定阈值。若候选矩形框超出指定阈值,则为正样本,反之则为负样本。其中正样本集合为n,负样本集合为n。
[0088]
优选地,iou是一种测量在特定数据集中检测相应物体准确度的一个标准。iou是一个简单的测量标准,只要是在输出中得出一个预测范围的任务都可以用iou来进行测量。
[0089]
步骤s1302:根据评分任务预测候选矩形框的得分差值。
[0090]
具体地,在正负样本中分别计算每两个候选矩形框的得分差,其中每两个候选矩形框的得分差值具体表示为:
[0091][0092]
其中si,sj分别为两个候选矩形框得分,候选矩形框得分为上述rpn网络和fast r-cnn在预测候选矩形框后随候选矩形框概率同时输出的得分。
[0093]
进一步地,根据候选矩形框之间的得分差值定义阶跃函数:
[0094][0095]
其中xi<xj说明候选矩形框i的得分小于候选矩形框j的得分,xi>xj说明候选矩形框i的得分小于候选矩形框j的得分。
[0096]
步骤s1303:根据得分差值得到一般性评分损失。
[0097]
具体地,根据由得分差值得到的阶跃函数确定一般性评分损失。
[0098]
其中,一般性评分损失具体表示为:
[0099][0100]
其中loss
rs
(i)表示原始排序损失(即考虑到所有正负样本的排序损失),loss
*rs
(i)表示正样本内部的排序损失(即仅考虑正样本的排序损失)。
[0101]
具体地,原始排序损失loss
rs
(i)具体表示为:
[0102][0103]
其中r为排序位置(即候选矩形框i得分在所有预测矩形框中的排名),r
p
代表正样本中排序位置(仅统计正样本),λ为加权系数,h(x
ij
)为阶跃函数,yj为候选矩形框和与其相交矩形框的最大iou值。n表示正样本集合,p表示负样本集合,j表示属于正样本集合或负样本集合的某一个候选矩形框。
[0104]
对于正样本内部的排序损失具体表示为:
[0105][0106]
通过上式可以看出,对于相对排序位置没有变化的正样本,其原始排序损失与排序后损失值相同,在最终损失计算中相互抵消,会削弱对排序正确的正样本影响。而原始排序在负样本后的正样本,具有较大的评分损失,即一般性评分损失的值较大,将上述一般性评分损失加入原本的faster r-cnn网络中,形成本实施例提供的目标检测模型,一般性评分损失会促进目标检测模型增强对这部分正样本的检测能力。
[0107]
步骤s140:响应于目标检测模型构建完成,根据处理后的训练集进行目标检测模型的训练。
[0108]
具体地,本实施例选择momentum(动量)算法作为梯度下降方法对目标检测模型进行悬链,其中本实施例选择momentum=0.9,学习率初始化为0.001,权值衰减为0.0001,对目标检测模型进行多轮训练。
[0109]
其中每轮迭代batch size(批量)=1,学习率衰减采用线性衰减,每4轮学习率衰减为原来的0.3倍,模型迭代训练为20轮。
[0110]
步骤s150:响应于目标检测模型训练完成,将测试集输入至目标检测模型,输出分类检测结果。
[0111]
具体地,目标检测模型训练完毕后,将测试集经过同步骤s120相同的数据预处理后,将处理后的测试集输入到目标检测模型中,最终输出预测的目标类别和目标矩形框的左上角及右下角坐标,并以可视化方式显示在骨髓象细胞影像图中,如图4所示,即形成了骨髓象细胞分析结果图。
[0112]
实施例二
[0113]
如图2所示,本技术提供一种基于深度学习的骨髓象细胞影像图检测分类系统,具体包括:数据获取单元210、处理单元220、模型构建单元230、训练单元240、输出单元250。
[0114]
数据获取单元210用于获取收集并标注骨髓象细胞影像图,根据骨髓象细胞影像
图确定训练集和测试集。
[0115]
优选地,数据获取单元包括光学显微镜、图像数字化设备和数字显微镜。在收集并标注骨髓象细胞影像图的过程中,骨髓涂片标本经过显微镜的光学放大,可通过目镜直接观察细胞形态变化。
[0116]
数字显微镜将光学显微镜和图像数字化设备整合在一起,直接输出数字显微图像,即本技术收集的骨髓象细胞影像图。其中图像数字化设备采用高清数码摄像头。
[0117]
处理单元220与数据获取210连接,用于对训练集中的数据进行预处理和数据扩增。
[0118]
模型构建单元230与处理单元220连接,用于构建目标检测模型。
[0119]
训练单元240与模型构建单元230连接,用于根据处理后的训练集进行目标检测模型的训练。
[0120]
输出单元250与训练单元240连接,用于将测试集输入至目标检测模型,得到检测结果。
[0121]
本技术具有以下有益效果:
[0122]
本技术中构建目标检测模型所用的数据来源简单,所需的数据来源于真实显微镜视野下的骨髓象细胞,无需复杂实验过程,成本低廉。本技术构建的目标检测模型设计是基于深度学习目标检测及分类算法,能够自动准确标定目标细胞并对21类细胞进行分类,分类结果高效且准确。
[0123]
虽然当前申请参考的示例被描述,其只是为了解释的目的而不是对本技术的限制,对实施方式的改变,增加和/或删除可以被做出而不脱离本技术的范围。
[0124]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。因此,本技术的保护范围应以所述权利要求的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。