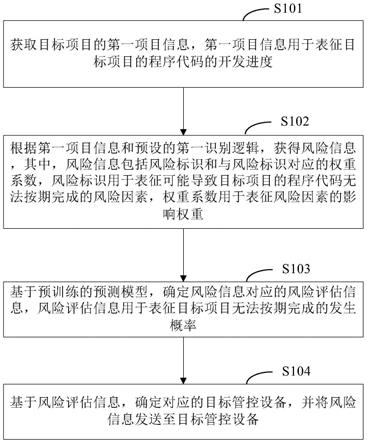
1.本发明属于电子信息领域,是一种基于目标检测和语义分割融合的实时障碍物检测方法。
背景技术:
2.目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,具有重要的现实意义。然而针对视障人士等群体,这项技术并没有得到广泛参与,大部分盲人出行所使用的工具依然是传统盲杖和少量导盲犬。其中传统盲杖探测范围小,主要靠触觉提供信息,无法提供类似路标和信号灯等视觉信息,盲人在出行的种种不便并没有得到有效解决;而导盲犬成本高昂、数量少,且依旧无法理解人类社会丰富又复杂的符号和颜色信息。
3.随着深度学习和计算机视觉技术的发展,越来越多针对移动设备的轻量级深度神经网络相继被提出,可以实时理解复杂的视觉信息,例如通过人体姿态分析动作语义、通过目标检测来获取目标的位置和类别、通过语义分割在像素级别对物体进行分类。其中目标检测和语义分割都可以用来帮助盲人理解周围环境中的复杂信息。然而视障人士出行中所关注的目标主要包括地形、障碍物、指示牌和信号灯等,其尺寸和长宽比跨度非常大,例如马路牙子比例细长、在画面中有时占比很大,再加上倾斜角度下背景信息复杂,单纯依靠目标检测很难保证良好的识别准确率,且会影响其他类别的指标。如果使用语义分割识别所有类别,其训练数据标注起来也非常耗费人力物力。
4.目前将目标检测和语义分割融合的轻量级端到端深度神经网络还很少,为此,设计了基于目标检测和语义分割融合的障碍物检测网络desenet,可以将目标检测和语义分割两种类型的数据集合并加载,并进行联合训练,扩充了可检测目标的类别数,提高了各尺寸目标的检测准确率,具有现实意义和良好应用前景。
技术实现要素:
5.本发明为了解决上述目标检测方法中无法有效识别细长倾斜目标的问题,提出了一种基于目标检测和语义分割融合的轻量级障碍物识别方法。
6.本发明是通过以下技术方案实现的:
7.(1)基于pytorch深度学习框架,实现对目标检测和语义分割数据集的混合加载与预处理,对数据集进行有效扩充,提高深度神经网络的泛化能力。
8.(2)基于卷积神经网络(convolutional neural networks,cnn),结合目前先进的适用于移动智能设备的轻量级深度网络结构,设计实现了同时进行目标检测和语义分割的端到端的深度神经网络desenet。
9.本发明核心算法
10.(1)目标检测数据集和语义分割数据集混合加载
11.目标检测数据集标注格式参考yolo目标检测标签的结构,每张图片对应一个txt
文件,其中每一行代表图片中的一个目标的边界框,包含class_id(类别编号)、x(边界框中心点x轴坐标)、y(边界框中心点y轴坐标)、w(边界框宽度)和y(边界框高度),这些值都是根据图片尺寸进行归一化。语义分割数据集标注格式设计为和目标检测数据集标注格式相统一,依旧采用txt文件存储每张图片的标注信息,区别是每一行除第一项类别标签之外,其余项均为x轴坐标和y轴坐标归一化后的值,每两项为一组确定一个点的坐标,点的个数不固定,这些点组成的封闭区域即为该类目标的范围。数据增强使用mosaic方式,即拼接4幅图像,每个图像又经过随机平移、缩放、翻转、亮度和饱和度调整,极大地丰富了被检测物体的背景,有利于提高模型的泛化能力。
12.(2)目标检测和语义分割融合的端到端深度卷积神经网络desenet架构
13.架构如图1和图2所示,整个结构一共分为4个部分。第1部分是input输入端,该部分将移动智能设备采集的单张图像进行一次下采样并调整通道数。第2部分为backbone骨干网络,用于初步提取图像特征,使用csp结构减少计算量并加强特征提取能力。第3部分是neck,用来更好地利用backbone提取的特征,采用空间金字塔池化spp(spatial pyramid pooling)结构、fpn(feature pyramid network)结构和pan(path aggregation network)结构,将backbone中的多尺度信息进行融合。第4部分是prediction预测模块,分为detection目标检测头和segmentaion语义分割头两个并行部分,分别输出3个不同尺度的目标检测特征图和1个语义分割特征图。通过设置超参数,控制两个预测头的比例以平衡各自的预测效果。4个部分的详细描述如下:
14.1)input输入端,首先在输入神经网络前,将原始图像较长边设定为网络输入的目标尺寸640,原始图像较短边按比例缩放,再对短边像素填充到640,使得网络的输入为640*640像素的3通道rgb图像;接着使用focus模块对图像进行切片操作,分解成4张尺寸为320*320*3的图像,并拼接成320*320*12的张量,这样就将空间信息集中到了通道维度,最后再通过卷积操作得到一个没有信息丢失的二倍下采样特征图。
15.2)backbone骨干网络,由3个csp_1(cross stage partial)模块组成;csp模块中包含两种基本模块:一种是cbs,即卷积层(conv) 归一化层(batchnorm) 激活层(swish),另一种是残差单元(resunit)。csp_1使用了残差单元,csp_2使用两个替换残差单元。csp_1_x卷积模块中的x代表模块中残差单元的数量,backbone中有1个csp_1_1和2个csp_1_3。csp_1_x的具体结构为:一个cbs接x个resunit,与另一个cbs进行concat(通道拼接)操作,将拼接后的张量经过一个cbs得到输出张量。csp结构将特征图分成两部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果拼接,在目标检测问题中,有效增强了卷积网络的学习能力,降低计算量的同时提高了准确率。backbone的最后使用了spp模块,用来将多重感受野融合,有效提升小目标的预测准确率。spp使用多个不同尺度的最大池化层去提取特征,再通过concat操作将特征整合在一起。本发明设计的backbone骨干网络借鉴了卷积神经网络中优秀的轻量级网络框架和优秀的网络设计思路,在保证提取更丰富的图像特征的同时,大幅度减少参数量,降低运算时间。
16.3)neck部分,主要分成fpn和pan两个模块。fpn模块通过自顶向下的方式提取图片的语义特征,利用上采样将深层特征的尺度扩展到浅层特征的尺度,再进行张量拼接,实现了深层和浅层特征的融合。pan模块通过自底向上提取图片中的位置特征,利用cbs模块实现下采样,将高维特征的尺度降低到低维特征的尺度,并通过张量拼接完成融合。通过这种
方式,既获得了丰富的语义特征又保留了位置特征。
17.4)prediction部分,分为目标检测头dehead和语义分割头sehead,分别输出3个不同尺度的目标检测结果和1个语义分割结果。
18.i)目标检测的输出为三个不同尺度的张量,张量形状为shape(batch_size,anchor_number,height,width,output_number),其中batch_size为批大小,anchor_number为锚框数(即每个网格对应的不同比例锚框的个数),height为特征图高度,width为特征图宽度。每个网格有anchor_number个预测值cs,预测值包含output_number项,可以综合反映基于当前模型预测的边界框内存在目标的可能性和预测目标位置的准确性。
[0019][0020]
其中,pr(object)表示网格内是否包含目标的中心点,如果包含,则为1。反之为0,为交并比,用于表示网络预测生成的边界框与物体真实的边界框面积的交并比。
[0021]
预测的边界框通过output_number个值来描述,其中x和y表示边界框中心点相对于网格中心的位置,w和h表示边界框相对宽高,c表示预测边界框和该物体真实边界框的交并比,每个网格对应一个预测是否包含某类目标的预测值ci,其表达式为
[0022]ci
=pr(classi|object)
ꢀꢀ
(2)
[0023]
其中,classi表示第i个类别,该公式的意思是在pr(object)的基础上判断边界预测框属于第i个类别的概率,当该框的pr(object)是0时,则预测值ci就是0。如果前者是1,则预测该边界框中物体属于第i类的概率。因此c对应每个类别的概率,共class_num项,故output_number=5 class_bum。使用bcewithlogitsloss分别计算class和object的损失,使用ciou_loss计算boundingbox的损失,三个损失相加即代表目标检测的总损失。
[0024]
ii)语义分割检测头借鉴了空洞空间金字塔池化模块aspp(atrousspatial pyramid pooling),利用到了多尺度信息,上、下层特征图间连接多个并行的空洞卷积分支,每个分支上使用不同的atrous rate(空洞率),以获得不同的感受野,再经过1*1卷积之后连接起来,得到全局和局部的特征。还设计了一个金字塔池化层(pyramid pooling)将输入的特征分成四条支路按不同尺度进行平均池化,提取出不同尺度的上下文信息,再分别通过1*1卷积调整通道数,通过上采样调整到相同尺寸后和输入特征一起按通道维拼接。接着使用特征融合模块ffm(feature fusion module)将空间路径sp(spatial path)和上下文路径cp(context path)输出的特征进行融合,使用的是类似se模块(squeeze-and-excitation)的方式计算加权特征,起到特征选择和结合的作用。语义分割的输出是一个形状为shape(batch_size,class_num,height,width)的张量,其中batch_size为批大小,class_num为类别数,height为特征图高度,width为特征图宽度。第二维的每一个矩阵对应每一个类别的语义分割预测结果,矩阵中每一项的值代表每一个网格属于当前类别的概率,采用交叉熵损失(crossentropyloss)作为损失函数计算语义分割的损失。
[0025]
网络训练超参数中设置了目标检测和语义分割两条分支在反向传播中所占的比例,使得目标检测和语义分割的训练速度基本一致。验证阶段使用均交并比miou(mean intersection over union)作为语义分割的标准度量,其计算两个集合的交并比,这两个集合为真实值(ground truth)和预测值(predicted segmentation),计算公式如下:
[0026][0027]
其中,i表示真实值,j表示预测值,pij表示将i预测为j的个数。
[0028]
网络每训练完一代,就将目标检测的验证指标和语义分割的miou按一定权重相加,将结果最高的网络参数保存为结果。
[0029]
发明效果
[0030]
本发明使用轻量级网络结构,将目标检测任务和语义分割任务结合起来了,使用目标检测和语义分割两种数据集进行训练调优,实现了端到端的实时预测推理,大大扩充了可识别障碍物的范围,非常适用于检测盲人出行中所关心的障碍物目标,有非常大的实用价值。
[0031]
发明难点
[0032]
(1)设计一种将目标检测和语义分割统一起来的数据标注格式。由于现有的网络都是单独训练目标检测或语义分割的形式,其数据集标注格式都是不一致的,如果使用两个加载器分别加载目标检测和语义分割的数据集势必影响代码一致性,为优化带来困难,所以难点在于如何让添加进来的语义分割数据标注利用上已有的数据扩充方案。
[0033]
(2)设计了基于卷积神经网络的desenet网络。考虑到该网络需要运行在移动智能设备上且要保证实时性,单纯的目标检测又无法更好的识别细长、方向不定且尺寸大的目标,所以难点在于如何将语义分割网络和目标检测网络有机地结合在一起,而又不会影响各自的识别准确率,以及要保证网络的实时性。
附图说明
[0034]
图1是desenet网络整体结构,包括input、backbone、neck和prediction。
[0035]
图2是desenet网络各模块的详细结构,包括focus、cbs、csp和spp。
[0036]
图3是desenet网络中语义分割头seg的详细结构。
具体实施方式
[0037]
本发明使用microsoft的coco数据集对desenet网络做预训练。此外,本发明单独采集了3000多组交通路口、人行道和天桥等步行场景训练数据,对其中的路障、电线杆、树、人、汽车、摩托车和自行车做了目标检测的人工标注,对台阶和马路牙子做了语义分割人工标注,按照4:1的比例将样本划分为训练集和验证集,通过自定义的标注格式转换脚本将xml格式的标注文件转成统一的txt格式的文件,再使用基于pytorch的自定义数据集加载类同时加载目标检测和语义分割数据集,使用mosaic方式进行数据扩充,即随机将四张图经过平移、缩放、翻转、亮度和饱和度变换再拼接成一张图,使用此数据集对预训练完的desenet网络进行加强训练。训练中,batch_size设置为32,代码会将梯度累积到batch_size为64时再统一进行梯度更新;对于目标检测头的输出,使用带sigmoid操作的二进制交叉熵bcewithlogitsloss分别计算class和object的损失,使用ciou_loss计算bounding box的损失,三个损失相加即代表目标检测的总损失;对于语义分割头的输出,使用交叉熵损失crossentropyloss计算语义分割的损失。根据两种数据集样本量的比例,目标检测损失和语义分割损失按照1∶6来进行梯度积累。ciou_loss计算方法如公式(4)所示:
[0038][0039]
其中,iou是预测框和目标框的交并比,distance2是预测框和目标框中心点的欧氏距离,distancec是最小外接矩阵的对角线距离。v是衡量宽长比一致性的参数,其计算方法如公式(5)所示:
[0040][0041]
其中,w
gt
是目标框宽度,h
gt
是目标框长度,w
p
是预测框宽度,h
p
是预测框长度。假设预测框和目标框的宽长比不一致,则v会很大。
[0042]
α是取舍参数,其值如公式(6)所示:
[0043][0044]
由此可见,当iou小于0.5的时候,ciou就变成diou。iou越大,α就越接近1。
[0045]
下面详细描述desenet每个模块的具体实施步骤,对照图1、图2和图3所示:
[0046]
(1)input输入端,输入的图片大小为640*640*3,接着使用focus模块对图像进行无损二倍下采样操作,具体操作是在一张图片中每隔一个像素取一个值,类似于邻近下采样,这样就获取了4张图片,每张图片类似但互补,没有信息丢失,尺寸变为320*320*3,将这4张图片按通道维拼接,组成一个320*320*12的张量,这样就将空间信息集中到了通道维度,最后再通过32个3*3的卷积核进行卷积运算输出一个32通道的特征图。
[0047]
(2)backbone骨干网络,其中spp模块首先通过一个cbs模块进行卷积操作,再分成四个分支,其中三个分别经过k={5
×
5,9
×
9,13
×
13}、步长为1的最大池化层,这三个分支的输出和另一个没有经过池化层的分支组成了四个不同尺度的特征图,将这四个特征图进行concat拼接操作,再经过一个cbs模块做融合。具体结构如表1所示:
[0048]
表1
[0049]
indextypein_channelout_channelkernel_sizestrideoutput_size1cbs326432160*1602csp1_16464
ꢀꢀ
160*1603cbs641283280*804csp1_3128128
ꢀꢀ
80*805cbs1282563240*406csp1_3256256
ꢀꢀ
40*407cbs2565123220*208spp512512
ꢀꢀ
20*209csp2_1512512
ꢀꢀ
20*20
[0050]
(3)neck部分,csp模块全部使用不带残差结构的csp2,上采样模块全部使用最邻近插值算法,除第28层为4倍上采样外,其余都是2倍上采样,下采样全部使用卷积核大小为3*3、步长为2的cbs模块来代替池化层。第12层接收来自第6和第11层的输出,第16层接收来自第4和第15层的输出,第19层接收来自第14和第18层的输出,第22层接收来自第10层和第
21层的输出,第24、25、27层分别接收来自第16、19、22层的输出,第29层接收来自24、26、28层的输出。具体结构如表2所示:
[0051]
表2
[0052][0053][0054]
(4)prediction部分,分为目标检测头和语义分割头。目标检测头使用3个卷积层,每个卷积层有36个大小为1*1、步长为1的卷积核,输出大小分别为80*80*36、40*40*36、20*20*36的3种特征图,其中维度36表示3个12维的网格,即每个特征图的每个网格中有3个先验框,每个先验框由先验框位置(4维)、置信度(1维)、类别(7维,目标检测数据集中有7种类别的目标)合计12维构成,80、40、20分别代表特征图的大小,关注不同尺度的目标。语义分割头详见图3,其中借鉴了aspp(空洞金字塔池化)结构,用来提取空间信息,利用cbs_x模块作为空洞卷积层(atrous convolutions),cbs_x中x的值表示卷积核的扩张率(dilation rate),常规卷积核的x为默认值1,当x大于1时,称为空洞卷积,可以在不降低分辨率的情况下扩大感受野,扩张率使用1、2、3的组合可以有效避免语义分割结果中的网格效应,让分割结果更平滑,金字塔池化层(pyramid pooling)使用四个输出大小分别为1、2、3、6的平均池化层再串连cbs和上采样的分支组成,这四个分支提取了丰富的上下文信息,和保留了空间信息的输入做concat操作,将空间和上下文信息传给后面的ffm(特征融合)模块,该模块使
用类似se模块(通道注意力机制)的方式计算加权特征,起到特征选择和结合的作用,最后通过一个卷积核大小为1*1、步长为1的卷积层将通道数调整为语义分割类别数以获得语义分割输出的特征图。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。