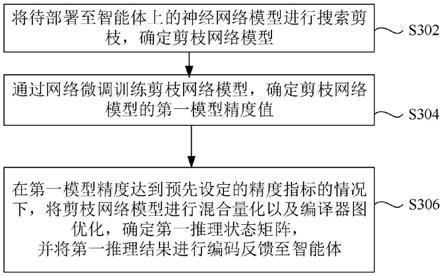
1.本发明涉及小样本学习的技术领域,尤其涉及一种基于模型驱动元学习的乳腺癌分子亚型预测方法。
背景技术:
2.近年来,乳腺癌分子亚型成为研究热点,因为不同分子亚型乳腺癌在疾病的表达、对治疗的反应、预后及生存结果上存在显著差异,些传统的乳腺癌分子亚型方法,有尝试通过患者影像预测乳腺癌分子亚型,比如采用的影像技术有乳腺钼靶、乳腺超声、正电子断层扫描与动态增强磁共振等,然而这些技术一般采用人工提取特征,存在主观性,很难客观反应乳腺癌本质特征。
3.最近,深度学习算法在医学图像分类中取得了巨大的成功,更多的研究试图将深度学习算法应用于癌症检测和诊断领域,然而医学图像的数据量极低,妨碍了深度学习算法充分发挥其潜力,并限制了评估结果的能力,因此,利用少量的医学图像样本对其进行分类是一个具有挑战性的问题。
技术实现要素:
4.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
5.鉴于上述现有存在的问题,提出了本发明。
6.因此,本发明提供了一种基于模型驱动元学习的乳腺癌分子亚型预测方法,能够避免人工判别的主观性的同时解决了少量的医学图像样本分类的问题。
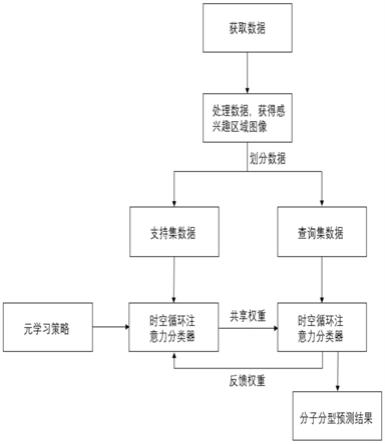
7.为解决上述技术问题,本发明提供如下技术方案:包括,通过乳腺癌数据库获取动态增强磁共振图像和动态增强磁共振图像的标签;将所述动态增强磁共振图像进行处理得到所述动态增强磁共振体积数据,将所述动态增强磁共振体积数据与所述动态增强磁共振图像的标签进行匹配得到有标签的动态增强磁共振体积数据;将所述有标签的动态增强磁共振体积数据分为支持集和查询集,利用支持集和查询集构建时空循环注意力分类器;利用改进的元学习策略优化所述时空循环注意力分类器,通过所述时空循环注意力分类器进行分子亚型预测。
8.作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:还包括,所述动态增强磁共振图像包括三个空间维度和一个时间维度;所述动态增强磁共振图像的标签包括正常型、管腔上皮型、her-2过表达型和基底细胞样型。
9.作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:将所述动态增强磁共振图像进行处理包括,根据人工标注病灶区域面积大小,在所述动态增强磁共振图像上截取病灶区域的感兴趣区域图像;将感兴趣区域图像统一采样为像素相同的图像,并放入三维矩阵中,得到动态增强磁共振体积数据。
10.作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:将所述有标签的动态增强磁共振体积数据分为支持集和查询集包括将所述有标签的动态增强磁共振体积数据通过n-way k-shot分类策略划分支持集和查询集。
11.作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:所述时空循环注意力分类器包括:循环神经网络、注意力机制、批标准化层和池化层;所述时空循环注意力分类器用循环神经网络并加入注意力机制,首先连接n
×n×
n的卷积运算,采用线性整流激活函数,然后连接一个批标准化层用来缓解过拟合现象,然后连接m
×m×
m的最大池化操作并加入注意力机制用来连接下一层;接着连接n
×n×
n的卷积运算,采用线性整流激活函数,然后连接一个批标准化层用来缓解过拟合现象,然后连接m
×m×
m的最大池化操作并加入注意力机制用来连接下一层;再接着连接n
×n×
n的卷积运算,采用线性整流激活函数,然后连接一个批标准化层用来缓解过拟合现象,然后连接m
×m×
m的最大池化操作;再进行压平操作;最后采用全连接层,采用归一化指数函数激活函数进行结果预测;所述卷积运算都使用a个滤波器;内循环采用梯度下降过程,学习率由模型自由选择;外循环学习率为b,采用adam优化器。
12.作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:所述循环神经网络包括3个卷积层:一个是前一层进入单元的输入,另一个是过去和未来时间帧的隐藏状态,最后一个是上一次迭代的隐藏状态,表示在第l层、时间帧t和迭代次数i的特征表达,表示在第l-1层、时间帧t和迭代次数i的特征表达,表示在第l层、时间帧t和迭代次数i-1的特征表达;是当信息在cran内向前传播时计算的表达,是在t-1时刻当信息在cran内向前传播时计算的表达;是信息在cran内向后传播时计算的表达,是在t 1时刻当信息在cran内向后传播时计算的表达。cran的详细表达为:
[0013][0014][0015][0016]
*为卷积运算,为线线性整流激活函数,w
l
为输入到隐藏卷积的过滤器,wi为在迭代过程中演化的隐藏到隐藏的循环卷积,w
t
为随时间演化的循环卷积滤波器,t为时刻,a
l
为一个偏差项。
[0017]
作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:还包括,
[0018]
时空循环注意力分类器学习图像形态学和药代动力学特征表征的步骤为:给出动态mr序列为
[0019]
[0020]
定义时刻t的每个mri体积v
t
为:
[0021][0022]
构造卷积循环注意力网络学习形态学和药代动力学表征,并周期性地利用循环注意力来模拟动态对比增强依赖性,可表示为:
[0023]yspatio-temporal
=fm(f
m-1
(
…
(f1(x
nt
))))
[0024]
其中,h和w为输入图像的高度和宽度,s为每个空间体积数中的切片数,t为时间点,v1,v2,
…vt
表示在1,2,
…
t时刻体积数据,表示在空间上具有s个切片数并且具有t个时序数的高度为h宽度为w的总数据;表示在具体t时刻第1,2,
…
s的体积数据;y
spatio-temporal
代表卷积循环注意力的预测,x
nt
表示带切片的下采样图像序列,f表示卷积循环注意力网,m表示迭代次数。
[0025]
作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:所述改进的元学习策略包括,
[0026]
对小样本数据集进行2步标准训练,所述2步标准训练包括内循环更新和外循环更新;
[0027]
计算时空循环注意力分类器的损失:
[0028][0029]
对于每一层,设置l个学习率实例供分类器选择。学习每个层的内环学习率公式定义为:
[0030][0031]
其中,αn为分类器第n层的内循环学习率,φ为随机选择函数,l1,l2,
…
,ln表示第1,2,
…
n的学习率,l为卷积循环注意力网可训练层的总数,为在第j批任务的第i组支持集或查询集的损失,xi为第i组支持集或查询集数据,yi为第i支持集或查询集标签,f
θ
′
(xi)为支持集或查询集的预测值。
[0032]
作为本发明所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的一种优选方案,其中:所述内循环更新和所述外循环更新包括,
[0033]
所述内循环更新:元学习策略学习一批任务,定义一个具有元参数θ神经网络f
θ
,随机初始化θ=θ0,在对来自支持集xj的数据进行少量m梯度下降后,获得θm;使用查询集yj评估网络的分类性能;j是一批任务的索引,m是内循环更新次数;支持集xj使用梯度下降计算自适应参数:
[0034][0035]
外循环更新:
[0036]
[0037]
其中,为在任务j上经过m次梯度下降后的基本网络参数权重,为在任务j上经过m-1次梯度下降后的基本网络参数权重,α为内部循环学习率,为θ的随机梯度下降过程,为在任务j上经过m-1次梯度下降后的神经网络,为支持集的损失;θ0为随机初始化参数,β为外循环学习率,为θ的随机梯度下降过程,为查询集的损失。
[0038]
本发明的有益效果:通过使用了模型驱动和元学习技术来探索4d时空相关性,并且能够在小量数据样本的情况下准确的实现乳腺癌的分子亚型预测。
附图说明
[0039]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
[0040]
图1为本发明第一个实施例所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的流程示意图;
[0041]
图2为本发明第一个实施例所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的感兴趣区域图;
[0042]
图3为本发明第一个实施例所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的模型驱动元学习体系结构图;
[0043]
图4为本发明第一个实施例所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的时空循环注意分类器结构图;
[0044]
图5为本发明第一个实施例所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的卷积循环注意力网络结构图;
[0045]
图6为本发明第一个实施例所述的基于模型驱动元学习的乳腺癌分子亚型预测方法的元学习策略图。
具体实施方式
[0046]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明,显然所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护的范围。
[0047]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0048]
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
[0049]
本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
[0050]
同时在本发明的描述中,需要说明的是,术语中的“上、下、内和外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一、第二或第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0051]
本发明中除非另有明确的规定和限定,术语“安装、相连、连接”应做广义理解,例如:可以是固定连接、可拆卸连接或一体式连接;同样可以是机械连接、电连接或直接连接,也可以通过中间媒介间接相连,也可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
[0052]
实施例1
[0053]
参照图1~6,为本发明的第一个实施例,该实施例提供了一种基于模型驱动元学习的乳腺癌分子亚型预测方法,包括:
[0054]
s1:通过乳腺癌数据库获取动态增强磁共振图像和动态增强磁共振图像的标签。
[0055]
(1)动态增强磁共振图像包括三个空间维度和一个时间维度;
[0056]
(2)动态增强磁共振图像的标签包括正常型(normal-like),管腔上皮型(luminal),her-2过表达型(her-2enriched)和基底细胞样型(basal-like)。
[0057]
s2:参照图2,将动态增强磁共振图像进行处理得到动态增强磁共振体积数据,将动态增强磁共振体积数据与动态增强磁共振图像的标签匹配得到有标签的动态增强磁共振体积数据。
[0058]
(1)根据人工标注病灶区域面积大小,在动态增强磁共振图像上截取病灶区域1倍和1.5倍大小的感兴趣区域(region of interest,roi)图像;
[0059]
(2)为了确保每个病例的图像数量相同,本发明选用切片位于序列中肿瘤最大横截面位置本身及其前4张和之后4张切片上截取感兴趣区域(roi)图像;
[0060]
(3)在9张切片中,将感兴趣区域(region of interest,roi)图像统一采样为32
×
32像素大小的图像,并将它们按顺序放入三维矩阵中。最后,得到了147个大小为32
×
32
×
9的体积数据。
[0061]
s3:将有标签的动态增强磁共振体积数据分为支持集和查询集,利用支持集和查询集构建时空循环注意力分类器。
[0062]
(1)对147个动态增强磁共振(dce-mri)体积数据构造n-way k-shot分类任务;
[0063]
(2)给出支持集和查询集样本,它们由{1,2,3,4,5}个样本组成,每个样本来自4个不同的类,构造出了4-way 1-shot、4-way 2-shot、4-way 3-shot、4-way 4-shot、4-way 5-shot的分类任务;
[0064]
(3)参照图4,时空循环注意力分类器包括:循环神经网络、注意力机制、批标准化层和池化层;
[0065]
进一步的,时空循环注意力分类采用循环神经网络(rnn)并加入注意力机制(ran),首先连接7
×7×
7的卷积运算,采用线性整流函数(relu)激活函数,然后连接一个批
标准化层用来缓解一定的过拟合现象,然后连接2
×2×
2的最大池化操作并加入注意力机制用来连接下一层;接着连接5
×5×
5的卷积运算,采用线性整流函数(relu)激活函数,然后连接一个批标准化层用来缓解一定的过拟合现象,然后连接2
×2×
2的最大池化操作并加入注意力机制用来连接下一层;再接着连接1
×1×
1的卷积运算,采用线性整流函数(relu)激活函数,然后连接一个批标准化层用来缓解一定的过拟合现象,然后连接2
×2×
2的最大池化操作;再接着进行压平操作;最后采用全连接层,采用归一化指数函(softmax)激活函数进行结果预测;本发明卷积操作都使用64个滤波器;内循环采用自定义梯度下降过程,学习率由模型自由选择;外循环学习率为0.001,采用adam优化器;
[0066]
其中,参照图5,循环神经网络包括3个卷积层:一个是前一层进入单元的输入,另一个是过去和未来时间帧的隐藏状态,最后一个是上一次迭代的隐藏状态,表示在第l层、时间帧t和迭代次数i的特征表达,表示在第l-1层、时间帧t和迭代次数i的特征表达,表示在第l层、时间帧t和迭代次数i-1的特征表达;是当信息在cran内向前传播时计算的表达,是在t-1时刻当信息在cran内向前传播时计算的表达;是信息在cran内向后传播时计算的表达,是在t 1时刻当信息在cran内向后传播时计算的表达。cran的详细表达为:
[0067][0068][0069][0070]
*为卷积运算,为线线性整流激活函数,w
l
为输入到隐藏卷积的过滤器,wi为在迭代过程中演化的隐藏到隐藏的循环卷积,w
t
为随时间演化的循环卷积滤波器,t为时刻,a
l
为一个偏差项;
[0071]
进一步的,构建时空循环注意力分类器(strac)学习4d图像形态学和药代动力学特征表征,具体包括以下步骤:
[0072]
给出动态mr序列为
[0073][0074]
定义时刻t的每个mri体积v
t
为
[0075][0076]
构造卷积循环注意力网络学习形态学和药代动力学表征,并周期性地利用循环注意力来模拟动态对比增强依赖性,可表示为:
[0077]yspatio-temporal
=fm(f
m-1
(
…
(f1(x
nt
))))
[0078]
其中,h和w为输入图像的高度和宽度,s为每个空间体积数中的切片数,t为时间点,v1,v2,
…vt
表示在1,2,
…
t时刻体积数据,表示在空间上具有s个切片数并
且具有t个时序数的高度为h宽度为w的总数据;表示在具体t时刻第1,2,
…
s的体积数据;y
spatio-temporal
代表卷积循环注意力的预测,x
nt
表示带切片的下采样图像序列,f表示卷积循环注意力网,m表示迭代次数。
[0079]
s4:参照图3,利用改进的元学习策略优化所述时空循环注意力分类器,通过所述时空循环注意力分类器进行分子亚型预测。
[0080]
(1)改进的元学习策略包括,对小样本数据集进行2步标准训练,所述2步标准训练包括内循环更新和外循环更新;
[0081]
(2)参照图6,内循环更新过程:元学习策略学习一批批的任务:定义一个具有元参数θ神经网络f
θ
,随机初始化θ=θ0,在对来自支持集xj的数据进行少量m梯度下降后,获得θm。使用查询集yj评估网络的分类性能。j是一批任务的索引,m是内循环更新次数。支持集xj使用梯度下降计算自适应参数:
[0082][0083]
表示在任务j上经过m次梯度下降后的基本网络参数权重,表示在任务j上经过m-1次梯度下降后的基本网络参数权重,α表示内部循环学习率,表示θ的随机梯度下降(sgd)过程,表示在任务j上经过m-1次梯度下降后的神经网络,表示支持集的损失。我们假设任务批量大小为j,并根据使用该查询集yj的总损失的平均来评估初始化θ0的性能;
[0084]
外循环更新过程:过程表示为:
[0085][0086]
θ0表示随机初始化参数,β表示外循环学习率,表示θ的随机梯度下降(sgd)过程,为查询集的损失;
[0087]
(3)计算时空循环注意力分类器的损失:
[0088][0089]
对于每一层,设置l个学习率实例供分类器选择。学习每个层的内环学习率公式定义为:
[0090][0091]
其中,αn为分类器第n层的内循环学习率,φ为随机选择函数,l1,l2,
…
,ln表示第1,2,
…
n的学习率,l为卷积循环注意力网可训练层的总数,为在第j批任务的第i组支持集或查询集的损失,xi为第i组支持集或查询集数据,yi为第i支持集或查询集标签,f
θ
′
(xi)为支持集或查询集的预测值。
[0092]
本实施例还提供一种可读存储介质,可读存储介质中存储有计算机程序,计算机程序被处理器执行时用于实现上述的各种实施方式提供的方法。
[0093]
其中,可读存储介质可以是计算机存储介质,也可以是通信介质,通信介质包括便于从一个地方向另一个地方传送计算机程序的任何介质,计算机存储介质可以是通用或专用计算机能够存取的任何可用介质;例如,可读存储介质耦合至处理器,从而使处理器能够从该可读存储介质读取信息,且可向该可读存储介质写入信息。
[0094]
当然,可读存储介质也可以是处理器的组成部分,处理器和可读存储介质可以位于专用集成电路(application specific integrated circuits,简称:asic)中,另外,该asic可以位于用户设备中,当然,处理器和可读存储介质也可以作为分立组件存在于通信设备中,可读存储介质可以是只读存储器(rom)、随机存取存储器(ram)、cd-rom、磁带、软盘和光数据存储设备等。
[0095]
实施例2
[0096]
为了对本方法中采用的技术效果加以验证说明,本实施选择原型网络(snell et al.2017)、匹配网络(vinyals et al.2016)、压缩-激励网络(se-net)(hu et al.2018)和采用本方法进行对比测试,以科学论证的手段对比试验结果,以验证本方法所具有的真实效果。
[0097]
为了对本方法中采用的技术效果加以验证说明,本实施例选择了传统的模型驱动元学习和本方法的改进的模型驱动元学习进行对比测试,结果如下表所示:
[0098]
表1模型驱动元学习精度对比表。
[0099][0100][0101]
参照表1,明显可以看出在相同迭代次数下相同的n-way k-shot,改进的模型驱动元学习的精度大于不改进的模型驱动元学习。
[0102]
传统的技术方案:需要大量的数据样本,并且训练一个性能卓越的神经网络需要大量的时间且不适用于小样本数据集,在少量数据情况下,将产生过拟合现象,导致结果的精度、均方根误差结果非常差。
[0103]
为验证本方法相对传统方法可以在少量数据样本情况下取得好的精度和减少均方根误差,本实施例中将采用传统的原型网络(snell et al.2017)、匹配网络(vinyals et al.2016)、压缩-激励网络(se-net)(hu et al.2018)和本方法分别对精度和均方根误差进行实时测量对比。
[0104]
为保证实验结果的有效性,传统的原型网络(snell et al.2017)、匹配网络(vinyals et al.2016)、压缩-激励网络(se-net)(hu et al.2018)和本方法均在jupyter notebook上通过tensorflow和keras框架实现,并且通过两个11gb nvidia rtx 2080ti gpus进行训练和测试;对于147个动态核磁共振体积图像,使用88个(约60%)作为训练图像和59个(约40%)作为测试图像;通过训练120个周期得到实验结果,结果如下表所示:
[0105]
表2本方法与其他方法的分类性能结果对比表。
[0106][0107]
参照表2,可以看到,本方法对应的精度明显高于其余三种方法,均方根误差明显低于其余三种方法,获得了更好的辨识效果。
[0108]
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。