1.本发明属于遥感图像识别技术领域,尤其涉及基于元核网络的小样本遥感场景分类方法。
背景技术:
2.场景分类是遥感图像解译领域的一个基础而重要的问题,其目的是根据语义内容为每张未标记的遥感图像分配一个特定的语义标签。该任务具有广泛的应用,包括灾害检测、住宅规划、环境监测、土地资源管理等。小样本遥感场景分类试图使模型迅速适应不出现在封闭训练集中的新场景,而每个新场景只有少数标记的例子。一方面,由于有限的样本很难描述数据的分布,所以模型要学习好的泛化特征是一个挑战;另一方面,由于表征受限,所以模型要学习依赖于样本偏差的分类边界是另一个挑战。
3.近年来,得益于高性能计算单元的发展,基于深度学习的方法凭借其出色的特征提取能力在遥感场景分类任务上取得了许多优异的成绩。该类方法的本质是使用自动编码机(auto encoder,ae)、深度信念网络(deep belief network,dbn)和卷积神经网络(convolutional neural network,cnn)等深度神经神经网络端到端的提取特征。一方面,这类方法都是基于封闭世界假设的,然而,在现实中,世界是开放的,本发明不得不面对封闭数据集中并不存在的新的遥感场景。另一方面,他们也都是数据饥渴的,因此这些标准监督的深度学习范式往往因为过拟合,无法为从少量数据中学习提供令人满意的解决方案。因此,为了减少对数据标注的依赖,更多的研究人员努力开发强大的方法,从很少的样本中学习新的概念,这就是所谓的小样本学习(fsl)。
4.为了解决fsl问题,最先进的方法当属元学习,其核心概念是学习一个模型,在给定任务(一组标记数据)的情况下,产生一个可以在所有任务中泛化的分类器。通过引入元学习策略和度量学习框架,匹配网络贡献了早期的小样本分类方法。原型网络和关系网络在此基础上做了进一步改进。这类方法通常由一个嵌入模块和一个度量模块组成。对于一个给定的未标记的遥感图像和几个标记的图像,嵌入模块首先生成所有输入图像的低维嵌入,然后度量模块通过测量未标记的图像特征和样本图像特征之间的距离给出识别结果。这类方法的本质是期望构建的嵌入空间能够更好地适应一些预先指定的距离度量函数,如余弦相似度或欧氏距离。然而,在实践中,由于只有嵌入模块是可学习的,固定的度量函数限制了特征提取器产生判别性的表示。sung,i等人试图通过引入一个隐含的可学习的度量模块来解决上述问题,但事实证明,由于其固有的局部连通性,比较能力仍然有限。
5.有些图片的"商业区"、"密集区"、"湿地和湖泊"、"高速公路"和"跑道"几乎没有区别,而"宫殿"和"教堂"也非常相似。标签样本的稀少放大了这些相似个体对分类边界的影响,使得这些类别之间的高度相似性导致了嵌入模块产生的低维特征的纠缠,这使得度量模块无法进行有效的线性划分。
6.此外,由于地面物体的复杂性和多样性,在采集过程中还会受到背景、光照和比例等成像条件的影响。因此,有些图片中同一语义类别的场景图像中的物体之间存在较大的
视觉差异,导致遥感图像的类内差异较大。这种大的类内变化导致类内特征分散现象。当样本数量足够丰富时,大量的样本可以弥补类的边界对样本的依赖性。然而,在小样本的情况下,当一个类的特征变得分散时,类内与类间方差比上升,类边界对选择一个样本的依赖性变得更强。这时通过对一个数据点进行抽样形成的分类边界往往会对大的区域进行错误分类,从而影响整体的分类精度。
7.小样本学习的核心是通过少数有监督信息的样本对新任务进行快速归纳,它大体上可以分为三种方法:基于生成的方法,基于梯度的方法,以及基于度量的方法。
8.基于生成的方法的核心思想是通过生成假的样本,将小的数据集扩展到大的数据集。y.wang提出了表示正则化技术为数据匮乏的类别幻化出额外的训练实例。l.gomez-chova等人通过从有足够例子的类中转移统计数据来校准少数样本类的分布,相似的,n.longbotham等人提出了一个带有数据平衡增强的光谱-空间分形残差卷积神经网络以解决高光谱分类中存在的标注样本有限问题。s.chaib等人提出了弓形网络,通过反馈回路共同学习三维几何和语义表征。
9.基于梯度的方法着重于通过梯度下降使模型参数快速适应新的任务。迭代地选择一批以前的任务,为每个任务训练学习者以计算梯度和损失,并在权重更容易被反向传播更新的方向上进行更新。对一个给定的任务进行随机梯度下降的k次迭代,然后逐渐将初始化权重向k次迭代后得到的权重移动。还可学习步长大小,或训练循环网络从梯度中预测步长。
10.基于度量的方法的目的是通过度量约束获取一个可以适应新任务的特征空间,这个特征空间与网络的权重相吻合。新的任务可以通过比较新的输入和该特征空间中的标签来学习。一个新的输入和这个标签之间的相似度越高,新的输入就越有可能属于该标签所代表的类别。孪生网络和匹配网络构建了基本学习范式,奠定了该类方法的基础。原型方法在此基础上开创性的提出原型中心的概念,通过一个前馈神经网络来嵌入任务实例,将类中心作为原型中心,使用最近邻分类器进行分类。在此基础上使用可学习的距离度量并提出一个均衡损失函数,目的是在最大化拟合能力的同时,可以在不同遥感场景中获得最大泛化能力。dla方法通过引入通道注意力和空间注意力模块以获得更具判别性的遥感影像特征,从全局和局部的角度捕捉遥感场景的辨别特征信息。
技术实现要素:
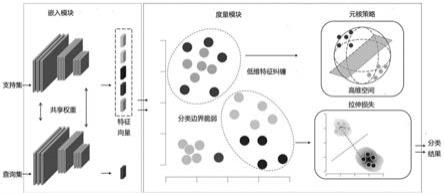
11.本发明提出了一个称为元核网络的网络框架,以提高小样本遥感场景分类的有效性。本发明的方法仍然在度量学习的框架内,并遵循episode(任务)的训练策略。首先,本发明摒弃了非参数化的最近邻分类器,将参数化的线性分类器融入度量空间以解除固定的度量函数对模型可学习性的限制。参数化线性分类器允许更多的灵活性,因为它们为不同的任务产生不同的参数集,可以学习更多的特定任务知识.第二,本发明提出元核策略,将度量空间中的特征二次映射到高维空间,从而有效的解决了因遥感影像类间高相似性而引起的低维特征纠缠问题。第三,本发明提出了一个新的损失函数,名为拉伸损失。该损失函数通过约束类内与类间的方差比,降低了类别边界对样本选择的依赖性,从而有效的解决了因遥感影像类内极大的差异性而引发的类别误判现象。
12.具体地,本发明公开的基于元核网络的小样本遥感场景分类方法,包括以下步骤:
13.选取给定不重叠的第一遥感数据集和第二遥感数据集,从第一遥感数据集中构建训练集和验证集,从第二遥感数据集中构建测试集;所述训练集、验证集和测试集包括多个任务,所述任务包括支持集和查询集;
14.对于每个任务,将给定的支持集嵌入到向量中;
15.采用参数化的线性分类器对嵌入得到的特征向量进行分类,为不同的任务产生不同的参数集,计算出最优解后,得到梯度最优线性逼近,再通过优化轨迹进行反向传播;
16.针对低维纠缠特征,使用非线性映射将度量空间中的特征二次映射到高维空间,扩大分离边界表面周围的空间分辨率;
17.使用拉伸损失函数约束类内与类间的方差比,强迫类内特征聚集;
18.使用最终的最优解,将小样本遥感图片进行场景分类。
19.进一步的,所述将给定的支持集嵌入到向量中的计算公式如下:
[0020][0021]
其中v为视觉特征向量,为网络参数。
[0022]
进一步的,所述采用参数化的线性分类器对嵌入得到的特征向量进行分类的计算如下:
[0023][0024]
t表示训练过程中采样的一个任务,p(t)是任务的分布,θ定义了用于预测验证集中的例子的线性回归权重,为从p(t)中抽取的新任务提供解决方案。
[0025]
进一步的,针对训练过程中采样的一个任务,都有
[0026][0027]
并且
[0028][0029]
其中
[0030][0031]
其中wn是第n个分类边界的参数,σn和σ
nk
是正则项,η是正则项系数,xi是第i个输入,yi是对应的预测值,n是分类任务的类别数,是获得由x参数化的预测模型。
[0032]
进一步的,所述计算出最优解后,得到梯度最优线性逼近,再通过优化轨迹进行反向传播包括:
[0033]
令c=(θ,λ,v),定义函数
[0034][0035]
其中diag(
·
)表示对角化操作,然后定义雅各比矩阵
[0036][0037]
当且仅当取得最优解;
[0038]
其中函数f和h分别是等式约束和不等式约束,f为求解拉格朗日鞍点其中函数f和h分别是等式约束和不等式约束,f为求解拉格朗日鞍点的函数,x是输入的图像。
[0039]
当计算出最优解时,就可以得到梯度最优线性逼近,然后通过优化轨迹进行反向传播。
[0040]
进一步的,所述使用非线性映射将度量空间中的特征二次映射到高维空间的计算公式如下:
[0041][0042]
其中,m
train
为支持集,m
test
为查询集,φ为非线性映射函数,θ定义用于预测验证集中例子的线性回归权重,v为视觉特征向量,y为真实标签。
[0043]
进一步的,损失函数计算如下:
[0044]
l=l
cls
αl
str
[0045]
其中l
cls
为分类损失函数,l
str
为拉伸损失函数。
[0046]
进一步的,所述分类损失函数l
cls
衡量嵌入模块中的分类效果,评估从同一分布中采样的测试数据的负对数可能性,计算如下:
[0047][0048]
其中wy是真实的分类边界,wk是第k个样本的预测边界,是获得由x参数化的预测模型。
[0049]
进一步的,所述拉伸损失函数,减小降低类别边界对样本选择的依赖性,提升分类边界鲁棒性,通过约束类内与类间的方差比,强迫类内特征聚集达成目的,计算如下:
[0050][0051]
其中,n表示类别数,k表示每个类别下包含的样本数,vi表示第i个输入图像的视觉特征,vi表示类别i的特征向量的均值,v表示所有特征向量的均值。
[0052]
本发明的有益效果如下:
[0053]
1、通过将参数化的线性分类器有效的融合到元学习框架中,使得本发明的模型高效利用了特定的任务信息,解除了固定距离对模型的限制。
[0054]
2、本发明提出一个元核策略,将嵌入空间中的特征二次映射到高维空间中,解决了因遥感影像类间相似性引发的低维特征纠缠问题,提高了分类边界清晰度,增强了分类
效果。
[0055]
3、本发明提出拉伸损失,通过减小类内类间方差比的方式,最大程度的降低了类别边界对样本选择的依赖性,有效的增加了分类边界的鲁棒性,提高了模型分类效果。
[0056]
4、在三个公开的、具有挑战性的遥感数据集上的实验结果表明,本发明提出的mkn方法取得了最先进的结果。
附图说明
[0057]
图1本发明基于元核网络的小样本遥感场景分类方法框架图。
具体实施方式
[0058]
下面结合附图对本发明作进一步的说明,但不以任何方式对本发明加以限制,基于本发明教导所作的任何变换或替换,均属于本发明的保护范围。
[0059]
本发明提出了用于小样本遥感分类的元核网络(mkn)的方法。本发明的方法在元度量学习的框架下,遵循episode的训练策略。针对每一个任务task,嵌入模块获取遥感图像特征,度量模块对不同特征进行线性分类。一方面,针对低维特征纠缠问题,本发明提出元核策略将其二次映射到较高维空间进行解缠,另一方面,为了降低类别边界对样本选择的依赖性本发明通过伸展loss约束类内与类间的方差比,强迫类内特征聚集。
[0060]
问题定义:
[0061]
给定不重叠的遥感数据集c
seen
和c
unseen
,本发明的目标是快速识别从c
unseen
中抽取的n个不同的遥感场景,每个场景仅含有k个有标签样本。由于本发明拟解决的是小样本的遥感场景分类问题,所以k的设定通常很小,通常k∈{1,5}。训练集d
train
和验证集d
val
是从c
seen
中构建的,测试集d
test
是从c
unseen
构建的,验证集d
val
的作用是选择合适的超参数和最好的模型,并且和训练集没有交集,即d
train
∩d
val
=φ。d
train
,d
val
和d
test
都包含多个任务(episode)。每一个episode由支持集m
train
和查询集m
test
组成,即组成,即其中e
tr
,e
val
,e
ts
分别代表训练,验证,测试过程中esipode的数量。训练阶段,对于每一个episode,本发明通过从d
train
中采样m个不同的类别,每个类别k个有标签样本构建支持集从剩下的类别中采样n个类别构建查询集合注意m
train
和m
test
也没有交集,即m
train
∩m
test
=φ。
[0062]
嵌入模块:
[0063]
本发明的最终目标是通过求解
[0064][0065]
获得由x参数化的预测模型
[0066]
其中l为损失函数,衡量真实标签和由预测的标签之间的误差。l由两个部分组成,第一部分衡量嵌入模块中的分类效果,第二部分为拉伸损失loss。它通过约束类内与类间的方差比,强迫类内特征聚集。通过嵌入模块,本发明将数据域映射到特征空间从而使得视觉信息彼此关联。即,对于每个任务episode,给定的数据集m
train
嵌入到一个向量中:
[0067][0068]
度量模块:
[0069]
度量模块需要针对嵌入模块得到的特征向量给出一个最佳的分类方案,传统方法大多使用最近邻分类器,然而这种分参数化的方法忽略了与任务相关的信息,固定的度量函数限制了特征提取器产生判别性的表示。因此,本发明采用参数化的线性分类器使度量空间具有更大的灵活性,因为它们可以为不同的任务产生一组不同的参数,并学习更多的特定任务知识。
[0070][0071]
t表示了训练过程中采样的一个任务,p(t)是任务的分布。θ定义了用于预测验证集中的例子的线性回归权重,为从p(t)中抽取的新的任务提供一个好的解决方案。针对每一个任务,都有
[0072][0073]
并且
[0074][0075]
其中
[0076][0077]
其中wn是第n个分类边界的参数,σn和σ
nk
是正则项,η是正则项系数,xi是第i个输入,yi是对应的预测值,n是分类任务的类别数,是获得由x参数化的预测模型。
[0078]
本发明的嵌入模块是可微的,为了使整个模型可以端到端的训练,这就需要本发明的嵌入模块也是可微分的,即本发明需要计算出线性分类模型的梯度,然后进行反向传播,从而优化模型。
[0079]
考虑如下优化问题:
[0080]
minimize
[0081]
这里向量θ是问题的优化变量,向量x是输入数据,函数f0是目标函数,函数f和h分别是等式约束和不等式约束,假设函数fi在固定的θ下是凸的,则可以通过求解以下拉格朗日的鞍点来优化目标,
[0082]
f(θ,λ,v,x)=f0(θ,x) λ
t
f(θ,x) v
t
h(θ,x)
ꢀꢀꢀꢀꢀ
(7)
[0083]
充分且必要的最优条件如下:
[0084][0085][0086][0087][0088][0089]
如果在一个连通区域内雅可比行列式恒等于零,则函数组是函数相关的,其中至少有一个函数是其余函数的一个连续可微的函数,也就是说,雅可比矩阵能够体现一个微分方程与给出点的最优线性逼近。
[0090]
所以,本发明令z=(θ,λ,v),定义函数
[0091][0092]
其中diag(
·
)表示对角化操作。然后定义雅各比矩阵
[0093][0094]
当且仅当取得最优解;
[0095]
其中函数f和h分别是等式约束和不等式约束,f为求解拉格朗日鞍点其中函数f和h分别是等式约束和不等式约束,f为求解拉格朗日鞍点的函数,x是输入的图像。
[0096]
当计算出最优解时,就可以得到梯度最优线性逼近,然后通过优化轨迹进行反向传播。
[0097]
针对低维纠缠特征,本发明引入元核的策略,使用非线性映射φ(x)将度量空间中的特征二次映射到高维空间(c可以是无穷大),通过共形映射扩大分离边界表面周围的空间分辨率,从而提高不同类别之间的可分离性,核函数定义如下:
[0098][0099]
其中
[0100][0101]
并且
[0102]
[0103]
其中σ虽然是核函数超参数,但是它可以通过不同的任务和θ一同学习,一切都无需人为设定,这不仅使得模型以数据驱动的方式运行,也大大提高了模型效果和效率。此时公式3可以重新表达为:
[0104][0105]
损失函数
[0106]
本发明的损失函数由两部分组成,第一部分衡量嵌入模块中的分类效果。本发明评估了从同一分布中采样的测试数据的负对数可能性:
[0107][0108]
wy是真实的分类边界,wk是第k个样本的预测边界,是获得由x参数化的预测模型。
[0109]
第二部分本发明命名为拉伸loss。遥感影像存在类间巨大的相似性,这就造成了度量空间内类内特征离散现象,在数据量很小时,分类边界很容易受到采样点的影响,即分类边界脆弱。因此,为了减小降低类别边界对样本选择的依赖性,提升分类边界鲁棒性,本发明提出拉伸损失loss。它通过约束类内与类间的方差比,强迫类内特征聚集达成目的。
[0110][0111]
n表示类别数,k表示每个类别下包含的样本数,vi表示第i个输入图像的视觉特征,vi表示类别i的特征向量的均值,v表示所有特征向量的均值。因此,本发明的损失函数是:
[0112]
l=l
cls
αl
str
ꢀꢀꢀ
(17)
[0113]
实验结果
[0114]
本发明将提出的mkn与三个基准数据集上的代表性和最先进的方法进行了比较。不难看出,无论是只给定一个样本(k=1)还是五个样本(k=5),本发明的方法都表现出最好的性能,在uc_merced数据集上分别达到57.29%和75.42%的场景分类精度,在aid上达到58.45%和77.92%的场景分类精度,在nwpusiscs数据集中达到65.84%和82.67%的场景分类精度。此外,本发明还报告了在这三个数据集中的每一个上以混淆矩阵衡量的结果。在每个数据集中,本发明都显示了1次和5次的混淆矩阵,如图所示,其中第i行和第j列的条目代表了第i类的测试图像被分类为第j类的比率。
[0115]
表1 nwpu-resisc45数据集上不同方法的分类精度(%)(粗体字代表每种情况下这些方法中的最佳精度)
[0116][0117]
表2 aid数据集上不同方法的分类精度(%)(粗体字代表每种情况下这些方法中的最佳精度)
[0118][0119]
表3 uc_merced数据集上不同方法的分类精度(%)(粗体字代表每种情况下这些方法中的最佳精度)
[0120][0121]
本发明的有益效果如下:
[0122]
1、通过将参数化的线性分类器有效的融合到元学习框架中,使得本发明的模型高效利用了特定的任务信息,解除了固定距离对模型的限制。
[0123]
2、本发明提出一个元核策略,将嵌入空间中的特征二次映射到高维空间中,解决了因遥感影像类间相似性引发的低维特征纠缠问题,提高了分类边界清晰度,增强了分类效果。
[0124]
3、本发明提出拉伸损失,通过减小类内类间方差比的方式,最大程度的降低了类别边界对样本选择的依赖性,有效的增加了分类边界的鲁棒性,提高了模型分类效果。
[0125]
4、在三个公开的、具有挑战性的遥感数据集上的实验结果表明,本发明提出的mkn
方法取得了最先进的结果。
[0126]
本文所使用的词语“优选的”意指用作实例、示例或例证。本文描述为“优选的”任意方面或设计不必被解释为比其他方面或设计更有利。相反,词语“优选的”的使用旨在以具体方式提出概念。如本技术中所使用的术语“或”旨在意指包含的“或”而非排除的“或”。即,除非另外指定或从上下文中清楚,“x使用a或b”意指自然包括排列的任意一个。即,如果x使用a;x使用b;或x使用a和b二者,则“x使用a或b”在前述任一示例中得到满足。
[0127]
而且,尽管已经相对于一个或实现方式示出并描述了本公开,但是本领域技术人员基于对本说明书和附图的阅读和理解将会想到等价变型和修改。本公开包括所有这样的修改和变型,并且仅由所附权利要求的范围限制。特别地关于由上述组件(例如元件等)执行的各种功能,用于描述这样的组件的术语旨在对应于执行所述组件的指定功能(例如其在功能上是等价的)的任意组件(除非另外指示),即使在结构上与执行本文所示的本公开的示范性实现方式中的功能的公开结构不等同。此外,尽管本公开的特定特征已经相对于若干实现方式中的仅一个被公开,但是这种特征可以与如可以对给定或特定应用而言是期望和有利的其他实现方式的一个或其他特征组合。而且,就术语“包括”、“具有”、“含有”或其变形被用在具体实施方式或权利要求中而言,这样的术语旨在以与术语“包含”相似的方式包括。
[0128]
本发明实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以多个或多个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。上述提到的存储介质可以是只读存储器,磁盘或光盘等。上述的各装置或系统,可以执行相应方法实施例中的存储方法。
[0129]
综上所述,上述实施例为本发明的一种实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何背离本发明的精神实质与原理下所做的改变、修饰、代替、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。