1.本发明涉及机器学习技术领域,尤其涉及一种基于深度学习的微波乳腺肿瘤分类方法。
背景技术:
2.在乳腺肿瘤检测中,确定肿瘤的大小和位置对于预防性诊断至关重要。因此,一种快速准确的肿瘤定位和大小估计方法非常重要。虽然磁共振成像(mri)和计算机断层扫描(ct)服务于当代医疗需求,但它们价格昂贵、体积大而且重量大,不适用于乳腺肿瘤的早期诊断。
3.电磁成像技术作为现有成像方式的补充,有很大的发展前景。电磁成像使用环绕乳腺的天线阵列测量透射和反射系数,这些复值参数可以使用各种技术进行处理,例如层析成像和基于雷达的技术,以完成基于成像的检测、定位和分类。层析成像需要正向和反向求解器,耗费很长时间计算数万个未知量,而且也需要精确的电磁仿真工具和昂贵的计算硬件。另一方面,基于雷达的技术在不均匀组织下很难实施,通常不能提供分类。机器学习可以弥补这些缺点,能够提供几乎实时结果。深度卷积神经网络是处理这种高度非线性和复杂任务非常好的选择。但是,一个主要的障碍是训练网络所需的数据量,该技术仍处于初级阶段尚未投入使用,需要使用模拟环境中的数据,虽然模拟需要巨大的计算能力,但它们仍是获取基本训练数据非常实用的解决方案。然而,基于完全模拟的结果,在实际应用中可能会遇到困难。
技术实现要素:
4.本发明克服现有技术存在的不足,所要解决的技术问题为:基于完全模拟训练的网络,在实际应用中可能会遇到困难的问题,以及传统方法中存在的计算量大、无法实时成像的技术问题。
5.本发明解决其技术问题所采用的技术方案是:构造一种基于深度学习的微波乳腺肿瘤分类方法,包括:
6.通过在健康乳腺的随机位置放置不同大小的肿瘤来创建乳腺肿瘤病例,通过创建的乳腺肿瘤病例的有限差分时域模拟创建合成数据集,构成源域数据集;
7.设置多个印刷单极天线,在第一直径的外环等角度放置构成发射器阵列,对应数量的多个印刷单极天线在第二直径的内环等角度放置构成接收器阵列,第三直径的均匀乳腺模型放置圆环中心;使用双端口矢量网络分析仪收集双基地数据,获得实张量目标域数据集;
8.搭建域对抗神经网络,在源域数据集和目标域数据集之间建立映射,通过建立映射的源域数据集和目标域数据集对构建的域对抗神经网络进行训练,至输出结果与数据集实际表示的乳腺肿瘤类型一致为止;
9.将实时的微波乳腺肿瘤图像输入训练完成的域对抗神经网络中,输出结果作为乳
腺肿瘤分类结果。
10.其中,域对抗神经网络由三部分组成,特征提取器、标签预测器和域分类器;特征提取器将数据映射到特征空间,使标签预测器能分辨出源域数据的标签,域分类器分辨不出数据来自源域还是目标域;
11.域对抗神经网络只能对源域数据集进行分类,要想实现目标域数据集的分类任务必须让域对抗神经网络把目标域数据看作成源域数据;在训练阶段的两个任务,第一个是实现源域数据集准确分类,实现标签预测误差最小化;第二个任务是混淆源域数据集和目标域数据集,实现域分类误差的最大化。
12.其中,域分类器有两个损失函数:一个是二元交叉熵,另一个是混淆域分类器;标签预测器和域分类器在训练过程中相互对抗最终实现了图像标签预测损失和域分类损失之间的相互平衡。
13.其中,使用软分类方法,将乳腺肿瘤区域离散为41个单元,创建41维向量,每个条目对应一个单元格,并包含肿瘤区域位于该单元格中的多少,之后归一化以创建有效的分布。
14.其中,使用kullback-lerbler(kl)散度,作为软分类问题的准确率度量,它测量由于从一个分布到另一个分布的散度而获得的额外信息。
15.本发明与现有技术相比具有以下有益效果:
16.本发明提供了一种基于域对抗神经网络的微波乳腺肿瘤分类方法,在训练分布和测试分布之间存在偏移的情况下,在源域和目标域之间尽力映射,使源域学习的分类器也可以适用于目标域;相比于传统方法解决微波乳腺电磁逆散射问题相比,可实现实时分类且计算量小;相比于先前的神经网络,可将2d乳腺肿瘤仿真分类应用于3d 实验环境中。
附图说明
17.下面将结合附图及实施例对本发明作进一步说明,附图中:
18.图1是本发明提供的一种基于深度学习的微波乳腺肿瘤分类方法的流程示意图。
具体实施方式
19.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明做进一步的详细说明。应当理解,此外所描述的具体实施例仅用以解释本发明,但并不用于限定本发明。基于本发明中的实施例,本领域普通人员在没有做出创造性劳动前提下所获得的所有其他实施例,都将属于本发明保护的范围。
20.参照附图1,本发明提供的一种基于深度学习的微波乳腺肿瘤分类方法,包括:
21.通过在健康乳腺的随机位置放置不同大小的肿瘤来创建乳腺肿瘤病例,通过创建的乳腺肿瘤病例的有限差分时域模拟创建合成数据集,构成源域数据集;
22.设置多个印刷单极天线,在第一直径的外环等角度放置构成发射器阵列,对应数量的多个印刷单极天线在第二直径的内环等角度放置构成接收器阵列,第三直径的均匀乳腺模型放置圆环中心;使用双端口矢量网络分析仪收集双基地数据,获得实张量目标域数据集;
23.搭建域对抗神经网络,在源域数据集和目标域数据集之间建立映射,通过建立映
射的源域数据集和目标域数据集对构建的域对抗神经网络进行训练,至输出结果与数据集实际表示的乳腺肿瘤类型一致为止;
24.将实时的微波乳腺肿瘤图像输入训练完成的域对抗神经网络中,输出结果作为乳腺肿瘤分类结果。
25.其中,域对抗神经网络由三部分组成,特征提取器、标签预测器和域分类器;特征提取器将数据映射到特征空间,使标签预测器能分辨出源域数据的标签,域分类器分辨不出数据来自源域还是目标域;
26.域对抗神经网络只能对源域数据集进行分类,要想实现目标域数据集的分类任务必须让域对抗神经网络把目标域数据看作成源域数据;在训练阶段的两个任务,第一个是实现源域数据集准确分类,实现标签预测误差最小化;第二个任务是混淆源域数据集和目标域数据集,实现域分类误差的最大化。
27.本发明使用了一种域自适应技术来弥补将深度神经网络应用于电磁学中的合成数据和真实数据之间的差距。该技术允许依赖于计算机模拟的数据,同时使其适应现实环境。所提出的方法在源域和目标域之间建立映射,从而当与域之间的学习映射组合时,以至于源域学习的分类器也可以应用于目标域。
28.通过在健康乳腺的不同位置放置大小不同的肿瘤来创建乳腺肿瘤病例,使用9000个带有肿瘤的乳腺病例的有限差分时域模拟创建合成数据集,构成了源域数据集。
29.目标域数据集由真实实验获得,16个印刷单极天线分别在直径500mm的外环和直径300mm的内环等角度放置构成发射器阵列和接收器阵列,直径为100毫米的均匀乳腺模型可以放置在圆环中心。使用双端口矢量网络分析仪收集双基地数据,获得的目标域数据集。
30.在本发明中,不是最小化分类器对正确域标签的信任,而是最大化对错误标签的信任。在这种设置下,使用软分类方法,将乳腺肿瘤区域离散为41个单元,创建41维向量,每个条目对应一个单元格,并包含肿瘤区域位于该单元格中的多少,之后归一化以创建有效的分布。
31.其中,使用kullback-lerbler(kl)散度,作为软分类问题的准确率度量,它测量由于从一个分布到另一个分布的散度而获得的额外信息。
32.具体的,为了创建用于训练神经网络的合成散射场数据,首先通过将mri乳腺图像的断层切片中的每个像素值转换成相应的复值介电常数来创建磁共振成像导出的数值乳腺模型。作为基础模型,使用了四种不同类型共9个磁共振成像衍生乳腺模型。
33.这些健康的乳腺模型来自于威斯康星大学计算电磁学实验室开发和维护的在线存储库。每个模型由立方体体素的三维网格组成,其中每个体素为0.5mm
×
0.5mm
×
0.5mm。乳腺模型包括大约1.5毫米厚的皮肤层、乳腺底部1.5厘米厚的皮下脂肪层和0.5厘米厚的肌肉胸壁。从9个不同的真实三维乳腺模型中提取的50个2d切片创建的,提供了450个不同的2d乳腺切片。
34.为了产生足够数量的具有各种肿瘤的数据训练神经网络,在9个乳腺模型中肿瘤存在的像素处的介电常数值首先被设置为纤维腺组织介电常数值。然后对每个乳腺模型的50个2d切片,生成1000个模型,其中一个或两个肿瘤占据纤维腺区域。500个模型具有一个肿瘤,另外500个模型由两个肿瘤组成。生成的肿瘤具有大约1.1-1.5cm 的最大直径,而且随机位于纤维腺区域内。因此数据集由9000个乳腺模型组成,每个模型有500张单个和两个
肿瘤图像。
35.在真实数据方面,使用了均匀介质模型。
36.在构建均匀乳腺模型时,乳腺被当做是一个完整的脂肪层,内部有一个肿瘤。均匀乳腺模型、肿瘤和皮肤的材料和混合比例列于表1。对于均匀乳腺模型,使用氯化钠、聚乙烯粉末、黄原胶、脱氢醋酸钠一水化合物和蒸馏水。用聚乙烯粉末调节介电常数,用氯化钠调节电导率。琼脂用于通过防止水含量的分离来保持模型的形状,黄原胶被用作增稠剂,脱氢醋酸钠一水化合物用作防腐剂。基本上,改变模型介电性能的材料是氯化钠、聚乙烯粉末、琼脂和蒸馏水,它们是模型的主要成分。乳腺模型的半径为50毫米,肿瘤直径为10毫米,位于乳腺内部随机点。
37.脂肪的介电常数为12.58,电导率为0.141s/m,肿瘤的介电常数为57.37,由于其含水量较高,肿瘤具有较高的介电常数。还制备了一个3毫米的表层,表层材料的介电性能测量值为23.44。放置在乳腺模型下用于分析身体效应的类肌肉材料的介电常数接近44。
[0038][0039]
表1均匀体模所用材料和混合比一览表
[0040]
实验装置使用印刷单极天线,发射器所在的外环直径为500毫米, 16个印刷单极天线等角度放置,接收器所在的内环直径为300毫米,同样也为16个印刷单极天线等角度放置,直径为100毫米的均匀乳腺模型可以放置在中心,使用双端口矢量网络分析仪收集双基地数据,通过手动将接收器切换到16个位置中的每一个位置来获取阵列的合成数据。测量过程:将发射器和接收器分别连接到矢量网络分析仪的端口1和端口2。更改端口2的接收天线,在对15个位置进行完全扫描后,将发射天线移动到下一个位置,并重复该过程。
[0041]
整个数据集形成大小为250
×
16
×
16
×
2的张量(2表示复信号的实部和虚部)。在3ghz的工作频率下,数据集为16
×
16复值s参数矩阵,包含由介质加载波导组成的多静态操作的16通道微波阵列的透射和反射系数。
[0042]
在电磁学中,用仿真对现实进行精确建模并不简单,也不容易实现,因为有无数复杂的因素需要根据传输线和物理理论来考虑。因为一个经过模拟数据训练的深度卷积网络可能在实际数据中失败。在计算机视觉中,当在不同数据集的图像上进行测试时,在一个数据集上训练的神经网络可能在另一个数据集上的性能急剧下降,即使这两个数据集具有相同的对象。域自适应算法致力于解决这个问题。
[0043]
在训练分布和测试分布之间存在偏移的情况下,学习有区别的分类器或其他预测器被称为域自适应。所提出的域对抗神经网络在源域和目标域之间建立映射,从而当与域之间的学习映射组合时,以至于源域学习的分类器也可以应用于目标域。
[0044]
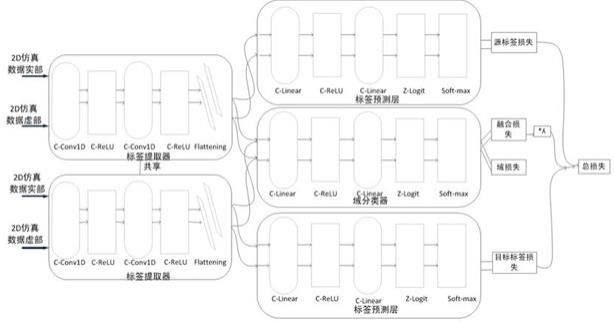
在最常见的域自适应场景中,第一个领域具有较多的标记数据 (称为源域),而感兴趣的域具有较少的数据(称为目标域)。在我们的设置中,源域是合成仿真数据,目标域是实验室中的真实场景。采用域对抗神经网络(dann)。第一部分是dann网络;第二部分是重新定义损失函数;第三部分是使用软分箱作为分类器;第四部分软分类问题的准确率度量。
[0045]
dann的基本结构由三部分组成:特征提取器(feature extractor, fe)、标签预测器(label predictor,lp)和域分类器(domain classifier,dc)。
[0046]
特征映射器gf:将数据映射到特征空间,使gy能分辨出源域数据的标签,gd分辨不出数据来自源域还是目标域。
[0047]
标签预测器gy:对于特征空间的源域数据进行分类,尽可能分辨出正确的标签。
[0048]
域分类器gd:对特征空间的数据进行域分类,尽可能分辨出数据来自于哪个域。
[0049]
在dann训练,网络的输入为带有图像分类标签的源域数据集和不带图像分类标签的目标域数据集,以及源域和目标域数据集的域分类标签。dann只能对源域数据集进行分类,要想实现目标域数据集的分类任务必须让dann把目标域数据看作成源域数据。在训练阶段的两个任务,第一个是实现源域数据集准确分类,实现标签预测误差最小化;第二个任务是混淆源域数据集和目标域数据集,实现域分类误差的最大化。标签预测器和域分类器在训练过程中相互对抗最终实现了图像标签预测损失和域分类损失之间的相互平衡。
[0050]
dann的输入x∈x,其中x代表图像输入空间,分类标签y∈y,其中y(y={1,2,3,...,k})代表分类标签空间。在dann中有两种数据分布:源域数据分布s(x,y)和目标域数据分布τ(x,y)。dann的目标是准确预测目标域输入图像的分类标签。
[0051]
训练样本为{x1,x2,...,xn}分别来自源域和目标域的边缘分布s(x) 和τ(x)。同时定义di为第i个训练样本的域标签,其中di∈{0,1}。若di=0 则xi~s(x),反之di=1则xi~t(x)。
[0052]
dann的图像输入x在训练阶段首先会经过特征提取网络 f=gf(x;θf)的映射转换为一个d维的特征向量,即f∈rd。dann会分成两个分支即标签预测网络gy(x;θy)和域分类网络gd(x;θd)。源域数据输入对应的特征向量会经过gy(x;θy)的映射获得对应标签预测结果。不管是源域输入还是目标域输入的特征向量都会经过gd(x;θd)得到每个输入的域分类结果。
[0053]
使用sgd算法进行优化dann的模型参数,dann模型参数的梯度更新公式如下:
[0054][0055][0056][0057]
从后面两个公式可以看出,域分类器和标签预测器的输入都来自于特征提取器,
但是域分类器的目标是最大化域分类损失,混淆目标域数据与源域数据,但是标签预测器的目标是最小化标签预测的损失。
[0058]
学习率也是随着迭代进程变换的,变换公式如下
[0059][0060]
其中μ0为初始学习率,值为0.01,p代表迭代进程相对值,即当前迭代次数与总迭代次数的比率,α和β属于超参数,α=10,β=0.75。
[0061]
重新定义损失函数
[0062]
在本发明中,不是最小化分类器对正确域标签的信任,而是最大化对错误标签的信任,在这种设置下,域分类器将有两个损失函数。第一个是常用的二元交叉熵,试图使分类器更好。第二个损失函数试图混淆域分类器。
[0063][0064]
n是批次的大小,h(xi)是输入xi的分类器输出,yi是对应标签。
[0065]
对于特征提取器,sigmoid作为激活函数,输出为
[0066]
gf(x;w,b)=sigm(wx b)
[0067]
对于标签预测器,softmax作为激活函数,输出为
[0068]
gf(gf(x);v,c)=softmax(vgf(x) c)
[0069]
当给定数据点(xi,yi),负对数似然作为损失函数,标签预测器的损失为
[0070][0071]
因此在源域上,训练的优化目标是
[0072][0073]
其中,表示第i个样本的标签预测损失,r(w,b)是一个正则化器,λ是人为设置的正则化参数,λ
·
r(w,b)是用来防止神经网络过拟合。
[0074]
由于混淆损失公式在结构上具有对抗性,因此消除了在dann中常使用的梯度反转层的需要。
[0075]
则最小化的总损失函数变成:
[0076]
loss
total
=loss
lp
source loss
lp
target λloss
confusion
[0077]
域分类器损失与总损失完全分离,因此,可以有一个单独的优化器对其权重进行操作。
[0078]
根据实际情况重新表述为一个软分类问题。为了实现这一点,将成像域离散为41个单元,为定位提供了足够的分辨率,对于每一个乳腺肿瘤案例,根据其参数构建一个乳腺肿瘤区域。然后,创建一个41维的向量,每个条目对应一个单元格,并包含肿瘤区域位于该单元格中的多少。之后需要归一化以创建有效的分布。这种技术被称为“软分箱”。
[0079]
如果简单地采用分类交叉熵损失本身作为性能度量,它没有反映真实的表现。这使得在观察损失曲线时,很难判断神经网络是否表现良好。为了解决这个问题,使用
kullback-lerbler(kl)散度,它测量由于从一个分布到另一个分布的散度而获得的额外信息。
[0080]
kl(p||q)=cxε(p||q)-h(p)
[0081]
cxε是分类交叉熵,h是熵度量。从信息论的角度来看,kl将测量外部信息,而不是测量cxε的新熵。熵的这种减法精确地消除了交叉熵的可变偏差,因此,当神经网络以最佳方式获得零损失,而不是返回cxε(p||q)=cxε(q||q)=cxε(p||p),其等于熵h(p)和 h(q)。前者依赖于当前的数据点,在大多数情况下是非零的。从优化的角度来看,这种变化不会产生任何影响,尽管熵是依赖于实例的,但相对于神经网络的参数是恒定的。
[0082]
在所有情况下,16
×
16矩阵整形为105维的一维向量;神经网络接收s矩阵的堆叠实部和虚部,
[0083]
在域自适应中,源域数据集中的训练集和测试集比例为1:10,目标域中80%用于训练,20%用于测试。批次大小被设置为32。对抗效应逐渐进入训练程序,以避免混淆标签预测器和域分类器。这是通过使λ以指数方式从0增长到1.0的训练计划实现。
[0084]
和传统的实值多层感知机进行对比,输入为s参数的绝对值,16
×
16矩阵被重塑为105维的一维向量(s参数具有对称性质,其冗余值被丢弃),神经网络接收s矩阵的实部。
[0085]
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。