1.本发明涉及科技大数据价值评估领域,具体的说是一种基于文本内容的科技大数据创新性评估方法。
背景技术:
2.近些年来,随着网络及通信技术的蓬勃发展,人们在生活生产中所涉及到的数据呈爆发式增长,现代社会也已迈进大数据时代,而科技大数据是一类能够反映人类科技活动状态和过程的信息资源。它可以支持人类洞察新思想、发现新规律、发明新技术、开发新产品。换言之,一方面,科技大数据和其它普通数据一样,都具有价值;另一方面,基于自身的特性,科技大数据的价值以科技创新导向为主;所以说,创新性是科技大数据不可或缺的特性,也是其区别于其它数据的根本特征。
3.科技大数据包括科技论文、专利、软著、标准规范、政策建议等,包括大量的以文本内容数据为代表的非结构化数据,其中对科技论文与发明专利的价值和创新性研究较多,一方面,研究者通过建立价值评估指标体系,运用传统计量模型来刻画数据价值,但对于文本内容等非结构化数据的质量却较难以衡量;另一方面,有学者运用词频分析、共现词分析等传统文本分析方法及以lda为代表的主题模型方法来衡量文本内容的质量,而对文本内容的创新性评估刻画较少。
技术实现要素:
4.本发明为克服现有技术存在的不足之处,提供一种基于科技大数据文本内容的创新性评估方法,以期能够有效地评估科技大数据的创新性高低,并提高评估准确性,从而为有价值的科技大数据的评估和筛选奠定基础。
5.本发明为达到上述发明目的,采用如下技术方案:
6.本发明一种基于科技大数据文本内容的创新性评估方法的特点是按如下步骤进行:
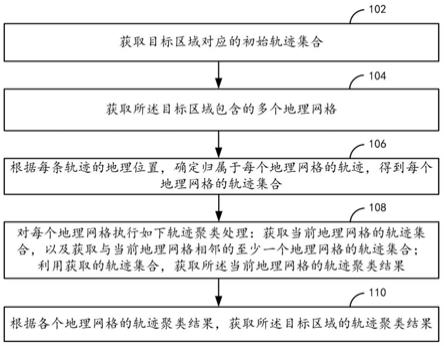
7.步骤1、获取待评估的科技大数据的文本内容集合并进行去重去缺失的预处理后,按照文本内容的生成时间,将预处理后的文本内容进行划分,得到带有时间戳的文本内容{d1,d2,...,dm,...,dm};dm表示第m篇文本内容,m表示文本内容集合中的文本篇数;
8.步骤2、对第m篇文本内容dm进行分词、去停留词以及合并重复词的处理,得到分词后的第m篇文本内容后的第m篇文本内容表示分词后的第m篇文本内容d
′m中的第n个词,nm表示分词后的第m篇文本内容d
′m中的不同词的总数;从而由m篇文本内容中的所有分词构成语料库d;
9.步骤3、使用tf-idf模型处理分词后的文本内容,提取待评估的科技大数据的关键词并构建文档词向量;
10.步骤3.1、利用式(1)计算语料库d中分词后的第m篇文本内容d
′m的第n个词的tf-idf值t
nm
:
[0011][0012]
式(1)中,表示分词后的第m篇文本内容d
′m中第n个词的词频,表示分词后的第m篇文本内容d
′m中第n个词在语料库d中的逆文档频率;
[0013]
步骤3.2、构建待评估的科技大数据的文档词向量;
[0014]
将所述语料库d中各篇文本内容之间的重复词进行合并,得到合并后的语料库d
′
={t1,t2,...,t
p
,...,t
p
},t
p
表示第p个词;p表示所述合并后的语料库d
′
中的总词数,利用式(2)计算第p个词t
p
在分词后的第m篇文本内容d
′m中的重要程度x
pm
,从而得到分词后的第m篇文本内容d
′m的词向量xm=(x
1m
,x
2m
,
…
,x
pm
,
…
,x
pm
)
t
,进而得到时间窗m下所有文档的词向量x=(x1,x2,...,xm,...,xm)并作为稀疏矩阵;
[0015][0016]
步骤4、运用主成分分析法对稀疏矩阵x进行降维;
[0017]
步骤4.1、将稀疏矩阵x中的每一行元素分别进行零均值化处理,得到矩阵h;
[0018]
步骤4.2、计算协方差矩阵
[0019]
步骤4.3、计算协方差矩阵c的特征值及对应的单位正交特征向量,并将特征向量按对应特征值大小降序按行组成矩阵p;
[0020]
步骤4.4、取矩阵p中前k行元素组成的矩阵并乘以矩阵h,从而得到降维后的矩阵y=(y1,y2,...,ym,...,ym),其中,ym表示降维后的第m个文档词向量,且y
km
表示降维后的第m个文档词向量中第k个维度值;k<<p;
[0021]
步骤5、计算时间窗m下降维后的第m个文档词向量ym与降维后的第z个文档词向量yz之间的余弦相似性值cos《ym,yz》,用于表示第m篇文本内容dm与第z篇文本内容dz之间的相似性sim《dm,dz》,从而得到第m篇文本内容dm与其他文本内容之间的文本相似性集合{sim《dm,dz》|z=1,2,
…
,m,且z≠m};
[0022]
步骤6、对文本相似性集合{sim《dm,dz》|z=1,2,
…
,m,且z≠m}中的相似性进行降序排序,选取文本相似性最大的前l个值,并将第l个相似性值作为第m篇文本内容dm的创新性值,将第m篇文本内容dm的创新性值进行标准化处理,得到第m篇文本内容dm的创新性评分;
[0023]
步骤7、按照步骤5和步骤6的过程计算时间窗m下所有m篇文本内容的创新性评分并进行降序排列,从而完成待评估的科技大数据的文本内容集合的创新性评估。
[0024]
与已有技术相比,本发明有益效果体现在:
[0025]
1、本发明获取科技大数据文本内容数据进行预处理,剔除存在缺失值的数据,重复的数据仅保留生产时间的最近的一项,并根据年份将被评估数据归类到各时间窗下;并结合已有成熟的停留词表,通过jieba分词,对科技大数据文本内容进行分词,删去其中的停留词,并去除无实义的虚词;大大提高了科技大数据文本数据的质量,有利于提升实际数据文本分析的效率;
[0026]
2、本发明使用tf-idf模型处理分词后的文本数据,提取科技大数据的关键词,对
每份被评估科技大数据分词后数据计算tf-idf值,实现了对该时间窗下的每份科技大数据关键主题、信息的体现,通过文本的分词与tf-idf值构建科技大数据的文档词向量,为后续文本间相似性的度量做好了准备工作;
[0027]
3、本发明通过构建每一时间窗下所有文档词向量组成的稀疏矩阵,运用主成分分析法(pca)通过对稀疏矩阵进行行压缩的方法,对文档词向量进行降维;解决了高维空间中样本点距离计算问题,为后续文档词向量相似性的计算做准备,提升了后续相似性度量的准确率;有利于准确地刻画该时间窗下领域内所有科技大数据的创新性;
[0028]
4、本发明通过计算降维后文档词向量之间的余弦相似度表示文档之间的相似性;最后结合最近邻(knn)思想,将每一科技大数据与其他所有科技大数据相似性最高的若干个值中最小的相似度值即可表示该科技大数据的创新性大小,有利于评估出科技大数据的创新性大小及价值高低,从而更有效地对创新性较高,有价值的科技大数据进行筛选。
附图说明
[0029]
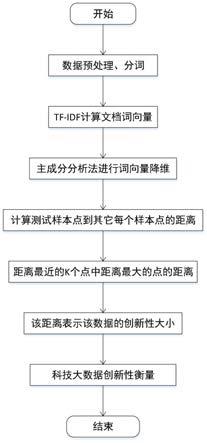
图1是本发明的基于科技大数据文本内容的创新性评估的流程图。
具体实施方式
[0030]
本实施例中,一种基于科技大数据文本内容的创新性评估方法,是通过tf-idf模型对被评估科技大数据文本内容的关键词进行提取;再通过关键词及其tf-idf值构建文档词向量,组成稀疏矩阵;并运用主成分分析法(pca)通过对稀疏矩阵进行行压缩的方法,对文档词向量进行降维;然后通过计算降维后文档词向量之间的余弦相似度表示文档之间的相似性;最后,结合最近邻(knn)思想,将每一文本与其他所有文本相似性最高的l个值中最小的相似度值即可表示该文本的创新性大小,具体的说,如图1所示,是按如下步骤进行:
[0031]
步骤1、获取待评估的科技大数据的文本内容集合并进行去重去缺失的预处理后,按照文本内容的生成时间,将预处理后的文本内容进行划分,得到带有时间戳的文本内容{d1,d2,...,dm,...,dm};dm表示第m篇文本内容,m表示文本内容集合中的文本篇数;
[0032]
步骤2、对第m篇文本内容dm进行分词、去停留词以及合并重复词的处理,得到分词后的第m篇文本内容后的第m篇文本内容表示分词后的第m篇文本内容d
′m中的第n个词,nm表示分词后的第m篇文本内容d
′m中的不同词的总数;从而由m篇文本内容中的所有分词构成语料库d;
[0033]
步骤3、使用tf-idf模型处理分词后的文本内容,提取待评估的科技大数据的关键词并构建文档词向量;
[0034]
tf-idf(term frequency-inverse document frequency)用于评估词语对于文档集或语料库中文本的重要程度,由tf-idf由两部分组成:tf和idf。
[0035]
步骤3.1:词频(tf)为该词在一个文本样本中出现的频率,假设dm为某一具体文本样本,为分词后按位置排列第n个词(若有重复词则选择该词首次出现位置为准,后续重复词不计位置),则该词在该文本样本中的词频可利用式(1)表示为该词出现的频次与该文本中所有词出现的总频次的比值:
[0036][0037]
步骤3.2:逆文档频率(idf)用来评价词语对于语料库的普遍性。在本实施例中,语料库d为每个时间窗下所有的分词后的科技大数据文本内容数据,的idf值可以利用式(2)由d中所有包含的文本数与总样本数n表示为:
[0038][0039]
步骤3.3:利用式(3)计算语料库d中分词后的第m篇文本内容d
′m的第n个词的tf-idf值t
nm
:
[0040][0041]
式(3)中,表示分词后的第m篇文本内容d
′m中第n个词的词频,表示分词后的第m篇文本内容d
′m中第n个词在语料库d中的逆文档频率;
[0042]
步骤3.4、构建待评估的科技大数据的文档词向量;
[0043]
将语料库d中各篇文本内容之间的重复词进行合并,得到合并后的语料库d
′
={t1,t2,...,t
p
,...,t
p
},t
p
表示第p个词;p表示合并后的语料库d
′
中的总词数,利用式(4)计算第p个词t
p
在分词后的第m篇文本内容d
′m中的重要程度x
pm
,从而得到分词后的第m篇文本内容d
′m的词向量xm=(x
1m
,x
2m
,
…
,x
pm
,
…
,x
pm
)
t
,进而得到时间窗m下所有文档的词向量x=(x1,x2,...,xm,...,xm)并作为稀疏矩阵;
[0044][0045]
步骤4、运用主成分分析法对稀疏矩阵x进行降维;
[0046]
步骤4.1、利用式(5)将稀疏矩阵x中的每一行元素分别进行零均值化处理,得到矩阵h:
[0047][0048]
式(5)中,且满足且满足
[0049]
步骤4.2、利用式(6)计算协方差矩阵
[0050][0051]
式(6)中,协方差矩阵c是一个p行p列的实对称矩阵,其对角线元素分别对应矩阵h每行数据的方差,而第i行第j列和第j行第i列元素相同,表示矩阵h第i行第j列第j行数据之间的协方差:
[0052]
步骤4.3、利用式(7)计算协方差矩阵c的特征值及对应的单位正交特征向量,并利用式(8)将特征向量按对应特征值大小降序按行组成矩阵p;
[0053]
求出c的特征值,并按大小顺序排列依次为λ1,λ2,λ3,...,λ
p
,由于c为p行p列的实对称矩阵,不难求出与特征值λ1,λ2,λ3,...,λ
p
依次对应的p个单位正交特征向量e1,e2,e3,...,e
p
,将其按列组成矩阵e=(e1,e2,e3,...,e
p
),则对协方差矩阵c有如下结论:
[0054][0055][0056]
步骤4.4、利用式(9)取矩阵p中前k行元素组成的矩阵并乘以矩阵h,从而得到降维后的矩阵y=(y1,y2,...,ym,...,ym),其中,ym表示降维后的第m个文档词向量,且y
km
表示降维后的第m个文档词向量中第k个维度值;k<<p;
[0057][0058]
步骤5、计算时间窗m下降维后的第m个文档词向量ym与降维后的第z个文档词向量yz之间的余弦相似性值cos《ym,yz》,用于表示第m篇文本内容dm与第z篇文本内容dz之间的相似性sim《dm,dz》,从而得到第m篇文本内容dm与其他文本内容之间的文本相似性集合{sim《dm
,dz》|z=1,2,
…
,m,且z≠m};
[0059]
步骤5.1、利用式(10)计算k维向量空间中不同文档词向量之间的相似性sim:
[0060][0061]
式(10)中,y
jm
表示降维后的第m个文档词向量中第j个维度值,y
jz
表示降维后的第z个文档词向量中第j个维度值,m,z=1,2,3,...,m,m≠z,j=1,2,...,k;
[0062]
步骤5.2、计算每个文档词向量与其他所有的文档词向量之间的余弦相似度,构成m个集合,其中每个集合有m-1个元素,集合依次为:
[0063]
{sim《d1,dm》|1《m≤m},{sim《d2,dm》|1≤m≤m,q≠2},
……
,{sim《dm,dm》|1≤m<m}
[0064]
步骤6、对文本相似性集合{sim《dm,dz》|z=1,2,
…
,m,且z≠m}中的相似性进行降序排序,选取文本相似性最大的前l个值,并将第l个相似性值作为第m篇文本内容dm的创新性值,将第m篇文本内容dm的创新性值进行标准化处理,得到第m篇文本内容dm的创新性评分;
[0065]
步骤6.1、对每一集合中的余弦相似度值进行降序排序,选择与该文本相似度最高的l个值,其中最小的相似度值即可表示该文本的创新性大小,文档dj(j=1,2,3...,m,...,m)的创新性大小可表示为式(11):
[0066]
sim
l
(dj)(j=1,2,3...,m,...,m;l=1,2,3,...,k)
ꢀꢀꢀ
(11)
[0067]
步骤6.2、对科技大数据创新性计算结果进行标准化,并进行百分制赋分,如式(12)所示,时间窗m下大数据文本文档dj(j=1,2,3...,m,...,m)的创新性可表示为:
[0068][0069]
式(12)中,sim
max
为sim
l
(dj)的最大值,j=1,2,3...,m,...,m,l=1,2,3,...,k;
[0070]
步骤7、按照步骤5和步骤6的过程计算时间窗m下所有m个文档词向量的创新性评分并进行降序排列,从而完成待评估的科技大数据的文本内容集合的创新性评估。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。