技术特征:
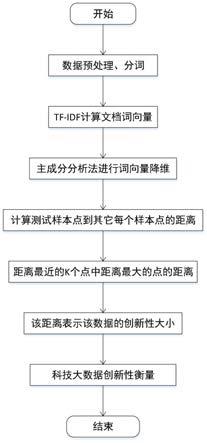
1.一种基于科技大数据文本内容的创新性评估方法,其特征是按如下步骤进行:步骤1、获取待评估的科技大数据的文本内容集合并进行去重去缺失的预处理后,按照文本内容的生成时间,将预处理后的文本内容进行划分,得到带有时间戳的文本内容{d1,d2,...,d
m
,...,d
m
};d
m
表示第m篇文本内容,m表示文本内容集合中的文本篇数;步骤2、对第m篇文本内容d
m
进行分词、去停留词以及合并重复词的处理,得到分词后的第m篇文本内容第m篇文本内容表示分词后的第m篇文本内容d
′
m
中的第n个词,n
m
表示分词后的第m篇文本内容d
′
m
中的不同词的总数;从而由m篇文本内容中的所有分词构成语料库d;步骤3、使用tf-idf模型处理分词后的文本内容,提取待评估的科技大数据的关键词并构建文档词向量;步骤3.1、利用式(1)计算语料库d中分词后的第m篇文本内容d
′
m
的第n个词的tf-idf值t
nm
:式(1)中,表示分词后的第m篇文本内容d
′
m
中第n个词的词频,表示分词后的第m篇文本内容d
′
m
中第n个词在语料库d中的逆文档频率;步骤3.2、构建待评估的科技大数据的文档词向量;将所述语料库d中各篇文本内容之间的重复词进行合并,得到合并后的语料库d
′
={t1,t2,...,t
p
,...,t
p
},t
p
表示第p个词;p表示所述合并后的语料库d
′
中的总词数,利用式(2)计算第p个词t
p
在分词后的第m篇文本内容d
′
m
中的重要程度x
pm
,从而得到分词后的第m篇文本内容d
′
m
的词向量进而得到时间窗m下所有文档的词向量x=(x1,x2,...,x
m
,...,x
m
)并作为稀疏矩阵;步骤4、运用主成分分析法对稀疏矩阵x进行降维;步骤4.1、将稀疏矩阵x中的每一行元素分别进行零均值化处理,得到矩阵h;步骤4.2、计算协方差矩阵步骤4.3、计算协方差矩阵c的特征值及对应的单位正交特征向量,并将特征向量按对应特征值大小降序按行组成矩阵p;步骤4.4、取矩阵p中前k行元素组成的矩阵并乘以矩阵h,从而得到降维后的矩阵y=(y1,y2,...,y
m
,...,y
m
),其中,y
m
表示降维后的第m个文档词向量,且y
km
表示降维后的第m个文档词向量中第k个维度值;k<<p;步骤5、计算时间窗m下降维后的第m个文档词向量y
m
与降维后的第z个文档词向量y
z
之间的余弦相似性值cos<y
m
,y
z
>,用于表示第m篇文本内容d
m
与第z篇文本内容d
z
之间的相似
性sim<d
m
,d
z
>,从而得到第m篇文本内容d
m
与其他文本内容之间的文本相似性集合{sim<d
m
,d
z
>]z=1,2,
…
,m,且z≠m};步骤6、对文本相似性集合{sim<d
m
,d
z
>|z=1,2,
…
,m,且z≠m}中的相似性进行降序排序,选取文本相似性最大的前l个值,并将第l个相似性值作为第m篇文本内容d
m
的创新性值,将第m篇文本内容d
m
的创新性值进行标准化处理,得到第m篇文本内容d
m
的创新性评分;步骤7、按照步骤5和步骤6的过程计算时间窗m下所有m篇文本内容的创新性评分并进行降序排列,从而完成待评估的科技大数据的文本内容集合的创新性评估。
技术总结
本发明公开了一种基于科技大数据文本内容的创新性评估方法,包括:1、科技大数据文本内容的获取、预处理及分词;2、使用TF-IDF模型处理分词后的科技大数据文本数据,构建待评估的科技大数据文档词向量;3、运用主成分分析法(PCA)对文档词向量进行降维;4、计算时间窗M下所有文档之间的相似性,用每个文档词向量之间的余弦相似度表示;5、对每一集合中的相似度值进行降序排序,选择与该文本相似度最高的L个值,其中最小的相似度值即可表示该文本的创新性大小,并得出标准化后的创新性评分。本发明能够有效地评估科技大数据的创新性高低,并提高评估准确性,从而为有价值的科技大数据的评估和筛选奠定基础。估和筛选奠定基础。估和筛选奠定基础。
技术研发人员:刘业政 陈航 姜元春 钱洋 孙见山 柴一栋 王继成 袁昆
受保护的技术使用者:合肥工业大学
技术研发日:2021.12.08
技术公布日:2022/3/8
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。