1.本发明涉及一种基于语音识别的“路怒”情绪判断方法和装置,属于人工智能,嵌入式系统技术,数字信号处理技术,检测技术领域。
背景技术:
2.在事故总体数量占比以及人员在事故中的伤亡占比,人为因素都占据了将近90%的比例。驾驶员在驾驶中的情绪状态与随后的驾驶行为之间存在非常显著的相关关系。我国约有60.72%的机动车驾驶员有“路怒”的经历。
3.因此,有效检测“路怒”情绪存在必要性,同时结合语音愤怒情绪判断模式的可扩展性,设计了基于语音识别的“路怒”情绪判断方法。路怒症,指汽车或其他机动车的驾驶人员有攻击性或愤怒的行为。此类行为可能包括:粗鄙的手势、言语侮辱、故意用不安全或威胁安全的方式驾驶车辆,或实施威胁。这个说法源于上个世纪80年代,产生于美国。
4.现有技术缺少基于语音识别的“路怒”情绪判断方法及对应的云边协同架构,无法及时更新语音识别系统中的算法参数,导致语音识别结果的准确率低。
技术实现要素:
5.鉴于以上内容,本发明提出一种基于语音识别的“路怒”情绪判断方法、装置,本发明云边协同更新算法模型中的算法参数,随着驾驶员驾车时长的提升,提高了语音识别“路怒”情绪的准确率。
6.本发明的目的是通过以下技术方案来实现的:一种基于语音识别的“路怒”情绪判断方法,所述方法包括:
7.(1)车载端实时获取的驾驶员的原始音频并进行预处理,得到用于算法模型处理的目标音频;
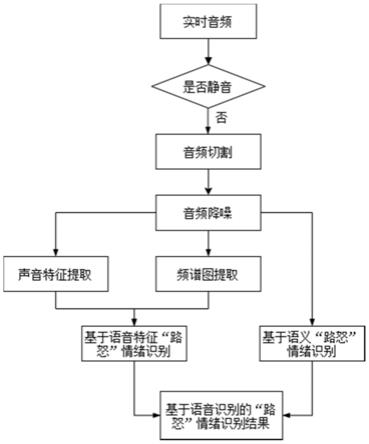
8.(2)根据语音识别的“路怒”情绪判断方法流程对所述目标音频进行“路怒”情绪判断,得到识别结果,其中,所述语音识别的“路怒”情绪判断方法流程包含三个识别节点,每个识别节点包含有不同的算法模型;其中,第一个识别节点算法模型用于对目标音频合规检测及音频切割,第二个识别节点算法模型用于音频降噪、特征提取和生成频谱,第三个识别节点算法模型用于语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果;
9.(3)采集驾驶员面部视频,将面部视频输入面部情绪识别的神经网络中,得到基于视频采集面部“路怒”情绪识别结果;对比针对基于语音的“路怒”情绪识别结果与基于视频采集面部“路怒”情绪识别结果;若存在差异,则将当前识别节点运行的算法模型参数、过去一段时间的目标音频以及基于语音的“路怒”情绪识别结果上传到云平台,云平台基于上传的数据对各个算法模型进行重新训练,更新算法模型的参数;
10.(4)云平台在完成算法模型参数更新后,向车载端发送更新后的算法模型参数;车载端基于更新后的算法模型参数进行后续的基于语音识别的“路怒”情绪判断。
11.进一步地,实时获取驾驶员音频,并进行预处理包括:
12.实时获取驾驶员的原始音频,从所述原始音频中提取音频码流;
13.采用库函数对所述音频码流进行解码获取能够用于算法模型计算的目标音频,所述库函数包含python中的librosa和wave。
14.进一步地,将目标音频输入第一个识别节点对应的第一算法模型中进行语音合规检测,得到第一结果包括:
15.对所述目标音频进行静默检测,识别出目标音频中的非静音片段;
16.根据所述非静音片段对所述目标音频进行切割,得到多个子音频,并将所述的多个子音频作为第一结果。
17.进一步地,将第一结果输入第二个识别节点对应的第二算法模型中进行处理,得到第二结果包括:
18.当第二个识别节点对应的第二算法模型接收到第一结果时,提取所述第一结果中的多个子音频的第一语音信号,并将所述第一语音信号进行降噪处理得到第二语音信号,将所述第二语音信号作为第二结果第一部分;
19.将所述第二语音信号分成多个短时帧信号,提取多个短时帧信号的声音特征,根据所述多个短时帧信号生成频谱图,并将所述声音特征及频谱图作为第二结果第二部分。
20.进一步地,将第二结果第一部分及第二结果第二部分输入至第三个识别节点对应的第三算法模型中进行情绪检测,得到目标识别结果包括:
21.判断第二结果第一部分的语义中,是否包含“唤醒词”,所述唤醒词为语音助手唤醒的词句;如果语音信号中包含“唤醒词”,则不进行语义分析,如果语音信号中不包含“唤醒词”,则进行语义分析,获得语义“路怒”情绪识别结果;
22.基于第二结果第二部分根据语音特征分析,获得语音特征“路怒”情绪识别结果;
23.根据语义“路怒”情绪识别结果及语音特征“路怒”情绪识别结果进行权重计算得到“路怒”情绪识别结果作为基于语音识别的“路怒”情绪识别结果,所述权重根据实际驾驶员的性格习惯进行适应调整。
24.进一步地,所述面部情绪识别的神经网络为利用opencv的haar面部检测及cnn分类的网络。
25.本发明还提供了一种基于语音识别的“路怒”情绪判断装置,所述装置包括车载端和云平台:
26.所述车载端包括:中央处理器、数据采集模块、存储模块、通信模块、边缘计算模块和摄像头;
27.所述数据采集模块用于采集驾驶员声音,获取原始音频;
28.所述存储模块存储采集的驾驶员声音数据、当前识别节点的算法模型参数以及基于语音识别的“路怒”情绪识别结果数据;
29.所述通信模块用于实现车载端与云平台通信;
30.所述边缘计算模块用于对采集的原始音频进行预处理,得到用于算法模型处理的目标音频;将目标音频经过“路怒”情绪判断方法流程进行检测,车载端的边缘计算模块部署了三个识别节点,每个识别节点包含有不同的算法模型;其中,第一个识别节点算法模型用于对目标音频合规检测及音频切割,第二个识别节点算法模型用于音频降噪、特征提取
和生成频谱,第三个识别节点算法模型用于语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果;
31.同时所述边缘计算模块上部署了面部情绪识别的神经网络,用于识别基于摄像头采集的驾驶员面部视频,得到基于视频采集面部“路怒”情绪识别结果;
32.所述中央处理器将对比针对基于语音的“路怒”情绪识别结果与基于视频采集面部“路怒”情绪识别结果;若存在差异,则将当前存储模块内的算法模型参数、过去一段时间的驾驶员声音数据以及基于语音的“路怒”情绪识别结果通过通信模块上传到云平台;
33.所述云平台基于通信模块上传的数据对各个算法模型进行重新训练,更新算法模型的参数;向车载端的边缘计算模块和存储模块发送更新的算法模型参数;存储模块和边缘计算模块的算法模型参数更新;同时存储模块将已上传数据进行删除。
34.本发明的有益效果:本发明语音识别的“路怒”情绪判断方法流程包含三个识别节点,流程清晰完整。利用了语音特征及语义共同对于“路怒”情绪判断,根据驾驶员性格习惯的算法权重调整,增加了算法的可靠性。基于视频采集面部“路怒”情绪识别算法判断结果与基于“语音”识别的“路怒”情绪判断结果不同时,将语音数据及算法数据从车载端上传至云端进行算法更新后,下载至车载端,云边协同,减轻了边缘端的计算压力,随着驾驶员驾车时长的提升,提高了语音识别“路怒”的准确率。
附图说明
35.图1是本发明实施例一提供的基于语音识别的“路怒”情绪判断方法的流程图。
36.图2是本发明实施例一提供的基于语音识别的“路怒”情绪判断方法的算法更新方法的流程图。
37.图3是本发明实施例二提供的基于语音识别的“路怒”情绪判断方法装置的结构示意图。
具体实施方式
38.下面将结合本技术实施例中的附图,对本实施例中的技术方案进行清楚、完整地描述。
39.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
40.实施例一
41.如图1所示,在本实施例中,可以预先设置基于语音识别的“路怒”情绪判断方法流程,根据所述预设的基于语音识别的“路怒”情绪判断方法流程实时获取的驾驶员音频,并进行预处理,得到用于算法模型处理的目标音频,对所述目标音频进进行“路怒”情绪判断,得到识别结果。
42.具体地,实时获取驾驶员音频,并进行预处理包括:
43.实时获取驾驶员的原始音频,从所述原始音频中提取音频码流;
44.采用库函数对所述音频码流进行解码获取能够用于算法模型计算的目标音频,所述库函数包含python中的librosa和wave。
45.所述语音识别的“路怒”情绪判断方法流程包含三个识别节点,每个识别节点包含有不同的算法模型;其中,第一个识别节点算法模型用于对目标音频合规检测及音频切割,第二个识别节点算法模型用于音频降噪、特征提取和生成频谱,第三个识别节点算法模型用于语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果。
46.所述的基于语音识别的“路怒”情绪判断方法,将目标音频输入第一个识别节点对应的第一算法模型中进行语音合规检测,得到第一结果;
47.所述的基于语音识别的“路怒”情绪判断方法,将第一结果输入第二个识别节点对应的第二算法模型中进行处理,得到第二结果;
48.所述的基于语音识别的“路怒”情绪判断方法,将第二结果输入至第三个识别节点对应的第三算法模型中进行情绪检测,得到目标识别结果。
49.本实施例中,预设的第一算法模型为vad算法,在第一个识别节点,通过vad算法对所述目标音频进行合规检测,识别出目标音频中的非静音片段,根据所述非静音片段对所述目标音频进行切割,得到多个子音频,并将所述的多个子音频作为第一结果;
50.预设的第二算法模型为信号处理和特征提取模型,对所述第一结果进行音频降噪,特征提取,生成频谱,得到第二结果;
51.预设的第三算法模型为基于语音的“路怒”情绪识别模型,对所述第二结果进行语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果。
52.具体地,所述将所述目标音频输入至所述基于语音识别的“路怒”情绪判断方法流程的第一个识别节点对应的预设的第一算法模型中进行语音合规检测,得到第一结果包括:
53.对所述目标音频进行静默检测,识别出目标音频中的非静音片段;
54.根据所述非静音片段对所述目标音频进行切割,得到多个子音频,并将所述的多个子音频作为第一结果。
55.本实施例中,使用librosa音频处理库实现对语音信号的读取、算得到子音频能量、过零率、切割,使用vad算法进行对所述子音频进行静默检测。
56.所述的vda算法步骤为:首先获取目标音频背景噪音的能量,能量取平方均值,噪音的能量值需要设置一个最小门限,防止出现很安静的状态下误处理。比较当前目标音频的语音能量大于噪音能量,并对音频进行过零检测及过零持续时间统计,满足所设阈值,可判断目标音频为非静音状态,得到取非静音目标音频,对于非静音目标音频进行切割,获得多个非静音子音频作为第一结果。
57.具体地,所述预设的第二算法模型为信号处理和特征提取模型,对所述第一结果进行音频降噪,特征提取,生成频谱得到第二结果包括:
58.当第二个识别节点对应的预设的第二算法模型接收到第一结果时,提取所述第一结果中的多个子音频得到第一语音信号,并将所述第一语音信号输入进行降噪处理得到第二语音信号,将所述第二语音信号作为第二结果第一部分;
59.将所述第二语音信号分成多个短时帧信号,提取多个短时帧信号的声音特征,根据所述多个短时帧信号生成频谱图,并将所述声音特征及频谱图作为第二结果第二部分。
60.具体地,短时帧长度为10-30ms,语音信号具有时变性,但认为在短时间内相对稳定,所述短时间为10-30ms。
61.具体地,所述提取多个短时帧信号的声音特征包括:
62.使用librosa音频处理库提取多个短时帧的声音特征,包含mfcc、plp-cc、基频特征、共振峰特征、短时能量,并将提取特征向量化,并进行向量拼接,作为根据所述所述声音特征向量,同时生成频谱图,并将所述声音特征及频谱图作为第二结果第二部分。
63.预设的第三算法模型将第二结果输入至语义“路怒”情绪识别结果及语音特征“路怒”情绪识别模型,获得权重计算后的基于语音的“路怒”情绪识别结果包括:
64.将第二结果第一部分根据语义“路怒”情绪识别,获得语义“路怒”情绪识别结果。
65.将第二结果第二部分根据语音特征“路怒”情绪识别,获得语音特征“路怒”情绪识别结果。
66.根据语义“路怒”情绪识别结果及语音特征“路怒”情绪识别结果权重计算获取“路怒”情绪识别结果。
67.具体地,所叙述将第二结果第一部分根据语义“路怒”情绪识别,获得语义“路怒”情绪识别结果包括:
68.使用语音识别算法对于第二结果第一部分进行语义识别,获得语义文本;
69.利用jieba分词库对于语义文本进行分割,获得语义词;
70.基于情感词典文本匹配算法对语义词进行匹配,逐个遍历分词后的语句中的词语,如果语义词中包含“唤醒词”,则不进行“路怒”情感分析,如果语音信号中不包含“唤醒词”,则进行语义分析,如果词语命中词典,则语义“路怒”得分加1,在指定时长内,对得到语义“路怒”得分进行计算,得到情绪识别结果;
71.具体地,所叙述将第二结果第二部分根据语音特征“路怒”情绪识别,获得语音特征“路怒”情绪识别结果包括:
72.当第三个识别节点对应的预设的第三算法模型接收到第二结果第二部分时,将所述频谱图通过opencv图片读取库进行读取,将图片尺寸进行统一、归一化、向量化,通过输入至预先训练好的频谱提取cnn网络中,提取结果输出层前的全连接输出层,作为语音特征的第一部分;
73.将所述声音特征向量作为语音特征提取的第二部分;
74.将所述语音特征提取第一部分及第二部分拼接,进行pca降维,作为目标声音特征向量;
75.将所述目标声音特征向量输入至训练好的lstm分类器中,得到语音特征“路怒”情绪识别结果。
76.具体地,所叙述根据语义“路怒”情绪识别结果及语音特征“路怒”情绪识别结果权重计算获取“路怒”情绪识别结果作为基于语音的“路怒”情绪识别结果包括:
77.将语义“路怒”情绪识别结果及语音特征“路怒”情绪识别结果权重计算获取“路怒”情绪识别结果乘以预设的权重系数,得到基于语音的“路怒”情绪识别结果;
78.具体地,所述权重根据实际驾驶员的性格习惯进行适应调整。当驾驶员在“路怒”时,通过语义表现“路怒”,如有抱怨,说脏话等言语,则提高语义“路怒”情绪识别结果权重,当驾驶员在“路怒”时,通过语音特征表述“路怒”,如突然音调变高,声音变大,则提高语音
特征“路怒”情绪识别权重。
79.实施例二
80.如图2所示,在本实施例中,所述基于语音识别的“路怒”情绪判断方法的算法更新方法可以应用于车载端,针对的是算法模型中的参数,可以直接在车载端上集成本发明的方法所提供的基于语音识别的“路怒”情绪判断的算法参数更新的功能,或者以软件开发工具包(software development kit,sdk)的形式运行在车载端中。
81.所述基于语音识别的“路怒”情绪判断的算法参数更新方法具体包括以下步骤,根据不同的需求,该流程图中步骤的顺序可以改变,某些可以省略。
82.s1,解析实时获取的原始音频,获取目标音频。
83.本实施例中,所述原始音频一般为“.mp3”格式的音频文件。
84.在一个可选的实施例中,所述解析预设实时获取的原始音频,获取目标音频包括:
85.实时获取原始音频,并进行预处理,得到用于算法模型处理的目标音频。
86.s2,根据语音识别的“路怒”情绪判断方法流程对所述目标音频进行“路怒”情绪判断,得到目标识别结果,其中,所述语音识别的“路怒”情绪判断方法流程包含多个识别节点,每个识别节点包含有不同的算法模型;。
87.本实施例中,可以预先设置语音识别流程,根据所述预设的基于语音识别的“路怒”情绪检测流程对所述目标音频检测“路怒”情绪,本实施例所述预设的语音识别流程可以包括三个识别节点,每个识别节点中包含由预设的算法模型。所述目标识别结果是指整个预设的语音识别流程的最后一个识别节点输出的识别结果,在一个较佳的实施例中,也可以包括所有识别节点的识别结果。
88.s3,将基于语音识别的“路怒”情绪的结果与基于视频采集面部“路怒”情绪识别结果进行对比。
89.本实施例中,采集驾驶员面部视频,将面部视频输入面部情绪识别的神经网络中,得到基于视频采集面部“路怒”情绪识别结果;所述面部情绪识别的神经网络为利用opencv的haar面部检测及cnn分类的网络。所述两种识别结果是针对从输入到输出的相同时间节点时间段内的所述语音识别与面部图像进行“路怒”情绪识别,即驾驶员在某一时间段内的“路怒”情绪通过不同形式表现。
90.由于基于语音识别的“路怒”情绪流程与面部视频的“路怒”流程,流程不一致,将致使检测时长不一致,对两者时长进行测算后,从而获得对应的识别结果。
91.由于驾驶员在“路怒”中可能存在表现上的不一致,如仅仅产生“路怒”情绪,但是没有在语音中体现,因此,存在“路怒”情绪被检测,但基于语音识别的“路怒”情绪检测为“非路怒”的情况,对该类情况进行记录,在算法数据更新中可以起到参考意义。
92.算法更新主要针对的是,驾驶员在语音中体现“路怒”情绪,且基于视频采集面部“路怒”情绪识别为“路怒”,但是基于语音识别的“路怒”情绪的识别结果为“非路怒”,或驾驶员在语音中体现为“路怒”,且通过面部图像识别结果为“非路怒”,主要体现为基于语音识别的“路怒”情绪的结果与基于视频采集的面部“路怒”情绪识别的结果进行对比不一致。因此,可以基于视频采集的面部“路怒”情绪识别结果对语音识别的“路怒”情绪的算法参数进行修正。
93.s4,若存在所述结果不一致,根据所述模型更新算法中的参数。
94.本实施例中,若存在所述结果不一致,将当前运行模型参数,目标音频,针对语音识别结果上传云平台,云平台基于上传数据更新预设的目标算法模型中的算法参数。
95.云平台在完成算法更新后,向车载端发送更新的算法模型;
96.车载端接收云平台发送的算法模型,以完成语音识别的“路怒”情绪判断算法参数更新。
97.可选地,由于每个流程节点中包含有一个预设的算法模型,在出现所述结果不一致,可以根据所述结果不一致,对于基于语音的“路怒”判断算法正确的识别结果进行确定,从而对于流程中的模型训练,实现参数更新。
98.所述根据差异更新语音识别的“路怒”情绪判断算法参数更新包括:语义分析算法参数、语音特征算法参数以及“路怒”情绪识别结果及语音特征“路怒”情绪识别结果权重值;
99.本实施例中,可以预先设置更新规则,所述更新规则可以根据不同的指标参数范围进行设置,不同的指标参数对应不同的更新规则。
100.本实施例中,由于每个预设的算法模型中预先配置有算法参数,当出现所述结果不一致时,确定更新规则对所述预设的目标算法模型中的算法参数进行更新,例如:
101.当异常指标参数值为语义“路怒”情绪识别结果不准确,造成原因可能为语句被截断,造成的语义识别结果不准确,因此增长子音频长度,对于情感词典文本进行补充,当语义“路怒”情绪识别结果长期不准确,可降低在语义“路怒”情绪识别结果及语音特征“路怒”情绪识别结果权重中语义“路怒”情绪识别结果的权重;当异常指标参数值为驾驶员停顿比较多时,根据驾驶员停顿指标参数值确定更新规则调整vad静音时长;当异常指标参数值为语义特征“路怒”情绪识别结果不准确,调整声音特征的数量,cnn、lstm网络参数。
102.实例三
103.如图3所示,本发明的第三方面提供基于语音识别的“路怒”情绪判断装置。所述装置包括车载端和云平台:
104.所述车载端包括:中央处理器、数据采集模块、存储模块、通信模块、边缘计算模块和摄像头;
105.所述数据采集模块用于采集驾驶员声音,获取原始音频;
106.所述存储模块存储采集的驾驶员声音数据、当前识别节点的算法模型参数以及基于语音识别的“路怒”情绪识别结果数据;
107.所述通信模块用于实现车载端与云平台通信;
108.所述边缘计算模块用于对采集的原始音频进行预处理,得到用于算法模型处理的目标音频;将目标音频经过“路怒”情绪判断方法流程进行检测,车载端的边缘计算模块部署了三个识别节点,每个识别节点包含有不同的算法模型;其中,第一个识别节点算法模型用于对目标音频合规检测及音频切割,第二个识别节点算法模型用于音频降噪、特征提取和生成频谱,第三个识别节点算法模型用于语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果;
109.同时所述边缘计算模块上部署了面部情绪识别的神经网络,用于识别基于摄像头采集的驾驶员面部视频,得到基于视频采集面部“路怒”情绪识别结果;
110.所述中央处理器将对比针对基于语音的“路怒”情绪识别结果与基于视频采集面
部“路怒”情绪识别结果;若存在差异,则将当前存储模块内的算法模型参数、过去一段时间的驾驶员声音数据以及基于语音的“路怒”情绪识别结果通过通信模块上传到云平台;
111.具体的,过去一段时间指当前存在差异,该输入的驾驶员声音数据以及之前所有存储在存储模块内的驾驶员声音数据。
112.所述云平台基于通信模块上传的数据对各个算法模型进行重新训练,更新算法模型的参数;向车载端的边缘计算模块和存储模块发送更新的算法模型参数;存储模块和边缘计算模块的算法模型参数更新;同时存储模块将已上传数据进行删除。
113.中央处理器实时启动存储介质容量检测任务;当车载存储设备的存储容量达到80%时,删除采集原始数据记录。
114.车载端向云平台传递数据包含当前运行模型参数,目标音频,针对语音识别结果。
115.云平台基于语音识别的“路怒”情绪判断算法进行算法参数的更新。
116.本发明涉及语音识别的“路怒”情绪判断方法中算法参数更新方法,基于视频采集面部“路怒”情绪识别算法判断结果与基于“语音”识别的“路怒”情绪判断结果不同时,将语音数据及算法数据从车载端上传至云端进行算法更新后,下载至车载端,云边协同,减轻了边缘端的计算压力,随着驾驶员驾车时长的提升,提高了语音识别“路怒”的准确率。
117.上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。