1.本发明涉及电子乐器、方法及程序。
背景技术:
2.近年来,合成声音的使用场景增多。其中,如果有不仅是自动演奏、还能够对应于用户(演奏者)的按键使歌词行进、来输出与歌词对应的合成声音的电子乐器,则能够进行更灵活的合成声音的表现从而是优选的。
3.由专用控制器操作有关演奏的乐句(例如歌词)行进从用户操作的观点看门槛较高,难以轻松地欣赏使用了合成声音的歌词的发音。
技术实现要素:
4.本发明的目的之一在于,提供能够适当地控制有关演奏的乐句(例如歌词)行进的电子乐器、方法及程序。
5.本发明的一技术方案的电子乐器,具备:多个键,包括对应于第1音域的多个第1键和对应于第2音域的多个第2键;以及至少1个处理器;上述至少1个处理器,在包含在上述第1音域中的键的操作持续的情况下,进行控制以使得不论包含在上述第2音域中的键怎样被操作、发音的音节都不行进;上述至少1个处理器,在包含在上述第1音域中的哪个键都没有被操作的情况下,进行控制以使得每当操作包含在上述第2音域中的键、发音的音节就行进。
附图说明
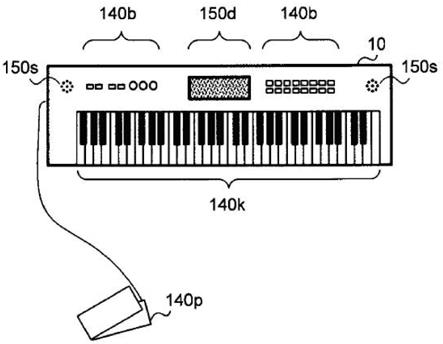
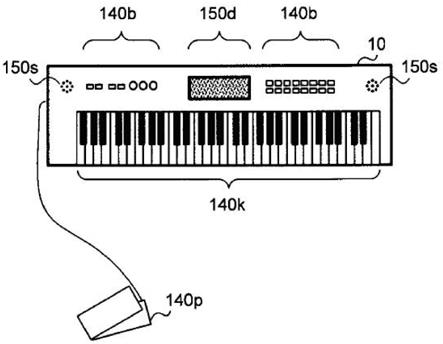
6.图1是表示一实施方式的电子乐器10的外观的一例的图。
7.图2是表示一实施方式的电子乐器10的控制系统200的硬件结构的一例的图。
8.图3是表示一实施方式的声音学习部301的结构例的图。
9.图4是表示一实施方式的波形数据输出部211的一例的图。
10.图5是表示一实施方式的波形数据输出部211的另一例的图。
11.图6是表示一实施方式的用于音节位置控制的键盘的键域划分的一例的图。
12.图7a~图7c是表示被分配给控制键域的音节的一例的图。
13.图8是表示一实施方式的歌词行进控制方法的流程图的一例的图。
14.图9是表示一实施方式的音节位置控制处理的流程图的一例的图。
15.图10是表示一实施方式的演奏控制处理的流程图的一例的图。
16.图11是表示一实施方式的音节行进判别处理的流程图的一例的图。
17.图12是表示一实施方式的音节变更处理的流程图的一例的图。
18.图13a及图13b是表示控制键域的键的外观的一例的图。
19.图14是表示一实施方式的实施歌词行进控制方法的平板终端的一例的图。
display)所连接的lcd控制器208分别与系统总线209连接。
36.也可以对cpu201连接用来控制演奏的定时器210(也可以称作计数器)。定时器210例如可以用于将电子乐器10的自动演奏的行进计数。cpu201也可以称作处理器,可以包括与周边电路的接口、控制电路、运算电路、寄存器等。
37.cpu201一边使用ram203作为工作存储器一边执行存储在rom202中的控制程序,从而执行图1的电子乐器10的控制动作。此外,rom202除了上述控制程序及各种固定数据以外可以还存储歌声数据、伴奏数据、包含它们的曲(song)数据等。
38.波形数据输出部211可以包括音源lsi(大规模集成电路)204、声音合成lsi205等。音源lsi204和声音合成lsi205也可以合并到1个lsi中。关于波形数据输出部211的具体的框图在图3中后述。另外,波形数据输出部211的处理的一部分可以由cpu201进行,也可以由波形数据输出部211中包含的cpu进行。
39.从波形数据输出部211输出的歌声波形数据217及歌曲波形数据218分别被d/a变换器212及213变换为模拟歌声声音输出信号及模拟乐音输出信号。可以是,模拟乐音输出信号及模拟歌声声音输出信号被混音器214混合,该混合信号被放大器215放大后,从扬声器150s或输出端子输出。另外,也可以将歌声波形数据称作歌声合成数据。虽然没有图示,但也可以在将歌声波形数据217及歌曲波形数据218数字合成之后,用d/a变换器变换为模拟值而得到混合信号。
40.键扫描器(scanner)206始终扫描图1的键盘140k的按键/放键状态、开关面板140b的开关操作状态、踏板140p的踏板操作状态等,对cpu201施加中断而传达状态变化。
41.lcd控制器208是控制作为显示器150d的一例的lcd的显示状态的ic(集成电路)。
42.另外,该系统结构是一例,并不限于此。例如,所包含的各电路的数量并不限于此。电子乐器10也可以具有不包括一部分电路(机构)的结构,也可以具有由多个电路实现1个电路的功能的结构。也可以具有由1个电路实现多个电路的功能的结构。
43.此外,电子乐器10也可以包括微处理器、数字信号处理器(dsp:digital signal processor)、asic(application specific integrated circuit)、pld(programmable logic device)、fpga(field programmable gate array)等硬件而构成,也可以由该硬件实现各功能块的一部分或全部。例如,cpu201也可以通过这些硬件的至少1个来安装。
44.《声学模型的生成》
45.图3是表示一实施方式的声音学习部301的结构的一例的图。声音学习部301可以作为与图1的电子乐器10独立地存在于外部的服务器计算机300所执行的一个功能来安装。另外,声音学习部301也可以作为cpu201、声音合成lsi205等所执行的一个功能内置在电子乐器10中。
46.本发明的实现声音合成的声音学习部301及波形数据输出部211分别也可以基于例如基于深层学习的统计性声音合成技术来安装。
47.声音学习部301可以包括学习用文本解析部303、学习用声学特征量提取部304和模型学习部305。
48.在声音学习部301中,作为学习用歌声声音数据312,例如使用将某个歌手歌唱适当体裁(genre)的多个歌曲的声音进行录音而得到的数据。此外,作为学习用歌声数据311而准备了各歌曲的歌词文本。
49.学习用文本解析部303输入包括歌词文本的学习用歌声数据311并解析该数据。结果,学习用文本解析部303推定并输出作为表现与学习用歌声数据311对应的音素、音高等的离散数值序列的学习用语言特征量序列313。
50.学习用声学特征量提取部304,与上述学习用歌声数据311的输入匹配地,输入并分析通过由某个歌手歌唱与该学习用歌声数据311对应的歌词文本从而经由麦克风等收录的学习用歌声声音数据312。结果,学习用声学特征量提取部304提取表示与学习用歌声声音数据312对应的声音的特征的学习用声学特征量序列314并输出。
51.在本发明中,学习用声学特征量序列314、后述的声学特征量序列317所对应的声学特征量序列包括将人的声道模型化后的声学特征量数据(也可以称作共振峰(formant)信息、波谱信息等)、和将人的声带模型化后的声带音源数据(也可以称作音源信息)。作为波谱信息,例如能够采用梅尔倒谱(mel cepstrum)、线谱对(lsp:line spectral pairs)等。作为音源信息,能够采用表示人的声音的音调频率(pitch frequency)的基频(f0)及功率值。
52.模型学习部305通过机器学习,推定从学习用语言特征量序列313生成学习用声学特征量序列314的概率最大的声学模型。即,作为文本的语言特征量序列与作为声音的声学特征量序列之间的关系通过称作声学模型的统计模型来表现。模型学习部305将表现进行机器学习而计算出的声学模型的模型参数作为学习结果315输出。因而,该声学模型相当于已学习模型。
53.作为由学习结果315(模型参数)表现的声学模型,可以使用hmm(hidden markov model:隐马尔可夫模型)。
54.当某个歌唱者唱出遵循某个旋律的歌词时,声带的振动、声道特性的歌声的特征参数一边进行怎样的时间变化一边被发音可以通过hmm声学模型来学习。更具体地讲,hmm声学模型可以是将根据学习用的歌声数据求出的波谱、基频及它们的时间构造以音素单位进行模型化而得到的。
55.首先,对采用hmm声学模型的图3的声音学习部301的处理进行说明。声音学习部301内的模型学习部305可以通过将学习用文本解析部303输出的学习用语言特征量序列313、和学习用声学特征量提取部304输出的上述学习用声学特征量序列314输入,来进行似然度(likelihood)为最大的hmm声学模型的学习。
56.歌声声音的波谱参数能够通过连续hmm而模型化。另一方面,由于对数基频(f0)是在有声区间中取连续值、在无声区间中不具有值的可变维度的时间序列信号,所以无法用通常的连续hmm或离散hmm直接模型化。因此,使用基于与可变维度对应的多空间上的概率分布的hmm即msd-hmm(multi-space probability distribution hmm),作为波谱参数,同时将梅尔倒谱作为多维高斯分布、将对数基频(f0)的有声音(voiced sound)作为一维空间、将无声音(unvoiced sound)作为零维空间的高斯分布来模型化。
57.此外,关于构成歌声的音素的特征,已知的是即使是声学特征相同的音素,也受到各种各样的因素的影响而变动。例如,基本的音韵单位即音素的波谱及对数基频(f0)根据歌唱风格及拍子、或者前后的歌词及音高等而不同。将这样的对声学特征量带来影响的因素称作前后关系(context)。
58.在一实施方式的统计性声音合成处理中,为了将声音的声学特征以良好的精度进
行模型化,可以采用考虑到前后关系的hmm声学模型(前后关系依存模型)。具体而言,学习用文本解析部303可以输出不仅考虑到每帧的音素、音高而且还考虑到紧前、紧后的音素、当前位置、紧前、紧后的颤音、重音(accent)等的学习用语言特征量序列313。进而,为了前后关系的组合的高效化,可以使用基于决策树(decision tree)的前后关系聚类(context clustering)。
59.例如,模型学习部305可以根据与学习用文本解析部303从学习用歌声数据311提取出的状态持续长度(state continuation length)相关的多个音素的前后关系所对应的学习用语言特征量序列313,生成用来决定状态持续长度的状态持续长度决策树作为学习结果315。
60.此外,模型学习部305例如也可以根据学习用声学特征量提取部304从学习用歌声声音数据312提取出的梅尔倒谱参数相关的多个音素所对应的学习用声学特征量序列314,生成用来决定梅尔倒谱参数的梅尔倒谱参数决策树作为学习结果315。
61.此外,模型学习部305例如也可以根据学习用声学特征量提取部304从学习用歌声声音数据312提取出的对数基频(f0)相关的多个音素所对应的学习用声学特征量序列314,生成用来决定对数基频(f0)的对数基频决策树作为学习结果315。另外,也可以将对数基频(f0)的有声区间和无声区间分别通过对应于可变维度的msd-hmm作为一维及零维的高斯分布来模型化,生成对数基频决策树。
62.另外,也可以代替基于hmm的声学模型或与其一起,采用基于深度神经网络(dnn:deep neural network)的声学模型。该情况下,模型学习部305也可以生成表示从语言特征量向声学特征量的dnn内的各神经元的非线性变换函数的模型参数作为学习结果315。通过dnn,能够使用难以用决策树表现的复杂非线性变换函数来表现语言特征量序列与声学特征量序列的关系。
63.此外,本发明的声学模型并不限于这些,例如也可以是将hmm与dnn组合的声学模型等,只要是利用了统计性声音合成处理的技术,则采用怎样的声音合成方式都可以。
64.学习结果315(模型参数)例如可以如图3所示那样,在图1的电子乐器10从工厂出货时被存储到图2的电子乐器10的控制系统的rom202中,在电子乐器10的电源接通时被从图2的rom202载入到波形数据输出部211内的后述的歌声控制部307等中。
65.学习结果315例如可以如图3所示那样,通过由演奏者操作电子乐器10的开关面板140b,经由网络接口219被从因特网等外部下载到波形数据输出部211内的歌声控制部307中。
66.《基于声学模型的声音合成》
67.图4是表示一实施方式的波形数据输出部211的一例的图。
68.波形数据输出部211包括处理部(也可以称作文本处理部、前处理部等)306、歌声控制部(也可以称作声学模型部)307、音源308、歌声合成部(也可以称作发音模型部)309等。
69.波形数据输出部211通过输入基于图1的键盘140k(演奏操作件)的按键且经由图2的键扫描器206从cpu201指示的、包含歌词及音高的信息的歌声数据215和歌词控制数据,合成并输出与该歌词及音高对应的歌声波形数据217。换言之,波形数据输出部211执行以下统计性声音合成处理:使用在歌声控制部307中设定的声学模型这样的统计模型进行预
测,从而合成与包含歌词文本的歌声数据215对应的歌声波形数据217。
70.此外,波形数据输出部211在歌曲数据的再现时,输出与对应的歌曲再现位置对应的歌曲波形数据218。这里,歌曲数据可以对应于伴奏的数据(例如,关于1个以上的音的音高、音色、发音定时等数据)、伴奏及旋律的数据,也可以称作回溯(backtrack)数据等。
71.处理部306,例如作为演奏者的演奏(操作)的结果,输入包含与由图2的cpu201指定的歌词的音素、音高等有关的信息的歌声数据215,并将该数据解析。歌声数据215例如可以包括第n个音符(也可以称作第n音符、第n定时等)的数据(例如,音高数据、音符长数据)、与第n音符对应的第n歌词(或音节)的数据、第n音节的数据等的至少1个。
72.例如,处理部306也可以基于从键盘140k、踏板140p的操作取得的音符开启/关闭(note on/off)数据、踏板开启/关闭(pedal on/off)数据等,基于后述的歌词行进控制方法判定歌词行进的有无,取得与应输出的音节(歌词)对应的歌声数据215。并且,处理部306也可以将与通过按键指定的音高数据或所取得的歌声数据215的音高数据、和所取得的歌声数据215的字符数据相对应的表现音素、词类(part)、单词(word)等的语言特征量序列316进行解析,并向歌声控制部307输出。
73.歌声数据215可以是包含歌词(的字符)、音节的类型(开始音节、中间音节、结束音节等)、对应的声高(正确的声高)和各音节的歌词(字符串)中的至少1个的信息。歌声数据215也可以包含与第n(n=1、2、3、4,
…
)音节对应的第n音节的歌声数据的信息。
74.歌声数据215也可以包含用来演奏与该歌词对应的伴奏(歌曲数据)的信息(特定的声音文件格式的数据、midi数据等)。在将歌声数据用smf格式表示的情况下,歌声数据215也可以包含保存关于歌声的数据的音轨块(track chunk)和保存关于伴奏的数据的音轨块。也可以将歌声数据215从rom202读入到ram203中。歌声数据215在演奏前被存储在存储器(例如,rom202、ram203)中。
75.歌词控制数据可以如关于图12后述的那样,用于与音节对应的歌声再现信息的设定。波形数据输出部211能够基于歌声再现信息对发音的定时进行控制。例如,处理部306可以基于歌声再现信息所表示的音节开始帧,调整向歌声控制部307输出的语言特征量序列316(例如,也可以不输出比音节开始帧靠前的帧)。
76.歌声控制部307基于从处理部306输入的语言特征量序列316和作为学习结果315而被设定的声学模型,推定与其对应的声学特征量序列317,将与推定出的声学特征量序列317对应的共振峰信息318对歌声合成部309输出。
77.例如,在采用hmm声学模型的情况下,歌声控制部307按照由语言特征量序列316得到的每个前后关系,参照决策树,将hmm连结,根据连结后的各hmm,预测输出概率最大的声学特征量序列317(共振峰信息318和声带音源数据319)。
78.在采用dnn声学模型的情况下,歌声控制部307也可以对以帧单位输入的语言特征量序列316的音素列,以上述帧单位输出声学特征量序列317。另外,本发明的帧例如可以是5ms、10ms等。
79.在图4中,处理部306从存储器(既可以是rom202,也可以是ram203)取得与被按键的音的音高对应的乐器音数据(音调信息),向音源308输出。
80.音源308基于从处理部306输入的音符开启/关闭数据,生成与应发音的(音符开启的)音对应的乐器音数据(音调信息)的音源信号(也可以称作乐器音波形数据),向歌声合
成部309输出。音源308也可以执行所发出的音的包络控制(envelope control)等控制处理。
81.歌声合成部309形成基于从歌声控制部307依次输入的共振峰信息318的序列而将声道进行模型化的数字滤波器。此外,歌声合成部309将从音源308输入的音源信号作为激励源信号,应用该数字滤波器,生成数字信号的歌声波形数据217并输出。该情况下,歌声合成部309也可以称作合成滤波器部。
82.另外,歌声合成部309能够采用以倒谱声音合成方式、lsp声音合成方式为代表的各种各样的声音合成方式。
83.在图4的例子中,输出的歌声波形数据217由于以乐器音为音源信号,所以虽然与歌手的歌声相比稍稍失去忠实性,但是成为该乐器音的氛围和歌手的歌声的音质的两者都良好地保留的歌声,能够输出有效的歌声波形数据217。
84.另外,音源308也可以如以下这样动作,即:与乐器音波形数据的处理一起,将其他声道的输出作为歌曲波形数据218输出。由此,也能够实现如下那样的动作,即:使伴奏音以通常的乐器音发音、或在使旋律线(melody line)的乐器音发音的同时发出该旋律的歌声。
85.图5是表示一实施方式的波形数据输出部211的另一例的图。关于与图4重复的内容不反复说明。
86.图5的歌声控制部307如上述那样,基于声学模型来推定声学特征量序列317。并且,歌声控制部307将与推定出的声学特征量序列317对应的共振峰信息318以及与推定出的声学特征量序列317对应的声带音源数据(音调信息)319对歌声合成部309输出。歌声控制部307可以推定使生成声学特征量序列317的概率最大那样的声学特征量序列317的推定值。
87.例如也可以是,歌声合成部309生成用来基于共振峰信息318的序列对从歌声控制部307输入的声带音源数据319中包含的以基频(f0)及功率值周期性地反复的脉冲列(有声音(voiced sound)音素的情况)、或声带音源数据319中包含的具有功率值的白噪声(无声音(unvoiced sound)音素的情况)、或混合了它们的信号应用了将声道模型化的数字滤波器而得到的信号的数据(例如,也可以称作与第n音符对应的第n歌词的歌声波形数据),向音源308输出。
88.音源308基于从处理部306输入的音符开启/关闭数据,从与应发音的(音符开启的)音对应的上述第n歌词的歌声波形数据,生成数字信号的歌声波形数据217并输出。
89.在图5的例子中,输出的歌声波形数据217由于以音源308基于声带音源数据319生成的音为音源信号,所以是被歌声控制部307完全模型化了的信号,能够输出非常忠实于歌手的歌声且歌声自然的歌声波形数据217。
90.这样,本发明的声音合成不同于现有的声音合成器(vocoder)(将人讲的词语用麦克风输入、替换为乐器音而合成的方法),即使用户(演奏者)不实际唱歌(换言之,即使不对电子乐器10输入用户实时地发出的声音信号),也能够通过键盘的操作来输出合成声音。
91.如以上说明,,作为声音合成方式,采用统计性声音合成处理的技术,从而以往的片段合成方式相比,能够实现显著少的存储器容量。例如,在片段合成方式的电子乐器中,为了声音片段数据而需要具有达到几百兆字节的存储容量的存储器,而在本实施方式中,为了存储学习结果315的模型参数,仅采用具有几兆字节的存储容量的存储器即可。因此,
能够实现更低价格的电子乐器,能够使更广泛的用户层使用高音质的歌声演奏系统。
92.进而,在以往的片段数据方式中,需要人工调整片段数据,所以在用于歌声演奏的数据的制作中需要大量的时间(以年为单位)和劳动,而在本实施方式的用于hmm声学模型或dnn声学模型的学习结果315的模型参数的制作中,由于几乎不需要数据的调整,所以制作时间和劳动仅为几分之一即可。由此也能够实现更低价格的电子乐器。
93.此外,还能够使一般用户利用能够用作云服务的服务器计算机300、声音合成lsi205等中内置的学习功能来学习自己的声音、亲人的声音或名人的声音等,并将其作为模型声音用电子乐器进行歌声演奏。该情况下,也能够作为更低价格的电子乐器实现比以往显著自然且高音质的歌声演奏。
94.(歌词行进控制方法)
95.以下对本发明的一实施方式的歌词行进控制方法进行说明。另外,本发明的歌词行进控制也可以改称为演奏控制、演奏等。
96.以下的各流程图的动作主体(电子乐器10)也可以改称为cpu201、波形数据输出部211(或其内部的音源lsi204、声音合成lsi205(处理部306、歌声控制部307、音源308、歌声合成部309等))的某个或它们的组合。例如,也可以由cpu201执行从rom202载入到ram203中的控制处理程序,实施各动作。
97.另外,在以下所示的流程的开始时,可以进行初始化处理。该初始化处理可以包括中断处理、成为歌词的行进、自动伴奏等的基准时间的ticktime的导出、拍子设定、歌曲的选曲、歌曲的读入、乐器音的选择、其他与按钮等关联的处理等。
98.cpu201能够以适当的定时,基于来自键扫描器206的中断,检测开关面板140b、键盘140k及踏板140p等的操作,实施对应的处理。
99.另外,以下表示控制歌词的行进的例子,但行进控制的对象并不限于此。基于本发明,例如也可以代替歌词而控制任意的字符串、文章(例如,新闻稿)等的行进。即,本发明的歌词也可以改称为字符、字符串等。
100.首先,对本发明的歌词(也可以称作乐句等)的音节位置的控制方法的概要进行说明。根据该控制方法,能够使用键盘迅速且直观地进行歌词控制。另外,在本发明中,假设“音节”例如如“go”、“for”、“it”等那样表示1个单词(或1个字符)、“歌词”或“乐句”例如如“go for it”那样表示由多个音节或多个单词(或多个字符)构成的词句(或文章)来进行说明,但它们的定义也可以不同。
101.此外,在本发明中,音节位置可以由特定的索引(例如称作音节索引)表示。音节索引可以是表示与歌词中包含的音节之中的从开头起第几音节(或第几字符)的音节(或字符)对应的变量。在本发明中,音节位置及音节索引也可以相互改称。
102.在本发明中,与1个音节索引对应的歌词可以与构成1个音节的1个或多个字符对应。音节可以包括仅元音、仅辅音、辅音及元音等各种音节。
103.图6是表示一实施方式的用于音节位置控制的键盘的键域划分的一例的图。在本例中,键盘140k被划分为第1键域(第1音域)及第2键域(第2音域)。即,键盘140k具备包括对应于第1音域的多个第1键和对应于第2音域的多个第2键的多个键。另外,在本例中表示了键盘140k的键数为61的例子,但在其他键数的情况下也能够同样地应用本发明的实施方式。
104.另外,在本发明中,键域也可以与键盘的区域(或范围)、演奏操作件的区域(或范围)、音域、音的区域(或范围))等相互改称。
105.第1键域也可以称作音节位置控制键域、键盘控制键域、控制键域等,用于指定音节位置。换言之,控制键域可以不用于演奏的音高、音的力度、长度等的指定。
106.作为一例,控制键域可以与和弦发音用的键的键域(例如,c1-f2)对应。控制键域中,用于音节位置的控制的键既可以仅由白键构成,也可以仅由黑键构成,也可以由它们两者构成。例如,在音节位置的控制中仅使用白键的情况下,控制键域内的黑键可以用于歌词的控制(例如,某个曲子的向之后/之前的歌词的转移等)。
107.第2键域也可以称作键盘演奏键域、演奏键域等,用于指定音高、音的力度、长度等。电子乐器10使用通过演奏键域的操作而指定的音高(音程)、力度等,发出与通过控制键域的操作而指定的音节位置(或歌词)对应的音。
108.另外,在图6中,表示了控制键域由左手侧的几个键构成、演奏键域由不与控制键域对应的键构成的例子,但并不限于此。例如,各键域也可以由不相邻的(分散的)键构成,也可以是,控制键域由右手侧的键构成,演奏键域由左手侧的键构成。
109.图7a~图7c是表示分配给控制键域的音节的一例的图。图7a表示作为用控制键域控制音节位置的对象的歌词的一例。表示了
“まばたきしてはみんなを”
的歌词。音高及音的长度作为例子,实际输出的音能够由演奏键域控制。
110.图7b表示将图7a的歌词的各音节分配给控制键域内的白键的例子。在本例中,对于控制键域内的c1-f2共计11个白键,分别各映射了上述歌词的1个音节。
111.电子乐器10,如果控制键域内的某个白键被按键,则将音节位置设定在与该白键对应的位置(例如,如果该白键是g1,则设定为
“し”
)。电子乐器10,如果c1被按键,则不论现状的音节位置如何,都将歌词起头(使音节位置为
“ま”
)。
112.电子乐器10,在控制键域内的键没有被按下的状态下,如果演奏键域内的任意的键被按键,则将音节位置移位1个(移动到下个)(例如,如果按键前的位置是
“ま”
,则移位至
“ば”
)。另外,在音节位置到达歌词的末尾的情况下,音节位置既可以被变更为该歌词的开头的位置(图7b中为
“ま”
),也可以被变更为该歌词的接下来的歌词的开头的位置。
113.电子乐器10,在控制键域内的某个白键被按键的状态下,即使演奏键域内的任意的键被按键多次,也保持与该白键对应的位置不变地维持音节位置(例如,如果对应于该白键的位置是
“し”
,则每当演奏键域按键时发音出
“し”
)。
114.电子乐器10,也可以在控制键域内的某个白键被按键时,在演奏键域内的键已经被按键的情况下,将对应于该白键的音节基于演奏键域内的被按键的键而发音。例如,可以是,在演奏键域内的键被按键的情况下,如果在控制键域中以c2
→
d1
→
e1的顺序按键,则电子乐器10以与该演奏键域内的键对应的音高使
“みばた”
发音。通过该动作,能够使与控制键域对应的歌词的音节以任意的顺序(自由地制作字母异位词(anagram))发音。
115.图7c表示将其他歌词(英文歌词)的各音节分配给控制键域内的白键的例子。在本例中,对于控制键域内的c1-f2共计11个白键,分别映射了歌词“holy infant so tender and mild sleep in”的各音节。这样,可以分配任意的语言的音节。
116.对于1个键,既可以如图7b、7c所示那样分配1个字符/1个音节,也可以分配多个字符/多个音节。
117.歌词及音节的相关数据也可以与上述的歌声数据215(也可以称作歌词数据、音节数据等)对应。例如,电子乐器10可以在存储器内存储多个歌词数据,如果进行了特定的功能键(例如,按钮、开关等)的操作则选择1个歌词数据。
118.《歌词行进控制》
119.图8是表示一实施方式的歌词行进控制方法的流程图的一例的图。
120.首先,电子乐器10,作为初始值而将音节位置控制标志置位为“无效”(步骤s101)。
121.电子乐器10判断是否需要音节的分配(步骤s102)。电子乐器10例如可以在进行了电子乐器10的特定的功能键(例如,按钮、开关等)的操作(并且,载入了歌词等)的情况下,判断为需要音节的分配。
122.在需要音节的分配的情况下(步骤s102的“是”),电子乐器10对于控制键域(的白键)进行音节的分配处理(步骤s103),将音节位置控制标志置位为“有效”(步骤s104)。被分配的音节可以如上述那样从多个歌词数据中选择1个。音节位置控制标志“有效”也可以称作键盘划分有效。
123.在不需要音节的分配的情况下(步骤s102的“否”),控制键域不被设定,全部的键被用于音高指定(通常的演奏模式)。音节位置控制标志“无效”也可以称作键盘划分无效。
124.在步骤s104或步骤s102的“否”之后,电子乐器10判断是否有任意的键盘操作(步骤s105)。在有键盘操作的情况下(步骤s105的“是”),电子乐器10取得被按键了/正在被按键的键、被放键了/正在被放键的键等的信息(也可以称作按键/放键信息)(步骤s106)。
125.在步骤s106之后,电子乐器10确认上述的音节位置控制标志是否为有效(步骤s107)。在音节位置控制标志为有效的情况下(步骤s107的“是”),进行音节位置控制处理(步骤s108)。否则(步骤s107的“否”),电子乐器10进行演奏控制处理(步骤s109)。音节位置控制处理在图9中后述,演奏控制处理在图10中后述。
126.在步骤s108或步骤s109之后,电子乐器10判断歌词的再现是否已结束(步骤s110)。在已结束的情况下(步骤s110的“是”),电子乐器10可以将该流程图的处理结束,回到待机状态。否则(步骤s110的“否”),可以回到步骤s102或步骤s105。这里的“歌词的再现是否已结束”既可以关于一个乐句的歌词的再现,也可以关于曲整体的歌词的再现。
127.《音节位置控制》
128.图9是表示一实施方式的音节位置控制处理的流程图的一例的图。
129.电子乐器10判断是否有控制键域中的按键/放键操作(步骤s201)。在有控制键域中的操作的情况下(步骤s201的“是”),判断该操作是否是按键操作(步骤s202)。
130.在有按键操作的情况下(步骤s202的“是”),电子乐器10将通过该按键操作而被按键的键(key)的信息作为音节控制键进行保存(或存储或设定)(步骤s203)。此外,电子乐器10将放键标志复位(或不设定)(步骤s204)。另外,放键标志在控制键域的任意的键被按键的情况下被复位(reset),否则被置位(set)。
131.另一方面,在有放键操作的情况下(步骤s202的“否”),电子乐器10判断通过该放键操作而被放键的键的信息是否与保存的音节控制键相同(步骤s205)。
132.在被放键的键的信息与保存的音节控制键相同的情况下(步骤s205的“是”),将放键标志置位(步骤s206)。另外,在尽管被放键的键的信息与保存的音节控制键相同、但在控制键域中还有按键中的键的情况下,电子乐器10可以将该按键中的键的信息作为音节控制
键来保存,该情况下可以不将放键标志置位。
133.另一方面,在没有控制键域中的操作的情况下(步骤s201的“否”),电子乐器10进行演奏控制处理(步骤s207)。步骤s207的演奏控制处理可以与步骤s109的演奏控制处理相同。
134.在步骤s204、步骤s206、步骤s205的“否”或步骤s207之后,电子乐器10可以结束音节位置控制处理。
135.另外,音节控制键也可以称作音节控制信息,可以是被按键/放键的键的键号(key number)的信息,也可以是被按键/放键的键的音高(或音符号)的信息。以下,在本发明中,以作为音节控制键而保持键号为例进行说明,但并不限于此。
136.另外,例如,图7b及图7c的例子的c1-f2所对应的键可以分别对应于0-11的键号。键号也可以是表示音高的字符串(例如,c1、f2)。
137.根据图9的音节位置控制处理,如果有控制键域中的按键,则该键被保持。如果有控制键域中的放键,则在所保持的键维持的状态下将放键标志置位。所保持的键当控制键域中的别的键被按键则替换为该别的键。另外,可以是,在控制键域的键没有被放键的状态下新的键被按键的情况下,所保持的键被该新键的键覆盖。
138.《演奏控制》
139.图10是表示一实施方式的演奏控制处理的流程图的一例的图。
140.电子乐器10实施音节行进判别处理(步骤s301)。音节行进判别处理返回与是否使音节位置前进有关的判别结果(返回值)。在该判别结果为“是”(或“真”)的情况下,取得当前的音节位置,使该音节位置转移(或移位、前进)1个(换言之,使歌词行进)(步骤s302)。关于音节行进判别处理的一例,在图11中后述。
141.另一方面,在步骤s301的音节行进判别处理的判别结果为“否”(或“假”)的情况下,不变更音节位置。
142.在步骤s302之后,电子乐器10判断音节控制键是否被置位(保存着有效的值)(步骤s303)。在音节控制键被置位的情况下(步骤s303的“是”),电子乐器10判断该音节控制键是否是音节位置指定有效键(也可以简称作有效键)(步骤s304)。
143.这里,有效键可以指控制键域内的全部键中的被分配了音节的键。例如,在当前的歌词中包含的音节数比控制键域内的白键的数量少的情况下,控制键域内的一部分白键对应于有效键,其余不对应于有效键。此外,该情况下,黑键也不对应于有效键。
144.由此可知,如果歌词变化,则哪个键成为有效键也会变化。另外,不需要1个键与1个音节1对1地对应,也可以1个键与多个音节对应,或多个键与1个音节对应。
145.在音节控制键为有效键的情况下(步骤s304的“是”),电子乐器10取得与该音节控制键(的键号)对应的音节位置(步骤s305)。
146.在步骤s305之后,电子乐器10判断放键标志是否被置位(步骤s306)。在放键标志被置位的情况下(步骤s306的“是”),电子乐器10将音节控制键清空(clear)(也可以设置无效的值)(步骤s307)。
147.在步骤s303的“否”、步骤s304的“否”、步骤s306的“否”或步骤s307之后,电子乐器10进行音节变更处理(步骤s308)。关于音节变更处理的一例,在图12中后述。另外,如后述那样,可以在音节变更处理之中进行音节的演奏(再现)处理。
148.另外,也可以是,在音节变更处理之前或之后,电子乐器10将当前的音节位置(在步骤s302或步骤s305中取得的(或取得并前进了1个的)音节位置)作为当前的音节位置存储到存储部中。步骤s302的音节位置的取得可以是所存储的当前的音节位置的取得。此外,也可以代替在步骤s302中使音节位置前进1个,而在步骤s308的音节变更处理之前或之后使音节位置前进1个。
149.在步骤s301的“否”或步骤s308之后,电子乐器10可以结束演奏控制处理。
150.《音节行进判别》
151.图11是表示一实施方式的音节行进判别处理的流程图的一例的图。该处理换言之相当于以下处理:如果在演奏键域中单音被按键则使音节行进,此外,如果在演奏键域中和声被按键,则根据和声中的哪个高度(也可以改称为“第几个高度”“哪个部分”等)的音通过按键而发生了变化,来判定音节行进。
152.电子乐器10取得演奏键域的当前的按键数(步骤s401)。
153.接着,电子乐器10判断演奏键域的当前的按键数是否为2以上(是否有2个音以上的按键)(步骤s402)。在当前的按键数为2以上的情况下(步骤s402的“是”),电子乐器10取得与各按键对应的按键时间和键号(步骤s403)。
154.在步骤s403之后,电子乐器10判断在演奏键域中最新的按键时间与上次的按键时间之差是否在和声判别时间内(步骤s404)。步骤s404例如也可以说是判断新被按键的音的按键时间与上次(或i次前(i为整数))被按键的音的按键时间之差是否在和声判别时间内的步骤。优选的是,该过去的按键时间对应于在最新的按键时间中也继续按键的键。
155.这里,和声判别时间是用来将在该时间内发出的多个音判断为同时和声、将在该时间外发出的多个音判断为独立的音(例如,旋律线的音)或分散和声的时间(期间)。和声判别时间例如可以用毫秒单位、微秒单位表现。
156.和声判别时间既可以通过用户的输入来取得,也可以以曲子的拍子为基准来导出。也可以将和声判别时间称作规定的设定时间、设定时间等。
157.在最新的按键时间与上次的按键时间之差为和声判别时间内的情况下(步骤s404的“是”),电子乐器10判断为被按键的音是同时和声(指定了和声)。并且,判断为维持音节(不使歌词行进),将音节行进判别处理的返回值设定为“否”(或“假”)(步骤s405)。
158.根据步骤s404的判定,在以和声的意图而按下了多个键的情况下,能够对应于不希望音节以键的数量行进这样的情况而使歌词仅行进1个。
159.另一方面,在和声判别时间内没有过去的按键时间的情况下(步骤s404的“否”),判断是否演奏键域的当前的按键数为规定数以上、并且最新的按键音(键)与在演奏键域中被按键的全部音(键)中的特定的音(键)相对应(步骤s406)。另外,电子乐器10在步骤s404为“否”的情况下,既可以判断为和声的指定已被解除,也可以判断为和声没有被指定。
160.另外,该规定数例如可以是2、4、8等。此外,特定的音(键)既可以是被按键的全部音(键)中的最低的音(键),也可以是第i(i为整数)高或低的音(键)。这些规定数、特定的音等既可以通过用户操作等来设定,也可以预先规定。
161.在步骤s406为“是”的情况下,电子乐器10判断为使音节前进(使歌词行进),将音节行进判别处理的返回值设定为“是”(或“真”)(步骤s407)。
162.在步骤s406为“否”的情况下,电子乐器10判断为虽然不是同时和声但维持音节
(不使歌词行进),将音节行进判别处理的返回值设定为“否”(或“假”)(步骤s405)。
163.此外,在步骤s402为“否”的情况下,电子乐器10由于不是同时和声所以判断为使音节前进(使歌词行进),将音节行进判别处理的返回值设定为“是”(或“真”)(步骤s407)。
164.根据图11那样的音节行进判定处理,例如,如果不是发音的时间差较小的多个音(所谓的同时和声(harmony)),而是发音的时间差较大的多个音(旋律(melody)),则能够使音节行进。
165.《音节变更》
166.图12是表示一实施方式的音节变更处理的流程图的一例的图。
167.电子乐器10取得在演奏控制处理中已经取得的音节位置所对应的歌词控制数据(步骤s501)。
168.这里,歌词控制数据可以是包含关于歌词中包含的各个音节的发音(歌声合成)的参数的数据。如果将包含关于某个音节的发音的参数的数据称作音节控制数据,则歌词控制数据可以包括1个以上的音节控制数据。
169.例如,音节控制数据可以包含发音定时、音节开始帧、元音开始帧、元音结束帧、音节结束帧、歌词(或音节)(的字符信息)等信息。另外,帧可以是上述音素(音素列)的构成单位,也可以改称为其他时间单位。以下,将歌词控制数据及音节控制数据不特别区别而进行说明。
170.发音定时可以表示成为各帧(例如,音节开始帧、元音开始帧等)的基准的定时(或偏移(offset))。该发音定时可以用从按键起的时间给出。发音定时及各帧的信息也可以用帧数(帧单位)指定。
171.与音节对应的音可以从音节开始帧开始发音,在音节结束帧结束发音。音节中的对应于元音的音可以从元音开始帧开始发音,在元音结束帧结束发音。即,通常,元音开始帧具有音节开始帧以上的值,元音结束帧具有音节结束帧以下的值。
172.音节开始帧可以与音节的帧的开头地址信息对应。音节结束帧可以与音节的帧的最终地址信息对应。
173.接着,电子乐器10判断是否需要调整在步骤s501中取得的歌词控制数据的音节开始帧(步骤s502)。例如,可以在帧位置调整标志设立(被置位)的情况下,电子乐器10判断为需要调整音节开始帧。电子乐器10既可以基于功能键的操作来控制帧位置调整标志的值,也可以基于歌词控制数据的参数来决定帧位置调整标志的值。
174.在需要调整音节开始帧的情况下(步骤s502的“是”),电子乐器10基于调节系数调整音节开始帧(步骤s503)。电子乐器10例如可以计算对音节开始帧应用了利用调节系数的规定的运算(例如,加法、减法、乘法、除法)而得到的值,作为新的(已调整的)音节开始帧。
175.调整系数可以是适合于减少(或去除)音节的白噪声部分的参数(例如,偏移量、帧数等)。调节系数可以具有按每个音节而不同(或独立)的值。调节系数既可以包含在歌词控制数据中,也可以基于歌词控制数据来决定。
176.另外,步骤s503的音节开始帧的调整既可以仅应用于在控制键域的按键中发音的音,也可以应用于在控制键域没有被按键时发音的音。
177.在步骤s503之后,电子乐器10判断已调整的音节开始帧的值是否比元音开始帧的值大(步骤s504)。在已调整的音节开始帧的值比元音开始帧的值大的情况下(步骤s504的“是”),电子乐器10将已调整的音节开始帧的值变更为元音开始帧的值(步骤s505)。
178.根据步骤s504及s505,例如,能够一边尽可能减小白噪声一边从元音的最初开始发音。如果在元音的中途发音开始,则发音的起音(attack)感变差,而通过从元音的最初开始发音,能够抑制起音感变差。
179.在步骤s502的“否”、步骤s504的“否”或步骤s505之后,电子乐器10将至少包括音节开始帧、元音开始帧、元音结束帧、音节结束帧的信息设定为歌声再现信息(步骤s506)。这里的音节开始帧如上述那样,可以是包含在歌词控制数据中的音节开始帧的值,也可以是使用调整系数调整后的音节开始帧的值,也可以是元音开始帧的值。
180.电子乐器10应用歌声再现处理而发出与当前的音节位置对应的音(步骤s507)。电子乐器10在该歌声再现处理中,可以根据步骤s506的歌声再现信息和在演奏键域中被按键的键(的音高等)发出与当前的音节位置对应的音。
181.在歌声再现处理中,电子乐器10例如也可以通过歌声控制部307取得与当前的音节位置对应的歌声数据的声学特征量数据(共振峰信息),向音源308指示与按键对应的音高的乐器音的发音(乐器音波形数据的生成),向歌声合成部309指示对从音源308输出的乐器音波形数据赋予上述共振峰信息。
182.例如,处理部306将被指定的音高数据(与被按键的键对应的音高数据)及与当前的音节位置对应的歌声数据、和与当前的音节位置对应的歌声再现信息向歌声控制部307输入。歌声控制部307基于输入来推定声学特征量序列317,将对应的共振峰信息318和声带音源数据(音调信息)319对歌声合成部309输出。该声学特征量序列317可以基于歌声再现信息来调整再现开始帧。
183.歌声合成部309基于所输入的共振峰信息318和声带音源数据(音调信息)319,生成歌声波形数据,向音源308输出。并且,音源308对从歌声合成部309取得的歌声波形数据进行发音处理。
184.另外,可以是,电子乐器10在步骤s301的音节行进判别处理的判别结果为“否”(或“假”)的情况下,也基于已经得到的歌声再现信息和在演奏键域中被按键的键,应用歌声再现处理而使与当前的音节位置对应的音发音。
185.《变形例》
186.也可以是,在电子乐器10中,在被分配了控制键域内的音节的键上,显示字符、图形、花纹、图案的至少1个,以使得能够视觉辨识(或区别、掌握、理解)被分配的音节,键(例如,内置于键中的发光元件(发光二极管(led:light emitting diode))等)的颜色、明亮度及色彩度的至少1个可以变化。
187.此外,也可以是,在电子乐器10中,在与当前的音节位置对应的键上,显示与其他键不同的字符、图形、花纹、图案的至少1个,以使得能够视觉辨识(或区别、掌握、理解)是当前的音节位置(换言之使得能够与其他键相区别),也可以显示与其他键不同的键的颜色、明亮度及色彩度的至少1个。
188.图13a及图13b是表示控制键域的键的外观的一例的图。在本例中,
“まばたきしてはみんなを”
的歌词以能够视觉辨识的方式被显示在控制键域内的c1-f2的共计11个白键各自上。
189.此外,在图13a中,c1键的一部分发光(图中的“〇”部分)。在图13b中,d1键的一部
分发光(图中的“〇”部分)。在图13a及图13b中,分别使演奏者容易地理解当前的音节位置是
“ま”
、
“ば”
。
190.另外,在如图13a及图13b那样进行了使得能够理解被分配了音节的键那样的显示的情况下,控制键域的键盘数可以不是固定的,可以根据当前的演奏对象的歌词而改变。例如,这是因为,在歌词的音节数为x(x是整数)的情况下,控制键域只要包括x个白键就足够。该情况下,能够抑制不论选择哪个歌词、演奏键域的键数都总是较少(能够演奏的音高的自由度较少)的状况。
191.在上述的实施方式中,设想了基于特定的功能键(例如,按钮、开关等)的操作来选择歌词数据,但并不限于此。例如,电子乐器10也可以基于控制键域内的没有被分配音节的键(例如黑键)的操作来选择歌词数据。例如,也可以是,控制键域内的最左方的黑键表示一曲中的比当前的歌词靠前1个的歌词的选择,控制键域内的左起第2个黑键表示一曲中的比当前的歌词靠后1个的歌词的选择。
192.电子乐器10也可以进行使显示器150d显示歌词的控制。例如,可以显示当前的歌词的位置(音节索引)附近的歌词,也可以将与发音中的音对应的歌词、与已发音的音对应的歌词等通过着色等方式而显示,以使得能够识别当前的歌词的位置。
193.电子乐器10也可以对外部装置(例如,智能电话、平板终端)发送歌声数据、与当前的歌词的位置有关的信息等的至少1个。该外部装置可以基于接收到的歌声数据、与当前的歌词的位置有关的信息等,进行使自身具有的显示器显示歌词的控制。
194.在上述的例子中,表示了电子乐器10是键盘那样的键盘乐器的例子,但并不限于此。电子乐器10只要是具有能够通过用户的操作来指定发音定时的结构的设备即可,也可以是电小提琴、电吉他、鼓、喇叭等。
195.因此,本发明的“键”也可以改称为弦、管、其他音高指定用的演奏操作件、任意的演奏操作件等。本发明的“按键”也可以改称为打键、拨弹、演奏、操作件的操作、用户操作等。本发明的“放键”也可以改称为弦的停止、静音、演奏停止、操作件的停止(非操作)等。
196.此外,本发明的操作件(例如,演奏操作件、键)也可以是在触摸面板、虚拟键盘等上显示的操作件(键的图像等)。该情况下,电子乐器10并不限于所谓的乐器(键盘等),也可以改称为便携电话、智能电话、平板电脑型终端、个人电脑(pc:personal computer)、电视等。
197.图14是表示实施一实施方式的歌词行进控制方法的平板终端的一例的图。平板终端10t至少将键盘140k显示在显示器上。该键盘140k的一部分(在本例中是c1-f2的共计11个白键)对应于控制键域,
“まばたきしてはみんなを”
的歌词被显示在控制键域内的c1-f2的共计11个白键各自上以便能够视觉辨识。
198.此外,也可以是,接收到上述的歌声数据、与当前的歌词的位置有关的信息等的外部装置也显示图14所示那样的被分配的音节、表示当前的音节位置的键盘140k等。
199.如以上说明,本发明的电子乐器10能够提供新的演奏体验,能够使用户(演奏者)更享受演奏。
200.例如,本发明的电子乐器10能够容易地进行歌词的起头。由于在视觉上知道音节的位置,所以能够在歌词演奏中直接地适当跳跃到任意的音节。
201.此外,本发明的电子乐器10,在歌词演奏中想要在特定的音节位置保持音节(元
音)的情况下,能够仅用键盘直接地指定、维持任意的元音。即使不使用踏板及按钮,也能够进行拖音(melisma)演奏。
202.此外,本发明的电子乐器10能够根据键盘的操作而随机地改变音节位置,能够一边变更音节的组合一边进行演奏。因此,不仅是本来的歌词,还能够如字母异位词那样制作其他歌词。例如,如果与循环演奏或琶音器(arpeggiator)等的自动演奏组合,则能够提供生成超出用户预想的歌词乐句的新的演奏体验。
203.另外,电子乐器10可以具备与相互不同的音高数据分别建立了对应的多个演奏操作件(例如键)和处理器(例如cpu)。上述处理器可以基于向上述多个演奏操作件中的、第1音域(控制键域)中包含的演奏操作件的操作(例如,按键/放键),来决定包含在乐句中的音节位置。此外,上述处理器也可以基于向上述多个演奏操作件中的、第2音域(演奏键域)中包含的演奏操作件的操作,来指示与所决定的上述音节位置对应的音节的发音。根据这样的结构,例如仅使用键盘就能够容易地指定用户想要发音的歌词的部位。
204.此外,上述处理器也可以在包含在上述第1音域中的演奏操作件被操作了的情况下,基于与被操作的包含在上述第1音域中的演奏操作件对应的键号,来决定上述音节位置。根据这样的结构,能够通过第1音域的按键直观地变更为任意的音节。
205.此外,上述处理器也可以在包含在上述第1音域中的演奏操作件被操作且被操作的包含在上述第1音域中的演奏操作件是被分配了音节的有效键的情况下,基于与被操作的包含在上述第1音域中的演奏操作件对应的键号,来决定上述音节位置。根据这样的结构,能够通过第1音域中的分配了音节的键的操作,直观地变更为任意的音节。关于没有被分配音节的键,能够用于音节变更之外的用途。
206.此外,上述处理器也可以在包含在上述第1音域中的演奏操作件没有被操作的情况下,基于包含在上述第2音域中的演奏操作件的操作,使上述音节位置转移1个。根据这样的结构,能够进行基本上仅通过第2音域的操作使音节前进、仅在需要的情况下对第1音域进行操作而进行音节的跳跃这样的对用户友好的动作。
207.此外,上述处理器也可以指示将与上述音节位置对应的音节的音节开始帧基于调节系数调整后的发音。根据这样的结构,能够适当地减少(或去除)音节的白噪声部分。
208.此外,上述处理器也可以在基于上述调节系数调整后的音节开始帧的值比上述音节的元音开始帧的值大的情况下,使调整后的音节开始帧的值与上述元音的开始帧的值相同。根据这样的结构,能够在尽可能减少白噪声的同时抑制起音感的变差。
209.此外,也可以是,上述处理器,在向上述多个演奏操作件中的、第1音域中包含的演奏操作件的操作持续的情况下,进行控制以使得不论上述多个演奏操作件中的、第2音域中包含的演奏操作件怎样被操作,发音的音节都不行进,在没有进行向上述第1音域中包含的某个演奏操作件的操作的情况下,进行控制以使得每当操作上述第2音域中包含的演奏操作件,发音的音节就行进。此外,也可以是,上述处理器,以基于向上述第2音域中包含的演奏操作件的操作而指定的音高,指示与上述音节位置对应的音节的发音。根据这样的结构,能够容易地进行音节的维持。
210.此外,也可以是,上述处理器,在向上述第1音域中包含的演奏操作件的操作持续的情况下,进行控制以使得不论上述第2音域中包含的演奏操作件怎样被操作,都不从操作持续的上述第1音域中包含的演奏操作件所对应的音节的位置行进。根据这样的结构,能够
进行基本上仅通过第2音域的操作使音节前进、仅在需要的情况下操作第1音域而进行音节的跳跃这样的对用户友好的动作。
211.此外,也可以对于包含在上述第1音域中的各演奏操作件分别分配包含在乐句中的各音节。根据这样的结构,用户能够容易地掌握当前的音节位置。
212.此外,也可以是,上述处理器,在特定的功能键被用户操作的情况下,将包含在上述第1音域中的演奏操作件用于上述音节的位置的决定,在不是那样的情况下,将包含在上述第1音域中的演奏操作件用于发音的音的音高指定(通常模式、通常的演奏动作)。根据这样的结构,能够适当地控制利用了键盘划分的歌词行进控制的可否。
213.此外,也可以是,上述处理器,对包含在上述第1音域中的演奏操作件,应用用于使用户理解被分配的音节的显示。根据这样的结构,由于用户能够容易地掌握与构成歌词的音节对应的键,所以能够适当地促进接着的用户操作。
214.此外,也可以是,上述处理器,进行将用来使外部装置显示用于使用户理解被分配给包含在上述第1音域中的演奏操作件的音节的显示的信息向上述外部装置发送的控制。根据这样的结构,用户能够通过视觉辨识外部装置而容易地掌握与构成歌词的音节对应的键,所以能够适当地促进接着的用户操作。
215.另外,在上述实施方式的说明中使用的框图表示功能单位的块。这些功能块(构成部)通过硬件及/或软件的任意组合实现。此外,各功能块的实现手段没有被特别限定。即,各功能块可以由物理性地结合的1个装置实现,也可以将物理性地分离的2个以上装置通过有线或无线连接,由这些多个装置实现。
216.另外,关于在本发明中说明的用语及/或本发明的理解所需要的用语,也可以替换为具有相同或类似的意思的用语。
217.在本发明中说明的信息、参数等既可以使用绝对值表示,也可以使用规定值的相对值表示,也可以使用对应的其他信息表示。此外,在本发明中对参数等使用的名称在任何方面都不是限定性的。
218.在本发明中说明的信息、信号等也可以使用各种各样不同的技术的某种来表示。例如,在上述整体说明中提及的数据、命令、指令、信息、信号、比特、符号、芯片等,也可以通过电压、电流、电磁波、磁场或磁性粒子、光场或光子、或者它们的任意组合来表示。
219.也可以将信息、信号等经由多个网络节点输入输出。被输入输出的信息、信号等既可以保存在特定的场所(例如存储器),也可以使用表进行管理。被输入输出的信息、信号等可以被覆盖、更新或追加。被输出的信息、信号等也可以被删除。被输入的信息、信号等也可以被向其他装置发送。
220.软件不论被称作软件、固件、中间件、微代码、硬件记述语言,还是被称作其他名称,都应被宽泛地解释,以表示命令、命令集、代码、代码段、程序代码、程序、子程序、软件模组、应用、软件应用、软件包、例程、子例程、对象、可执行文件、执行线程、步骤、功能等。
221.此外,软件、命令、信息等也可以经由传送介质而被收发。例如,在利用有线技术(同轴线缆、光纤线缆、双绞线、数字用户线路(dsl:digital subscriber line)等)及无线技术(红外线、微波等)的至少一方从网站、服务器或其他远程源发送软件的情况下,这些有线技术及无线技术的至少一方包含在传送介质的定义内。
222.在本发明中说明的各形态/实施方式既可以单独使用,也可以组合使用,也可以随
着执行而切换使用。此外,在本发明中说明的各形态/实施方式的处理工序、序列、流程图等只要没有矛盾就可以改换顺序。例如,关于在本发明中说明的方法,使用例示性的顺序提示了各种各样的步骤的要素,并不限定于所提示的特定的顺序。
223.在本发明中使用的“基于”的记载只要没有特别明述,就不是指“仅基于”。换言之,“基于”的记载是指“仅基于”和“至少基于”的两者。
224.在本发明中使用的向使用了“第1”“第2”等名称的要素的任何参照,都完全不限定这些要素的量或顺序。这些名称可以作为将2个以上要素间进行区别的方便的方法而在本发明中使用。因而,第1及第2要素的参照,并不意味着仅能够采用2个要素、或必须以某种形式使第1要素先行于第2要素。
225.在本发明中,在使用“包括(include)”“包含(including)”及它们的变形的情况下,这些用语与用语“具备(comprising)”同样,意味着是包含性的。进而,在本发明中使用的用语“或(or)”意味着不是排他性逻辑和。
226.本发明的“a/b”也可以意味着“a及b的至少一方”。
227.在本发明中,例如,在如英语中的a、an及the那样,通过翻译而追加了冠词的情况下,本发明也可以包括在这些冠词之后接续的名词为复数形式的情况。
228.以上,对本公开的发明详细地进行了说明,但对于本领域技术人员而言,显然本公开的发明并不限定于在本公开中说明的实施方式。本公开的发明能够不脱离基于权利要求书的记载设定的发明的主旨及范围而作为修正及变更形态实施。因而,本公开的记载以例示说明为目的,对于本公开的发明不带来任何限制性意思。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。