技术特征:
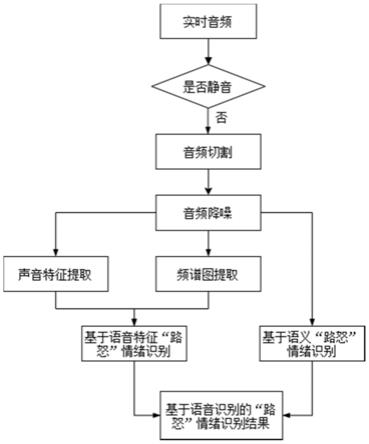
1.一种基于语音识别的“路怒”情绪判断方法,其特征在于,所述方法包括:(1)车载端实时获取的驾驶员的原始音频并进行预处理,得到用于算法模型处理的目标音频;(2)根据语音识别的“路怒”情绪判断方法流程对所述目标音频进行“路怒”情绪判断,得到识别结果,其中,所述语音识别的“路怒”情绪判断方法流程包含三个识别节点,每个识别节点包含有不同的算法模型;其中,第一个识别节点算法模型用于对目标音频合规检测及音频切割,第二个识别节点算法模型用于音频降噪、特征提取和生成频谱,第三个识别节点算法模型用于语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果;(3)采集驾驶员面部视频,将面部视频输入面部情绪识别的神经网络中,得到基于视频采集面部“路怒”情绪识别结果;对比针对基于语音的“路怒”情绪识别结果与基于视频采集面部“路怒”情绪识别结果;若存在差异,则将当前识别节点运行的算法模型参数、过去一段时间的目标音频以及基于语音的“路怒”情绪识别结果上传到云平台,云平台基于上传的数据对各个算法模型进行重新训练,更新算法模型的参数;(4)云平台在完成算法模型参数更新后,向车载端发送更新后的算法模型参数;车载端基于更新后的算法模型参数进行后续的基于语音识别的“路怒”情绪判断。2.如权利要求1所述的基于语音识别的“路怒”情绪判断方法,其特征在于实时获取驾驶员音频,并进行预处理包括:实时获取驾驶员的原始音频,从所述原始音频中提取音频码流;采用库函数对所述音频码流进行解码获取能够用于算法模型计算的目标音频,所述库函数包含python中的librosa和wave。3.如权利要求1所述的基于语音识别的“路怒”情绪判断方法,其特征在于,将目标音频输入第一个识别节点对应的第一算法模型中进行语音合规检测,得到第一结果包括:对所述目标音频进行静默检测,识别出目标音频中的非静音片段;根据所述非静音片段对所述目标音频进行切割,得到多个子音频,并将所述的多个子音频作为第一结果。4.如权利要求1所述的基于语音识别的“路怒”情绪判断方法,其特征在于,将第一结果输入第二个识别节点对应的第二算法模型中进行处理,得到第二结果包括:当第二个识别节点对应的第二算法模型接收到第一结果时,提取所述第一结果中的多个子音频的第一语音信号,并将所述第一语音信号进行降噪处理得到第二语音信号,将所述第二语音信号作为第二结果第一部分;将所述第二语音信号分成多个短时帧信号,提取多个短时帧信号的声音特征,根据所述多个短时帧信号生成频谱图,并将所述声音特征及频谱图作为第二结果第二部分。5.如权利要求1所述的基于语音识别的“路怒”情绪判断方法,其特征在于,将第二结果第一部分及第二结果第二部分输入至第三个识别节点对应的第三算法模型中进行情绪检测,得到目标识别结果包括:判断第二结果第一部分的语义中,是否包含“唤醒词”,所述唤醒词为语音助手唤醒的词句;如果语音信号中包含“唤醒词”,则不进行语义分析,如果语音信号中不包含“唤醒词”,则进行语义分析,获得语义“路怒”情绪识别结果;
基于第二结果第二部分根据语音特征分析,获得语音特征“路怒”情绪识别结果;根据语义“路怒”情绪识别结果及语音特征“路怒”情绪识别结果进行权重计算得到“路怒”情绪识别结果作为基于语音识别的“路怒”情绪识别结果,所述权重根据实际驾驶员的性格习惯进行适应调整。6.如权利要求1所述的基于语音识别的“路怒”情绪判断方法,其特征在于,所述面部情绪识别的神经网络为利用opencv的haar面部检测及cnn分类的网络。7.一种基于语音识别的“路怒”情绪判断装置,其特征在于,所述装置包括车载端和云平台:所述车载端包括:中央处理器、数据采集模块、存储模块、通信模块、边缘计算模块和摄像头;所述数据采集模块用于采集驾驶员声音,获取原始音频;所述存储模块存储采集的驾驶员声音数据、当前识别节点的算法模型参数以及基于语音识别的“路怒”情绪识别结果数据;所述通信模块用于实现车载端与云平台通信;所述边缘计算模块用于对采集的原始音频进行预处理,得到用于算法模型处理的目标音频;将目标音频经过“路怒”情绪判断方法流程进行检测,车载端的边缘计算模块部署了三个识别节点,每个识别节点包含有不同的算法模型;其中,第一个识别节点算法模型用于对目标音频合规检测及音频切割,第二个识别节点算法模型用于音频降噪、特征提取和生成频谱,第三个识别节点算法模型用于语义“路怒”情绪识别及语音特征“路怒”情绪识别,并得到计算后的基于语音的“路怒”情绪识别结果;同时所述边缘计算模块上部署了面部情绪识别的神经网络,用于识别基于摄像头采集的驾驶员面部视频,得到基于视频采集面部“路怒”情绪识别结果;所述中央处理器将对比针对基于语音的“路怒”情绪识别结果与基于视频采集面部“路怒”情绪识别结果;若存在差异,则将当前存储模块内的算法模型参数、过去一段时间的驾驶员声音数据以及基于语音的“路怒”情绪识别结果通过通信模块上传到云平台;所述云平台基于通信模块上传的数据对各个算法模型进行重新训练,更新算法模型的参数;向车载端的边缘计算模块和存储模块发送更新的算法模型参数;存储模块和边缘计算模块的算法模型参数更新;同时存储模块将已上传数据进行删除。
技术总结
本发明公开了一种基于语音识别的“路怒”情绪判断方法和装置,所述方法包括:实时获取驾驶员音频;车载边缘端对音频进行基于语音识别的“路怒”情绪判断结果,并存储识模型参数;对比基于视频采集面部“路怒”情绪判断结果;当两者结果不同时,将音频、计算结果以及当前模型参数上传云平台,云平台基于上传数据训练算法模型,向车载端发送更新的算法模型参数,边缘端完成基于语音识别的“路怒”情绪判断算法参数更新。本发明云边协同更新算法模型中的参数,云边协同方式,减轻了边缘端的计算压力,随着驾驶员驾车时长的提升,提高了语音识别“路怒”的准确率。的准确率。的准确率。
技术研发人员:徐新民 王文婧 沈鑫怡 王煜
受保护的技术使用者:浙江大学
技术研发日:2021.11.30
技术公布日:2022/3/8
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。