1.本发明属于计算机技术领域,特别涉及利用多文档摘要和多轮引导问答的可解释企业征信评价方法。
背景技术:
2.亟待监管的企业数量的日益激增,使得相关部门的及时、有效监管愈发困难,此外征信监管相关条目较多,更增加了条目抽查和失信行为判断的难度。为方便监管条目的有效选择和失信行为的及时预警,现有行政机制制定了随机抽查机制以提高监管效率。然而,基于随机抽查机制的条目选择,无法充分满足政府部门及时性、可靠性的企业监管需求。监管人员的信息获取行为往往基于粗粒度历史数据和任务驱动,更为市场中的频繁违规企业、热点违规条目等特定内容。因此,在数智赋能层面实现企业征信相关文本数据中可能违规条目、指标的抽取,和企业失信行为的及时预警,不仅可为导向性的企业监管提供有效支持,更能助力于行政效率的提升和社会企业的良性发展。
3.现有的企业征信评价研究,多将评价问题转换为机器可解的分类问题,通过企业违规历史数据统计和行业主体属性比较判断企业是否属于高风险主体。然而,
‘
历史数据 机器学习算法’模式下的判断方法依赖于大规模、高质量的历史语料,训练数据的获取高成本使得模型在性能提升上颇受掣肘,模型评价结果受限于数据质量和机器学习黑盒特性,可解释性较低。其次,对于模型反映的高风险监管条目多为市场整体情况,拟监管企业有效信息较少,现有方法难以制定实时有效监管方案。
技术实现要素:
4.针对背景技术存在的问题,本发明提供一种利用多文档摘要和多轮引导问答的可解释企业征信评价技术。
5.为解决上述技术问题,本发明采用如下技术方案:利用多文档摘要和多轮引导问答的可解释企业征信评价方法,包括以下步骤:
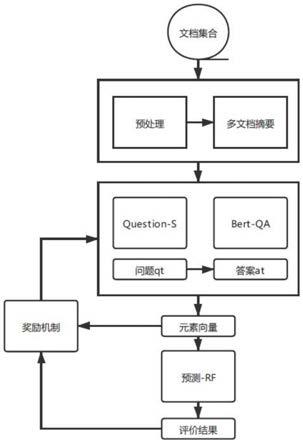
6.步骤1、输入企业文档集合,对非结构化文本进行预处理;企业文档包括但不限于基金文档、专利文本、评价文本、新闻报道以及相关部门调查报告;
7.步骤2、通过多文档摘要技术生成企业描述文本;
8.步骤3、构建企业征信评价元素集合和问题集合,结合企业描述文本和问题集合中问题文本,利用bert-qa问答模型生成问题答案;
9.步骤4、通过预训练的bert语言模型对文本进行篇章粒度向量化表征,搭建question-s问题选择网络;通过多轮迭代选择优先提问的问题,迭代停止后根据问题-答案情况生成征信元素向量;
10.步骤5、使用分类模型rf根据步骤4生成的征信元素向量判断企业是否征信违法。
11.在上述利用多文档摘要和多轮引导问答的可解释企业征信评价方法中,步骤1所述对企业文档集合文本进行预处理操作,具体过程包括:
12.步骤1.1、使用正则表达对文本进行清晰,除去特殊字符;
13.步骤1.2、使用jionlp工具包对文本进行句子切分。
14.在上述利用多文档摘要和多轮引导问答的可解释企业征信评价方法中,步骤2的实现包括以下步骤:
15.步骤2.1、应用cnn模型进行单篇文档摘要句子抽取,得到关键信息;
16.步骤2.2、通过textrank方法对多篇文档关键信息分别进行打分及排序,进一步过滤冗余信息,生成企业的单篇描述文本。
17.在上述利用多文档摘要和多轮引导问答的可解释企业征信评价方法中,步骤3的实现包括以下步骤:
18.步骤3.1、首先根据经验生成与企业征信违法强相关的评价关键元素集合和构建问题集合;
19.步骤3.2、bert-qa模型经过预训练,针对新的问题进行询问,将描述文本和问题文本作为输入,该模型输出答案,答案包含是、否两种情况。
20.在上述利用多文档摘要和多轮引导问答的可解释企业征信评价方法中,步骤4的实现包括:使用bert模型和搭建的深度神经网络,进行多轮问题抽取,具体过程如下:
21.步骤4.1、应用bert预训练语言模型对步骤2所生成的企业描述文本进行篇章粒度向量化表征,得到富含文本语义信息的特征向量;
22.步骤4.2、搭建question-s问题选择网络,使迭代过程中逐次选择一个问题,并将调整后的问题向量作为下一轮选择问题的输入向量,同时将文本向量作为输入,通过问题选择网络继续选择问题;
23.步骤4.3、生成征信元素向量,多轮问答迭代过程中提到问题且答案为是,对应元素向量维度值为1,否则为0。
24.与现有技术相比,本发明的有益效果:本发明旨在采用一种多文档摘要和多轮引导问答结合实现可解释的征信评价方法,同时该方法生成的过程问题可辅助政府部门进行企业监管抽查条目的选择。通过多文档摘要,解决了传统方法中过分依赖历史数据、模型倾向于行业整体情况、缺乏公司有效信息的问题。通过多轮引导问答策略,能够快速、优先选择关键度高、影响程度高的问题,贴合抽查需求,提升行政效率。本发明所提出的可解释征信评价技术,能够在文本信息层面实现大规模、批量化的文本自动解析,可为企业征信可解释性评价、企业有效监管以及企业风险预警提供有力支持。
附图说明
25.图1为本发明一个实施例流程图。
具体实施方式
26.下面将结合本发明实施例对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
27.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相
互组合。
28.下面结合具体实施例对本发明作进一步说明,但不作为本发明的限定。
29.本实施例采用多文档摘要策略和多轮引导问答策略完成可解释的企业征信评价,通过多文档摘要策略预先进行多源企业相关文档集合中关键信息的抽取和集成以生成企业描述文本,应用预训练的bert架构的神经网络语言模型,生成包含较多描述文本语义信息的特征向量,通过特定神经网络完成多轮问题抽取,通过bert-qa模型进行回答,并构成征信元素向量,最终借助分类模型基于元素向量完成企业征信的评价。其中,从相关部门制定的企业监管条目集合和历史违规数据中限定得到和征信强相关的元素集合,将其作为多轮引导问答策略的问题抽取范围,并通过人工标注企业元素向量(表示是否涉及元素集合相关条目),利用分类模型预测征信行为方式进行效果评价,以证明元素集合的有效性。
30.本实施例是通过以下技术方案来实现的,利用多文档摘要和多轮引导问答的可解释企业征信评价方法,获取企业文档集合;对非结构化文本进行预处理;通过多文档摘要技术生成企业描述文本;构建企业征信评价关键元素集合和问题集合;利用bert-qa问答模型根据企业描述文本和问题集合中征信问题文本,生成答案;通过预训练的bert语言模型对文本进行篇章粒度向量化表征,搭建question-s问题选择网络进行多轮引导式提问;根据问答情况构建征信元素向量;使用分类模型依据元素向量判断企业是否征信违法。该方法包括自然语言处理、机器学习和深度学习,能够实现大规模的企业文档自动化处理,并据此针对企业进行征信评价元素分析和具有可解释性的征信评价。如图1所示,具体包括以下步骤:
31.s1,输入企业文档集合,对非结构化文本进行预处理;
32.s2,通过多文档摘要技术生成企业描述文本;
33.s3,构建企业征信评价元素集合和问题集合,结合企业描述文本和问题集合中问题文本,利用bert-qa问答模型生成问题答案;
34.s4,通过预训练的bert语言模型对文本进行篇章粒度向量化表征,搭建question-s问题选择网络通过多轮迭代选择优先提问的问题,迭代停止后根据问题-答案情况构建征信元素向量;
35.s5,使用分类模型根据s4生成的元素向量判断企业是否征信违法。
36.并且,s1所述的企业文档是指任何承载企业征信相关信息的文档,包括但不限于基金文档、专利文本、评价文本、新闻报道、相关部门调查报告。所述对企业文档集合文本进行预处理操作具体过程为:应用正则表达等规则对文本进行清晰,去除非结构化文本中的特殊字符,应用jionlp工具包对文本进行句子切分。
37.并且,实现s2包括,应用cnn模型进行单篇文档进行摘要抽取得到关键信息,通过textrank方法对多篇文档关键信息分别进行打分及排序进一步过滤冗余信息,最终生成企业的单篇描述文本。
38.并且,实现s3包括,首先根据经验生成与企业征信违法强相关的评价关键元素集合和构建问题集合。bert-qa模型经过预训练,针对新的问题询问无必要重新训练模型,将描述文本和问题文本作为输入,该模型输出答案,答案包含是、否两种情况。
39.并且,s4中将企业描述文本进行向量表达,并利用优化后的神经网络通过多轮迭代选择优先提问的问题集合。具体过程包括:
40.s41,应用bert预训练模型对s2所述的描述文本进行篇章粒度向量化表征,得到富含文本语义信息的特征向量;
41.s42,搭建question-s问题挑选网络(question-select-net),使迭代过程中逐次选择一个问题,并将调整后的问题向量作为下一轮选择问题的输入向量,同时将文本向量作为输入,通过神经网络继续选择问题;
42.s43,生成征信元素向量,多轮问答迭代过程中提到问题且答案为是对应元素向量维度值为1,否则为0。
43.模型优化的奖励机制同时考虑最终征信评价的正确度和选择问题的有效度(优先选择出答案为是的关键问题)。
44.并且,s5的实现包括,对s4生成的征信元素向量,通过分类模型rf(random forest)判断企业是否征信违法。
45.由于企业征信相关文本来源多样、种类复杂,本实施示例以新闻文本、评价文本、历史抽查报告为企业文档集合来源阐述企业征信的过程方法,包括以下步骤:
46.1)输入文档集合各全文,使用正则表达和jionlp工具包对文本进行预处理;
47.2)利用cnn模型完成单篇文档关键信息抽取,对集合各关键信息按照textrank方法统一打分排序生成企业描述文本。
48.3)根据经验和监管业务实际情况选定征信评价关键元素集合,并进一步生成问题集合;将步骤2)所述企业描述文本和问题文本作为输入,利用bert-qa网络得到问题对应答案,答案用1、0表示是、否,即企业是否存在对应评价元素所述情况;
49.4)输入步骤2)所述企业描述文本,进行篇章向量化表示,将向量输入问题选择网络,由其决定本轮选择的问题编号,调整问题向量,进行下一轮迭代,具体过程包括;
50.4.1)使用bert预训练语言模型对s2中所述企业描述文本进行向量化表征,得到富含文本语义信息的篇章特征向量;
51.4.2)搭建question-s问题挑选网络(question-select-net),网络能够进行多轮逐次输出,本轮结果作为下一轮输入。
52.4.3)构建问题向量,向量维度和问题集合大小相等,向量的每一个维度包含三种情况,0表示问题尚未被提问,1表示提问到问题且答案是1,-1表示问题被提问但答案是0。
53.4.4)每轮网络运算,将步骤4.1)所述篇章特征向量和问题向量作为输入,与权重向量进行运算后得到输出向量,向量最大值对应维度与具体问题相对应,调整问题向量,进行下一轮运算;
54.4.5)进行指定轮数引导问答,依次更新问题向量;
55.4.6)根据步骤4.4)多轮引导问答最终的问题向量,推理得到征信元素向量,被问及问题且答案为1对应的元素维度值为1,其他为0。
56.步骤5)中,将步骤4.5)所述元素向量作为输入,使用分类模型rf(random forest)推理得到征信评价结果。
57.以上仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
