动态环境下基于gmm结合yolo实时跟踪与建图方法
技术领域
1.本发明涉及图像处理领域,特别涉及一种动态环境下基于gmm结合yolo实时跟踪与建图方法。
背景技术:
2.slam是指同时定位与地图构建,slam可以解决机器人在未知环境中的运动问题,通过机器人在对环境的观测后及时反馈自身的姿态以及运动轨迹,构建出环境地图。早期的slam系统主要利用单线激光雷达、声呐等传感器来实现自身的定位,随着计算机视觉的飞速发展,通过相机与imu的视觉slam系统凭借其便捷与成本低的优势,在机器人、ar地图构建、无人驾驶等领域得到广泛应用。
3.传统的动态目标检测方法包括光流法、帧间差分法和背景消除法,存在以下问题:光流法受场景亮度变化影响较大,帧差法受噪声影响较大,导致目标检测过程中存在误检、漏检等现象,使目标跟踪时产生漂移,进而影响目标跟踪的精度。
4.在诸多研究中将vslam系统建立在静态环境上,然而现实环境更为复杂,众多场景如教室、医院、购物场所等往往存在像人、车等诸多动态目标,很多的vslam系统并不具备复杂场景的适应性,导致计算得到的地图点和位姿矩阵产生误差。随着跟踪精度要求提高,目标跟踪数目增加,传统的滤波算法无法提供良好的跟踪效果。
技术实现要素:
5.发明目的:针对以上问题,本发明目的是提供一种动态环境下基于gmm结合yolo实时跟踪与建图方法,在动态环境下准确的去除动态区域,进而实现稳定的跟踪与建图。
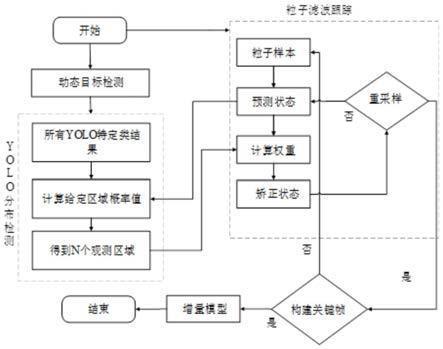
6.技术方案:本发明的一种动态环境下基于gmm结合yolo的实时跟踪与建图方法,包括如下步骤:
7.(1)对动态图像中的每帧图像提取特征点,分成关键帧和非关键帧,计算非关键帧中相邻两帧之间的仿射变换矩阵,利用仿射变换矩阵对非关键帧进行校正;
8.(2)利用高斯混合模型(gmm)对非关键帧阶段的图像进行训练,通过gmm对背景图像建模和分割前景动态区域;
9.(3)将步骤(2)训练后的非关键帧图像和步骤(1)关键帧图像输入到yolo检测器,使用粒子滤波算法,对yolo检测器的图像进行跟踪和预测,剔除当前帧检测到的动态特征点,插入关键帧进行地图构建。
10.进一步,所述步骤(1)仿射变换矩阵的关系式为:
11.12.其中等式左边矩阵表示当前帧坐标,等式右边表示仿真变换矩阵,表示当前帧的前一帧的坐标。
13.进一步,步骤(2)所述建模过程包括:
14.(21)利用gmm对非关键帧阶段图像的每个像素点进行匹配,找到每个像素点在k类正态分布模型中对应的模型,若该像素点属于当前的正态分布模型,则满足下式:
15.|x
t
‑
μ
i,t
‑1|≤2.5σ
i,t
‑116.式中x
t
表示待匹配的像素点,i表示正态分布模型对应的类别,μ
i,t
‑1表示t
‑
1时刻第i个正态分布模型对应的像素均值,σ
i,t
‑1表示t
‑
1时刻第i个正态分布模型对应所有像素的标准差;
17.(22)对k类正态分布模型的权重w
k,t
进行更新,表达式为:
18.w
k,t
=(1
‑
α)*w
k,t
‑1 α*m
k,t
19.式中α表示学习率,w
k,t
‑1表示t
‑
1时刻第k个正态分布模型权重;m
k,t
表示t时刻第k个模型匹配判别,若步骤(21)公式成立,则像素点匹配上高斯模型,m
k,t
=1,否则m
k,t
=0;
20.(23)如果当前像素点不满足步骤(21)中公式,表明当前像素点不属于背景图像,则像素均值μ
i,t
‑1和标准差σ
i,t
‑1保持不变;
21.如果当前像素点满足步骤(21)中公式,表明当前像素点属于背景图像,则更新当前所属分布模型的参数,表达式如下:
22.ρ=α*η(x
t
∣μ
k
,σ
k
)
23.μ
t
=(1
‑
ρ)*μ
t
‑1 ρ*x
t
[0024][0025]
式中ρ表示中间参数,η(x
t
∣μ
k
,σ
k
)表示t时刻第k个模型的学习率变化函数;
[0026]
(24)若所有像素点均不满足步骤(21)公式,修改高斯混合模型中权重最小的分布模型参数,将均值修改为当前像素值;
[0027]
(25)对k个分布模型进行排序,按照权重从大到小的顺序依次进行排列,选定前b个分布模型作为背景像素,其他模型为前景像素,b的表达式为:
[0028][0029]
其中t为背景所占比例,b为选定模型个数。
[0030]
进一步,步骤(3)将关键帧图像送入到yolo检测器后,关键帧建立动态候选区,接受各个候选区,抛弃不能被识别的候选区。
[0031]
进一步,步骤(3)将步骤(2)训练后非关键帧图像输入到yolo检测器后,前景动态区域为检测器提供先验,yolo检测器根据非关键帧的前景动态区域估计关键帧的前景动态区域;当非关键提供的前景动态区域与yolo检测器检测到的动态目标有重叠时,则接受此
时的动态目标候选区;若非关键提供的前景动态区域与yolo检测器检测到的动态目标无重叠时,则抛弃此时的动态目标候选区;将接收的动态目标候选区作为yolo检测器估计得到的关键帧前景动态目标。
[0032]
进一步,步骤(3):利用粒子滤波算法对yolo估计的关键帧前景动态目标进行跟踪,更新当前帧的下一帧前景动态目标存在的位置、长度信息。
[0033]
进一步,所述yolo检测器使用的检测网络为yolov3。
[0034]
进一步,所述步骤(1)校正前对非关键帧中图像各像素点进行均衡化处理。
[0035]
进一步,所述步骤(1)提取特征点通过orb
‑
slam2实现。
[0036]
有益效果:本发明与现有技术相比,其显著优点是:
[0037]
1、本发明利用关键帧全局不连续的特性,通过gmm对背景图像训练,分割出前景动态区域,为yolo提供先验;
[0038]
2、利用yolov3速度快、鲁棒性好的优点,实现连续帧之间的动态目标检测,提高了动态区域检测精度;
[0039]
3、利用yolov3结合粒子滤波算法对动态目标进行长时间跟踪,有效保证跟踪目标的稳定运行。
附图说明
[0040]
图1为仿射变换矩阵求解示意图;
[0041]
图2为gmm动态求解示意图;
[0042]
图3为gmm动态目标检测流程图;
[0043]
图4为边界框回归示意图;
[0044]
图5为yolo动态目标检测示意图;
[0045]
图6为yolo动态目标检测原理图;
[0046]
图7为基于粒子滤波的动态目标跟踪流程图。
具体实施方式
[0047]
本实施例所述的一种动态环境下基于gmm结合yolo实时跟踪与建图方法,包括如下步骤:
[0048]
(1)通过orb
‑
slam2对动态图像中的每帧图像提取特征点,分成关键帧和非关键帧,计算非关键帧中相邻两帧之间的仿射变换矩阵,如图1所示,其中(x1,y1)、(x2,y2)、(x3,y3)为当前帧对应映射点坐标,(x1’
,y1’
)、(x2’
,y2’
)、(x3’
,y3’
)为上一帧对应的映射点坐标,p1,p2,p3为三个三维点。
[0049]
对非关键帧中图像各像素点进行均衡化处理,利用仿射变换矩阵对非关键帧进行校正。
[0050]
仿射变换矩阵的关系式为:
[0051]
[0052]
其中等式左边矩阵表示当前帧坐标,等式右边表示仿真变换矩阵,表示当前帧的前一帧的坐标。
[0053]
(2)利用gmm对非关键帧阶段的图像进行训练,如图2所示。通过gmm对背景图像建模,进而分割出前景动态区域,具体过程如下,流程图如图3所示。
[0054]
(21)利用gmm对非关键帧阶段图像的每个像素点进行匹配,找到每个像素点在k类正态分布模型中匹配的模型,若该像素点属于当前的正态分布模型,则满足下式:
[0055]
|x
t
‑
μ
i,t
‑1|≤2.5σ
i,t
‑1[0056]
式中x
t
表示待匹配的像素点,i表示正态分布模型对应的类别,μ
i,t
‑1表示t
‑
1时刻第i个正态分布模型对应的像素均值,σ
i,t
‑1表示t
‑
1时刻第i个正态分布模型对应所有像素的标准差;
[0057]
(22)对k类正态分布模型的权重w
k,t
进行更新,表达式为:
[0058]
w
k,t
=(1
‑
α)*w
k,t
‑1 α*m
k,t
[0059]
式中α表示学习率,w
k,t
‑1表示t
‑
1时刻第k个正态分布模型权重;m
k,t
表示t时刻第k个模型匹配判别,若步骤(21)公式成立,则像素点属于高斯混合模型中的某一模型,m
k,t
=1;若步骤(21)公式不成立,像素点不属于高斯混合模型,m
k,t
=0;
[0060]
(23)如果当前像素点不满足步骤(21)中公式,表明当前像素点不属于背景图像,则像素均值μ
i,t
‑1和标准差σ
i,t
‑1保持不变;
[0061]
如果当前像素点满足步骤(21)中公式,表明当前像素点属于背景图像,则更新当前所属分布模型的参数,表达式如下:
[0062]
ρ=α*η(x
t
|μ
k
,σ
k
)
[0063]
μ
t
=(1
‑
ρ)*μ
t
‑1 ρ*x
t
[0064][0065]
式中ρ表示中间参数,η(x
t
|μ
k
,σ
k
)表示t时刻第k个模型的学习率变化函数;
[0066]
(24)若所有像素点均不满足步骤(21)公式,修改高斯混合模型中权重最小的分布模型参数,将均值修改为当前像素值,标准差修改为比之前标准差大,权重修改为比之前权重小;
[0067]
(25)对k个分布模型进行排序,按照权重从大到小的顺序依次进行排列,选定前b个分布模型作为背景像素,其他模型为前景像素,b的表达式为:
[0068][0069]
其中t为背景所占比例,b为选定模型个数。
[0070]
(3)将步骤(2)训练后的非关键帧图像和步骤(1)关键帧图像输入到yolo检测器,使用粒子滤波算法,对yolo检测器的图像进行跟踪和预测,剔除当前帧检测到的动态特征
点,插入关键帧进行地图构建。
[0071]
步骤(3)将关键帧图像送入到yolo检测器后,关键帧建立动态候选区,接受各个候选区,抛弃不能被识别的候选区。
[0072]
步骤(3)将步骤(2)训练后非关键帧图像输入到yolo检测器后,前景动态区域为检测器提供先验,yolo检测器根据非关键帧的前景动态区域估计关键帧的前景动态区域;当非关键提供的前景动态区域与yolo检测器检测到的动态目标有重叠时,则接受此时的动态目标候选区;若非关键提供的前景动态区域与yolo检测器检测到的动态目标无重叠时,则抛弃此时的动态目标候选区;将接收的动态目标候选区作为yolo检测器估计得到的关键帧前景动态目标。
[0073]
如图5所示,本实施例中采用yolov3目标检测算法,采用darknet
‑
53作为网络主体框架,对输入的图片划分成13
×
13的表格,利用每个单元格检测动态目标,每个单元格给出包含边界框和辨别概率值,以此判断该单元格是否包含有动态目标物以及该目标物的位置信息、概率信息。在边界框上选择维度聚类的方式挑选3种尺度、9种类型的先验框,将边界框的检测问题转换成回归问题,如图4所示,预测每个边界框的4个坐标偏移量t
x
,t
y
,t
w
,t
h
,通过偏移量计算目标框的结果,计算公式为:
[0074]
b
x
=σ(t
x
) c
x
[0075]
b
y
=σ(t
y
) c
y
[0076][0077][0078]
其中t
x
,t
y
,t
w
,t
h
分别表示x坐标、y坐标、宽度、高度的偏移量,b
x
、b
y
、b
w
、b
h
表示最终目标框的结果,σ()表示sigmoid函数,c
x
、c
y
表示特征图中当前位置相对左上角网格偏移的网格数坐标,将x的结果进行归一化处理,以加快网络收敛速度,p
w
和p
h
是先验框的宽度和高度。
[0079]
先验框包括:对于特征图尺度为13
×
13的,采用10
×
13、16
×
30、33
×
23像素大小的三种先验框;对于特征尺度图为26
×
26的,采用30
×
61、62
×
45、59
×
119像素大小的三种先验框;对于特征尺度图大小为52
×
52的,采用116
×
90、156
×
198、373
×
326像素大小的三种先验框。
[0080]
yolov3的损失函数主要包括以下三个部分:
[0081]
目标置信度损失函数
[0082][0083]
目标分类损失函数
[0084][0085]
目标定位偏移量损失函数
[0086][0087]
通过三种损失函数模型建立一个总体损失函数loss:
[0088][0089]
其中o
ij
表示该矩形框是否负责预测一个目标物体,如果该矩形框负责预测一个目标则其大小为1,否则等于0;c为预测框内含有目标物体的概率得分,为标记框内含有目标物体的真实概率得分,p表示某一类别的概率,表示标记框所属类别真实值;(x
ij
,y
ij
)是网络预测的矩形框中心坐标,是标记矩形框的中心坐标,(w
ij
,h
ij
)为网络预测的矩形框宽高大小,是标记矩形框的宽高大小,为真实值,c、p、g为拟合值。
[0090]
利用yolo进行动态区域目标检测示意图如图6所示,其中虚框代表通过gmm提供的前景动态目标候选区,实框表示yolov3检测出所有动态目标物,以重叠度iou结果作为概率信息,获取最大可能的动态目标如
②
处,同时抛弃gmm动态检测失败的区域如
①
处,抛弃yolov3得到的其他静态目标如
④
处,针对如
③
处的实框进行跟踪。
[0091]
利用粒子滤波算法对yolo估计的关键帧前景动态目标进行跟踪,更新当前帧的下一帧前景动态目标存在的位置、长度信息,具体过程如下:
[0092]
首先搭建状态方程与观测方程如下所示:
[0093]
x
r
=f
r
(x
r
‑1,v
r
‑1)
[0094]
y
r
=h
r
(x
r
,n
r
)
[0095]
其中r表示当前时刻,x表示状态量,v和n表示为噪声量,f为状态转移函数,h为测量函数。粒子滤波存在的目的是为了计算出最大可信度的x
r
,即服从贝叶斯概率的最大后验p(x
r
|y
1:r
)。已知上一时刻的概率分布函数为p(x
r
‑1|y
1:r
‑1),且状态转移服从一阶马尔科夫模型的要求,即线性的时序关系,而测量数据只与状态值有关,基于目标识别的粒子滤波算法遵循以下步骤,流程图如图7所示。
[0096]
(301)初始化:构建n个粒子,对每个粒子赋予相同的权重,且粒子在图像上均匀分布,其每个粒子满足状态方程和观测方程。同时为了将粒子滤波方程应用在目标跟踪领域,给每个粒子赋予属性信息,包括目标位置信息、目标速度信息、目标区域框框长信息、目标区域框框宽信息、目标权重信息。设定状态转移矩阵a和观测矩阵c为:
[0097][0098]
c=[i 0]
[0099][0100]
其中矩阵i表示为单位矩阵;
[0101]
(302)通过状态方程,根据上一帧n个粒子的状态结果预测当前粒子的状态:
[0102]
p(x
r
∣y
1:r
‑1)=∫p(x
r
,x
r
‑1∣y
1:r
‑1)dx
r
‑1[0103]
=∫p(x
r
∣x
r
‑1,y
1:r
‑1)p(x
r
‑1∣y
1:r
‑1)dx
r
‑1[0104]
=∫p(x
r
∣x
r
‑1)p(x
r
‑1∣y
1:r
‑1)dx
r
‑1[0105]
(303)校正阶段:通过观测方程对每个粒子计算权重,根据描述子匹配结果、iou值、像素一致性结果计算权重信息,最后对所有候选粒子权重结果进行归一化计算。为了避免在vslam视频序列中出现大量被划分为动态区域而造成vslam局部地图和位姿跟踪失败的情况,对观测结果做出限制,观测区域像素大于视频帧的一半,取消两个关键帧之间的动态结果采集。同样,如果出现大量小动态目标,急剧增加了描述子的匹配时间,设置观测数量上限10,超过上限,使用iou和像素一致性结果作为权重信息。为了计算积分结果使用蒙特卡洛采样估计计算粒子状态的期望结果。
[0106][0107]
其中q(x
r
∣y
1:r
)为引入的简单概率分布函数。
[0108]
(304)重采样阶段:通过粒子权重对预测粒子进行筛选,保留大量权重大的粒子。同时为了避免粒子权重退化问题,抛弃低权重的粒子,按权重比例,将大权重的粒子复制出来以补足抛弃的粒子数量。重采样的粒子即表示真实的状态的概率分布。权重w
i
计算公式如下所示:
[0109][0110]
其中w
iou
为预测框和检测框的交并比(归一化)结果,w
f
为对关键帧截取的目标区域图像和当前帧图像匹配得到的个数占比并归一化的结果,w
app
为外观相似度(归一化)的结果。依次通过(302)、(303)、(304)、(302)步骤完成预测更新的过程,以上步骤(301)
‑
(304)仅仅存在于两个关键帧之间的图像序列。当vslam构建关键帧时,重新判断是否需要构建新的目标区域。因此在关键帧的构建时添加增量模型,以保证跟踪过程中可以稳定跟踪动态增量,或者通过增量模型判断是否取消跟踪丢失的目标信息。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。