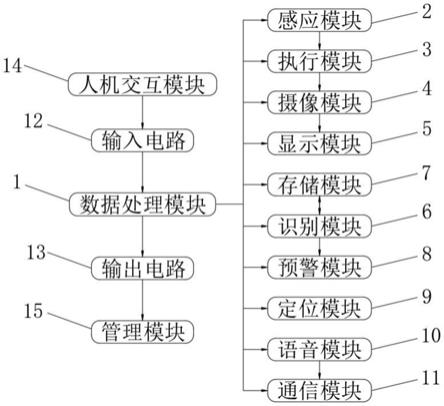
1.本发明属于通信技术领域及公共交通领域,具体涉及一种基于手机信令数据的新型共享公共交通服务区域选取方法。
背景技术:
2.手机通讯技术与互联网技术的发展与普及应用,促使手机信令数据成为城市交通数据的主要来源之一。其具有可获取性强、样本量大、可靠度高、可连续观测等特点,由此吸引了大量学者的关注。
3.传统的新型共享公共交通需求获取方式主要是通过居民出行调查获取,包括家访调查、电话调查等方式,这一过程需要消耗大量的人力、物力、精力完成调查并进行数据整合与处理工作。近年来通信设备设施不断更新,自动获取居民出行信息的手段也不断丰富,如通过公交ic卡数据、浮动车gps数据、地铁票务数据等进行出行信息挖掘,但这些数据样本量仍然较低,无法适用于普遍广泛的人群出行分析。而移动通信技术的发展,通信基站定位精度的提高,给研究大规模人群出行需求提供了新的契机。
4.现阶段国内外普遍依据天然屏障、行政区、用地性质等客观特性为原则划分交通小区,如何基于手机基站服务特性针对研究问题尽可能有效地划分交通小区是选取新型共享公共交通服务区域时面临的一个重要问题。当前利用手机信令数据进行的交通研究,通常都是根据手机基站覆盖区域,遵循传统交通小区划分原则进行划分交通小区。传统交通小区划分原则在多数研究中有较高的普适性,但是在特定科学问题的研究中针对性不强。
5.现有的新型公共交通服务区域选取方法主要通过从用户上传数据中挖掘出行需求点,再对需求点进行合并形成出行需求区域,即为新型公共交通服务区域。由于新型公共交通主要是为了适应居民个性化、多元化出行需求,因此以响应出行需求为目的对服务区域进行规划与选取无可厚非。而城市发展带来的个性化交通出行需求持续增加,需求响应式新型公共交通系统设计无益于城市公共交通系统整体水平的提升,甚至可能导致城市交通压力进一步增大,服务质量也将受到影响。
技术实现要素:
6.发明目的:为解决背景技术中存在的问题,本发明利用低成本手机通信数据,提出了一种定性与定量相结合的新型共享公共交通服务区域选取方法。
7.技术方案:本发明为解决上述技术问题采用以下技术方案:一种基于手机信令数据的新型公共交通服务区域选取方法,包括以下步骤:
8.s1、获取手机用户信令数据并进行数据预处理,基于手机用户信令数据识别停驻点,判断停驻点构成的出行段是否属于一次出行,形成用户出行链;
9.s2、基于手机信令数据分别对用户居住地和工作地进行判别,根据用户出行链中的起点/端点位置信息,判断用户的出行是否为通勤出行;
10.s3、根据手机基站的空间位置属性、活跃度属性对基站进行标定和分类,基于基站服务范围和交通小区划分原则,将研究区域划分成若干个交通小区;
11.s4、结合新型公共交通系统的特性设计服务区域筛选指标,筛选出满足指标要求的交通小区od对,筛除公交无法通行的交通小区,并最终确定服务区域。
12.作为优选,步骤s1基于手机用户信令数据的出行停驻点识别,包括以下步骤:
13.s11、设用户k某天的信令数据集合为pk={p1,p2,...pk...,pn},其中pk表示用户k的第k条信令数据,每条数据包含字段:用户编码msid、位置区编码lac、小区编码cellid、基站编码stationid、到达时刻begin_time、离去时刻end_time,通信时间duration,且该用户当天共产生n条信令数据;
14.s12、从第一条数据k=1开始,当p
k-duration>t1时,标记该基站点为停驻点;当p
k-duration<t2时,标记该基站点为位移点;当t2≤p
k-duration≤t1时,标记该基站点为可疑点;其中,t1,t2分别为停驻点阈值和位移点阈值;
15.s13、当第k个基站点与第k 1个基站点均被标记为停驻点时,计算两个基站的距离d,若d≤d
th
,则将这两个基站点合并为一个停驻点,合并这两个基站点数据为一条数据,并标记为停驻点;其中d
th
为空间阈值;
16.s14、对于每个可疑点,计算其与上一个识别为停驻点的基站的空间距离,当该距离大于空间阈值d
th
时,该可疑点被确定为停驻点;
17.s15、循环步骤s12~s14,直到所有基站点均完成标记;
18.s16、若连续两个停驻点间的距离大于空间阈值d
th
,则这两个停驻点之间构成一个出行段;计算每个出行段的出行时间及出行距离,当出行时间或出行距离小于一定值,则判定不属于一次出行,删除此出行段。
19.作为优选,步骤s2基于手机信令数据的通勤出行判别,包括以下步骤:
20.s21、首先提取在研究日期范围内出现天数大于1的用户编码msid每天[t1,t2]时段的信令数据,按字段排序,选取前一日最后一条信令数据、[t1,t2]、t1时间前一条信令数据及t2时间后一条信令数据,设该集合为ni={n
i0
,n
i1
,n
i2
,...n
ij
...,n
im
},其中n
ij
表示日期i下第j条信令数据,共m条信令数据,n
i0
为日期i的前一日最后一条信令数据;
[0021]
s22、若n
i1-begin_time>t1,且n
i0
存在,判断n
i0-stationid与n
i1-stationid之间的距离d,若d≤d
th1
,则二者在同一位置,同时计算[t1,t2]在n
(i-1)m-stationid上的逗留时间;若n
i0
不存在或d>d
th1
,则二者不在同一位置,该msid在[t1,n
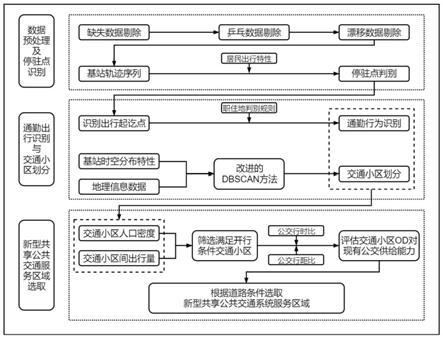
i1-begin_time]间数据缺失;
[0022]
s23、统计在该时间段每个基站逗留的总时间δt1,以及基站出现的天数x1,若δt1>2x1,则标记该基站为用户的居住地所处基站;
[0023]
s24、根据步骤s21~s23记载的方法,选取工作日的工作时段,统计用户在基站j上的总逗留时间,当出现天数大于1天且日均逗留时长大于一定值,判别基站j为用户的工作地;
[0024]
s25、在对用户居住地和工作地判别后,根据用户出行链中的起点/端点位置信息,判断用户的出行是否为通勤出行。
[0025]
作为优选,步骤s3基于手机基站多维特性对基站进行标定和分类,并将研究区域划分成若干个交通小区,包括以下步骤:
[0026]
s31、计算工作日不同时段基站活跃度以及基站经纬度对应地理位置的语义信息和停驻点基站的交通语义信息,初步对基站进行标定;
[0027]
s32、根据基站的空间位置信息,利用基于密度的dbscan聚类算法将位置间隔一定范围内、属性相同的基站分为一类,同时不断更新聚类中心点,直到所有的基站被划分到不同的聚类簇,且聚类效果的评价指标达到收敛;
[0028]
s33、将聚类簇集合映射到空间区域,利用泰森多边形法划分聚类簇基站服务范围,同时考虑交通小区划分原则,将天然屏障作为分区界限,优化交通小区边界,将研究区域划分为若干个交通小区。
[0029]
进一步的,步骤s31初步标定方法如下:
[0030]
计算某工作日各基站每td分钟内连接的用户数量,筛选各基站一天中连接用户最多的时间区间并对连接用户数量进行排序,将排在前p1%的基站初步标定为活跃基站;
[0031]
再根据各基站连接的各用户的停留时长,统计用户数量最多的停留时长,若该停留时长大于一定值,则将该基站补充标定为活跃基站,其余基站标记为不活跃基站。
[0032]
进一步的,步骤s32利用dbscan聚类算法划分基站流程如下:
[0033]
①
遍历基站样本数据集,预设邻域半径ε以及最小核心对象数minpts,将所有基站标记为未访问点;
[0034]
②
从未访问点集中任意选择一个点p,将其标记为已访问点,如果点p的ε邻域内至少有minpts个对象,则创建一个新簇c,并将点p添加到簇c中,否则将点p标记为噪音点;
[0035]
③
令n为点p的ε邻域中对象集合,遍历集合n,将其中未访问的点p
*
标记为已访问点,如果点p
*
的ε邻域内至少有minpts个对象,则将这些对象添加至集合n,此时如果点p
*
不属于任何簇集合,则将p
*
添加至c中;
[0036]
④
重复步骤
②‑③
至没有未访问点;
[0037]
⑤
计算出各聚类簇的质心位置坐标;
[0038]
⑥
分别遍历各聚类簇,计算簇内各点到其质心的空间距离,将簇内最大空间距离大于一定值的聚类簇记为待修改聚类簇;
[0039]
⑦
将各基站的交通发生量与交通吸引量作为基站属性添加至样本数据集,重新设置邻域半径ε及最小核心对象数minpts的取值,并将待修改聚类簇的所有样本点标记为未访问点;
[0040]
⑧
分别对所有待修改聚类簇重复步骤
②‑⑦
,至无待修改聚类簇,然后将各聚类簇的质心坐标作为聚类簇中心。
[0041]
作为优选,步骤s4结合新型公共交通系统的特性设计服务区域筛选指标并最终确定服务区域,包括以下步骤:
[0042]
s41、统计基站上连接的居住人口数和工作人口数,并将其映射到所属的交通小区内,计算交通小区居住人口密度和工作人口密度,选取人口密度大于均值的交通小区为城市交通出行产生区域与出行吸引区域;
[0043]
s42、提取出行产生区域与出行吸引区域间各交通小区间高峰时段出行量;
[0044]
s43、将s41筛选出的交通小区间出行量由高到低进行排序,并且根据交通小区间出行量的集中分布情况,剔除出行量低于一定值的交通小区od对;
[0045]
s44、计算s43筛选出的交通小区od对质心之间的距离,剔除距离小于一定值的交
通小区od对,筛选出满足距离要求的交通小区od对;
[0046]
s45、基于交通小区od对间现有公交线网供给情况,筛选现有公交线路行距比大于均值且行时比大于一定值的交通小区od对;
[0047]
s46、根据筛选出的交通小区od对之间的道路等级及道路条件,筛除公交无法通行的交通小区,最终确定新型共享公共交通服务区域。
[0048]
进一步的,步骤s44中距离计算使用经纬度距离公式,如下:
[0049][0050]
其中,d
ij
为交通小区i与交通小区j之间的空间距离;r为地球半径;lati为交通小区i质心的纬度坐标;loni为交通小区i质心的经度坐标。
[0051]
进一步的,步骤s45中行距比与行时比计算方法如下:
[0052]
将公交与步行出行距离比值定义为行距比,以及公交与小汽车出行时间比值定义为行时比;行距比与行时比的计算公式如下:
[0053][0054]
式中为交通小区i
→
j的公交车与步行的行距比;为交通小区i
→
j的公交车出行距离;为交通小区i
→
j的步行出行距离;
[0055][0056]
式中为交通小区i
→
j的公交车与小汽车的行时比;为交通小区i
→
j的公交车出行时间;为交通小区i
→
j的小汽车出行时间。
[0057]
有益效果:本发明采用以上技术方案与现有技术相比,具有以下技术效果:
[0058]
1、在数据源方面:本发明将手机信令数据作为数据源,通过对大样本、连续性的手机信令数据进行多角度、深层次的挖掘,尽可能全面地挖掘到全样本居民对新型共享公共交通系统的服务需求,较为准确地确定服务区域,从而为公共交通线路规划布设及政策引导提供有效支持,有利于提高城市公共交通系统整体服务水平。
[0059]
2、在交通小区划分方面:本发明基于手机信令数据,同时考虑基站活跃度时空分布特性、基站地理位置语义信息、基站定位环境特性与基站自身属性,通过改进的dbscan密度聚类算法聚类手机基站覆盖区域,针对研究问题有效划分交通小区。
[0060]
3、在新型共享公共交通服务区域选取方面:本发明利用交通大数据进行新型共享公交通需求主动辨识,极大地提高了新型共享公共交通系统的服务效用,为公共交通线路规划布设及政策引导提供有效支持;同时,定性与定量相结合的服务区域选取方法将促进新型共享公共交通系统、常规交通系统和轨道交通系统协同运作,提高城市公共交通系统整体水平,缓解城市交通压力。
附图说明
[0061]
图1为本发明的整体流程图;
[0062]
图2为实施例中昆山市城市用地性质图;
[0063]
图3为实施例中昆山市手机基站空间分布情况;
[0064]
图4为实施例中交通小区划分结果图;
[0065]
图5为实施例中交通小区居住人口密度图;
[0066]
图6为实施例中交通小区工作人口密度图;
[0067]
图7为实施例中交通小区间出行量频数直方图;
[0068]
图8为实施例中筛选后的交通小区间出行od量分布图;
[0069]
图9为实施例中交通小区od对间行距比频数直方图;
[0070]
图10为实施例中交通小区od对间行时比频数直方图;
[0071]
图11为实施例中最终确定的新型共享公共交通服务区域图。
具体实施方式
[0072]
下面结合实施例对本发明作进一步说明。
[0073]
本发明所述的基于手机信令数据的新型公共交通服务区域选取方法,整体流程如图1所示,具体包括以下步骤:
[0074]
s1、获取手机用户信令数据并进行数据预处理,基于手机用户信令数据识别停驻点,判断停驻点构成的出行段是否属于一次出行,形成用户出行链。具体包括:
[0075]
s11、设用户k某天的信令数据集合为pk={p1,p2,...pk...,pn},其中pk表示用户k的第k条信令数据,每条数据包含字段:用户编码msid(mobile subscriber identity document)、位置区编码lac(location area code)、小区编码cellid、基站编码stationid、到达时刻begin_time、离去时刻end_time,通信时间duration,且该用户当天共产生n条信令数据。
[0076]
数据预处理包括缺失数据剔除、乒乓数据剔除、漂移数据剔除;缺失数据剔除:删除缺少lac和cellid的信令数据;乒乓数据剔除:识别基站切换顺序为a-b-a和a-b-c-a的信令数据组,若该数据组的通信时间duration之和小于120s,则合并该数据组为一条数据,保留首条数据的stationid、begin_time,保留末条数据的end_time,通信时间duration相加;漂移数据剔除:计算相邻两条数据pk与p
k 1
的基站的空间距离,除以数据p
k 1
的通信时间duration,获得相邻两条数据的切换速度vk;若切换速度vk大于150km/h,则删除数据p
k 1
,合并数据pk与p
k 2
为一条数据,合并方法同前。
[0077]
s12、获取预处理后的数据,从第一条数据k=1开始,当p
k-duration>t1时,标记该基站点为停驻点;当p
k-duration<t2时,标记该基站点为位移点;
[0078]
当t2≤p
k-duration≤t1时,标记该基站点为可疑点;其中,t1,t2分别为停驻点阈值和位移点阈值;t1,t2取值分别为40min和10min。
[0079]
s13、当第k个基站点与第k 1个基站点均被标记为停驻点时,计算两个基站的距离d,若d≤d
th
,则将这两个基站点合并为一个停驻点,合并这两个基站点数据为一条数据,合并方法同前,并标记为停驻点;其中d
th
为空间阈值,取值为500m。
[0080]
s14、对于每个可疑点,计算其与上一个识别为停驻点的基站的空间距离,当该距
离大于空间阈值d
th
时,该可疑点被确定为停驻点;
[0081]
s15、循环步骤s12~s14,直到所有基站点均完成标记;
[0082]
s16、若连续两个停驻点间的距离大于空间阈值d
th
,则这两个停驻点之间构成一个出行段;计算每个出行段的出行时间及出行距离,当出行时间或出行距离小于一定值(如:出行时间小于600秒),则判定不属于一次出行,删除此出行段。
[0083]
s2、基于手机信令数据分别对用户居住地和工作地进行判别,根据用户出行链中的起点/端点位置信息,判断用户的出行是否为通勤出行;具体包括:
[0084]
s21、首先提取在研究日期范围内出现天数大于1的用户编码msid每天[t1,t2]时段的信令数据,按字段排序,选取前一日最后一条信令数据、[t1,t2]、t1时间前一条信令数据及t2时间后一条信令数据,设该集合为ni={n
i0
,n
i1
,n
i2
,...n
ij
...,n
im
},其中n
ij
表示日期i下第j条信令数据,共m条信令数据,n
i0
为日期i的前一日最后一条信令数据,每条数据包含字段同前;本实施例中,选取每天1:00~7:00的数据;即t1=1:00,t2=7:00;
[0085]
s22、若n
i1-begin_time>t1,且n
i0
存在,判断n
i0-stationid与n
i1-stationid之间的距离d,若d≤d
th
,则二者在同一位置,同时计算[t1,t2]在n
(i-1)m-stationid上的逗留时间;若n
i0
不存在或d>d
th
,则二者不在同一位置,该msid在[t1,n
i1-begin_time]间数据缺失;
[0086]
s23、统计在该时间段每个基站逗留的总时间δt1,以及基站出现的天数x1,若δt1>2x1,则标记该基站为用户的居住地所处基站;
[0087]
s24、根据步骤s21~s23记载的方法,选取工作日典型的工作时段(比如:[9:00-11:30]、[14:00-16:30]),统计用户在基站j上的总逗留时间,当出现天数大于1天且日均逗留时长大于2小时,判别基站j为用户的工作地;
[0088]
s25、在对用户居住地和工作地判别后,根据用户出行链中的起点/端点位置信息,判断用户的出行是否为通勤出行。
[0089]
s3、根据手机基站的空间位置属性、活跃度属性对基站进行标定和分类,基于基站服务范围和交通小区划分原则,将研究区域划分成若干个交通小区。具体如下:
[0090]
s31、计算工作日不同时段基站活跃度以及基站经纬度对应地理位置的语义信息和停驻点基站的交通语义信息,初步对基站进行标定;标定方法如下:
[0091]
计算某工作日各基站每5min内连接的用户数量,筛选各基站一天中连接用户最多的时间区间并对连接用户数量进行排序,将排在前50%的基站初步标定为活跃基站;
[0092]
再根据各基站连接的各用户的停留时长,统计用户数量最多的停留时长,若该停留时长大于60min,则将该基站补充标定为活跃基站,其余基站标记为不活跃基站。
[0093]
s32、根据基站的空间位置信息,利用基于密度的dbscan聚类算法将位置间隔一定范围内、属性相同的基站分为一类,同时不断更新聚类中心点,直到所有的基站被划分到不同的聚类簇,且聚类效果的评价指标达到收敛;聚类算法流程如下:
[0094]
①
遍历基站样本数据集,预设邻域半径ε以及最小核心对象数minpts,将所有基站标记为未访问点;
[0095]
②
从未访问点集中任意选择一个点p,将其标记为已访问点,如果点p的ε邻域内至少有minpts个对象,则创建一个新簇c,并将点p添加到簇c中,否则将点p标记为噪音点;
[0096]
③
令n为点p的ε邻域中对象集合,遍历集合n,将其中未访问的点p
*
标记为已访问
点,如果点p
*
的ε邻域内至少有minpts个对象,则将这些对象添加至集合n,此时如果点p
*
不属于任何簇集合,则将p
*
添加至c中;
[0097]
④
重复步骤
②‑③
至没有未访问点;
[0098]
⑤
计算出各聚类簇的质心位置坐标;
[0099]
⑥
分别遍历各聚类簇,计算簇内各点到其质心的空间距离,将簇内最大空间距离大于一定值的聚类簇记为待修改聚类簇;
[0100]
⑦
将各基站的交通发生量与交通吸引量作为基站属性添加至样本数据集,重新设置邻域半径ε及最小核心对象数minpts的取值,并将待修改聚类簇的所有样本点标记为未访问点;
[0101]
⑧
分别对所有待修改聚类簇重复步骤
②‑⑦
,至无待修改聚类簇,然后将各聚类簇的质心坐标作为聚类簇中心。
[0102]
s33、将聚类簇集合映射到空间区域,(结合arcgis平台)利用泰森多边形法(voronoi图)划分聚类簇基站服务范围,同时考虑交通小区划分原则,将天然屏障(铁路、河流、山林、道路等)作为分区界限,逐步优化交通小区边界,最终将研究区域划分为若干个交通小区。
[0103]
s4、结合新型公共交通系统的特性设计服务区域筛选指标,本实施例中采用的指标包括:交通小区人口密度,交通小区od对间出行量、质心距离、现有公交线网供给情况、道路条件;筛选出满足指标要求的交通小区od对,筛除公交无法通行的交通小区,并最终确定服务区域;具体如下:
[0104]
s41、识别研究区域内交通出行产生与出行吸引交通小区:统计基站上连接的居住人口数和工作人口数,并将其映射到所属的交通小区内,计算交通小区居住人口密度和工作人口密度,选取人口密度大于均值的交通小区为城市交通出行产生区域与出行吸引区域;
[0105]
s42、提取出行产生区域与出行吸引区域间各交通小区间高峰时段出行量;一般选取早上7:00-9:00期间为高峰时段;
[0106]
s43、将s41筛选出的交通小区间出行量由高到低进行排序,并且根据交通小区间出行量的集中分布情况,剔除出行量低于30人次的交通小区od对(origin and destination);
[0107]
s44、计算s43筛选出的交通小区od对质心之间的距离,剔除距离小于一定值的交通小区od对,筛选出满足距离要求的交通小区od对;
[0108]
距离计算使用经纬度距离公式,如下:
[0109][0110]
其中,d
ij
为交通小区i与交通小区j之间的空间距离,单位为m;r为地球半径,单位为km;lati为交通小区i质心的纬度坐标;loni为交通小区i质心的经度坐标;
[0111]
s45、基于交通小区od对间现有公交线网供给情况,筛选现有公交线路行距比大于均值且行时比大于2(说明公交线路的直达性较差)的交通小区od对;具体如下:
[0112]
通过调用地图导航路径规划api,输入交通小区od对质心的经纬度坐标,获取其公
交车、小汽车以及步行三种不同出行方式的可能出行方案,包括出行距离、出行时间以及出行费用等信息,其中公交车出行方案还包括起点到公交车站与公交车站到终点的总步行距离以及相关换乘信息;
[0113]
将公交与步行出行距离比值定义为行距比,以及公交与小汽车出行时间比值定义为行时比,来反映出公交线路的直达性;
[0114]
行距比与行时比计算方法如下:
[0115][0116]
式中为交通小区i
→
j的公交车与步行的行距比;为交通小区i
→
j的公交车出行距离,单位为m;为交通小区i
→
j的步行出行距离,单位为m;
[0117][0118]
式中为交通小区i
→
j的公交车与小汽车的行时比;为交通小区i
→
j的公交车出行时间,单位为s;为交通小区i
→
j的小汽车出行时间,单位为s;
[0119]
当公共交通出行时间超过小汽车出行时间两倍时,公众乘车体验感将急剧下降,因此选取行距比大于均值且行时比大于2的交通小区为现有公共交通供给薄弱区域,将相应的交通小区od对视为有新型共享公共交通需求的区域;
[0120]
s46、根据筛选出的交通小区od对之间的道路等级及道路条件,筛除公交无法通行的交通小区,最终确定新型共享公共交通服务区域。
[0121]
具体以江苏省昆山市手机用户信令数据为例,其中信令轨迹点状态识别如表1所示:
[0122]
表1信令轨迹点状态识别
[0123][0124]
步骤s2基于提取的手机用户信令数据,识别各用户的居住地和工作地,判别其通勤出行行为,用于为后续服务区域选取过程提供人口密度数据。
[0125]
在传统的交通小区划分基础上,步骤s31中综合考虑基站连接手机用户的时空特性、以及基站服务范围的地理语义信息和基站之间的交通语义信息,将研究区域划分为若干个交通小区。
[0126]
首先,通过分别提取手机基站在不同时段内连接用户数量情况和统计用户在基站停留时长,来描述不同基站的活跃程度,具体字段如表2和表3所示。
[0127]
表2手机基站各时段用户分布情况
[0128][0129]
表3手机基站用户停留时长统计
[0130][0131]
其次,由于城市的用地属性和功能在空间上存在差异性,因此不同基站覆盖范围内用地属性也不尽相同,代表着不同的地理语义特征。
[0132]
根据城市居民日常活动规律可知,分布范围较为广泛的居住区,相应基站在工作日日间活跃程度较低,夜间活跃度较高。而包含大型商超、写字楼等工作场所的商业区则相反,相应基站在日间活跃度较高,夜间活跃度较低。
[0133]
此外,由于工业用地大多占地面积广,且分布集中在郊区位置,根据基站布设分布情况,郊区基站覆盖密度较低,且郊区人员活动量较少,因此可以适当加大交通小区面积。而城区内人口密度较高,人流量活动较大,划分小区时需考虑实际出行量适当细化。昆山市城市用地性质图如图2所示。
[0134]
随后,结合步骤s1中识别的停驻点和位移点结果,提取所有停驻点的基站信息,代表着城市居民出行的起讫点,初步对基站进行标定。提取的手机基站空间分布情况如图3所示。
[0135]
在此基础上,步骤s32利用改进的基于密度的dbscan聚类算法对基站进行聚类;步骤s33借助arcgis平台将聚类簇集合映射到空间区域,划分聚类簇基站服务范围,最终将昆山市域划分为1034个交通小区,划分结果如图4所示。
[0136]
基于提取的2019年5月22日昆山市手机用户信令数据,步骤s4运用新型公共交通服务区域筛选指标及方法,最终确定服务区域;具体如下:
[0137]
首先,根据步骤s2各用户的居住地和工作地的判别结果,步骤s41统计各个交通小区内居住人口数及工作人口数,用各类人口数除以其单元面积,得到居住人口密度和工作
人口密度,计算结果如图5和图6所示。选取人口密度大于均值的交通小区为城市交通出行产生和出行吸引区域,即新型共享公共交通需覆盖的城市核心功能区。
[0138]
其次,将步骤s42提取的高峰时段交通小区间出行量由高到低进行排序,获得交通小区间出行量集中分布情况,如图7所示。
[0139]
步骤s43剔除出行量过低的交通小区od对(低于30人次),获得符合出行量指标的交通小区od对,其分布及相应出行od量分布如图8所示。
[0140]
步骤s44中计算交通小区od对质心距离,并根据步行和自行车出行的优势运距,剔除距离过近(d
ij
<2km)的交通小区od对,获得符合出行距离指标的交通小区od对。
[0141]
步骤s45中计算交通小区od对间行时比与行距比,统计分布情况如图9与图10所示。其中,行距比平均值为1.35,行时比平均值为4。选取行距比大于1.35且行时比大于2的交通小区od对为公共交通供给薄弱区域。
[0142]
步骤s46根据筛选出的交通小区od对之间的道路等级及道路条件,进一步筛选具备公交通行条件的交通小区,最终确定新型共享公共交通服务区域如图11所示。
[0143]
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。