1.本发明涉及智能语音领域,尤其涉及一种心理状态检测方法及系统。
背景技术:
2.心理状态自动检测的研究受到越来越多的关注,主要包括社交媒体帖子的文本检测和会话录音的音频检测。例如,应用到智能语音中,若在与用户交互的过程中感受到用户的心理状态,基于所述心理状态进行针对性的人性化回复,可以提高用户的体验。
3.对于心理状态监测模型,可以参考在计算机视觉领域取得了巨大成功的对比自我监督学习进行训练,从而检测出一个人的语言对应的心理状态。
4.在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
5.由于人的心理状态复杂多变与视觉领域完全不同,仅通过对比学习很难准确的检测用户的心理状态。
技术实现要素:
6.为了至少解决现有技术中由于人的心理复杂,仅利用视觉领域的对比训练难以准确的检测用户的心理状态的问题。
7.第一方面,本发明实施例提供一种心理状态检测方法,包括:
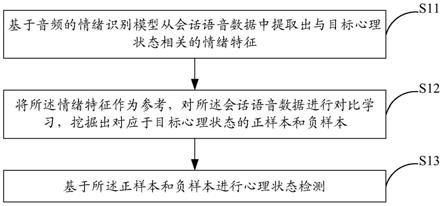
8.基于音频的情绪识别模型从会话语音数据中提取出与目标心理状态相关的情绪特征;
9.将所述情绪特征作为参考,对所述会话语音数据进行对比学习,挖掘出对应于目标心理状态的正样本和负样本;
10.基于所述正样本和负样本进行心理状态检测。
11.第二方面,本发明实施例提供一种心理状态检测系统,包括:
12.情绪特征确定程序模块,用于基于音频的情绪识别模型从会话语音数据中提取出与目标心理状态相关的情绪特征;
13.样本挖掘程序模块,用于将所述情绪特征作为参考,对所述会话语音数据进行对比学习,挖掘出对应于目标心理状态的正样本和负样本;
14.状态监测程序模块,用于基于所述正样本和负样本进行心理状态检第三方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的心理状态检测方法的步骤。
15.第四方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的心理状态检测方法的步骤。
16.本发明实施例的有益效果在于:通过情感识别模型得到的情绪参考特征,并利用对比学习,细粒度的从负样本,准确的预测出用户的心理状态。
附图说明
17.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
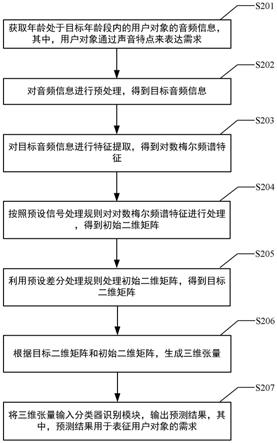
18.图1是本发明一实施例提供的一种心理状态检测方法的流程图;
19.图2是本发明一实施例提供的一种心理状态检测方法的基于音频的心理状态检测简易框架示意图;
20.图3是本发明一实施例提供的一种心理状态检测方法的基于音频的心理状态检测总框架示意图;
21.图4是本发明一实施例提供的一种心理状态检测方法的不使用任何引用来分隔正样本和负样本示意图;
22.图5是本发明一实施例提供的一种心理状态检测方法的daic-woz下游检测结果数据图;
23.图6是本发明一实施例提供的一种心理状态检测方法的验证和测试mdd上的f1分数数据图;
24.图7是本发明一实施例提供的一种心理状态检测方法的对心理状态检测结果数据图;
25.图8是本发明一实施例提供的一种心理状态检测方法的受试者的情绪分类示意图;
26.图9是本发明一实施例提供的一种心理状态检测方法的情绪嵌入的可视化示意图;
27.图10是本发明一实施例提供的一种心理状态检测方法的验证和测试iemocap上的f1得分数据图;
28.图11是本发明一实施例提供的一种心理状态检测系统的结构示意图;
29.图12为本发明一实施例提供的一种心理状态检测的电子设备的实施例的结构示意图。
具体实施方式
30.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
31.如图1所示为本发明一实施例提供的一种心理状态检测方法的流程图,包括如下步骤:
32.s11:基于音频的情绪识别模型从会话语音数据中提取出与目标心理状态相关的情绪特征;
33.s12:将所述情绪特征作为参考,对所述会话语音数据进行对比学习,挖掘出对应于目标心理状态的正样本和负样本;
34.s13:基于所述正样本和负样本进行心理状态检测。
35.在本实施方式中,本方法的目标是预先训练一个心理状态检测侧模型,从原始声学特征中提取每个片段的单个向量。进行每个片段的提取是为了防止由于连接原始特征而导致的太长序列问题。此外,也发现了如果模型能够在训练前的过程中从原始特征中获取与心理相关的信息,该策略将会有更好的表现。简易的布局如图2所示,进一步地,细致的框架介绍如图3所示。
36.对于步骤s11,为了利用额外的信息作为参考进行更有效的对比训练,首先需要一个能够提取这些情绪作为参考特征的模型。正如前面提到的,本方法把情绪作为检测心理状态的一个有利视角。基于音频的情绪识别模型从用户的对话中的会话语音中提取出与目标心理状态相关的情绪特征。
37.作为一种实施方式,所述方法还包括:
38.基于语音情感识别数据集对所述情绪识别模型进行情感预训练,以使所述情绪识别模型能够提取出与目标心理状态相关的情绪特征。在本实施方式中,首先需要训练一个基于音频的情绪识别模型φe,如图3(a)所示。
39.这种特征提取模型可以通过标准的情感识别任务来实现,该任务通常是在包含不同情感标签的音频片段的情感数据集上进行训练。可以利用一个简单的卷积神经网络来训练情绪识别模型。φe由8个堆叠的卷积块组成,每个卷积块包含一个卷积层、一个max-pooling层、一个batch归一化层和一个激活函数(relu)。注意,本方法主要关注的是培训策略,而不是提出任何新的模型体系结构,因此本方法应用到各种智能语音领域中进行工作所使用的模型都相对简单。
40.给定一个语音情感识别数据集,其中包含话语:d=[a1,a2,...,an],标签为[y1,y2,...,yn],使用模型φe从这些话语中提取表示:vi=φe(ai),并使用线性映射进行分类:经过培训后,选择在验证集上具有最佳性能的模型φe,并使用它从会话语音中提取情感相关特征作为参考特征。
[0041]
对于步骤s12,图3(b)说明了本方法的核心,即对比学习。给定一批具有n个相同大小的音频片段谱图的会话语音数据d=[a1,a2,
…
,an]进行对比学习,挖掘出对应于目标心理状态的正样本和负样本;
[0042]
具体的,将所述情绪特征作为参考,对所述会话语音数据进行对比学习包括:
[0043]
利用所述情感特征对语音检测模型内的多个相同架构的独立编码器进行对比学习。
[0044]
在本实施方式中,使用随机掩蔽方法(掩蔽为0)生成两个实例(样本)并对每个样本ai进行操作,以构造两个实例:使用两个相同架构的独立编码器φk,φq提取的嵌入,编码器φk被动量更新并且没有梯度反向传播到它:
[0045]
θk←
mθk (1-m)θq[0046]
其中θ表示模型参数。模型φk,φq的结构与φe相似,只是堆叠的卷积块的数量不同,这里是6个。另外,两种模型的最后一层是非线性映射层,在提取下游任务的表示时将去
掉这一层。
[0047]
对于样本i,主要关注于嵌入对于φq得到梯度反向传播到它,而φk没有。本方法还维护一个容量为q的队列q,以包含来自最近的前一批数据的嵌入zk。然后使用φe从这些音频片段的谱图中提取参考特征:vi=φe(ai)。对于q中的zk,也从相应的谱图中提取参考特征,表示为:[v
n 1
,
…
,v
n q
]
[0048]
使用余弦相似度来衡量两个嵌入的距离,例如是和之间的相似性得分。是将正样本的相似性最大化,将负样本的相似性最小化。
[0049]
对于样本i和对应的可以表示:
[0050]-与的相似度评分如下:
[0051]
[s1,s2,
…
,sn,s
n 1
,
…
,s
n q
],sj∈[-1,1]
[0052]-与[v1,
…
,vn]∪[v
n 1
,
…
,v
n q
]的参考相似性得分如下:
[0053]
[r1,
…
,rn,r
n 1
,
…
,r
n q
]
[0054]
当rj∈[1,1]也是是参考特征的余弦相似性时,rj为(vi,vj)之间的余弦相似性。
[0055]
积极实例(正样本)设定:
[0056][0057]
其中topk表示最高k个项目。正集合不仅包含它自己的增强视图,还包含具有最高参考相似性得分的k个实例。
[0058]
消极实例(负样本)ni包含剩余的zk。
[0059]
在对这批数据进行优化后,将被推到q中,并弹出最早的数据。这样,就得到会话语音数据的正、负样本。
[0060]
作为一种实施方式,所述将所述情绪特征作为参考,对所述会话语音数据进行对比学习,挖掘出对应于目标心理状态的正样本和负样本包括:
[0061]
基于负样本的分数确定与目标心理状态的相关性;
[0062]
利用损失函数对与所述目标心理状态相关的负样本进行加权,以细粒度的检测所述心理状态。
[0063]
在本实施方式中,与以往的对比学习方法主要关注积极的实例而对消极的实例一视同仁不同,给每个消极的实例赋予一定的权重以区分它们。最简单的来说,视觉领域即所见即所得。然而,人的语音所表达的意思并不是直接说出的意思。例如,孩子考了班级第一,家长说,你真棒啊。这就是字面上的意思,字面上积极的词语,对应开心的心理。然而如果,孩子打破了邻家的玻璃,家长说,你真棒啊,此时字面上积极的词语对应家长的心理的消息实例,属于带着怨气怒气的郁闷心理。又或者,过年给压岁钱时,通常孩子们开始会意思意思的说,“谢谢叔叔阿姨,我不要”。但其实,虽然孩子说着字面上“消极”的“不”。然而孩子也只是意思意思,并不是真实的心理想法,心理还是很积极想要的。对于上述情况,提出了一个新的损失函数,进一步细粒度的对负样本进行参考,重新确定相似性得分rj:
[0064][0065]
不同于coclr(contrastive learning of audio representation,音频表
[0066]
损失函数为
[0067]
在这里证明了本方法的损失函数的有效性:lc和l1之间的差异可以通过它们的梯度传递到ni中负样本的sn分数来实现。通过ni中阴性样品sn得分的梯度分别为:
[0068][0069][0070]
可以推断:
[0071]
当rn<0时(-rn>0),表示样本n具有负参考相似度得分。因此,两个损耗函数的梯度具有相同的符号,即优化目标是使sn变小。
[0072]
当rn>0(-rn<0)时,表示样本n对参考信息的相似度得分为正。因此,两个损失函数的梯度具有不同的符号,即修正函数会使sn变大。
[0073]
此外,考虑当sn保持不变时,|rn|将如何影响梯度范数,因为较大的|rn|意味着更显著的参考相关性。为方便起见,考虑函数f(x)=|x
·es
·
x
|,其中x=-rn∈[-1,1],s=sn∈[-1,1]。
[0074][0075]
在几乎任何情况下,都不能为0,这意味着梯度的范数随着|rn|的增加而增加。因此,在引用上与实例i关系更密切的否定实例将受到更多关注。更重要的是,在sn相近的负实例中,较大的|rn|会比较小的|rn|得到更多的更新,即改进的损失函数根据参考信息对负实例进行加权,这与传统的对比损失函数不同。因此,将区分具有相似性分数sn但参考分数rn不同的否定实例。
[0076]
由于φe提取的参考特征可能包含噪声,因此最终损失函数是l1和lc的加权和,以便更稳健:
[0077][0078]
培训过程完成后,本方法使用φq为下游任务提取特征。
[0079]
如前所述,传统的对比学习不需要引用积极的实例。为了说明使用情绪参考是否可以提高性能,还设计了一种对比学习方法“noref”,将随机蒙面实例作为积极实例。图4解
释了如何进行noref(无参考)对比训练。
[0080]
对于样本i的
[0081]
正样本:
[0082]
负样本:
[0083]
对于样本i,损失函数为:
[0084][0085]
通过上述方式可以挖掘出对应于目标心理状态的正样本和负样本。
[0086]
对于步骤s13,心理状态检测是本方法的下游任务,如图3(c)所示,使用之前通过对比学习训练的φq来提取特征和心理状态标签。数据集中的主题(受访者)在多回合对话中有多个语音片段。基于音频的心理状态的目标是预测一个二进制标签yi∈{0,1},有时是一个量表分数yr,指示用户的心理状态,例如不同程度的心理轻松健康,或者低迷郁闷。有了这些信息,就可以进一步下游处理。例如,在智能对话中,可以基于用户的心理状态调整设备的说话音调语气以及推荐内容,更加人性化。
[0087]
利用预训练模型φq从每个话语的频谱图(每个话语只有一个向量)中提取响应级特征。然后,将提取的特征序列送入一个四层双向lstm(long short-term memory,长短期记忆网络)进行凹陷检测,该lstm在下游检测中实现了sota(state of the art,目前技术水平)性能。
[0088]
通过该实施方式可以看出,通过情感识别模型得到的情绪参考特征,并利用对比学习,细粒度的从负样本,准确的预测出用户的心理状态。
[0089]
对本方法进行试验说明,报告了不同方法对下游的检测结果。在2个数据集上,由f1得分和回归指标包括mae(mean absolute error,平均绝对误差)和rmse(root mean squared error,均方根误差)测量。
[0090]
iemocap语料库是一个二元会话数据集,由大约12小时的多模态数据组成,包括语音、面部表情和手部运动,以及文本记录(其中只使用语音数据)。它包含5个环节并被记录下来自10个不同的演员。选择标签为“愤怒”、“快乐”、“兴奋”、“悲伤”、“沮丧”和“中性/平稳”的话语,其中带有“兴奋”的话语被归为“快乐”类。总共用了7380句话,其中高兴的1636句,生气的1103句,伤心的1084句,沮丧的1849句,中立的1708句。将它们随机分成训练集(70%)和验证集(30%)。使用这个数据集训练φe,并在验证集上选择性能最好的模型。
[0091]
mdd语料库是一个用于心理状态监测的大型会话数据集。它包括采访者和受试者之间1000小时的谈话,活泼快乐和低沉郁闷的参与者比例均衡(722名活泼快乐的人和527名低沉郁闷心理状态的人)。
[0092]
在这些数据中,使用大约200小时的数据进行对比学习,并训练本方法的模型φq。将数据分割成固定长度的音频片段。然后,从这些剪辑中提取形状的特征:(96*128),每个剪辑的持续时间约为0.96秒。
[0093]
还使用完整的数据集进行心理状态检测。在这里,数据集被分为一个训练集(70%)、一个开发集(15%)和一个测试集(15%)。
[0094]
daic woz《危难分析访谈语料库-绿野仙踪》是一个常用的心理状态检测基准数据集。它包含从142名用户收集的大约50小时的数据。每个用户都有两个标签:低沉郁闷/积极阳光。培训组中有30人(28%)和发展组中有12人(34%)被归类为低沉郁闷的心理状态。数据集被完全转录,包括音频中相应的on和offset。数据集中的每个用户都与采访者进行多轮对话,因此与情绪识别不同,一个用户有多个话语。虽然该数据集包含培训、开发和测试子集,但评估协议在开发子集上报告,因为测试子集标签仅适用于视听情感挑战赛的参与者。将该数据集用于本方法的下游任务,以获得与其他方法类似的结果。
[0095]
由于本方法使用的数据集有不同的采样率,将所有音频剪辑重新采样到22050赫兹。对于所有音频片段,使用128维lms(log-scale mel spectrogram,梅尔频谱)特征提取,跳跃长度为10ms,hann窗口为40ms作为输入。
[0096]
在进行对比学习时,使用1024的批大小,并设置q的大小q为8192。在这之后,设置动量m=0.999。使用λ=0.1作为默认的减重。使用初始学习率为1*10-4
,当验证损失趋于平稳时,将其降低0.5倍。训练过程持续30个周期,如果验证性能在10个周期内没有改善,将使用早期停止策略。掩蔽方法t的作用是在随机带宽下沿时间和频率轴将lms特征随机掩蔽为0。
[0097]
对于下游凹陷检测,在blstm的输出上应用了第一个时间步池和线性映射。在训练时,模型被训练了100个周期。初始学习率为5*10-5
,批量大小为1。
[0098]
将本方法的工作与以前的对比音频结果进行比较。depaudionet提出了一个结合cnn(convolutional neural networks,卷积神经网络)和lstm的深层模型,对声道中与心理状态相关的特征进行编码,以提供更全面的音频表示。tcn(temporal convolutional network,时间卷积网络)已被用于提取工作中的高级特征表示。lld代表表现良好的低水平描述符包括:光谱特征、韵律特征和音质特征,用于预测心理状态的不同程度。将工作分为两组:有对比学习和没有对比学习。原始lms使用输入blstm检测模型的基本lms特征。情感lms利用φe的情感特征进行心理状态检测,即用φe代替φq提取嵌入。noref是不使用参照物的对比学习。coclr(互补强化对比学习)利用引用挖掘正面实例,其中λ=0,损失函数减少为coclr类型的实例。re-clr(reference-enhanced contrastive learning,参照强化对比学习)考虑了引用相似性。
[0099]
小型基准数据集daic-woz上的结果如图5显示了基准daic-woz数据集上的心理状态检测结果,该数据集包含相对较少的受试者。通常,使用对比学习方案在很大程度上提高了心理状态检测的准确性(与原始lms相比),适用于这种数据稀疏的情况。
[0100]
此外,有参考文献的对比学习方法(本方法提出的reclr和coclr)在分类和回归指标上都优于所有其他结果,表明使用与下游任务相关的参考文献来增强对比学习的预训练过程有利于提高绩效。可以看出,参考文献在对比学习中起着重要作用:有参考文献的方法优于无参考文献的方法。
[0101]
最后,reclr优于coclr-style风格,这意味着通过更好地利用情绪相关特征,本方法的参考增强对比学习方法可以更好地捕捉有助于心理状态检测的信息。对于使用情绪相关特征的方法(情绪lms,reclr,coclr),在回归度量上往往有更好的表现,这与患者的心理状态严重程度有关。结果表明,利用情绪信息有助于预测心理状态的严重程度。
[0102]
进一步比较了比较大的mdd数据集上的对比学习方法,结果如图6所示。同样,对比
参考学习优于noref。在验证集和测试集上,reclr都实现了最好的性能。
[0103]
本方法还进行了几个实验来比较参数λ的影响。除λ外,所有实验的设置与上述相同。由于iemocap数据集中的数据量较小,在其上训练的模型φe可能不够强;因此,由φe提取的参考可能包含噪声。因此,需要区分不同样本中的实例。
[0104]
如图7所示了不同λ的性能,当λ=0时,损失函数类似于coclr类型的函数,没有权重来区分负样本。结果表明,随着λ的增加,性能先增加后下降,这表明在l1和lc之间有一个适当的λ平衡是鲁棒性所必需的。
[0105]
为了证明选择情绪相关信息作为参考的有效性,使用情绪识别训练的模型从心理状态数据集(daic-woz)中的每个话语中提取相应的发送分数。图8显示了daic-woz数据集中一些心理心情低沉郁闷和心理阳光健康快乐受试者的相应情绪类别,他们的id在垂直轴上标记。“all”表示郁闷和阳光受试者的总平均水平。可以推断,与健康的人相比,心情郁闷的人倾向于输出更消极的情绪。它展示了心情郁闷和情绪之间的关系,从情绪识别学习到的知识转移到心理状态检测任务。
[0106]
为了验证reclr在相似类实例聚类中的有效性,采用了reclr模型φq进行情感嵌入提取。对于iemocap数据集中的每个话语,通过φq提取单个向量(嵌入)。还提取noref和原始lms特征进行比较。
[0107]
随机选取标记为“快乐-悲伤”和“愤怒-中性”的话语,它们代表了情感匹配和激活。使用t-分布随机邻居嵌入(t-sne)将这些嵌入的维数降低到二维平面,并在图9中显示它们。根据对比学习的本质,积极实例的表达将被结合在一起。具有相同标签的reclr提取的嵌入比其他两个嵌入更接近,表明reclr很好地利用了情感识别的知识。
[0108]
本方法还将半监督学习应用于上述嵌入的iemocap。将数据随机分成训练集(1%)、开发集(29%)和测试集(70%)。此外,还使用了线性探测策略,即训练一个简单的线性映射层来使用嵌入进行分类。通过使用非常少量的数据和简单的模型,希望减少由分类模型体系结构和iemocap数据集的原始数据分布带来的额外知识。图10所示了reclr方法在所有方法中取得了最好的性能,表明reclr从情感识别数据集中学习知识。
[0109]
总的来说,由于数据有限的问题,心理状态的检测是一个相当具有挑战性的任务。因此,本方法使用自我监督的方法对模型进行预训练,并对心理状态进行检测。作为其下游任务。本方法提出了一种用于心理状态检测的参考增强对比学习音频表征方法——reclr。还提出了一种新的参考增强损失函数,在与下游任务相关的参考信息的帮助下,以更细粒度的方式进行对比学习。选择情绪相关信息作为参考,将情绪识别数据集中的知识转移到心理状态中,并检验它们之间的关系。在两个心理状态检测数据集上,通过与以往的工作和其他对比学习策略的比较,证明了本方法具有更优的性能。
[0110]
如图11所示为本发明一实施例提供的一种心理状态检测系统的结构示意图,该系统可执行上述任意实施例所述的心理状态检测方法,并配置在终端中。
[0111]
本实施例提供的一种心理状态检测系统10包括:情绪特征确定程序模块11,样本挖掘程序模块12和状态监测程序模块13。
[0112]
其中,情绪特征确定程序模块11用于基于音频的情绪识别模型从会话语音数据中提取出与目标心理状态相关的情绪特征;样本挖掘程序模块12用于将所述情绪特征作为参考,对所述会话语音数据进行对比学习,挖掘出对应于目标心理状态的正样本和负样本;状
态监测程序模块13用于基于所述正样本和负样本进行心理状态检测。
[0113]
进一步地,所述样本挖掘程序模块用于:
[0114]
基于负样本的分数确定与目标心理状态的相关性;
[0115]
利用损失函数对与所述目标心理状态相关的负样本进行加权,以细粒度的检测所述心理状态。
[0116]
进一步地,所述样本挖掘程序模块用于:
[0117]
对所述会话语音掩码,生成多个数据集;
[0118]
利用所述多个数据集、所述情感特征对语音检测模型内的多个相同架构的独立编码器进行对比学习。
[0119]
进一步地,所述系统还包括情感预训练程序模块,用于:
[0120]
基于语音情感识别数据集对所述情绪识别模型进行情感预训练,以使所述情绪识别模型能够提取出与目标心理状态相关的情绪特征。
[0121]
本发明实施例还提供了一种非易失性计算机存储介质,计算机存储介质存储有计算机可执行指令,该计算机可执行指令可执行上述任意方法实施例中的心理状态检测方法;
[0122]
作为一种实施方式,本发明的非易失性计算机存储介质存储有计算机可执行指令,计算机可执行指令设置为:
[0123]
基于音频的情绪识别模型从会话语音数据中提取出与目标心理状态相关的情绪特征;
[0124]
将所述情绪特征作为参考,对所述会话语音数据进行对比学习,挖掘出对应于目标心理状态的正样本和负样本;
[0125]
基于所述正样本和负样本进行心理状态检测。
[0126]
作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本发明实施例中的方法对应的程序指令/模块。一个或者多个程序指令存储在非易失性计算机可读存储介质中,当被处理器执行时,执行上述任意方法实施例中的心理状态检测方法。
[0127]
图12是本技术另一实施例提供的心理状态检测方法的电子设备的硬件结构示意图,如图12所示,该设备包括:
[0128]
一个或多个处理器1210以及存储器1220,图12中以一个处理器1210为例。心理状态检测方法的设备还可以包括:输入装置1230和输出装置1240。
[0129]
处理器1210、存储器1220、输入装置1230和输出装置1240可以通过总线或者其他方式连接,图12中以通过总线连接为例。
[0130]
存储器1220作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块,如本技术实施例中的心理状态检测方法对应的程序指令/模块。处理器1210通过运行存储在存储器1220中的非易失性软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例心理状态检测方法。
[0131]
存储器1220可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储数据等。此外,存储器1220可以包
括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,存储器1220可选包括相对于处理器1210远程设置的存储器,这些远程存储器可以通过网络连接至移动装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0132]
输入装置1230可接收输入的数字或字符信息。输出装置1240可包括显示屏等显示设备。
[0133]
所述一个或者多个模块存储在所述存储器1220中,当被所述一个或者多个处理器1210执行时,执行上述任意方法实施例中的心理状态检测方法。
[0134]
上述产品可执行本技术实施例所提供的方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本技术实施例所提供的方法。
[0135]
非易失性计算机可读存储介质可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据装置的使用所创建的数据等。此外,非易失性计算机可读存储介质可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,非易失性计算机可读存储介质可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至装置。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
[0136]
本发明实施例还提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的心理状态检测方法的步骤。
[0137]
本技术实施例的电子设备以多种形式存在,包括但不限于:
[0138]
(1)移动通信设备:这类设备的特点是具备移动通信功能,并且以提供话音、数据通信为主要目标。这类终端包括:智能手机、多媒体手机、功能性手机,以及低端手机等。
[0139]
(2)超移动个人计算机设备:这类设备属于个人计算机的范畴,有计算和处理功能,一般也具备移动上网特性。这类终端包括:pda、mid和umpc设备等,例如平板电脑。
[0140]
(3)便携式娱乐设备:这类设备可以显示和播放多媒体内容。该类设备包括:音频、视频播放器,掌上游戏机,电子书,以及智能玩具和便携式车载导航设备。
[0141]
(4)其他具有数据处理功能的电子装置。
[0142]
在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”,不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
[0143]
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性
的劳动的情况下,即可以理解并实施。
[0144]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
[0145]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。