1.本技术涉及语音转换模型生成方法和装置的技术领域。
背景技术:
2.实时声音转换技术具有广泛的应用场景,是指保留原说话人的节奏、情感、语速等特征,在保持说话内容信息一致的前提下,将其实时转换为指定说话人的声音。例如,玩家在玩游戏时进行“变声”,让游戏里的语音互动变得更具娱乐性。在电话客服场景,让客服的声音变得更加柔美,提升用户的体验。在直播领域,主播通过声音转换软件转变成某位“明星”的声音,以吸引用户观看。
3.目前常见的变声算法主要是:1)基于数据信号处理方式来调节音调和音色,其调节出来的声音有局限性且不够逼真和自然,另外要求使用者对各类参数有一定的了解;2)基于语音合成的方法,将原始音频转为音频特征之后再通过语音合成方法合成至目标声音,该方法合成的声音较为自然,但是该方法本质上需要接收到完整的一句话音频之后才能进行转换,无法做到基本实时的同步合成。
4.因此,需要提出一种新的技术来解决上述现有技术中的一个或多个问题。
技术实现要素:
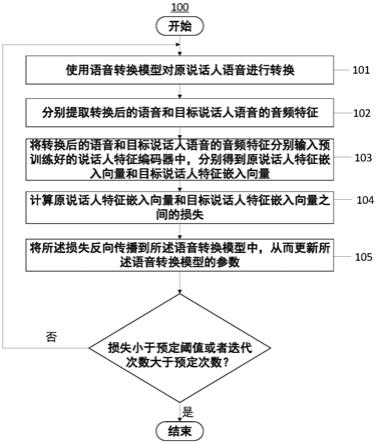
5.根据本公开的一个方面,提供了一种语音转换模型生成方法,该方法用于训练基于神经网络的语音转换模型,包括以下步骤:a.使用所述语音转换模型对原说话人语音进行转换;b.分别提取转换后的语音和目标说话人语音的音频特征;c.将转换后的语音和目标说话人语音的音频特征分别输入预训练好的说话人特征编码器中,分别得到原说话人特征嵌入向量和目标说话人特征嵌入向量;d.计算原说话人特征嵌入向量和目标说话人特征嵌入向量之间的损失;e.将所述损失反向传播到所述语音转换模型中,从而更新所述语音转换模型的参数;f.使用更新后的所述语音转换模型,重复上述步骤a至e,直到所述损失小于预定阈值或者迭代次数大于预定次数。
6.根据本公开的另一方面,提供了一种实时语音转换方法,包括:接收原说话人语音;和使用根据上述方法生成的语音转换模型对原说话人语音进行转换。
7.根据本公开的另一方面,提供了一种计算机可读存储介质,包括可执行指令,当所述可执行指令由信息处理装置执行时,使所述信息处理装置执行上述各方法。
8.根据本公开的另一方面,提供了一种语音转换模型生成装置,该装置用于训练基于神经网络的语音转换模型,包括:一个或多个处理器;和存储器,其上存储有可执行指令,所述可执行指令在由所述一个或多个处理器执行时使得所述一个或多个处理器:a.使用所述语音转换模型对原说话人语音进行转换;b.分别提取转换后的语音和目标说话人语音的音频特征;c.将转换后的语音和目标说话人语音的音频特征分别输入预训练好的说话人特征编码器中,分别得到原说话人特征嵌入向量和目标说话人特征嵌入向量;d.计算原说话人特征嵌入向量和目标说话人特征嵌入向量之间的损失;e.将所述损失反向传播到所述语
音转换模型中,从而更新所述语音转换模型的参数;f.使用更新后的所述语音转换模型,重复上述处理a至e,直到所述损失小于预定阈值或者迭代次数大于预定次数。
9.根据本公开的另一方面,提供了一种实时语音转换装置,包括:一个或多个处理器;和存储器,其上存储有可执行指令,所述可执行指令在由所述一个或多个处理器执行时使得所述一个或多个处理器:接收原说话人语音;和使用通过上述装置生成的语音转换模型对原说话人语音进行转换。
附图说明
10.图1是说明根据本公开的一个实施例的语音转换模型生成方法的流程图。
11.图2是根据本公开的一个实施例的语音转换模型的示例。
具体实施方式
12.现在将参照附图来详细描述本公开的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
13.以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。
14.对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
15.在这里示出和讨论的所有示例中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它示例可以具有不同的值。
16.如上所述,现有的两种主要的变声算法存在各自的局限性。为了解决现有技术中存在的上述技术问题中的一个或多个,本技术的发明人提出了一种新的技术构思:使用基于神经网络的语音转换模型对语音进行转换,并使用原说话人语音和目标说话人语音对该语音转换模型进行训练。
17.图1是说明根据本公开的一个实施例的语音转换模型生成方法100的流程图,该方法用于对未训练好的基于神经网络的语音转换模型进行训练,从而生成最终的语音转换模型。
18.在方法100中,首先,使用语音转换模型对原说话人语音进行转换(步骤101)。在一些实施例中,可以接收原说话人语音并对其进行转换。在一些实施例中,可以对存储在服务器或云端上的原说话人语音进行转换。
19.在一些实施例中,在转换时,需要将原说话人语音分成具有第一时间长度(例如,30ms(毫秒))的多个帧,并且每次将一个或多个帧输入语音转换模型中。在一些实施例中,在将语音分成帧时,可以采用具有第二时间长度(例如,10ms)的滑动窗口,使得相邻帧之间存在交叠的时间长度。
20.在一些实施例中,可以每次将原说话人语音的一个或多个帧输入语音转换模型中,并使用该语音转换模型将原说话人语音的所述一个或多个帧转换成一个帧的语音数据。通过重复该过程,可以将具有预定时间长度(例如,半小时左右)的原说话人语音转换成在时间上连续的多个帧的语音数据。需要指出的是,上述语音转换可以基本上实时地进行。
21.作为一个示例,例如,在第一时间长度为30ms,第二时间长度为10ms的情况下,可以将原说话人语音分成如下的帧:第1帧(时间区间在0~30ms)、第2帧(时间区间在10~40ms)、第3帧(时间区间在20~50ms)、第4帧(时间区间在30~60ms)、第5帧(时间区间在40~70ms)、第6帧(时间区间在50~80ms)、第7帧(时间区间在60~90ms)、第8帧(时间区间在70~100ms)
…
。
22.作为一个示例,可以每次将原说话人语音的5个帧输入语音转换模型中,并且可以每次错开三帧输入下一组的5个帧。例如,第一次输入第1至第5帧,第二次输入第4至第8帧
…
。在一些实施例中,可以每三帧输出一次语音。由此,转换后的语音的第1帧的时间区间为20~50ms,第2帧的时间区间为50~80ms,从而能够确保转换后的语音的各个帧在时间上是连续的。此外,在每次输入原说话人语音的多个帧的情况下,可以使得输入的语音具有足够的上下文信息,从而能够提高语音转换的准确度。
23.需要指出的是,上述所有数值都是示例性的,本公开的技术不限于这些具体数值。
24.在步骤101之后,可以分别提取转换后的语音和目标说话人语音的音频特征(步骤102)。与步骤101类似,可以接收目标说话人语音并对其进行特征提取。在一些实施例中,可以对存储在服务器或云端上的目标说话人语音进行特征提取。在一些实施例中,可以使用第一时间长度(例如,30ms(毫秒))的时间窗口和第二时间长度(例如,10ms)的滑动窗口对语音进行特征提取。在一些实施例中,目标说话人语音可以具有预定时间长度(例如,半小时)。
25.音频特征是指能够表征说话人语音的特征的任意特征。在一些实施例中,音频特征例如可以包括短时能量、过零率以及梅尔倒谱系数(mel frequency cepstral coefficents,mfcc)。
26.在一些实施例中,原说话人语音和目标说话人语音的说话内容可以相同,并且可以具有相同的预定时间长度(例如,半小时)。
27.在步骤102之后,可以将在步骤102中提取的转换后的语音和目标说话人语音的音频特征分别输入预训练好的说话人特征编码器中,分别得到原说话人特征嵌入向量和目标说话人特征嵌入向量(步骤103)。
28.在一些实施例中,说话人特征编码器可以是基于神经网络的语音特征编码器。在本公开中,该语音特征编码器用于将说话人的音频特征转换成说话人特征嵌入向量,该说话人特征嵌入向量中嵌入有一个或多个说话人语音特征。使用转换后的说话人特征嵌入向量,可以更容易地对不同说话人的语音特征的差别进行量化。
29.在一些实施例中,在使用说话人特征编码器之前,可以使用大量任何人的语音对说话人特征编码器进行预训练。
30.在一些实施例中,可以使用大量任何人的语音对包括编码器和解码器的基于神经网络的自编码器进行预训练,并使用预训练好的自编码器中的编码器部分,作为说话人特征编码器。
31.在步骤103之后,可以计算原说话人特征嵌入向量和目标说话人特征嵌入向量之间的损失(步骤104)。在一些实施例中,所述损失可以是可用于评估两个向量之间的差别的任何函数。在一些实施例中,损失例如可以是平方误差损失、绝对误差损失、huber损失或交叉熵损失。本领域技术人员可以在实施本技术时根据具体情况选择合适的损失。例如,对于
某些结构或类型的神经网络,可以选择交叉熵损失来加快神经网络的学习过程。在一些实施例中,可以针对所述预定时间长度上的所有帧的说话人特征嵌入向量和目标说话人特征嵌入向量计算损失。
32.在步骤104之后,可以将所述损失反向传播到语音转换模型中,从而更新语音转换模型的参数(步骤105)。
33.使用更新后的语音转换模型,可以重复上述步骤101至105,直到损失小于预定阈值或者迭代次数大于预定次数,从而生成最终的语音转换模型。
34.使用最终的语音转换模型,可以直接将原说话人的音色自然且逼真地转换成目标说话人的音色,并且能够保留原说话人的节奏、情感以及语速。此外,在用户使用语音转换模型时,不需要进行参数设置。
35.在本公开中,语音转换模型可以是基于任何类型的神经网络(例如,深度神经网络、时延神经网络、卷积神经网络、递归神经网络以及多种任何类型的神经网络的组合)的模型。在一些实施例中,本公开可以使用基于时延神经网络(tdnn)结构的深度神经网络。
36.图2是示出根据本公开的一个实施例的语音转换模型的神经网络结构的图,其基于3层tdnn结构。显然,本公开中的神经网络的深度不受任何限制。针对该神经网络,例如,第一时间长度(帧长)为30ms,第二时间长度(滑动窗口大小)为10ms。在该神经网络的示例结构中,分别在t,t 3(表示t 30ms,以下类似),t 6
…
时刻输出转换后的语音信号,t时刻的转换信号需要延迟到t 8时刻输出,即系统延迟为80ms。
37.在本公开中,通过设计神经网络的结构,使得原说话人语音的转换后的语音的时间延迟不超过200ms。由此,用户不会感觉到明显的延迟,从而能够实现基本实时的语音转换。
38.在一些实施例中,还可以提供一种实时语音转换方法,包括:接收原说话人语音;和使用根据如上所述方法生成的语音转换模型对原说话人语音进行转换。如上所述,通过进行转换,能够将原说话人语音转换成目标说话人的音色的语音。
39.在一些实施例中,可以在语音转换模型生成装置中实现本公开的上述语音转换模型生成处理。该语音转换模型生成装置可以包括处理电路,该处理电路可以被配置成执行上述语音转换模型生成处理。
40.在一些实施例中,语音转换模型生成装置可以包括一个或多个处理器和存储器,在该存储器上可以存储可执行指令,该可执行指令在由所述一个或多个处理器执行时使得所述一个或多个处理器执行上述语音转换模型生成处理。
41.在一些实施例中,可以提供一种实时语音转换装置,包括:一个或多个处理器;和存储器,其上存储有可执行指令,所述可执行指令在由所述一个或多个处理器执行时使得所述一个或多个处理器:接收原说话人语音;和使用通过上述语音转换模型生成装置生成的语音转换模型对原说话人语音进行转换。
42.在一个实施例中,本公开可以提供一种计算机可读存储介质,其包括可执行指令,当所述可执行指令由信息处理装置(例如,诸如计算机、智能电话之类的装置)执行时,使该信息处理装置执行上述语音转换模型生成处理或实时语音转换处理。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。