1.本发明涉及脑部磁共振图像处理技术领域,尤其涉及一种采用了多尺度卷积和分散注意力的3d u-net全卷积模型,用于解决脑白质高信号(white matter hyperintensities,wmh)的自动分割问题。
背景技术:
2.脑白质高信号(white matter hyperintensity,wmh)是指出现在核磁共振的t2加权图像和flair图像上出现的高亮的局部区域,也称脑白质病变。wmh常见于患有神经退行性疾病(例如痴呆、阿尔茨海默氏症)、中风和脑小血管疾病患者的脑部磁共振图像(mri)中,以及70岁以上的健康老年人的脑结构中。已有研究表明,wmh的大小、位置、数量和形状可以为探索脑部疾病的病因和发展以及评估治疗效果提供有价值的信息,因此,准确分割出mri上的wmh区域并对其进行定量和定性分析在临床诊断上具有重要意义。
3.然而,依靠医生手动分割出wmh区域是十分耗时的,因为手动方式要在mri影像上逐帧处理(每个大脑mri影像通常包含数十甚至上百帧切片),如果每一帧都由医生手动分割会耗费医生大量的时间和精力。同时,由于手动分割依靠医生的主观判断,因此,难免会有人为疏漏,还会产生不同医生由于经验不同所致的诊断结果差异。如果能由机器取代医生对脑白质病变部位进行自动分割,则可以把医生从繁重的分割操作中解脱出来,并确保分割与诊断结果的客观性和准确性。因此,近年来研究者们提出了许多wmh自动分割方法,主要包括早期的基于传统机器学习的分割方法和当前基于深度学习的分割方法。由于深度学习方法能自主地学习出隐含于图像中的复杂的特征,因此在分割效果上优于传统方法。但现有的深度学习方法在解决wmh分割问题时多数是直接采用图像分割领域中的经典全卷积神经网络u-net模型或对其进行简单改进,比如单纯增加跳跃连接,或在瓶颈层或所有层不加区分的使用注意力等,这些看似改进的方法由于缺少针对性,对分割效果的提升并不明显,因此分割的准确度不高,存在小病灶漏识,病灶边界分割不精准的问题。究其原因,是模型在设计时没有充分考虑wmh的特点,使得模型的特征提取能力不足,进而影响分割效果。
4.wmh具有形状多变、位置随机、信号不均的特点,如有的呈片状,有的呈点状;有的出现在脑室周围,有的出现在脑深部;有的具有明显的高亮度信号,有的在亮度上与周边组织相似,这些都给wmh的自动识别带来难度和挑战。因此,亟待研究一种能够针对wmh特点的、准确、有效的自动分割脑白质高信号(wmh)的技术,以解决目前wmh分割中小病灶漏识、边界分割不精准、分割准确度不高的问题。
技术实现要素:
5.针对现有技术的不足,本发明提出一种基于多尺度融合和分散注意力的脑白质高信号全卷积分割方法,该方法通过增强模型的多尺度特征提取能力和对分割目标的关注能力提升wmh自动分割的准确率,能很好地分割出脑白质高信号区域,特别是能分割出许多细
小的病灶。
6.技术方案如下:
7.一种基于多尺度融合和拆分注意力的脑白质高信号分割方法,步骤如下:
8.步骤一、获取脑白质高信号flair图像数据集;
9.步骤二、对获取的脑白质高信号flair图像数据集进行划分,分成训练集、验证集和测试集;
10.步骤三、对获取的脑白质高信号flair图像数据集进行预处理;
11.步骤四、对所述基于多尺度融合和拆分注意力的脑白质高信号分割模型进行构建和训练;
12.s4.1、构建所述基于多尺度融合和拆分注意力的脑白质高信号分割模型;
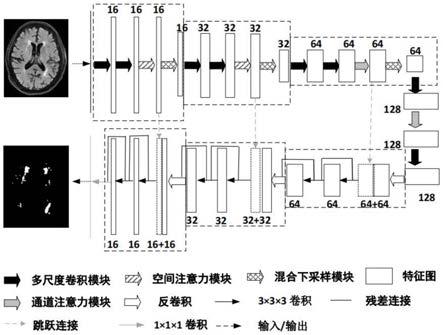
13.所述基于多尺度融合和拆分注意力的脑白质高信号分割模型基于3d u-net架构,包括编码部分和解码部分。其中,编码部分由三个具有同样结构的特征提取子模块及一个瓶颈层组成;每个特征提取子模块包括2个多尺度卷积模块、1个注意力模块和1个混合下采样模块;瓶颈层顺次包含1个多尺度卷积模块、1个注意力模块、1个多尺度卷积模块;解码部分由三个具有同样结构的解码子模块和1个像素分类层组成,每个解码子模块包括1个反卷积和2个带有残差连接的卷积。此外,模型中还包括三次跳跃连接,该连接将每个特征提取子模块中的注意力模块送与对等的解码子模块中的反卷积结果进行拼接。其中,拆分注意力体现在,在第1和第2编码层中的注意力模块使用空间注意力模块;在第2编码层和瓶颈层中的注意力模块使用通道注意力模块。
14.s4.2、将预处理后的训练集、验证集图像数据输入到构建好的模型中进行训练。训练基于损失函数计算误差。在训练过程中,将训练集图像输入模型进行多轮次的训练,并基于验证集对每一轮次的训练结果进行验证,当训练满足终止条件时,得到模型在该训练集下的最优权值参数,此时停止训练,得到训练好的分割模型。
15.步骤五、将测试集中的每个图像输入到已经训练完成的基于多尺度融合和拆分注意力的脑白质高信号分割模型中进行测试;
16.s5.1、将训练好的模型在测试集上进行测试与显示
17.s5.2、对测试结果进行评估
18.进一步的,在步骤三中,所述预处理包括:数据增强、统一图像大小和数据归一化。
19.进一步的,在步骤4.2中,所述训练过程的终止条件是:当验证集上的损失函数值在n个迭代周期内不再减小时停止训练;或达到迭代次数的上限。模型训练过程中还需要设置学习率、优化模式、迭代次数。
20.进一步的,在步骤4.1中,所述多尺度卷积模块包含3条卷积支路和1条残差支路。3条卷积支路分别采用16
×
n个1
×1×
1卷积、16
×
n个3
×3×
3卷积、连续两次16
×
n个3
×3×
3卷积,其中n为编码层(包含瓶颈层在内)的层次数,n∈{1,2,3,4}。3条卷积支路的输出结果经过逐体素叠加后与残差支路的输出再叠加,最后经过relu激活函数输出。
21.进一步的,在步骤4.1中,所述混合下采样模块中:
22.对输入的特征矩阵进行最大池化,同时进行卷积核大小为3
×3×
3,步长为2的卷积操作,然后将获得的两个特征矩阵拼接,再执行一个卷积核大小为1
×1×
1,步长为1的卷积操作来融合特征实现信息补偿;
23.用以下公式表示:
[0024][0025]
其中,x
in
表示输入特征,y
out
表示混合下采样模块的输出,c1×1×1表示卷积核大小为1
×1×
1,步长为1的卷积,c3×3×3表示卷积核大小为3
×3×
3,步长为2的卷积,max
pool
表示最大池化,表示拼接操作。
[0026]
进一步的,在步骤4.1中,所述通道注意力模块中:
[0027]
首先在空间维度上分别使用全局平均池化操作和全局最大池化操作对输入的特征图进行压缩,得到两个一维特征向量。然后将这两个一维特征向量分别输入到含有隐藏层的多层感知机网络中进行编码,并将编码后的结果使用体素级加和操作后经过sigmoid激活操作输出,输出结果为一个通道权重的表示向量;
[0028]
通道注意力的计算如下:
[0029]
mc(f)=σ{x
mlp
[(x
avgpool
(f)] x
mlp
[x
maxpool
(f)]},
[0030]
mc(f)=σ{w1[w0(f
c,avg
)] w1[w0(f
c,max
)]},
[0031]
式中:f表示输入的特征图,σ表示sigmoid函数;x
avgpool
(
·
)表示平均池化函数;x
maxpool
(
·
)表示最大池化函数;
[0032]fc,avg
和f
c,max
分别表示经过平均池化和最大池化后的特征图;w1和w0表示mlp中的两层参数;
[0033]
进一步的,在步骤4.1中,所述空间注意力模块中:
[0034]
将输入的特征矩阵首先在通道维度上进行全局平均池化和全局最大池化后得到两个空间特征矩阵;将这两个空间特征矩阵拼接,拼接后的特征矩阵经过一个卷积核大小为7
×7×
7,步长为1的卷积操作后再经过sigmoid激活函数输出,生成空间注意力特征图;
[0035]
空间注意力的计算如下:
[0036]ms
(f')=σ{f7×7×7[x
avgpool
(f');x
maxpool
(f')]},
[0037]ms
(f')=σ[f7×7×7(f
s,avg
;f
s,max
)],
[0038]
式中:σ表示sigmoid函数,f'表示输入的特征图,f
s,avg
和f
s,max
分别表示经过平均池化和最大池化后的特征图;f7×7×7表示7
×7×
7的卷积运算。
[0039]
进一步的,在步骤4.2中,所述损失函数:
[0040]
采用tversky损失函数,可以表示为:
[0041]
lc=∑(1-ic),
[0042]
其中,
[0043][0044]
式中:c表示病灶类;g
ic
∈{0,1}和p
ic
∈{0,1}分别表示真实标签和预测结果;和分别表示真实标签和预测结果中的背景体素;g
ic
表示分割结果中的假阴性;p
ic
表示分割结果中的假阳性;n表示图像中的总体素数;ε表示一个可以自由选择的常数;α和β分别表示控制假阴性和假阳性的惩罚力权重,其中一个权重的增长就会增加与权重相关的错
误类型的惩罚;将α设为0.7,β设为0.3。
[0045]
作为本发明的一种改进,在步骤4.1中,所述多尺度融合包含多尺度卷积模块和混合下采样模块,使模型具有更多尺度的特征提取和融合能力。
[0046]
作为本发明的一种改进,所述多尺度卷积模块包含的3条卷积支路分别具有1
×1×
1、3
×3×
3和5
×5×
5的感受野,这3条支路卷积后再叠加使得多尺度卷积模块具有三个不同尺度的特征提取和融合能力,以及计算量小的优点。
[0047]
作为本发明的一种改进,在步骤4.1中,所述混合下采样模块包含两条下采样支路,一条采用采样步长为2的最大池化进行下采样,另一条采用步长为2,卷积核大小为3
×3×
3卷积操作对图像进行过滤,其效果等同采样步长为2的下采样,但可以保留采样步长范围内的细节特征,而最大池化保留的是采样步长范围内的最大特征;两条支路的输出通过步长为1,卷积核大小为1
×1×
1卷积操作融合后,使网络在下采样时保留粗、细两种不同尺度的信息,实现信息的相互补偿,避免下采样过程中的信息丢失。
[0048]
作为本发明的一种改进,在步骤4.1中,所述拆分注意力是将原有注意力机制中的空间注意力和通道注意力拆分使用。原有注意力机制由于将空间注意力和通道注意力联合使用,其计算代价较高,且没有针对性地发挥两种注意力的优势。我们根据浅层特征偏向于空间信息、深层特征偏向于语义信息的特点,以及空间注意力偏向于空间关注、通道注意力偏向于语义关注,将两种注意力拆分使用,分别用于模型编码部分的不同阶段,使注意力更具有针对性,从而提高网络对目标的关注能力,且计算代价较低。
[0049]
作为本发明的一种改进,在步骤4.1中,所述基于多尺度融合和拆分注意力的脑白质高信号分割模型的解码子模块中采用连续2个带有残差连接的卷积操作,以避免训练过程中的梯度消失和模型过拟合。
[0050]
作为本发明的一种优选改进,在步骤4.2中,所述损失函数采用与以往多数方法不同的损失函数——tversky损失函数,来优化模型训练,解决样本不平衡所致的假阴性过多问题以提升模型对病灶的敏感性。
[0051]
相对于现有技术,本发明具有如下有益效果:
[0052]
(1)本发明所述的基于多尺度融合和拆分注意力的脑白质高信号分割方法能有效提高wmh分割准确率,特别是对细小病灶有很好的识别和分割能力。本发明对其他医学影像的分割同样具有参考意义,对推进脑部疾病的计算机辅助诊断也具有积极意义。
[0053]
(2)模型在编码阶段加入多尺度卷积模块以增加网络宽度,使模型具有多尺度特征提取能力,同时,在编码阶段加入混合下采样模块,使网络在下采样时保留粗、细两种不同尺度的信息,防止下采样带来的细节信息丢失,两个模块的同时使用使模型具有较强的多尺度特征提取能力,可显著提升细小病灶的识别。
[0054]
(3)模型在编码阶段采用拆分注意力机制,不仅降低了计算代价,而且提高了网络对目标的关注能力,有助于提高wmh分割准确率。
[0055]
(4)模型在解码阶段采用带有残差连接的卷积操作,可以避免训练过程中的梯度消失和模型过拟合。
[0056]
(5)模型在训练过程中使用tversky损失函数,有效解决了由于样本不平衡所致的分割结果假阴性过多的问题,提升了模型对病灶识别的敏感性。
附图说明
[0057]
图1为本发明融合多尺度特征提取和分散注意力的脑白质高信号分割模型整体结构示意图;
[0058]
图2为本发明多尺度卷积模块结构示意图;
[0059]
图3为本发明空间注意力模块示意图;
[0060]
图4为本发明通道注意力模块示意图;
[0061]
图5为本发明混合下采样模块示意图;
[0062]
图6为本发明脑白质高信号flair图像;
[0063]
图7为本发明图6对应的人工标注的分割标签(金标准);
[0064]
图8为本发明图6对应的模型自动分割的结果。
具体实施方式
[0065]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图1-6和具体实施方式对本发明作进一步详细的说明。
[0066]
本发明提供了一种基于多尺度卷积和分散注意力的脑白质高信号分割方法,该方法具体包括如下步骤:
[0067]
步骤1、获取脑白质高信号flair图像数据集;
[0068]
具体的,所述脑白质高信号flair图像数据集来自于miccai2017wmh分割挑战赛公开的数据集,该数据集包括60例脑白质高信号患者的脑部flair图像数据和由专家标定的wmh区域的标签数据。该flair图像数据是从三家医院不同扫描仪下采集得到,每家医院提供20例数据,共60例。获取到的脑白质高信号flair图像数据已由提供方做过偏移场校正的预处理。flari图像的格式为nifti,标签图像的格式均为nifti。三家医院的数据大小分别为132
×
256
×
83、240
×
240
×
48、256
×
232
×
48。
[0069]
步骤2、对获取到的数据集进行划分,分成训练集、验证集和测试集;
[0070]
具体的,将60个样本按照8:1:1的比例分成训练集(包含48个样本)、验证集(包含6个样本)和测试集(包含6个样本)。
[0071]
步骤3、对获取到的样本数据集进行预处理;
[0072]
首先,将获取的flair图像数据及标签数据的尺寸调整为统一的192
×
192
×
16;其次,取训练集中的48例样本进行数据扩增处理,扩增方式包括对每例样本分别进行水平翻转、4次不同角度旋转和3次仿射等变换处理,扩增后生成新样本336例;然后,对扩增后的384例训练样本集、测试集、验证集数据做归一化处理。
[0073]
步骤4、对所述基于多尺度融合和拆分注意力的脑白质高信号分割模型进行构建和训练;
[0074]
s4.1、构建如图1所示的基于多尺度融合和拆分注意力的脑白质高信号分割模型;
[0075]
模型包括编码部分和解码部分。
[0076]
编码部分由三个具有同样结构的特征提取子模块及一个瓶颈层组成。
[0077]
第1编码层的特征提取子模块包含2个多尺度卷积模块如图2所示,其卷积通道数
为16,1个空间注意力模块,如图3所示,其卷积通道数为16和1个混合下采样模块,其卷积通道数为16;
[0078]
第2编码层的特征提取子模块包含2个多尺度卷积模块,如图2所示,其卷积通道数为32,1个空间注意力模块,如图3所示,其卷积通道数为32和1个混合下采样模块,其卷积通道数为32;
[0079]
第3编码层的特征提取子模块包含2个多尺度卷积模块,如图2所示,其卷积通道数为64,1个通道注意力模块,如图4所示,其卷积通道数为64和1个混合下采样模块,其卷积通道数为64;
[0080]
瓶颈层包含2个多尺度卷积模块,如图2所示,其卷积通道数为128,1个通道注意力模块,如图4所示,其卷积通道数为128;
[0081]
解码部分由三个具有同样结构的解码子模块和1个像素分类层组成。
[0082]
第1解码层包含1个通道数为64、卷积核大小为3
×3×
3的反卷积和2个带有残差连接的64通道的3
×3×
3卷积。其中,反卷积结果与第3编码层的通道注意力模块的输出进行拼接;
[0083]
第2解码层包含1个通道数为32、卷积核大小为3
×3×
3的反卷积和2个带有残差连接的32通道的3
×3×
3卷积。其中,反卷积结果与第2编码层的通道注意力模块的输出进行拼接;
[0084]
第3解码层包含1个通道数为16、卷积核大小为3
×3×
3的反卷积和2个带有残差连接的16通道的3
×3×
3卷积。其中,反卷积结果与第1编码层的通道注意力模块的输出进行拼接;2个带有残差连接的卷积的输出结果被传递给1个通道数为1的3
×3×
3卷积后经过softmax激活函数进行像素级分类,其输出即为最终的分割结果。
[0085]
s4.2、将预处理后的训练集、验证集图像数据输入到构建好的模型中进行训练。
[0086]
具体的,首先,进行训练前的模型超参数设置,包括定义损失函数为tversky损失函数;设置学习率为0.0001;优化模式采用用adam随机梯度下降优化器;设置迭代次数(训练轮次)epoch=400次。终止条件采用当验证集上的损失函数值在10个迭代周期内不再减小时停止训练。
[0087]
其次,将预处理后的训练集、验证集图像数据输入到构建好的基于多尺度融合和拆分注意力的脑白质高信号分割模型中进行训练。在该训练过程中,将训练集图像输入模型进行多轮次的训练,并基于验证集对每一轮次的训练结果进行验证,当训练满足终止条件时,得到模型在该训练集下的最优权值参数,此时停止训练,得到训练好的分割模型,并保存模型参数。
[0088]
步骤5、将测试集中的每个图像输入到已经训练完成的基于多尺度融合和拆分注意力的脑白质高信号分割模型中进行测试;
[0089]
s5.1、将训练好的模型在测试集上进行测试与显示
[0090]
得到测试集中每例样本的分割结果的二值图。图6是测试集中某一例flair图像的轴向位切片图像;图7是其对应的人工标注的分割标签(金标准);图8是本发明所提模型的分割结果。从图7与图8的对比可以看出,本发明所述基于多尺度融合和拆分注意力的脑白质高信号分割方法能很好地将细小病灶分割出来,且整体分割效果与金标准接近。
[0091]
s5.2、对测试结果进行评估
[0092]
本实施例使用三项常用的评价指标对测试结果进行评估,分别是:dsc(dice similarity coefficient)、召回率(recall)、精度(precision)。召回率反映实际为脑白质病变的体素中被正确分割出的比例,用来衡量脑白质病灶分割的完整性。精度反映分割的体素中实际为脑白质病变的比例,用来衡量脑白质病灶分割的精确度。dsc是对病灶图像的整体分割性能的一种评估,其值反映分割结果与真实标签之间的相似度,dsc值越大,分割结果越接近于真实标签。具体公式可表示为:
[0093][0094][0095][0096]
式中:x
tp
表示真实标签为脑白质病变类且被分割为脑白质病变类的体素个数;x
fp
表示真实标签为非脑白质病变类但被分割为脑白质病变类的体素个数;x
fn
表示真实标签为脑白质病变类被分割为非脑白质病变类的体素个数。
[0097]
按照上述公式,对本发明模型在测试集上得到的分割结果进行评估,计算得到recall=0.84;precision=0.77;dsc=0.79。
[0098]
s5.3、与现有技术方法的对比
[0099]
将本发明所提供的基于多尺度融合和拆分注意力的脑白质高信号3d u-net分割方法与现有几种主流用于wmh分割的方法进行了对比,对比结果如表1所示。
[0100]
表1
[0101][0102]
表1中所有方法使用的数据集均源自miccai2017 wmh分割竞赛的公开数据集。从表中可以看出,本发明所提供wmh分割方法相比其他方法各项评估指标最优。相比现有方法中各项指标的最优值,本发明提出的模型的精度提高3%,dsc提高1%,召回率提高1%。从表中可以明显看出,本发明提出的网络取得了优异的结果。
[0103]
本发明针对提升小病灶区域的分割及wmh分割的精准率,在3du-net的模型基础上做了以下改进:
[0104]
(1)利用多尺度卷积模块扩展3d u-net模型的宽度,使模型具有多尺度的特征提取感受野,增强特征提取能力;
[0105]
(2)使用混合下采样替代原有的最大池化,使网络在下采样时保留粗、细两种不同尺度的信息,防止下采样带来的细节信息丢失;
[0106]
(3)在编码阶段采用拆分注意力机制,有针对性地发挥空间注意力和通道注意力
各自的优势,提高网络对目标的关注能力;
[0107]
(4)在解码阶段采用带有残差连接的卷积操作,避免训练过程中的梯度消失和模型过拟合。
[0108]
(5)使用tversky损失函数优化训练,控制假阴性和假阳性之间的平衡,提升模型对病灶区域的敏感性。
[0109]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
