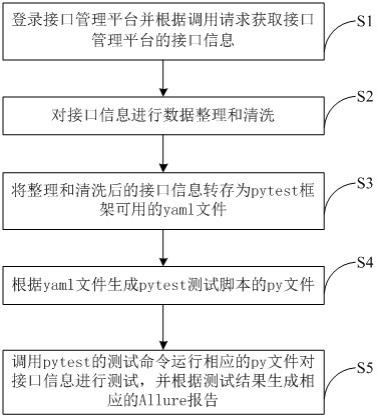
1.本发明属于计算机软件技术领域,涉及视频中的语言片段定位技术,具体为一种基于对比学习的视频中语言片段定位时序方法及装置。
背景技术:
2.视频中的语言片段时序定位是计算机视觉领域的一个重要研究任务,其目的是通过一句自然语言查询一个长视频中与这句话匹配的片段。视频中的语言片段定位在现实场景中有广泛的应用前景,例如在一段长电影中通过自然语言查找一段具体的情节,或以自然语言为键值对广告场景中的视频片段进行组织从而形成素材体系。
3.目前的常用方法是分别提取视频特征与自然语言特征后进行特征融合,然后直接进行时序检测,其类别为简单的二分类。这种情况下,由于与一句自然语言匹配的视频片段正样本只有一个,而与自然语言不匹配的视频片段负样本过多,即除正样本片段外,整个视频其他部分均为负样本,很容易造成时序检测的效果不佳的情况;并且,在融合过后的多模态特征上直接进行时序检测的可解释性较弱,模型只能输出视频中每个位置属于视频片段正样本的置信度曲线,而不能显式地给出语言和视觉两个模态之间特征的相似度。更加重要的是,现有方法的训练过程中使用的监督信号都是利用一句自然语言去匹配视频中的正样本片段,抑制其他负样本片段。这样的监督信号是受限的,即作为一个多模态任务,现有技术方法只有自然语言匹配视频片段的过程,而没有视频片段匹配自然语言的过程。也就是说,只有视频模态的负样本,而没有自然语言描述的负样本,这种单一方向的监督信号,即语言的正样本在视频的正负样本中匹配正确的样本这种单一监督,会导致视频和语言之间匹配的监督信号不够全面,而没有完整的利用所有可用的监督信号,从而导致匹配的准确性较差。本发明就此提出一种新的方法,完整利用两个方向的监督信号,包括语言的正样本在视频片段的正负样本中匹配正确的样本,并且视频片段的正样本在语言的正负样本中匹配正确的样本,从而大幅提升视频中的语言片段时序定位的效果。
技术实现要素:
4.本发明要解决的技术问题是:现有的视频中语言片段定位方法使用特征融合方式,都只能利用从一句自然语言描述匹配视频片段的单一方向的监督信号,而忽视了另一种同样重要的监督信号,即从视频片段匹配多句自然语言描述的监督信号,导致定位检测效果不佳。
5.本发明的技术方案为:一种基于对比学习的视频中语言片段定位方法,建立一个对比与兼容匹配网络来建模句子和视频片段的关系,对比与兼容匹配网络首先分别对句子和视频提取自然语言特征和视频片段特征,然后对自然语言特征和视频片段特征通过映射函数均分别映射到两组联合建模空间里,映射函数分别用于将两种模态的特征降维到同一维度从而实现联合建模的目标,两组联合建模空间对应的映射函数参数不相同,在联合建模空间使用余弦相似度计算自然语言特征和视频片段特征的相似度;训练对比与兼容匹配
网络时,对两个联合建模空间分别使用对比学习损失函数和二分类交叉熵损失函数来监督训练,通过反向传播算法来更新网络参数,直至网络收敛;对待定位的视频片段和自然语言语句,输入训练好的对比与兼容匹配网络,得到两组联合建模空间中的相似度,将它们分别归一化后相乘得到定位置信度,由定位置信度确定最终定位结果。
6.进一步的,对比与兼容匹配网络的实现为:
7.1)自然语言建模网络:使用自然语言特征提取网络distilbert的分词器从句子中提取词级别特征,输入distilbert得到具有句子全局信息的词级别特征序列,使用全局平均池化和层归一化的方法得到句子的特征向量,即自然语言特征;
8.2)视频片段建模网络:对由视频获取的固定长度的视觉特征序列,使用最大值池化的方法得到一个二维特征图来表示所有的候选定位框的特征,使用多层二维卷积网络对候选定位框的邻域信息建模,得到最终二维特征图,作为每个候选定位框的最终特征,即视频片段特征;
9.3)联合建模空间:将自然语言特征和视频片段特征均降维映射到两组联合建模空间中,自然语言特征采用单层全连接层为映射函数,视频片段特征使用1x1卷积为映射函数,两组联合建模空间对应的映射函数具有不同参数,在联合建模空间中使用余弦相似度计算句子和候选定位框的相似度,衡量两者的匹配程度;
10.4)训练阶段:对两组联合建模空间的相似度分别使用对比学习损失函数和二分类交叉熵损失函数进行监督,使用adamw优化器,通过反向传播算法来更新网络参数,不断重复步骤1)至4)训练对比与兼容匹配网络,直到网络收敛。
11.本发明还提供一种基于对比学习的视频中语言片段定位的装置,所述装置具有存储介质,存储介质中配置有计算机程序,所述计算机程序被执行时实现上述语言片段定位方法的对比与兼容匹配网络。
12.本发明提出从另一个角度来审视视频中的语言片段时序定位任务,不再进行视频和语言特征的融合,而是将语言片段时序定位这个任务看作是一个度量学习问题,将视频和语言特征分别投射到同一片空间中,通过特征的相似度进行视频和语言特征的匹配。本发明有以下几个优点:(1)通过将时序定位任务看作是一个度量学习问题,本发明将这个问题的监督信号拓展为视频和自然语言的双向匹配:即,对于一句自然语言描述的正样本,一组视频片段的正样本和负样本会提供监督信号,这也是现有方法常用的监督信号;对于一个视频片段的正样本,一组自然语言描述的正样本和负样本会提供监督信号,这是现有方法由于使用了特征融合而无法使用的监督信号,但是在本发明的度量学习框架下,本发明提出了使用这种全新的监督信号。(2)通过解耦语言和视觉两个模态的特征提取网络,本发明可以通过对一个视频中多个自然语言描述之间共用视频特征从而减少训练时长;而现有技术方法都需要对每一句话重复提取视频特征。基于以上两个优点,本发明方法在提高视频中的语言片段定位任务的效果的同时也减少了训练时的开销。
13.本发明与现有技术相比有如下有益效果:
14.本发明提出了一种同时使用对比学习和iou回归的视频中语言片段定位方法,可以对于视频中的候选定位框和自然语言语句之间的相似性进行有效建模,相比于只使用iou回归的方法取得明显的效果提升。
15.本发明提出了在语言和视觉两个模态的关系建模时使用后融合替代原有的先融
合,使得在多个自然语言语句之间实现视频特征的复用,从而在网络训练速度上取得了大幅提升。本发明提出的方法训练收敛时所需的时间是基线方法的30%以内。
附图说明
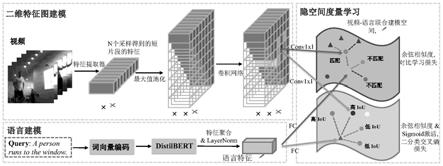
16.图1是本发明所使用的框架图。
具体实施方式
17.本发明提出将视频中语言片段定位方法视作一个度量学习问题,提出对比与兼容匹配网络(contrastive and compatible matching network,c2m
‑
net)来直接建模自然语言描述和视频片段的关系。具体来说,本发明在现有技术的基线模型2d
‑
tan网络上进行了两点主要的修改:(1)对于网络结构,本发明将语言和视觉模态的早融合(early
‑
fusion)改为了晚融合(late
‑
fusion),也就是将在网络前部利用逐元素相乘融合两个模态的特征,改为在最后一层利用余弦相似度(cosine similarity)建模两个模态之间的关系,从而解耦了两个模态的建模过程,使得两个模态之间的双向匹配成为可能。(2)对于损失函数中使用的监督信号,本发明在现有技术的基于交并比iou的二分类交叉熵损失函数(binary cross entropy loss)之外,增加了一个新的分支进行对比学习损失函数(contrastive loss)的监督信号进行训练,显著提高了网络的检测效果。
18.下面具体说明本发明的实施。
19.本发明提出了一种基于对比学习的视频中语言片段时序定位方法。在charades
‑
sta,activitynet
‑
captions,tacos,didemo语言片段时序定位数据集上的训练和测试达到了高准确性,具体使用python3编程语言,pytorch 1.3.0深度学习框架实施。
20.本发明通过对比与兼容匹配网络来建模句子和视频片段的关系,首先对句子和视频提取自然语言特征和视频片段特征,然后将两种特征均分别映射到两组联合建模空间里,在联合建模空间使用余弦相似度计算两种特征的相似度;分别使用对比学习损失函数和二分类交叉熵损失函数来监督训练网络;对待定位的视频片段和自然语言语句,输入训练好的对比与兼容匹配网络,得到两组联合建模空间中的相似度,计算得到定位置信度,由定位置信度确定最终定位结果。图1是本发明所使用的系统框架图,本发明方法的总体步骤包括视觉特征序列提取,网络配置阶段,训练阶段和测试检测阶段,为方便说明本发明的技术方案,以下将对比与兼容匹配网络的网络配置阶段拆为了步骤2至4进行说明,具体实施步骤如下。
21.1)视觉特征序列提取:使用特征提取网络c3d提取视频时序特征,通过双线性插值得到固定长度的特征序列。本发明实施例预先提取好activitynet
‑
captions数据集视频帧存储在硬盘上,一个视频总共有t帧,对于第i帧,以该帧为中心,大小为16帧的窗口的rgb帧作为三维特征提取网络c3d的输入。然后将该特征提取网络c3d的倒数第二层的输出(即fc7层)得到的4096维向量作为第i帧的特征。对于所有t帧提取特征后,得到一个关于此视频的长度为t,维度为4096的特征序列,将其存储。视觉特征序列提取网络不参与对比与兼容匹配网络训练的梯度回传过程。
22.其中,视觉特征序列提取的输入具体组成形式为:
23.以rgb图片为输入,以第n帧为中心,训练样本视频片段的帧序列i
rgb
如下:
24.i
rgb
={img
n
‑8,img
n
‑7,
…
,img
n
‑1,img
n
,img
n 1
,
…
,img
n 6
,img
n 7
},
25.其中img
n
代表训练样本视频片段中对应的第n帧,通道数为3。
26.2)自然语言建模网络:对应于图1中的语言建模部分。由于distilbert相比于其他常用的大规模预训练语言模型更加轻量级的模型容量,本发明使用它作为自然语言特征提取器并参与对比与兼容匹配网络的梯度回传。对于每个包含l
s
个词的输入句子s,首先通过distilbert对应的分词器生成单词的标记token,根据标记token在单词开头添加一个类嵌入标记“[cls]”从而将一句话转换为一个词向量级别的特征序列。然后将得到的词向量级别特征序列输入经过预训练的distilbert模型以获得包含语句语义信息的特征序列其中每个为一个维度为768的特征向量。distilbert含有6层transformer encoder layer,相比于原始bert的12层transformer encoder layer来说参数量得到了极大的减少,它能够在比bert的参数量减少40%,速度加快60%的情况下保持97%的综合自然语言性能。在通过distilbert得到一个和原始句子同样长度的特征向量序列后,有两种常见的聚合方法来获得整个句子的特征:1)所有特征向量的全局平均池化;2)直接使用类嵌入“[cls]”的特征向量。
[0027]
1.使用全部词向量级特征的全局平均池化作为整个句子的特征时,句子级特征如下:
[0028][0029]
是distilbert输出的第i个词向量级特征,l
s
是词向量级特征的个数,layernorm代表层归一化layer normalization。
[0030]
2.直接选用
‘
[cls]’的特征向量作为整个句子的特征时,句子级特征如下:
[0031][0032]
是distilbert输出的第1个词向量级特征,即
‘
[cls]’的特征向量,layernorm代表层归一化layer normalization。
[0033]
本发明在实验中对比了两种聚合方法的性能,发现全局平均池化在此任务中具有收敛速度更快和性能更好的优点,所以默认采用平均池化。
[0034]
在聚合整个句子的特征后,使用层归一化layer normalization的方法对特征进行归一化处理,从而使得网络在训练时更加稳定。将经过层归一化的768维特征向量作为每个自然语言句子的最终特征,即自然语言特征。
[0035]
3)视频片段建模网络:对应于图1中的二维特征图建模部分。对于1)中得到的维度为4096*t的特征序列,首先使用双线性插值对于不同长度的视频得到固定长度n的特征序列,维度为4096*n。然后为了减少显存占用,使用带有relu激活函数的全连接层将特征维度降为d维,从而得到维度为d*n特征序列。基于这份特征序列,通过最大值池化的方法构建一个二维特征图来表示所有的候选定位框的特征,即对于二维特征图上的第i,j个元素,使用d*n特征序列上的从第i个特征到第j个特征在时序维度上进行最大值池化,得到一个维度为d的特征向量作为二维特征图上的第i,j个元素的特征。基于这份维度为d*n*n二维特征图,使用l层卷积核大小为k的二维卷积进行候选框的邻域信息建模,得到一个d*n*n的最终
二维特征图,作为对于每个候选定位框的最终特征。
[0036]
以下详细说明用于候选框的邻域信息建模的二维卷积的细节。从公式上来讲,我们一般把二维卷积的卷积核表示为conv(x,k,h,s),其中x为输入的特征图,k为卷积核大小,此处的二维卷积核即为k*k的正方形,h为输出的特征图维度,即卷积核数量,s为卷积核移动的间隔。因此,用于候选定位框的邻域信息建模的二维卷积网络由l层conv(x,k,256,1)组成,其中k的大小在具体数据集上通过实验结果选取。在二维时序候选定位框特征图中,k决定了领域信息建模中的感受野,因此k越大时模型能够看到与自己更远的候选框的信息,k越小时模型只能够看到与自己相邻的候选框的信息。一般来说对于片段较长的数据集我们使用较大的k,对于片段较短的数据集我们使用较小的k,实验中我们对于不同的数据集分别采用了5,7,9。
[0037]
4)联合建模空间:对应于图1的隐空间度量学习部分。在得到自然语言特征和视频片段特征后,通过映射函数均分别映射到两组联合建模空间里,本发明优选使用一个单层全连接层作为自然语言特征的映射函数,并且使用一个1x1卷积作为视频片段特征的映射函数,将两个模态的特征映射到同一个片联合建模空间里。本发明使用对比学习损失函数和二分类交叉熵损失函数来共同训练自然语言建模网络和视频片段建模网络,为了同时实现对比学习与iou回归学习,本发明使用了两组维度和结构完全相同的联合建模空间,但是这两组将自然语言特征或者视频候选框特征映射到联合建模空间的映射函数参数不相同,以得到分别建模两种不同相似度的效果。
[0038]
联合建模空间中的映射函数的具体形式为:
[0039]
句子级自然语言特征使用的映射函数如下:
[0040][0041][0042]
w
iou
与b
iou
是二分类交叉熵损失函数所在空间的映射函数的线性变换参数,w
c
与b
c
是对比学习损失函数所在空间的映射函数的线性变换参数,f
s
为自然语言特征,和分别为自然语言特征在两组联合建模空间的映射结果,两组参数都通过梯度回传自动学习。代表经过映射之后的维度大小。
[0043]
候选定位框特征使用的映射函数如下:
[0044][0045][0046]
f为视频片段特征,conv
iou
(.,1,1)和conv
c
(.,1,1)分别表示二分类交叉熵损失函数和对比学习损失函数所在空间的1x1卷积核,和分别为视频片段特征在两组联合建模空间的映射结果,两组卷积核的参数都通过梯度回传自动学习。代表经过映射之后的维度大小。
[0047]
在联合建模空间里,每个特征向量代表一个自然语言句子或者一个视频候选定位框,其中自然语言特征经映射函数后映射为联合建模空间的一个d维向量;视频片段特征为一个d*n*n的最终二维特征图,n为视觉特征序列长度,即每个视频具有n*n个d维的向量,除
去一半不合法的候选位置,即d*n*n的最终二维特征图中时序上开始比结束更迟的下三角矩阵位置,本发明保留n*n/2个d维的向量;每个句子在经过全局平均池化后得到一个d维的向量。在实际实施中,为了减少显存占用,本发明进一步使用了一种稀疏采样的方式在n*n/2个候选框的基础上进一步减少候选框的数量。所述洗漱才有具体为:对于n<=16的情况,不进行稀疏采样;对于n>16的情况,使用如下公式进行稀疏采样:设每次采样的区间为[a,b],其中a=2
k
,b=2
k 2
,k的取值从4开始,即a从16开始,每次k增加2,至b=n结束,从而覆盖16至n的全部区间;对于当前稀疏采样的区间[a,b),采样的间隔为即对于[a,b)区间内的梯形区域采样主对角线方向的斜线,每的大小内只采样一条斜线。主对角线方向的斜线的定义为第一行被采样的元素开始,沿着45
°
线从左上至右下到达最后一列中某个元素的线,例如[a,b)区间中第一条斜线为从矩阵中(1,a)元素开始,依次经过(t,a t)等元素,t=2,3,4
…
,到达(n
‑
a,n)元素的一个序列;第二条斜线为从矩阵中(1,a 1)元素开始,依次经过(t,a t 1)等元素,到达(n
‑
a
‑
1,n)元素的一个序列;最后一条斜线为从矩阵中(1,b
‑
1)元素开始,依次经过(t,b
‑
1 t)等元素,到达(n
‑
b 1,n)元素的一个序列。具体举例,例如,对于16*16的特征图,保留全部16*16/2个候选框;对于32*32的特征图,对沿着主对角线方向(即左上至右下)的前16条斜线保留全部候选框,对于后16条斜线只等距采样8个斜线;对于64*64的特征图,对沿着对角线方向的前16条斜线保留全部候选框,对第16至32条斜线只等距采样8个斜线,对第32至64条斜线只等距采样8个斜线;对于128*128的特征图,对沿着对角线方向的前16条斜线保留全部候选框,对第16至32条斜线只等距采样8个斜线,对第32至64条斜线只等距采样8个斜线;对第64至128条斜线只等距采样8个斜线。
[0048]
联合建模空间映射完成后,本发明使用余弦相似度(cosine similarity)来衡量语言和视觉两个模态特征的相似度,即任意一对句子
‑
候选框对的匹配程度,优选先对句子和候选框特征进行欧式空间的特征归一化,再做内积实现余弦相似度的计算。
[0049]
两个模态在两个联合建模空间中的相似度分数计算如下:
[0050][0051][0052]
其中c和iou分别代表两个联合建模空间,c对应于对比学习损失函数的空间,iou对应于二分类交叉熵损失函数的空间,s
iou
和s
c
分别为两个联合建模空间的相似度,在计算内积之前使用l2归一化将特征向量归一化为一个单位向量,即从而使得内积成为余弦相似度。
[0053]
5)训练阶段:在步骤4)中说明的两个联合建模空间中,分别使用对比学习损失函数和二分类交叉熵损失函数作为监督,来共同训练步骤2)与步骤3)的网络,两个损失函数通过共享两个模态的主干网络(backbone network)来实现训练过程中的相互促进。
[0054]
二分类交叉熵损失函数与对比学习损失函数的具体形式分别为
[0055]
1.二分类交叉熵损失函数如下:
[0056]
[0057][0058]
其中是二分类交叉熵的联合建模空间的余弦相似度,σ是sigmoid函数,是经过sigmoid函数过后归一化到[0,1]的相似度得分。y
r
是基于iou通过线性函数生成的监督信号,c是二分类交叉熵损失的全部类别,在本发明中是二分类交叉熵的联合建模空间的余弦相似度得分的数量(即时序候选框的数量),l
bce
是二分类交叉熵损失函数计算的结果。
[0059]
2.对比学习损失函数如下:
[0060][0061][0062]
其中f
i
表示特征,i代表第i个正样本, v表示视觉模态, s表示语言模态,上标t代表向量转置,例如代表与f
v
做内积,exp代表e指数运算。此处视觉模态的f
i
从中采样获得,语言模态的即对应句子的p(i
s
∣v)与p(i
v
∣s)为条件概率公式,用于样本的建模,由于本发明使用的是“样本对”,所以两个模态的正样本个数一样,都为p。这两个条件概率的含义为:给定一组视频候选框
‑
语言的正样本对后,网络模型对给定的样本分类为正确的样本级别类别(instance
‑
level class)的置信度,我们需要在损失函数中最大化这个条件概率来使得模型区分正样本与负样本,后面的总损失函数l
c
中通过最小化负的log版本的条件概率来实现这个目的,i
s
代表第i个语言模态正样本的样本级别类别置信度,i
v
对应代表第i个视觉模态正样本定义出的样本级别类别置信度,公式中“∣”符号后的v和s分别表示视觉和语言模态。 p
s
或p
v
分别为在计算第i个正样本时构造的自然语言负样本或视频片段负样本的总数,j为负样本标号。τ
v
与τ
s
分别为视觉模态和语言模态的温度系数,实施例中使用τ
v
=τ
s
=0.1。m是边际系数(margin),用于让正样本的相似度总是比负样本的相似度更高至少m的程度。得到两个模态分别的建模公式后,本发明对于p个视觉
‑
语言正样本对进行求和,即对以上的单个样本对的损失函数进行p次运算并求和,l
c
为求得的对比学习损失函数最终结果,如下式所列:
[0063][0064]
式中p(i
v
∣s
i
)表示第i个视觉模态正样本的样本级别类别置信度与与第i个语言正样本的匹配概率,p(i
s
∣v
i
)同理。
[0065]
3.总体损失函数如下:
[0066]
l=l
bce
λl
c
[0067]
λ是超参数,实验中使用0.005。
[0068]
具体来说,二分类交叉熵损失函数对于每个候选定位框与自然语言语句的相似度
进行回归,监督信号为基于该候选定位框对应的iou构造的0~1之间的数值,该数值可以认为是网络应该将当前候选框认为是正样本的程度,在实际实验中,监督信号为其中t
min
与t
max
根据在具体数据集上的效果选取。二分类交叉熵损失函数的梯度会回传。对比学习损失函数对于每个候选定位框与自然语言语句的相似度进行正负样本的判别:将匹配上的一对候选定位框
‑
自然语言语句作为正样本,并构造如下4种负样本。
[0069]
1)将正样本中的自然语言语句与同一个视频里其他位置上低iou的候选定位框的样本对作为负样本;
[0070]
2)将正样本中的自然语言语句与其他视频中的候选定位框的样本对作为负样本;
[0071]
3)将正样本中的候选定位框与同一个视频里其他自然语言语句的样本对作为负样本,此处我们通过自然语言语句对应的候选定位框之间的iou之间的关系来判断是否具有不合适作为负样本的自然语言语句,具体来说程序会自动从负样本集中删除那些对应的候选定位框与正样本中的候选定位框iou大于0.5的自然语言语句;
[0072]
4)将正样本中的候选定位框与其他视频里自然语言语句的样本对作为负样本。
[0073]
在构建负样本集合时,我们基于一个简单的假设,即同一个视频内时序差距很大的位置之间的语义信息重复的概率很小,不同视频之间的语义信息重复的概率也很小。我们认为只要数据集的规模较大时,负样本集合中含有语义相似的一对候选定位框
‑
自然语言语句的数量会远少于符合我们设想的语义不相似的样本对。对比学习损失函数每次在一批样本(mini
‑
batch)中对于每个正样本对,在同一个视频里采样以上1)与3)的负样本对,并且在这一批其他所有视频中采样以上2)与4)的负样本对。然后利用infonce损失对于一个正样本和多个负样本进行监督,并将梯度回传。
[0074]
对比学习损失与二分类交叉熵损失按照0.005:1的比例加权,对总体loss使用adamw优化器进行优化,初始学习率为5e
‑
4,当损失函数平稳时降低10倍学习率,在8块rtx 2080ti gpu上完成训练,单卡batchsize设置为6,总的训练轮数不超过20轮。为了网络训练过程更好的收敛,在对比学习损失函数不再下降后即停止对比学习损失的监督,只使用二分类交叉熵损失的监督,直到最终训练完成。
[0075]
6)测试阶段:在两个联合建模空间中分别计算两个模态的相似度,可以得到每一对候选定位框
‑
自然语言语句的相似度。对于给定的语句,在两个联合建模空间里分别计算候选定位框与该语句的余弦相似度。由于余弦相似度的范围为[
‑
1,1],将两个相似度都归一化到[0,1]后进行相乘,最后基于相乘得到分数即定位置信度,将一个视频里的所有候选定位框按照定位置信度从大到小排序,根据定位置信度所对应的候选定位框
‑
自然语言语句对,取置信度最好的一个或者五个候选定位框作为预测结果。
[0076]
本发明对上述基于对比学习的视频中语言片段定位方法提供对应的实现装置,所述装置具有存储介质,存储介质中配置有计算机程序,所述计算机程序被执行时实现上述语言片段定位方法的对比与兼容匹配网络。
[0077]
本发明通过对比学习损失函数建模语言和视觉两个模态的双向匹配过程从而极大提高定位的效果,并且为了使得双向匹配成为可能,本发明提出了仅仅在网络最后一层基于余弦相似度的关系建模而不需要在网络前部进行融合。在使用了对比学习损失函数和二分类交叉熵损失函数分别建模句子
‑
候选框的相似度后,本发明取得了比此前方法更好
的效果。根据上述具体实施方式,由测试阶段取最好的一个或者五个候选定位框作为预测结果提交到评估代码中,本发明在activitynet captions数据集上,r@1在iou为0.3,0.5,0.7上分别达到65.05,48.59,29.26;r@5在iou为0.3,0.5,0.7上分别达到87.25,79.50,64.76。在tacos数据集上,r@1在iou为0.1,0.3,0.5上分别达到51.39,39.24,26.17;r@5在iou为0.1,0.3,0.5上分别达到78.03,62.03,47.39。在charades
‑
sta数据集上,r@1在iou为0.5,0.7上分别达到46.61,27.93;r@5在iou为0.5,0.7上分别达到84.54,60.48。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。