基于人体骨架特征的3d卷积神经网络不安全行为检测系统
【技术领域】
1.本发明涉及人体目标检测、人体姿态以及人体行为识别技术领域,具体涉及一种基于人体骨架特征的3d卷积神经网络不安全行为检测系统。
背景技术:
2.在安全生产领域,随着技术的进步发展,设备、场所等所代表的物的不安全状态和环境的不安全因素在安全生产事故原因中的所占比例在逐年下降。如何规范作业人员,降低不安全行为发生的概率,成为当下重要却富有挑战的难题。尽管随着监管力度的加大,相关法令的完善和监控系统的普及,相关问题得到一定的改善,但是安全生产事故数和死亡人数仍然是一个相当大的数字。因此,为了减少安全生产事故,降低事故导致的人员伤亡和财产损失,针对在某些特定作业场所中不安全行为的识别这一领域进行研究有着相当的必要性。
3.以往的监管系统大多依赖于人力,在起初技术不发达阶段,单纯的依靠安全相关人员的监管,受限于监管人员的个人素养和数量问题,漏洞频出。而当前阶段,在安全生产领域已经大量推广普及监控系统,但其中鲜有能够提供对人员进行智能化识别的功能,更无法做到对监控范围内的人员的动作行为进行实时监管,需要由管理人员时刻注意着监控画面,因而仍然存在着较大的漏洞。
技术实现要素:
4.针对现有技术在安全生产领域存在的不足,本发明提供一种基于人体骨架特征的3d卷积神经网络不安全行为检测系统。
5.本发明解决其技术问题采用的技术方案是:发明一种基于人体骨架特征的 3d卷积神经网络不安全行为检测系统,其特征在于,该系统包括如下步骤:
6.步骤一:通过视频采集设备获取实时视频影像;
7.步骤二:采用yolox-tiny算法对所述视频影像中的人进行识别,得到所述视频影像中出现的人的总个数以及各个人的最小矩形包围框的坐标和置信度,设定置信度阈值;
8.步骤三:采用litehrnet算法对经过上述步骤二的处理后的待识别对象进行识别,对其中置信度高于设定阈值的人体最小矩形包围框进行人体姿态估计,获取人体重要骨架关节点坐标,将人体骨架关节点依照人体各肢体关节位置进行串接,形成人体骨架特征向量;
9.步骤四:采用posec3d算法对上述步骤三中的人体骨架特征向量进行行行为识别,判断人员是否存在不安全行为。
10.进一步,上述步骤二中包含:
11.(1)收集典型包含不安全行为的样本视频作为正样本集,并收集其他各类姿态下的人体视频作为负样本集,将各样本集依照coco数据集格式合并为一个数据集,依照8:1:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集、验证集和测试集;
12.(2)所用yolox-tiny算法模型采用cspdarknet为backbone, yoloxafpn为neck,yoloxhead为bbox_head所构建;
13.(3)采用上述数据集对yolox-tiny进行训练,建立具有高鲁棒性的人体目标检测模型;
14.(4)将视频输入的帧图片重置为416
×
416像素分辨率的图片,保留图片原始的位置信息和缩放比例,对于空白部分进行空白填充;
15.(5)根据上述所得目标检测模型对上述输入的帧图片信息预测,获得人体所处矩形包围框坐标信息和预测置信度。
16.进一步,所述的步骤三包括如下:
17.(1)所用litehrnet网络模型采用litehrnet-18为backbone和neck, topdownsimplehead为keypoint_head所构建;
18.(2)采用上述的数据集集对litehrnet网络模型进行训练,建立人体骨架特征向量预测模型;
19.(3)采用上述的输入的帧图片以图片流的形式,连同上述获得的人体所处矩形包围框坐标信息和预测置信度,作为输入,通过上述训练完成后的 litehrnet模型进行预测;
20.(4)在上述输入的图片流中,仅对帧图片中处于步骤三中获得的人体最小矩形包围框范围内的区域进行人体骨架特征向量的预测。
21.进一步,其特征在于,所述的步骤四包括如下步骤:
22.(1)所用posec3d算法模型采用resnet3dslowonly为backbone和neck, i3dhead为class_head所构建;
23.(2)采用上述的数据集对posec3d网络模型进行训练,建立基于人体骨架特征向量的行为识别预测模型;
24.(3)上述所建立的人体骨架特征向量,生成2d姿态图,堆叠t张形状为 k
×h×
w的二维关键点热图以生成形状为k
×
t
×h×
w的3d热图;
25.(4)将上述所获得的3d热图堆叠输入到posec3d模型当中进行识别,以 64帧的实践窗口为时长进行采帧,之后采用均匀采样的方式,将其分成长度相同的n段,在每段中选取一帧,共采集n帧进行行为识别,通过预先训练好的分类器,判断行为是否为不安全行为并进行分类。。
26.与现有技术相比,本发明的有益效果在于:
27.(1)本发明结合了目标识别、人体关键点提取、行为识别等技术,为安全监管人员提供了一种具有实时性的作业人员不安全行为检测的方式;
28.(2)本发明无须使用人体深度信息摄像头来获取人体关键点信息,通过深度学习的方式,仅通过传统rgb视频影像即可获得可信的人体关键点信息并进行不安全行为的识别,能够简单快速的于现有的监控设备相结合;
29.(3)本发明拥有多种检测识别,在应对安全生产场所复杂多变的环境时,仍然具有较高的识别精度和较快的识别速度。
【附图说明】
30.图1为不安全行为检测系统处理流程也是本发明的摘要附图;
31.图2为yolox-tiny算法模型处理流程;
32.图3为人体骨骼特征向量示意图;
33.图4为litehrnet网络模型处理流程;
34.图5为posec3d网络模型处理流程。
【具体实施方式】
35.为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图及发明,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体发明仅仅用以解释本发明,并不用于限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
36.参阅说明书附图,考虑到现有的安全生产作业场所缺少智能化实时检测作业人员行为的监测,而现有大多数的人体行为检测模型是基于时空模型来进行预测,存在着运算量较大,实时性能较差的问题,在大量部署的工业环境中实用性不强。此外,在实际的应用场景中,由于作业环境复杂和繁多的设备,所获取的数据往往是包含有大量干扰的数据。
37.针对产生上述技术问题的根本原因,本技术采用预先训练好的yolox-tiny 算法模型先对采集到的视频影像进行人体识别,得到影像中的人体最小矩形包围框的坐标和置信度之后,再使用litehrnet轻量化网络模型,在对模型进行预训练之后,对上述采集的视频影像中的人体最小矩形包围框进行人体关键点识别,生成人体骨骼特征向量,再基于此通过基于3d-cnn(3d卷积神经网络) 的人体姿态估计模型posec3d网络模型来识别影像中的作业人员是否存在不安全行为,该系统相比传统单一模型,能够大幅减少运算量,从而在保证精度的前提下,实现对安全生产过程中的作业人员的不安全行为的监测。
38.基于上述思考思路,本技术发明提供了一种基于yolox-tiny、litehrnet 和posec3d的不安全行为识别系统。图集请参阅图1所示的根据本技术发明提供的作业人员不安全行为识别系统的处理流程图。本发明提供的不安全行为识别系统,具体包括以下步骤:
39.步骤一:通过视频采集设备获取实时视频影像。
40.s1:本发明中,对于输入的待检测实时视频影像具体可以为作业场所的监控视频,其中,上述待检测的视频数据具体可以由多帧图像数据构成;
41.步骤二:采用yolox-tiny算法对所述视频影像中的人进行识别,得到所述视频影像中出现的人的总个数以及各个人的最小矩形包围框的坐标和置信度,设定置信度阈值;
42.s21:本发明中,所述yolox-tiny算法在训练前需要进行预训练以获得对人体的高识别率,建立具有高鲁棒性的人体目标检测模型,预训练的数据集的选择为:
43.所述数据集将采用coco数据集和mpii human pose数据集(两者包含大量各种姿态的人体图片);
44.对于上述两个数据集,由于其标注信息存在大量类别,本发明仅提取标注信息中的person类bbox信息,并统一处理为coco格式,合并为一个数据集;
45.按照8:1:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集、验证集和测试集。
46.s22:本发明中,所述yolox-tiny算法在预训练完成之后需要针对不安全行为数据集进行针对性训练,提高对于作业场景中具有不安全行为的人体目标识别精度,不安全行
为数据集的选择为:
47.收集典型包含不安全行为的样本图片作为正样本集,并收集其他各类姿态下的人体图片作为负样本集,将各样本集依照coco数据集格式合并为一个数据集;
48.依照8:1:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集、验证集和测试集;
49.s23:本发明中,所述yolox-tiny算法需要对于视频输入帧图片进行处理,将图片重置为416
×
416像素分辨率的,并保留图片原始的位置信息和缩放比例,对于空白部分进行空白填充。
50.s24:本发明中,所述yolox-tiny算法将在所有训练完成后通过对上述处理后的帧图片进行预测,获得人体所处矩形包围框坐标信息和预测置信度。
51.步骤三:采用litehrnet算法对经过步骤二的处理后的待识别对象进行识别。对其中置信度高于设定阈值的人体矩形包围框进行人体姿态估计,得到人体的重要关节点的像素坐标及其预测置信度;
52.s31:本发明中,所述litehrnet网络模型需要进行预训练以获得对人体骨架特征向量的预测模型,训练的数据集的选择为:
53.所述数据集将采用coco数据集和mpii human pose数据集(两者包含大量各种姿态的人体图片);
54.对于上述两个数据集,提取标注信息中的人体关键点信息,并统一处理为 coco person_keypoints格式,合并为一个数据集;
55.按照8:1:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集、验证集和测试集。
56.s32:本发明中,所述lite-hrnet算法在预训练完成之后需要针对不安全行为数据集进行针对性训练,提高对于作业场景中具有不安全行为的人体骨架向量识别精度,不安全行为数据集采用上述s22中所用数据集;
57.s33:本发明中,图4为litehrnet网络模型原理流程图,如图3所示,所述litehrnet网络模型对上述步骤二中处理后的帧图片以图片流的形式,连同上述yolox-tiny获得人体所处矩形包围框坐标信息和预测置信度,作为输入,通过已经完成预先训练的litehrnet网络模型进行预测;
58.s34:图3为人体骨骼特征向量示意图,根据coco数据集提供的17个人体关键点的坐标位置信息的样本标签格式绘注,其中,关键点位分别为:0——鼻子,1——左眼,2——右眼,3——左耳,4——右耳,5——左肩,6——右肩,7——左肘,8——右肘,9——左腕,10——右腕,11——左胯,12——右胯,13——左膝,14——右膝,15——左脚,16——右脚。
59.步骤四:采用posec3d算法对步骤三中的人体关节图进行行为识别,判断人员是否存在不安全行为;
60.s41:在本发明中,基于上述litehrnet所测得的人体骨骼特征向量,生成 2d姿态图,并堆叠t张形状为k
×h×
w的二维关键点热图以生成形状为k
×ꢀ
t
×h×
w的3d热图,其中k是关节的数量,h和w分别是帧图片的高度和宽度。由于已经给出了人体骨骼特征向量,因此在其他地方以零进行填充,来匹配帧图片的大小。通过合成以每个关节为中心的k个高斯图,可以在仅获得人体骨骼特征向量的情况下得到热图h,具体计算方法为:
61.h_kij=exp((-\[(i-x_k)^2 (j-y_k)^2\])/((2*σ^2)))*c_k
[0062]
其中σ起到控制高斯图的方差的作用,(x_k,y_k)和c_k分别是第k个关节的位置和置信度。于此同时,通过堆叠高斯图也可以用来创建3d人体姿态热图,具体计算方法为:
[0063]
v_ij=exp(-d^2/(2*σ^2))*min(c_i,c_j)
[0064]
其中v_ij是高斯图中某一点的值,即连接第i个和第j个关节的肢体,而d 是该点到链接第i个和第j个关节的肢体的最小距离。由于帧图片中可能存在多人的情况,因此将累积所有人的第k个高斯图,而不放大热图。最后,通过沿时间维度堆叠所有的热图,得到一个3d热图体。
[0065]
s42:在本发明中,采用上述所获得的3d热图堆叠输入到posec3d模型当中进行识别,以64帧的时间窗口为时长进行采帧,之后采用均匀采样的方式,将其分成长度相同的n段,在每段中选取一帧,共采集n帧进行行为识别,通过预先训练好的分类器,进行姿态预测;
[0066]
s43:在本发明中,为了进一步减少3d热图的冗余信息,将采用主题中心裁剪的技术来提高效率。通过所述yolox-tiny算法模型得到的人体最小矩形包围框信息,一次将上述所有帧的2d姿势包围起来,重新调整目标尺寸,在空间维度上减小了3d热图体的大小。
[0067]
s44:在本发明中,所述posec3d网络模型需要进行预训练以获得对人体动作的识别,训练的数据集的选择为:
[0068]
所述数据集将采用nturgb-d动作识别数据集,分为ntu-60和ntu-120,分别包含60个人类动作的57k段视频和120个人类动作的114k段视频
[0069]
使用所述litehrnet网络模型对nturgb-d进行姿态提取,将姿态提取后的人体骨骼特征向量和视频同时作为视频标注信息写入数据集;
[0070]
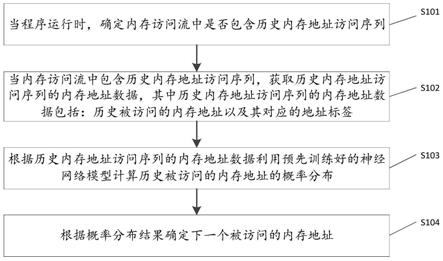
按照8:1:1的比例,将上述两个数据集进行统一处理融合后的数据集划分为训练集、验证集和测试集。
[0071]
s45:本发明中,所述lite-hrnet算法在预训练完成之后需要针对不安全行为数据集进行针对性训练,提高对于作业场景中具有不安全行为的人体行为识别精度,不安全行为数据集采用上述s22中所用数据集;
[0072]
s46:在本发明中,所述posec3d网络模型需要进行预训练以获得对作业人员不安全行为的识别,训练的数据集的选择为:
[0073]
所述数据集将采集典型安全生产作业场所中的不安全行为视频,并将其标注为nturgb-d格式,生成不安全行为数据集;
[0074]
将所述对于nturgb-d的训练权重作为预权重,使用所述litehrnet网络模型对不安全行为数据集进行姿态提取,将姿态提取后的人体骨骼特征向量和视频同时作为输入进行迁移学习训练;
[0075]
s47:在本发明中,将所述处理完成的3d热图体作为输入,使用已经进行训练的posec3d网络模型来对人体动作行为的识别,最后通过cls_head来判断视频影像中的作业人员是否存在不安全行为及其类别。
[0076]
以上所述仅为本发明的较佳发明而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换或改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。