1.本发明涉及粉尘监测与控制技术领域,特别是涉及一种生产性粉尘多参量分布式监测与智能预测方法。
背景技术:
2.工业生产(矿井开采、隧道掘进等)中会产生大量粉尘,可导致粉尘爆炸事故和尘肺病等职业病,严重威胁安全生产和工人职业安全健康,污染生产区域空气和周边大气环境、影响工作效率,降低现代传感与通信技术的感知和传输能力、严重制约智能化作业,降低生产区域能见度,严重制约安全生产。目前现有的传统生产性粉尘监测手段局限于单一参量(浓度)监测与单点式监测,存在大量监测盲区,不能监测粉尘的粒度、速度等重要特征参数及其时空演化状况,成为制约降尘除尘智能化及降尘效果的瓶颈。
技术实现要素:
3.针对现有技术存在的问题,本发明提供了一种生产性粉尘多参量分布式监测与智能预测方法,可以根据粉尘历史数据预测生产区域的粉尘特征参数,弥补了传统粉尘监测方法粉尘感知范围小,监测盲区大的缺点;同时采用了粉尘多场(浓度、粒度、速度)参数传感器对生产区域内的粉尘进行监测,能够同时对粉尘的浓度、粒度、速度进行监测,监测功能完备,能够为高效、精准防尘提供粉尘特征数据。
4.一种生产性粉尘多参量分布式监测与智能预测方法,其特征在于,该方法包括以下步骤:步骤101、在生产区域内布置粉尘特征监测节点,搭建粉尘监测网络;在生产性粉尘监测节点处放置粉尘多场(浓度、粒度、速度)参数传感器,监测并传输粉尘浓度、粒度、速度数据,粉尘监测节点将粉尘浓度、粒度、速度微传感器模块集成于粉尘监测设备内,包括微传感器模块和为装置中各用电模块供电的电源模块;;步骤102、基于多元回归分析方法建立粉尘分布与流场参数的统计模型,挖掘影响粉尘分布的主控因素:生产性粉尘影响因素包括生产强度、作业方式、产尘物体理化性质(脆性、硬度、工业分析组分)等,通过多元回归分析方法从大量粉尘产生影响因素中筛选出对粉尘产生影响最大的因素;步骤103、基于主成因分析方法对由粉尘特征数据(浓度、粒度、速度)以及粉尘主要控制因素组成的大量数据集进行降维,减小数据的体量,制作出原始数据集,便于数据的传输;步骤104、采用基于长短期记忆网络的生产性粉尘特征参数预测模型,对融合粉尘分布主控因素与历史监测数据,对粉尘浓度、速度、粒度多场参数时空演化特性做出智能预测。
5.上述的基于长短期记忆网络的生产性粉尘特征参数预测模型,其特征在于,该方法包括以下步骤:
步骤201、将由步骤103得到的原始数据集进行预处理:通过步骤102的数据多元回归分析,筛选出样本特征参数,选定生产强度、作业方式、产尘物体理化性质等粉尘影响主要因素作为输入层的输入变量 (输入特征),粉尘的浓度、粒度、速度作为输出变量(标签),将相应的输入特征与标签组合起来,得到数据集;步骤202、对数据集d=(x
(1)
,x
(2)
,
……
,x
(m)
)进行归一化处理,得到新的数据集将新的数据集按照7:3的比例划分为训练集和测试集;步骤203、构建预测生产性粉尘特征参数的长短期记忆网络模型:所述长短期记忆网络模型将包含输入层、lstm层l1、dropout层d1、lstm层l2、dropout层d2和输出层;输入层:输入训练集内的粉尘浓度、粒度、速度等相关数据;lstm层l1:训练来自输入层的粉尘浓度、粒度、速度等相关数据,记忆体设置为80个,设定各时间步输出记忆体;dropout层d1:随机丢弃部分来自lstm层l1的记忆体数据,比率设置为0.2;lstm层l2:训练来自dropout层d1的相关数据,记忆体设置为100个,设定仅最后时间步输出记忆体;dropout层d2:随机丢弃部分来自lstm层l2的记忆体数据,比率设置为0.2;输出层:设置3个神经元,与dropout层d2直接连接,输出粉尘的浓度、粒度、速度等相关数据;步骤204、测试经步骤203训练的长短期记忆网络模型,batch_size设置为128,epochs设置为50;步骤205、对预测输出的数据进行反归一化处理,并用预测数据与测试集对应的标签计算出误差。
6.上述的基于长短期记忆网络的生产性粉尘特征参数预测模型,其特征在于,所述lstm层中,输入特征至记忆体的激活函数设置为tanh函数,记忆体至输出特征的激活函数设置为softmax函数;
7.上述的基于长短期记忆网络的生产性粉尘特征参数预测模型,其特征在于,所述误差用预测数据与所对应的实际监测数据之间的均方差来表示
8.与现有技术相比,本发明采用了粉尘特征长短期记忆网络模型进行隧道空气质量状况的预测,方法步骤简单,实现方便;本发明采用了粉尘多场(浓度、粒度、速度)参数传感器对生产区域内的粉尘进行监测,能够同时对粉尘的浓度、粒度、速度进行监测,功能完备;本发明的工作可靠性高,实用性强,使用效果好,便于推广使用。
附图说明
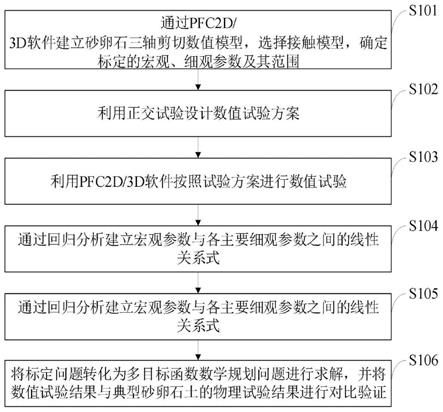
9.图1为生产性粉尘多参量分布式监测与智能预测方法流程图
具体实施方式
10.如图1所示,本发明的生产性粉尘多参量分布式监测与智能预测方法,该方法包括以下步骤:
11.一种生产性粉尘多参量分布式监测与智能预测方法,其特征在于,该方法包括以下步骤:步骤101、在生产区域内布置粉尘特征监测节点,搭建粉尘监测网络;在生产性粉尘监测节点处放置粉尘多场(浓度、粒度、速度)参数传感器,监测并传输粉尘浓度、粒度、速度数据,粉尘监测节点将粉尘浓度、粒度、速度微传感器模块集成于粉尘监测设备内,包括微传感器模块和为装置中各用电模块供电的电源模块;;步骤102、基于多元回归分析方法建立粉尘分布与流场参数的统计模型,挖掘影响粉尘分布的主控因素:生产性粉尘影响因素包括生产强度、作业方式、产尘物体理化性质(脆性、硬度、工业分析组分)等,通过多元回归分析方法从大量粉尘产生影响因素中筛选出对粉尘产生影响最大的因素;步骤103、基于主成因分析方法对由粉尘特征数据(浓度、粒度、速度)以及粉尘主要控制因素组成的大量数据集进行降维,减小数据的体量,制作出原始数据集,便于数据的传输;步骤104、采用基于深度学习的长短期记忆网络构建生产性粉尘特征参数预测模型,对融合粉尘分布主控因素与历史监测数据,对粉尘浓度、速度、粒度多场参数时空演化特性做出智能预测。
12.本实施例中,所述的基于长短期记忆网络的生产性粉尘特征参数预测模型,其特征在于,该方法包括以下步骤:步骤201、将由步骤103得到的原始数据集进行预处理:通过步骤102的数据多元回归分析,筛选出样本特征参数,选定生产强度、作业方式、产尘物体理化性质等粉尘影响主要因素作为输入层的输入变量 (输入特征),粉尘的浓度、粒度、速度作为输出变量(标签),将相应的输入特征与标签组合起来,得到数据集;步骤202、对数据集d=(x
(1)
,x
(2)
,
……
,x
(m)
)进行归一化处理,得到新的数据集将新的数据集按照7:3的比例划分为训练集和测试集;步骤203、构建预测生产性粉尘特征参数的长短期记忆网络模型:所述长短期记忆网络模型将包含输入层、lstm层l1、dropout层d1、lstm层l2、dropout层d2和输出层;输入层:输入训练集内的粉尘浓度、粒度、速度等相关数据;lstm层l1:训练来自输入层的粉尘浓度、粒度、速度等相关数据,记忆体设置为80个,设定各时间步输出记忆体;dropout层d1:随机丢弃部分来自lstm层l1的记忆体数据,比率设置为0.2;lstm层l2:训练来自dropout层d1的相关数据,记忆体设置为100个,设定仅最后时间步输出记忆体;dropout层d2:随机丢弃部分来自lstm层l2的记忆体数据,比率设置为0.2;输出层:设置3个神经元,与dropout层d2直接连接,输出粉尘的浓度、粒度、速度等相关数据;步骤204、测试经步骤203训练的长短期记忆网络模型,batch_size设置为128,epochs设置为50;
步骤205、对预测输出的数据进行反归一化处理,并用预测数据与测试集对应的标签计算出误差。
13.本实施例中,所述基于长短期记忆网络的生产性粉尘特征参数预测模型的lstm层中,输入特征至记忆体的激活函数设置为tanh函数,记忆体至输出特征的激活函数设置为softmax函数;
14.本实施例中,所述算法模型精度用预测数据与所对应的实际数据 d=(x
(1)
,x
(2)
,
……
,x
(m)
)之间的均方差(mes)来表示,
15.需要进一步说明的是,本文中所描述的具体实施例仅仅是对本发明的精神所作的举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或权利要求书所定义的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。