一种基于lstm神经网络的变压器绕组变形识别的方法
技术领域
1.本发明涉及变压器领域,具体涉及一种基于lstm神经网络的变压器绕组变形故障识别方法。
背景技术:
2.近年来变压器的制作工艺和流程在不断优化,但是由于变压器长期运行,总是会出现不同程度的损坏和潜伏性的故障。电力变压器在过载运行以及大短路电流的冲击下,巨大的电磁力对变压器的铁芯、绕组等重要组件产生强大的冲击力,导致部件机械强度减弱,这种故障可能不会马上凸显,但是随着损伤的日积月累,并伴随着部分组件的绝缘老化、劣化,势必引起一些重大故障的出现。因此长期以来,电力部门为确保电力系统的安全运行,及早发现并去除一些早期潜伏性故障,须根据《电力设备预防性试验规程》的要求,对变压器进行定期停电检修和维护。这种机制无疑对防止变压器故障发生、保证变压器可靠运行等方面起到了重要作用,但是停电检修机制往往是按照章程中规定的检修周期,到了一定的时间必须对变压器进行相关的试验项目,而不顾设备当前运行状况,存在较大的盲目性,同时由于部分试验的复杂性以及停电所带来的影响,往往会造成大量人力、财力的浪费,而且长期对一台本就健康的变压器进行检修,无疑会在很大程度上损害系统的稳定性,其后果将导致设备提前损坏的概率明显提高,并可能使得所预防的故障反而提前发生。
3.变压器振动检测法能够发现变压器早期潜在隐患,在变压器正常运行工况下开展与带点系统无直接连接的检测。目前,国内外已有许多关于变压器振动方面的研究成果报道。主要集中在变压器振动测量方法、振动信号以及基于振动的变压器状态评价方法、振动信号分类等方面。
4.通过试验分析了不同测点位置对变压器振动信号测试结果的影响,提出了变压器振动测试过程中测点布置的优选方位;对现场运行变压器振动信号进行测试,并且分析了振动信号的时域与频域特性;对空载、不同功率因数、不平衡负载等条件下的变压器振动信号进行了测试与分析;分析了变压器内部存在结构缺陷条件下,振动信号的特征提取与故障判别方法。然而,以上研究成果均建立在对实验室或运行现场的1台或数台变压器振动信号进行检测的基础上,数据最较为缺乏。由于变压器现场运行条件复杂多变,关于变压器振动特性、振动特征及其普适性等方面的问题需要进一步深入研究。
5.循环神经网络(recurrent neural network,rnn)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,rnn就能够很好地解决这类问题。
技术实现要素:
6.本发明的目的在于提供一种基于lstm神经网络的变压器绕组变形故障识别方法,在变压器振动缺乏时域信号分析工具的情况下,借助于lstm长短期记忆神经网络技术,能够迅速有效的开展时域信号的分析;该方法区别于传统的变压器进行绕组变形识别的方
法,神经网络训练完成后,具有搭建神经网络方便,故障识别效率高等优点。
7.为达到上述目的,根据本发明的一个方面,本发明提供如下技术方案:
8.一种基于lstm神经网络的变压器绕组变形识别的方法,其包括以下步骤:
9.1)对变压器采集到的振动数据进行数据清洗;
10.2)区分直流偏磁与绕组变形,标定绕组变形数据;
11.3)设计lstm神经网络;
12.4)调节神经网络参数,对参数调节后的神经网络参数进行训练;
13.5)采用训练好的神经网络开始验证,将需要故障识别的变压器通过训练好的神经网络进行故障识别。
14.进一步的,所述步骤1)对变压器采集到的振动数据进行数据清洗,具体为,
15.对变压器采集到的振动数据中,基频谐波频率成分比重超过10%的数据标定为系统干扰数据类型,并进行剔除,避免信噪比过低带来的测量误差。
16.进一步的,所述步骤2)区分直流偏磁与绕组变形,标定绕组变形数据,具体为,
17.对数据清洗后的振动数据进行特征值分析,对同时满足奇偶次谐波比《10%与振动熵》3.0的数据标定为绕组变形,
18.其中奇偶次谐波比为
[0019][0020]
式(1)中a
(2i-1)
为第2i-1次基频谐波振动幅值,a
2i
为第2i次基频谐波振动幅值,
[0021]
频谱复杂度,即振动熵为
[0022][0023]
式(2)中ri为第i次基频谐波振动幅值比重。
[0024]
进一步的,所述步骤3)设计lstm神经网络,具体为,
[0025]
3.1)前向传播
[0026]
lstm神经网络的重复部分细胞结构中,有三个门,从对输入的处理顺序来看,先后为遗忘门、输入门、输出门,有三个细胞的输入,分别为上一时刻的细胞状态向量c
t-1
,上一时刻的细胞输出向量h
t-1
和当前时刻的输入向量x
t
,有两个输出,分别为当前时刻的状态向量c
t
和输出向量h
t
;
[0027]
遗忘门f
t
,其前向传播公式为
[0028]ft
=σ(w
(f)
·
x
t
u
(f)
·ht-1
)
ꢀꢀ
(3)
[0029]
其中,w
(f)
为x
t
的权重矩阵,u
(f)
为h
t-1
的权重矩阵,σ(
·
)为sigmoid函数;遗忘门会读取x
t
和h
t-1
并且给上一时刻的细胞状态向量c
t-1
中的每一个元素输出一个0~1之间的数,0表示完全舍弃,1表示完全保留,之间的值表示按比例舍弃;
[0030]
输入门决定有多少信息需要加入到细胞中,其中包括两个步骤,
[0031]
第一步,计算决定需要更新的信息i
t
,决定候选更新的信息
[0032]it
=σ(w(i)·
x
t
u(i)·ht-1
)
ꢀꢀ
(4)
[0033][0034]
其中tanh(
·
)为tanh函数,w(i)为需要更新的信息i
t
对应的x
t
的权重矩阵,u(i)为需要更新的信息i
t
对应的h
t-1
的权重矩阵,w
(c)
为候选更新的信息对应的x
t
的权重矩阵,u
(c)
为候选更新的信息对应的h
t-1
的权重矩阵,i
t
的取值范围为0~1,0表示完全舍弃,1表示完全保留,之间的值表示按比例舍弃,取值范围为-1~1;
[0035]
第二步,通过获取的决定需要更新的信息i
t
和决定候选更新的信息更新细胞的状态,将c
t-1
更新为c
t
,
[0036][0037]ct-1
与f
t
进行元素相乘,得到遗忘后的状态信息,而与i
t
元素相乘,得到决定更新每个状态的程度,其中*代表矩阵(向量)内元素相乘;
[0038]
输出门决定输出的数值,其中包括两个步骤,
[0039]
第一步,通过输出门o
t
决定输出的部分,
[0040]ot
=σ(w
(o)
·
x
t
u
(o)
·ht-1
)
ꢀꢀ
(7)
[0041]
式中,w
(o)
为x
t
的权重矩阵,u
(o)
为h
t-1
的权重矩阵;
[0042]
第二步,c
t
与o
t
元素相乘,得到确定输出的部分,
[0043]ht
=o
t
*tanh(c
t
)
ꢀꢀ
(8)
[0044]
式(3)至式(8)构成了lstm的前向传播公式;
[0045]
3.2)后向传播
[0046]
相较于前向传播公式,后向传播的推导在最后一层加上一个输出,即,
[0047]yt
=σ(w
·ht
)
ꢀꢀ
(9)
[0048]
式中,w为h
t
的权重矩阵,因此所求的参数共有九个权重矩阵,w
(f)
,u
(f)
;w(i),u(i);w
(c)
,u
(c)
;w
(o)
,u
(o)
;w,
[0049]
定义损失函数式中y为实际值,对九个权重矩阵分别求偏导可得到梯度,
[0050]
在更新权重矩阵时选择负梯度方向进行更新。
[0051]
进一步的,所述步骤4)调节神经网络参数中的神经网络参数包括隐藏层,训练次数,hidden_size,dropout。
[0052]
进一步的,所述步骤4)调节神经网络参数,具体为,
[0053]
4.1)调参前准备工作
[0054]
a.首先使用一个数据集,让调节神经网络去训练拟合这个数据集,看看能否做到损失为0/准确率为1;
[0055]
b.在一轮训练中,打印出输入、输出,检测数据的正确性;
[0056]
c.去除正则化项,观察初始的损失值,并对损失进行预估;
[0057]
d.可视化训练过程,在每一轮训练完成后,计算验证集上的损失值与准确率,并记录下每一轮训练集与验证集的损失值,进行每一层的可视化。
[0058]
4.2)调节参数
[0059]
a.在确保了数据与网络的正确性之后,使用默认的参数设置,观察损失值的变化,初步定下各个参数的范围,再进行调参,对于每个参数,在每次的调整时,只去调整一个参数,然后观察损失值变化;
[0060]
b.对于loss的变化情况,主要有以下几种可能性,上升、下降、不变,对应的数据集有train与val,那么进行组合有如下的可能,
[0061]
train loss不断下降,val loss不断下降——网络仍在学习;
[0062]
train loss不断下降,val loss不断上升——网络过拟合;
[0063]
train loss不断下降,val loss趋于不变——网络欠拟合;
[0064]
train loss不断上升,val loss不断上升——网络结构问题;
[0065]
train loss不断上升,val loss不断下降——数据集有问题;
[0066]
4.3)可能性处理
[0067]
当网络过拟合时,采用的方式是正则化(regularization)与丢弃法(dropout)以及bn层(batch normalization);
[0068]
当网络欠拟合时,可以采用的方式是,去除/降低正则化、增加网络深度、增加神经元个数、增加训练集的数据量。
[0069]
与现有技术相比,本发明具有的有益之处是:在变压器振动缺乏时域信号分析工具的情况下,借助于lstm长短期记忆神经网络技术,能够迅速有效的开展时域信号的分析;该方法区别于传统的变压器进行绕组变形识别的方法,神经网络训练完成后,具有搭建神经网络方便,故障识别效率高等优点。
附图说明
[0070]
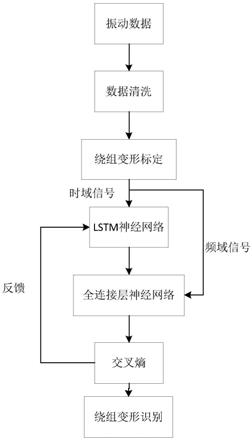
图1为本发明的基于lstm神经网络的变压器绕组变形识别流程图;
[0071]
图2为本发明的数据清洗与绕组变形故障标定流程图;
[0072]
图3为本发明的lstm细胞结构图;
[0073]
图4为本发明的lstm神经网络的设计图;
[0074]
图5为本发明的不同隐藏层数量仿真图;
[0075]
图6为本发明的不同训练次数仿真图;
[0076]
图7为本发明的损失值分布图;
[0077]
图8为本发明的训练值与预测值对比图。
具体实施方式
[0078]
下面结合说明书附图,对本发明作进一步的说明。
[0079]
本发明提供了一种基于lstm神经网络的变压器绕组变形故障识别方法,包括以下步骤:
[0080]
1)对变压器采集到的振动数据进行数据清洗,具体为,
[0081]
对变压器采集到的振动数据中,基频谐波频率成分比重超过10%的数据标定为系统干扰数据类型,并进行剔除,振动信号中的基频谐波一般来源于测试现场的电磁干扰,利用基频谐波的比重可以对测点的信噪比进行初步的筛选,避免信噪比过低带来的测量误差。
[0082]
2)区分直流偏磁与绕组变形,标定绕组变形数据,具体为,
[0083]
对数据清洗后的振动数据进行特征值分析,对同时满足奇偶次谐波比《10%与振动熵》3.0的数据标定为绕组变形,
[0084]
其中奇偶次谐波比为
[0085][0086]
式(1)中a
(2i-1)
为第2i-1次基频谐波振动幅值,所述基频谐波振动幅值可为50hz谐波振动幅值,a
2i
为第2i次基频谐波振动幅值,变压器在发生直流偏磁时,振动信号中的基频谐波,奇次谐波分量增多,利用奇偶次谐波比,可以判断变压器直流偏磁的严重程度。
[0087]
频谱复杂度,即振动熵为
[0088][0089]
式(2)中ri为第i次基频谐波振动幅值比重。
[0090]
频谱复杂度主要表征频谱中频率成分的复杂性,该值越低时,频谱中能量越集中在某些特征频率,该值越高则表明频谱中的能量越分散。
[0091]
3)设计lstm神经网络,具体为,
[0092]
使用的lstm建模的方法为长短期记忆(long short-term memory,lstm)是一种特殊的rnn,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题,简单来说,就是相比普通的rnn,lstm能够在更长的序列中有更好的表现。
[0093]
3.1)前向传播
[0094]
在rnn的内部结构中仅有一个tanh激活函数而显得相当简单,相比较之下lstm的结构和逻辑就更加得复杂,也正是这样才能够有效地控制历史信息的记忆和遗忘。lstm神经网络的重复部分细胞结构图如图3所示,一共有三个门,从对输入的处理顺序来看,依次为输入门(input gate),输出门(output gate)和遗忘门(forget gate),有三个细胞的输入,分别为上一时刻的细胞状态向量c
t-1
,上一时刻的细胞输出向量h
t-1
和当前时刻的输入向量x
t
,有两个输出,分别为当前时刻的状态向量c
t
和输出向量h
t
;
[0095]
从图3中也可以看出遗忘门f
t
,其前向传播公式为
[0096]ft
=σ(w
(f)
·
x
t
u
(f)
·ht-1
)
ꢀꢀ
(3)
[0097]
其中,w
(f)
为x
t
的权重矩阵,u
(f)
为h
t-1
的权重矩阵,σ(
·
)为sigmoid函数;遗忘门会读取x
t
和h
t-1
并且给上一时刻的细胞状态向量c
t-1
中的每一个元素输出一个0~1之间的数,0表示完全舍弃,1表示完全保留,之间的值表示按比例舍弃;
[0098]
输入门决定有多少信息需要加入到细胞中,其中包括两个步骤,
[0099]
第一步,计算决定需要更新的信息i
t
,决定候选更新的信息
[0100]it
=σ(w(i)·
x
t
u(i)·ht-1
)
ꢀꢀ
(4)
[0101][0102]
其中tanh(
·
)为tanh函数,w(i)为需要更新的信息i
t
对应的x
t
的权重矩阵,u(i)为需要更新的信息i
t
对应的h
t-1
的权重矩阵,w
(c)
为候选更新的信息对应的x
t
的权重矩阵,u
(c)
为候选更新的信息对应的h
t-1
的权重矩阵,i
t
的取值范围为0~1,0表示完全舍弃,1表示完全保留,之间的值表示按比例舍弃,取值范围为-1~1。
[0103]
第二步,通过获取的决定需要更新的信息i
t
和决定候选更新的信息更新细胞的状态,将c
t-1
更新为c
t
,
[0104][0105]ct-1
与f
t
进行元素相乘,得到遗忘后的状态信息,而与i
t
元素相乘,得到决定更新每个状态的程度,其中*代表矩阵(向量)内元素相乘;
[0106]
输出门决定输出的数值,其中包括两个步骤,
[0107]
第一步,通过输出门o
t
决定输出的部分,
[0108]ot
=σ(w
(o)
·
x
t
u
(o)
·ht-1
)
ꢀꢀ
(7)
[0109]
式中,w
(o)
为x
t
的权重矩阵,u
(o)
为h
t-1
的权重矩阵。
[0110]
第二步,c
t
与o
t
元素相乘,得到确定输出的部分,
[0111]ht
=o
t
*tanh(c
t
)
ꢀꢀ
(8)
[0112]
式(3)至式(8)构成了lstm的前向传播公式。
[0113]
3.2)后向传播
[0114]
在计算机实际训练中,需要知道各个参数是如何更新的,即后向传播公式。相较于前向传播公式,后向传播的推导在前向传播的最后一层加上一个输出,即
[0115]yt
=σ(w
·ht
)
ꢀꢀ
(9)
[0116]
式中,w为h
t
的权重矩阵,因此所求的参数共有九个权重矩阵,w
(f)
,u
(f)
;w(i),u(i);w
(c)
,u
(c)
;w
(o)
,u
(o)
;w。
[0117]
定义损失函数式中y为实际值,对九个矩阵分别求偏导就可以得到其梯度,在更新权重矩阵时选择负梯度方向进行更新。
[0118]
以遗忘门为例,其前向公式实质上还需要加上一个偏置项bf,然而为了计算方便,可以将式(3)写成如下的形式:
[0119][0120]
其中的偏置项bf就被合并入权重矩阵内,而wf为矩阵w
(f)
和u
(f)
连接,s
t
则为向量x
t
和h
t-1
连接。以此类推,式(3)至(6)和(8)可以合并为一个矩阵形式:
[0121][0122]
式中wi为矩阵w(i)和u(i)连接,wc为矩阵w
(c)
和u
(c)
连接,wo为矩阵w
(o)
和u
(o)
连接。
[0123]
对每个时刻t,令δh
t
记为e
t
对h
t
的偏导,δh
t-1
记为e
t-1
对h
t-1
的偏导,同理t-2,t-3,t-4时刻等等类推。则根据式(8)可以得到:
[0124]
δo
t
=δh
t
*tanh(c
t
),δc
t
=δh
t
*o
t
*(1-tanh2(c
t
)),
[0125]
根据式(7)可以得到:
[0126]
δf
t
=δc
t
*c
t-1
,
[0127]
δc
t-1
=δc
t
*f
t
,δi
t
=δc
t
*i
t
,
[0128]
根据式(3)至(6)可以得到:
[0129][0130]
其中上标t为转置,符号
×
为向量外积。最后求δh
t-1
,通过链式法则可以得到最终结果:
[0131][0132]
所以总体梯度就可以写出:
[0133][0134]
以上就是lstm的后向传播公式,也就是实际的参数训练公式。
[0135]
4)调节神经网络参数,对参数调节后的神经网络参数进行训练,其中调节神经网络参数具体为,
[0136]
所述神经网络参数包括隐藏层,训练次数,hidden_size,dropout,
[0137]
4.1)调参前准备工作
[0138]
a.首先使用一个较小的数据集,让调节神经网络去训练拟合这个数据集,看看能否做到损失为0/准确率为1;
[0139]
b.在一轮训练中,打印出输入、输出,检测数据的正确性;
[0140]
c.去除正则化项,观察初始的损失值,并对损失进行预估;
[0141]
d.可视化训练过程,在每一轮训练完成后,计算验证集上的损失值与准确率,并记录下每一轮训练集与验证集的损失值,可以进行每一层的可视化。
[0142]
4.2)调节参数
[0143]
a.在确保了数据与网络的正确性之后,使用默认的参数设置,观察损失值loss的变化,初步定下各个参数的范围,再进行调参,对于每个参数,在每次的调整时,只去调整一个参数,然后观察损失值loss变化,不会一次改变多个超参数的值去观察损失值;
[0144]
b.对于loss的变化情况,主要有以下几种可能性,上升、下降、不变,对应的数据集有train与val,那么进行组合有如下的可能,
[0145]
train loss不断下降,val loss不断下降——网络仍在学习;
[0146]
train loss不断下降,val loss不断上升——网络过拟合;
[0147]
train loss不断下降,val loss趋于不变——网络欠拟合;
[0148]
train loss不断上升,val loss不断上升——网络结构问题;
[0149]
train loss不断上升,val loss不断下降——数据集有问题;
[0150]
4.3)可能性处理
[0151]
当网络过拟合时,可以采用的方式是正则化(regularization)与丢弃法(dropout)以及bn层(batch normalization),正则化中包括l1正则化与l2正则化,在lstm中采用l2正则化。另外在使用丢弃法dropout与bn层时,需要主要注意训练集和测试集上的设置方式不同,例如在训练集上dropout设置为0.5,在验证集和测试集上dropout要去除;
[0152]
当网络欠拟合时,可以采用的方式是,去除/降低正则化、增加网络深度、增加神经元个数、增加训练集的数据量。
[0153]
5)采用训练好的神经网络开始验证,将需要故障识别的变压器通过训练好的神经网络进行故障识别。
[0154]
实施例
[0155]
具体流程如图1所示,主要包含以下步骤:
[0156]
(1)对变压器振动数据进行数据清洗与绕组变形故障标定工作,如图2,本工作开展是否顺利将影响损失值的收敛值和收敛速度,样本的清洗与标定工作占到总工作量的40%,决定神经网络结果是否收敛与过拟合,最终将其作为lstm神经网络模型训练的样本。
[0157]
(2)开展lstm神经网络的设计工作,如图4,集成lstm神经网络的搭建,包含lstm长短期记忆神经网络用于训练振动时域信号,再与频域信号进行集合训练,变压器振动时域信号的点数为4096个点,lstm神经元数目就定位4096个,隐藏层大小最终定为50,训练数据600组,softmax维度是(50,600),全连接层输入参数为(90,600)。
[0158]
(3)神经网络设计结束后,开始神经网络参数的调整工作,先确定隐藏层大小,假定训练次数为2000次,对不同的隐藏层大小进行仿真,如图5,损失值从0.0021下降到
0.0004,当hidden_size达到50次时,损失值已经下降到0.00042,之后损失值随hidden_size不断增大下降不到0.00002,遂选择50作为hidden_size的大小。
[0159]
(4)确定了隐藏层大小,还需要确定训练次数,固定神经网络参数,把训练次数作为唯一变量,进行仿真,如图6,损失值从0.00057降低到0.00018,在训练次数达到10k次后,在0.0002徘徊,本次选择10k作为训练次数,为了防止lstm出现过拟合情况,将dropout设置为0.5,自此lstm神经网络搭建完毕,准备就绪。
[0160]
(5)神经网络参数选择完毕,开始训练,训练100次,损失值分布,如图7,损失值平均值为0.00018
[0161]
采用训练好的神经网络开始验证工作,把验证组数据代入神经网络,训练值与故障预测值进行比对,如图8,从预测绕组不变形角度出发,正确率达到99.5%,按照神经网络预测精度已经达标,从绕组变形角度,预测出的绕组变形故障变压器为3台,而实际是2台,有1台误报,而这一台变压器振动熵为2.95,接近3,处于绕组变形辨识的边界,存在误报的可能性。通过频率信号与lstm神经网络集合分析,提高了绕组正常的识别率,达到了99.5%,而对绕组变形的识别误报一个,大大提高了预测成功率。
[0162]
以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。