1.本发明属于水文统计学技术领域,具体涉及一种基于多数据同化集合平滑刻画地下水简单面源信息的方法。
背景技术:
2.地下水在水资源的重要组成部分,是人类生活、农业与工业淡水的重要来源,地下水的质量与人类健康紧密相连。一旦地下水遭受到污染,就有必要了解清楚污染源信息,比如污染物在何处释放以及释放了多长时间。随着我国城市化进程的推进,水资源开发不合理,地下水遭受到严重污染,追溯、整治污染源等问题亟待解决。可靠的污染源识别对于了解地下水污染以及提高地下水管理的修复效率至关重要。
3.用于识别地下水污染源的逆向建模方法因其有效性与高效性受到广泛关注,根据其特点可分为三类:优化方法、概率性方法和确定性方法。早期用于识别污染源的方法是优化方法,主要是通过最小化模拟浓度和观测值之间的差异刻画污染源;概率方法是最大化给定观测值的一些源参数的后验概率;确定性方法是解决时间上的平流-扩散方程。但是这些很难准确刻画多个未知信息参数。还有一些应用在石油工程和水文地质学中可以进行参数识别的方法,在识别静态参数与污染源信息参数方面具有突出表现,其中,多数据同化集合平滑能够同时识别污染源点的位置与释放信息,并在合成以及实际案例中得到证明。
4.从规模角度来看,地下水污染源可简单分为两类:点源与面源。点源通常由垃圾填埋场、加油站、工厂废水和城市污水引起,而面源通常由农业肥料、牲畜、家禽养殖粪便污水和化工厂的化学品泄漏引起。目前绝大部分的污染源识别研究都只涉及到单点源或多散点源识别源位置以及释放信息,或者采用点源简化面源,然而直接将面源简化到其中心点会导致低估污染物释放的质量。由于污染源识别的复杂性会随着面源排放数量的增加而增加,很少有关于面源识别的工作。少数的面源识别工作只是将面源区域利用矩形或矩形组成的简单图形作常规化、棱角化处理。
技术实现要素:
5.发明目的:为了克服背景技术的不足,本发明公开了一种基于多数据同化集合平滑刻画地下水简单面源信息的方法,该方法利用多数据同化集合平滑技术,通过多次同化污染物浓度观测值,反演椭圆的信息参数,并通过反演的椭圆近似刻画实际简单面源位置及范围,此外该发明还可同时反演简单面源的其它信息。
6.技术方案:本发明所公开的一种基于多数据同化集合平滑刻画地下水简单面源信息的方法,包括以下步骤:
7.s1、根据水文地质统计信息,利用序贯高斯模拟生成初始对数渗透系数场;根据前期野外调查确定污染源可疑区域并确定用来近似刻画污染物简单面源的信息参数(比如,椭圆中心点位置、长短半轴长、旋转角度、污染物初始释放时间、释放持续时长、以及释放
量)取值范围,并在此范围内随机采样生成个参数的初始值;设定多数据同化的次数;
8.s2、对于第j次数据同化,基于更新(初始)的面源信息,通过溶质运移方程进行全局污染物浓度场的预测;
9.s3、基于观测井处,同化的所有时间段内的污染物浓度观测数据与预测浓度数据之间的差异,利用多数据同化集合平滑技术中的更新过程更新面源的各信息参数;
10.s4、重复s2-s3的同化过程,直至达到设定的同化次数。
11.其中,s1具体为:
12.生成初始对数渗透系数场lnk、旋转椭圆近似刻画的初始污染源中心点位置xs(x坐标轴方向)以及ys(y坐标轴方向)、长短半轴长ra以及rb、椭圆绕中心点逆时针旋转角度b、初始释放时间ti、释放时长δt以及释放质量负载率m,并构建参数向量s:
[0013][0014]
进一步的,s2具体为:
[0015]
基于初始污染物浓度场(状态变量)c0和(j-1)次数据同化迭代更新的面源各信息参数向量使用溶质运移的状态转换方程预测第j次迭代全局的污染物浓度分布场
[0016][0017]
进一步的,s3具体为:
[0018]
基于第j-1次数据同化迭代更新的模型参数增广向量卡尔曼增益kj、观测井处的浓度观测值co与预测浓度之间的差值以及观测误差εj更新第j次数据同化后的面源参数向量更新过程中的卡尔曼增益kj是所有时间的面源相关参数和观测点的预测浓度之间的交叉协方差d
sc,j
,以及所有时间中获得的观测点的预测浓度之间的自协方差d
cc,j
和观测误差协方差rj的函数,
[0019][0020]
其中:
[0021]
kj=d
sc,j
(d
cc,j
a
jrj
)-1
。
[0022]
从上式可知,观测误差协方差rj和观测误差εj分别由aj和放大。
[0023]
有益效果:与现有技术相比,本发明的优点为:首先,本发明能够通过旋转椭圆近似刻画简单面源的位置、形状、污染物释放时间、释放时长以及释放浓度;其次,本方法仅需
已知面源各参数的大致取值范围,就可通过同化状态变量的观测数据来识别污染源各信息参数;最后,本发明验证了多数据同化集合平滑在识别面源方面的可行性。
附图说明
[0024]
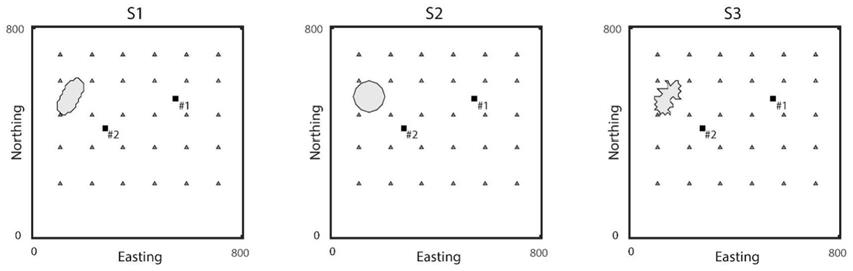
图1为实施例中三种情景下真实简单面源与观测井位置示意图;
[0025]
图2为本发明方法流程图;
[0026]
图3为实施例中三种情景下的无观测数据同化和在数据同化不同次数后更新的面源各信息的平均绝对误差(aab)和集合散度(esp)图;
[0027]
图4为实施例中三种情景下的简单面源信息参数的初始和更新集合计算的箱线图。
具体实施方式
[0028]
下面结合附图和实施例对本发明的技术方案作进一步的说明。
[0029]
在一个饱和稳态的承压含水层中验证本发明是可以通过基于多数据同化集合平滑有效反演地下水简单面源信息的方法。设置二维含水层空间:800[l]*800[l],厚度为80[l],离散为80*80*1个单元格,每个单元格为10[l]*10[l]*10[l],模型东西边界为定水头边界且给定水头分别为80[l]和300[l],南北边界均为隔水边界。
[0030]
如图1所示,给出真实面源的位置及形状、30口观测井以及2口验证井的位置分布,三角形代表观测井、方形代表验证井、不规则区域代表不同形状的面源。通过一个序贯多元多高斯模拟器gcosim3d[g
ó
mez-hern
á
ndez and journel,1993],生成一个均值为-2ln[lt-1
],标准差为1ln[lt-1
],最大相关长度和最小相关长度分别为300[l]和200[l],角度为135度的球形变异函数的高维高斯分布的对数水力渗透系数参考场。
[0031]
含水层初始污染物浓度为0[ml-3
],其他地下水流与溶质运移参数设为均值:孔隙度设为0.3[-],纵向弥散度设为3.0[l],横向弥散度和纵向弥散度的比值设为0.5。假定污染物的溶质运移只存在平流与弥散过程,并且整个溶质运移过程为非稳态。真实的面源设置如图1,分为三种情景(椭圆形、圆形及简单不规则图形),各自的位置形状以及面源区域内每个网格释放的质量负载率、释放时间等信息参数见表1。对于本实施例,模拟总时长设为10950[t],并将其等分为100个时间步,面源从985.5[t]开始释放,直到2299.5[t]停止释放(即释放时长为1314[t]),前50个时间步记录观测井中浓度变化,用于面源参数的反演。
[0032]
通过地下水溶质运移模型mt3dms[zheng,2010]计算污染物运移方程式:
[0033][0034]
式中:θ表示含水层中的有效孔隙度[-];c表示浓度[ml-3
];t为时间[t];
·
表示散度算子;dm表示分子弥散系数[l2t-1
];α为色散张量[l];v为流速矢量[lt-1
],与水头h通过相联系;为拉普拉斯算子;qs为含水层单位体积的体积流速[t-1
];cs为源汇通量浓度。
[0035]
稳态情况下的水头h通过地下水流动模型modflow[mcdonald and harbaugh,1988]计算地下水流动稳态方程式得到:
[0036]
[0037]
式中:k为水力渗透系数[lt-1
];w为含水层单位体积的源汇量[lt-1
]。
[0038]
对于本实施例,如表1所示,假定利用多数据同化集合平滑同化状态变量观测数据的迭代次数为1次、2次、4次以及6次。
[0039]
表1为三种情景下的真实简单面源各参数定义
[0040]
情景s1s2s3同化迭代次数1,2,4,61,2,4,61,2,4,6污染源形状椭圆形圆形不规则图形xs150150/ys540540/ra8060/rb4060/b30//ti985.5985.5985.5δt2299.52299.52299.5m100010001000
[0041]
对于本实施例,如表2所示,从旋转椭圆近似刻画的面源中心点位置、长短半轴长、旋转角度、初始释放时间、释放时长以及释放浓度的可疑范围内的均匀分布中随机选取500个样本集合。
[0042]
表2为实施例的三种情景下的面源各参数的可疑范围
[0043]
参数可疑范围xs110-210ys460-560ra40-140rb10-80b0-90ti0-3175.5δt1204.5-6679.5m950-1200
[0044]
如图2所示,本发明的基于多数据同化集合平滑刻画地下水简单面源信息的方法,包括步骤如下:
[0045]
s1、根据水文地质统计信息,利用序贯高斯模拟生成初始对数渗透系数场;根据前期野外调查确定污染源可疑区域并确定用来近似刻画污染物简单面源的信息参数(比如,椭圆中心点位置、长短半轴长、旋转角度、污染物初始释放时间、释放持续时长、以及释放量)取值范围,并在此范围内随机采样生成个参数的初始值;设定多数据同化的次数。
[0046]
s2、对于第j次数据同化,基于更新(初始)的面源信息,通过溶质运移方程进行全局污染物浓度场的预测。
[0047]
s3、基于观测井处,同化的所有时间段内的污染物浓度观测数据与预测浓度数据之间的差异,利用多数据同化集合平滑技术中的更新过程更新面源的各信息参数。
[0048]
s4、重复s2-s3的同化过程,直至达到设定的同化次数。
[0049]
具体实施时:
[0050]
(1)生成初始对数渗透系数场lnk、旋转椭圆近似刻画的初始污染源中心点位置xs(x坐标轴方向)以及ys(y坐标轴方向)、长短半轴长ra以及rb、椭圆绕中心点逆时针旋转角度b、初始释放时间ti、释放时长δt以及释放质量负载率m,并构建参数向量s:
[0051][0052]
(2)基于初始污染物浓度场(状态变量)c0和(j-1)次数据同化迭代更新的面源各信息参数向量使用溶质运移的状态转换方程预测第j次迭代全局的污染物浓度分布场
[0053][0054]
(3)基于第j-1次数据同化迭代更新的模型参数增广向量卡尔曼增益kj、观测井处的浓度观测值co与预测浓度之间的差值以及观测误差εj更新第j次数据同化后的面源参数向量更新过程中的卡尔曼增益kj是所有时间的面源相关参数和观测点的预测浓度之间的交叉协方差d
sc,j
,以及所有时间中获得的观测点的预测浓度之间的自协方差d
cc,j
和观测误差协方差rj的函数,
[0055][0056]
其中
[0057]
kj=d
sc,j
(d
cc,j
a
jrj
)-1
[0058]
从上式可知,观测误差协方差rj和观测误差εj分别由aj和放大。
[0059]
(4)重复以上过程,直至达到设定的数据同化次数。
[0060]
对于本发明的方法,如图3所示,显示的是实施例中三种情景下在无观测数据同化和在不同数据同化次数后更新的面源各参数值与真实值之间的平均绝对误差(aab)和通过集合方差平方根来衡量更新实现的集合精度的集合散度(esp)图,可以看出,在未经数据同化时,三种情景下的面源各参数的aab和esp都在一个相对高值,随着迭代次数的增加,aab和esp逐渐减小,除6次迭代后场景s3的aab外,所有场景都趋于收敛到较小的值。这个结果证明随着迭代次数的增加,面源各参数越来越接近真实值,并且不确定性也显著降低。
[0061]
如图4所示,实施例中三种情景下面源信息参数的初始和更新集合计算的箱线图。图中矩形框中的实线表示中值数,矩形框的上下边分别表示上下四分位数,黑色水平虚线表示面源各参数的真实值。从箱线图中可以看出,与初始面源各参数值的巨大不确定性相
比,当同化迭代次数增加时,所有更新的源参数值的不确定性急剧减少,4次迭代后的中值几乎与真值重合,只有情景s3的质量负载率m的值小于真值。情景s3的m被低估的原因是,更新的用来近似不规则源区域的椭圆覆盖的节点比真实的不规则源区域覆盖的节点多,导致m被稀释。对于情景s2,圆形面源的最终次迭代的旋转角度b对图形刻画无影响;对于情景s3,当真实污染源形状不规则时,没有真实的源形状参数值(xs、ys、ra、rb和b),但更新的椭圆形状参数值可以很快收敛到某个值,而根据这些参数刻画的椭圆能够近似的刻画不规则面源。由此可知,利用es-mda同化污染物浓度观测数据后更新的椭圆参数刻画出的椭圆形状及相关污染源信息(污染源释放初始时间、释放时长、污染物释放量),不仅能够有效地刻画规则的真实面源(如椭圆或圆形)信息,而且能够通过使用椭圆来近似刻画真实不规则的简单面源信息。
[0062]
通过以上分析可知,本发明使用基于多数据同化集合平滑技术在同化迭代足够次数的观测数据后能够有效刻画含水层中简单面源各参数信息。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
