技术特征:
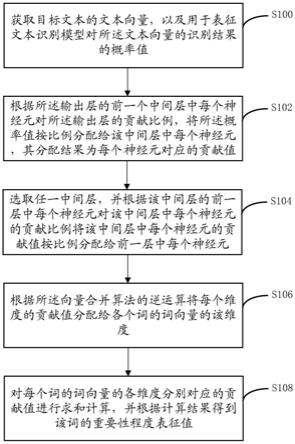
1.一种文本中词的重要性程度确定方法,其中,包括如下步骤:获取目标文本的文本向量,以及用于表征文本识别模型对所述文本向量的识别结果的概率值,其中,所述文本向量是基于向量合并算法对所述目标文本中各个词的词向量的相同维度进行合并后得到的,所述文本识别模型的算法结构包括神经网络,所述神经网络包括输入层、若干中间层以及输出层;根据所述输出层的前一个中间层中每个神经元对所述输出层的贡献比例,将所述概率值按比例分配给该中间层中每个神经元,其分配结果为每个神经元对应的贡献值,其中,该中间层中每个神经元对所述输出层的贡献比例包括该中间层中每个神经元的参数值乘以该神经元与所述输出层之间的连接权重值;选取任一中间层,并根据该中间层的前一层中每个神经元对该中间层中每个神经元的贡献比例将该中间层中每个神经元对应的贡献值按比例分配给所述前一层中每个神经元,其中,所述前一层包括所述输入层或其他中间层,所述前一层中第一神经元对该中间层中第二神经元的贡献比例包括该第一神经元的参数值乘以该第一神经元与该第二神经元之间的连接权重值;根据所述向量合并算法的逆运算将每个维度的贡献值分配给各个词的词向量的该维度,其中,所述输入层中每个神经元对应的贡献值为该神经元对应的维度的贡献值;对每个词的词向量的各维度分别对应的贡献值进行求和计算,并根据计算结果得到该词的重要性程度表征值。2.如权利要求1所述方法,其中,根据计算结果得到该词的重要性程度表征值的步骤,还包括如下步骤:将计算结果的绝对值,作为该词的重要性程度表征值。3.如权利要求1或2所述方法,所述目标文本为用于训练文本识别模型的标准文本,所述方法还包括对抗文本生成步骤,所述对抗文本生成步骤包括:基于所述标准文本中每个词的重要性程度表征值,选择若干重要性词作为待替换词;根据所述标准文本中位于每个待替换词之前的词与之后的词,预测每个待替换词对应的若干备选词;根据至少部分待替换词对应的备选词,对所述标准文本进行词替换操作,得到若干备选文本;使用所述文本识别模型分别识别每个备选文本,将若干满足对抗条件的备选文本确定为对抗文本;其中,所述对抗条件为,所述文本识别模型对该备选文本的识别结果区别于对所述标准文本的识别结果。4.如权利要求3所述方法,其中,所述预测每个待替换词对应的若干备选词的步骤还包括:针对每个待替换词执行以下步骤:将所述标准文本中该待替换词的位置进行遮掩标记之后,将所述标准文本输入bert模型,输出该遮掩标记对应的预测概率值集合;按照预测概率值由大到小的顺序,依次确定除该待替换词之外的若干词为备选词,其中,所述预测概率值集合包括多个词分别对应的预测概率值,其中每个词对应的预
测概率值用于预测该词出现在该遮掩标记对应的位置上的概率。5.如权利要求4所述方法,其中,所述文本识别模型用于对目标业务场景下的文本进行识别,其中,在将所述标准文本输入bert模型之前,所述方法还包括:利用目标业务场景下的文本对bert模型进行场景自适应训练。6.如权利要求3所述方法,其中,所述方法还包括如下步骤:用所述标准文本充当目标文本,以及按照各个待替换词的顺序将第一个待替换词作为目标待替换词,其中,所述确定对抗文本的步骤还包括迭代执行的以下步骤:针对所述目标待替换词对应的每个备选词,将所述目标文本中的该目标待替换词替换成该备选词,得到所述目标文本对应的一个备选文本;使用文本识别模型分别识别所述目标文本对应的每个备选文本,得到所述目标文本对应的每个备选文本的识别结果,并将所述目标文本对应的各个备选文本中满足对抗条件的备选文本添加至可用备选文本集合,若所述可用备选文本集合不为空,则基于所述可用备选文本集合确定对抗文本,并结束迭代;若所述可用备选文本集合为空,则将所述目标文本对应的各个备选文本中满足预设差异条件的备选文本重新作为所述目标文本,将下一个待替换词重新作为所述目标待替换词,开始执行下一次迭代,其中,所述预设差异条件为:在所述目标文本对应的各个备选文本中,该备选文本的识别结果对应的预测概率值与所述标准文本的识别结果对应的预测概率值的差异最大。7.如权利要求3所述方法,其中,所述标准文本属于中文文本,确定备选词的步骤还包括:针对至少部分待替换词获取该待替换词对应的若干火星文词汇,以作为该待替换词对应的备选词。8.一种文本中词的重要性程度确定装置,包括:获取模块,获取目标文本的文本向量,以及用于表征文本识别模型对所述文本向量的识别结果的概率值,其中,所述文本向量是基于向量合并算法对所述目标文本中各个词的词向量的相同维度进行合并后得到的,所述文本识别模型的算法结构包括神经网络,所述神经网络包括输入层、若干中间层以及输出层;第一分配模块,根据所述输出层的前一个中间层中每个神经元对所述输出层的贡献比例,将所述概率值按比例分配给该中间层中每个神经元,其分配结果为每个神经元对应的贡献值,其中,该中间层中每个神经元对所述输出层的贡献比例包括该中间层中每个神经元的参数值乘以该神经元与所述输出层之间的连接权重值;第二分配模块,选取任一中间层,并根据该中间层的前一层中每个神经元对该中间层中每个神经元的贡献比例将该中间层中每个神经元对应的贡献值按比例分配给所述前一层中每个神经元,其中,所述前一层包括所述输入层或其他中间层,所述前一层中第一神经元对该中间层中第二神经元的贡献比例包括该第一神经元的参数值乘以该第一神经元与该第二神经元之间的连接权重值;第三分配模块,根据所述向量合并算法的逆运算将每个维度的贡献值分配给各个词的
词向量的该维度,其中,所述输入层中每个神经元对应的贡献值为该神经元对应的维度的贡献值;确定模块,对每个词的词向量的各维度分别对应的贡献值进行求和计算,并根据计算结果得到该词的重要性程度表征值。9.一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现权利要求1至8任一项所述的方法。10.一种计算设备,包括存储器、处理器;所述存储器用于存储可在处理器上运行的计算机指令,所述处理器用于在执行所述计算机指令时实现权利要求1至8任一项所述的方法。
技术总结
本公开的实施方式提供了一种文本中词的重要性程度确定方法、介质、装置和计算设备。利用具有神经网络算法结构的文本识别模型对目标文件的文本向量进行识别,将文本识别模型输出的用于表征识别结果的概率值,完成文本向量的正向传播。然后,将该概率值由神经网络的输出层向输入层进行逐层反向传播。出层向输入层进行逐层反向传播。出层向输入层进行逐层反向传播。
技术研发人员:勒一凡 罗晓华 杨杰 许翔 王强
受保护的技术使用者:杭州网易再顾科技有限公司
技术研发日:2021.11.10
技术公布日:2022/2/24
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。