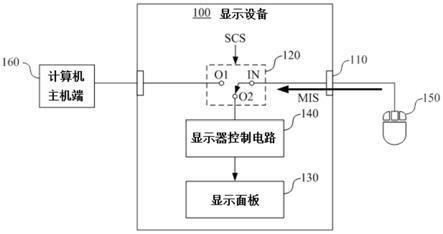
一种基于ft-2000 的整数矩阵乘法内核优化方法
技术领域
1.本发明属于信息处理领域,尤其提供了一种基于ft-2000 的整数矩阵乘法内核优化方法。
背景技术:
2.矩阵运算一直是高性能计算领域与科学计算领域的核心问题。而blas库中的许多函数,例如特征值求解和奇异值求解,是许多科学与工程应用的底层计算支撑。结构计算、自动控制、集成电路设计、化学模拟等领域都要将blas库作为底层计算函数库。同时blas库做为标准库函数的一种,是评测计算机性能的核心程序,在高性能计算中被广泛使用。hpl(高性能标准测试函数)在有一些极端情况下超过90%以上的时间都在进行矩阵运算。当前针对blas库优化的方向主要存在两个方向。一种是通过底层操作系统api(应用程序接口)获得当前体系结构的详细性能参数,例如l1缓存大小、l2缓存大小、l3缓存大小、内存大小等,然后通过参数的不同,自动计算出该平台下最佳的优化方案,这种优化方向最终产生的blas版本具有较好的可移植性;另外一个方向是基于不同的体系结构进行blas库的优化,并在这个方向上进行深入的研究,基于这个方向产生了大量基于不同体系结构的blas库。其中,许多科研人员基于飞腾体系结构对blas库进行优化,主要包括:
3.迟利华等人基于ft1000处理器对blas库的1级、2级、3级函数都进行优化,并成功研制出fitenblas。根据ft1000体系结构的硬件资源,对于blas库中的多级循环展录方法进行重新设计与实现。同时通过无冗余数据拷贝分块算法优化blas库中重要的blas3子程序。其核心子程序dgemm能达到峰值性能的86.4%。
4.2.王锋等人基于64位armv8多核处理器对blas库中的dgemm函数进行优化。其在文中提出了一个基于demmm的性能模型。然后在性能模型的指导下,为64位armv8多核处理器设计一个高效的dgemm。获得的峰值性能非常接近从理论浮点峰值。并且并行实现在不同矩阵大小的范围内均达到了良好的性能。此外,其实现对比与atlas的dgemm实现性能有较大提升。
5.3.杜琦等人基于64位armv8多核处理器对qtrsm(四精度三角矩阵求解)进行优化。基于两种数据格式分别实现了qtrsm,第一种实现利用gcc编译器对long-double数据类型的支持来实现qtrsm,第二种实现采用double-double数据格式及其相应的四精度加减法、乘法和除法。以long-double数据类型qtrsm为测试基准,就不同矩阵规模下测试结果精度和时间与double-double数据格式qtrsm进行比较。实验结果表明:两者得到近似相同精度的数值结果,但double-double数据格式qtrsm的性能是long-double数据类型qtrsm的1.6倍。随着线程数的增加,两种qtrsm实现的加速比接近2.0,具有较好的可扩展性。
6.综上所述,现阶段大部分研究人员对blas库优化的重点在于矩阵规模较大的高精度计算,例如dgemm。而面对人工智能领域需要的单精度及整型矩阵乘法进行优化的blas库是极少的。所以基于飞腾2000 ,对单精度矩阵乘法及整形矩阵乘法进行优化是一项十分有意义的工作。
技术实现要素:
7.为解决上述问题,本发明提供了一种基于ft-2000 的整数矩阵乘法内核优化方法。本发明基于飞腾2000 处理器对gemm函数进行研究与优化,结果表明本专利实现的gemm对比当前主流的径源blas库与数学计算库,计算速度有明显提升。
8.为达到上述技术效果,本发明的技术方案是:
9.一种基于ft-2000 的整数矩阵乘法内核优化方法,包括如下步骤:
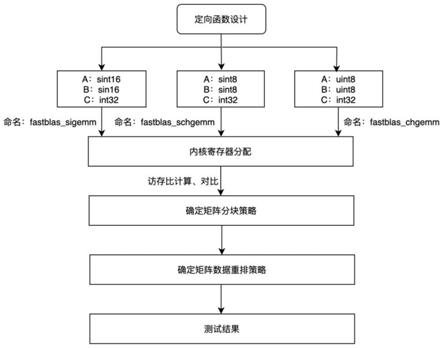
10.步骤一、根据输入和输出矩阵数据长度的不同,对子函数的设计内容加以区分;
11.步骤二、确定矩阵分块策略;
12.步骤三、基于指定目标,同时结合飞腾2000 体系结构,确定计算内核规模及内核寄存器分配策略;
13.步骤四、根据步骤三汇总确定的分块策略,确定矩阵数据重排策略,得到优化后的ft-2000 的整数矩阵乘法内核。
14.进一步的改进,所述步骤一包括如下步骤:
15.设置三种类型的整数矩阵乘法的内核寄存器:第一种矩阵乘法:若输入矩阵a和输入矩阵b的数据均为有符号int16,输出矩阵c的数据为有符号int32,则选择子函数为fastblas_sigemm;第二种矩阵乘法:若输入矩阵a和输入矩阵b的数据均为有符号int8,输出矩阵c的数据为有符号int32,则选择子函数为fastblas_schgemm;第三种矩阵乘法:若输入矩阵a和输入矩阵b的数据均为无符号int8,输出矩阵c的数据为有符号int32,则选择子函数为fastblas_chgemm。
16.进一步的改进,所述步骤二的矩阵分块策略如下:
17.(1)在最外层循环中,首先将矩阵b、c分别按列分为若干个矩阵规模为k
×
nc的子矩阵bc和m
×
nc的子矩阵;
18.(2)第二层中,将矩阵a按列得到panel a、矩阵b按行进行分块得到panel b,完成后矩阵a的规模为m
×
kc,panel b的规模为kc×
nc;
19.(3)第三层中,在panel a的基础上按行进行切分得到子矩阵blocka,规模为mc
×
kc,结合panel b可以得到结果矩阵c的规模为mc
×
nc;
20.(4)panel b按列切分成规模为kc
×
nr的子矩阵br,blocka按行切分为mr
×
kc的子矩阵ar,得到了micro-kernel;
21.(5)最后一层中,我们每次取矩阵a的一列与矩阵b的一行相乘,得到结果矩阵cr,然后将cr进行累加从而得到结果矩阵c;
22.三种类型的整数矩阵乘法的内核寄存器的分块参数如下:
23.其中,fastblas_sigemm的内核寄存器中由于规模为kc×
nr的矩阵br被重复使用,因此矩阵br要一直存储在l1缓存中;同时规模为mr×
kc的矩阵ar要从l2缓存中加载到l1缓存,并且计算完成后需要更新矩阵规模为mr×
nr的矩阵cr,并且要将结果从寄存器中存储到计算机内存层次结构中;此时数据计算量为2mrnrkc;那么此时的计算访存比为:
[0024][0025]
同时实际上mc是mr的整数倍,因为gebs和gess的计算访存比类似,所以gebs和gess的比率简化为:
[0026][0027]
其中,mr为8,kc为1024,nr为8;
[0028]
隐藏掉输出矩阵c数据存储到内存中的这个过程的开销,此时只要mr和nr的值确定了,则kc的值取最大值;
[0029]
另一方面,受限于l1缓存,kc受到如下限制:
[0030][0031]
其中,nr=8,element_size=2,并且飞腾2000 中l1缓存大小为32kb,从而得到得到kc=1024;
[0032]
同理得公式:
[0033][0034]
kc=1024,element_size=2,并且飞腾2000 中l2缓存大小为2mb,得到mc=512;
[0035]
由于飞腾2000 的处理器并没有l3缓存,选取经验值nc=10240;
[0036]
产品呢个人得到fast_sigemm的全部参数:mr=8,nr=8,kc=1024,mc=
[0037]
512,nc=10240;
[0038]
根据上述方法,fastblas_chgemm内核寄存器中计算得到得到fast_chgemm的全部参数:mr=4,nr=4,kc=4096,mc=1024,nc=10240;
[0039]
fastblas_schgemm内核寄存器中计算得到fast_schgemm的全部参数:mr=4,nr=4,kc=4096,mc=1024,nc=10240。
[0040]
进一步的改进,所述步骤三包括如下步骤:
[0041]
对于飞腾2000 体系结构,选择4
×
4内核作为计算内核,当遇到可以可以直接处理的小矩阵时,则直接使用用4
×
4内核,否则遇到无法直接处理的大矩阵的时候,通过跳步读取矩阵b的元素组成4
×
16的内核;
[0042]
三种整数矩阵乘法的内核寄存器分配策略如下:
[0043]
对于fastblas_sigemm的内核寄存器:
[0044]
因为缓存一行有64个字节,同时在64位的armv8体系结构中,每个浮点寄存器可以保存8个int16的数据,因此,将mr和nr设置为8的倍数;其中,v0-v7的8个寄存器用于存储矩阵ar的数据,v8-v15这8个寄存器将存储矩阵br的数据,v16-v31这16个寄存器将存储矩阵cr;
[0045]
对于fastblas_chgemm的内核寄存器:
[0046]
由于fastblas chgemm的内核寄存器中矩阵数据类型为int8,其中输入矩阵a为无符号int8,输入矩阵b为无符号int8,所以一个128位向量寄存器能够存储16个输入矩阵a或者输入矩阵b的数据;fastblas chgemm的寄存器分配方法如下:在数据重排之后,通过neon向量访存指令ld1,每次读取矩阵a连续地址中的32个int8类型的数据存入向量寄存器v2,v3,v24,v25,v26,v27,v28,v29的上半部分中,同时读取矩阵b连续地址中的16个int8类型的数据存入向量寄存器v4,v5,v6,v7的上半部分中。使用8个向量寄存器保存规模为4
×
2的
矩阵c的8个元素,每个向量寄存器中存储着由neon向量无符号混合乘加指令umlal计算得到的4个int32类型的整数,且这4个int32类型整数都属于矩阵c的同一个元素,且该元素由这4个整数相加得到。接着继续读取矩阵b的16个数据存入向量寄存器v4,v5,v6,v7的上半部分中;然后接着与矩阵a元素通过neon向量混合乘加指令umlal进行计算,将结果存入另外8个向量寄存器中,同样组成一个规模为4
×
2的矩阵c;所以最后得到的矩阵c的规模为4
×
4;同时在计算过程中会使用2个寄存器来存储中间结果。所以使用这种寄存器分配策略会使用30个寄存器;
[0047]
对于fastblas_schgemm的内核寄存器,在数据重排之后,通过neon向量访存指令ldr,每次读取输入矩阵a连续地址中的64个int8类型的数据存入向量寄存器v0,v1,v2,v3中,同时读取输入矩阵b连续地址中的64个int8类型的数据存入向量寄存器v4,v5,v6,v7中;使用16个向量寄存器保存规模为4
×
4的输出矩阵c的16个元素;
[0048]
此外,在本次计算过程中,将下次计算需要的输入矩阵b的32个元素读取到寄存器v8,v9,v10,v11中,将下次计算所需要的输入矩阵a的32个元素继续存储在寄存器v0,v1,v2,v3中;寄存器v12,v13,v14,v15用于保存计算所需要的中间结果。
[0049]
进一步的改进,fastblas_sigemm的内核寄存器中,mr=8,nr=8;在最后一层循环每次取的是8
×
nr和mr×
8。
[0050]
进一步的改进,所述步骤四中,输入矩阵a按照规模mr×
kc进行分块,然后按行主序进行数据重排,同时每个mr×
kc中的数据按照列主序进行重排;将panelb子矩阵按照规模kc×
nr进行分块,然后按行主序进行数据重排,同时每个kc×
nr中的数据按照列主序进行重排。
[0051]
本发明的优点:
[0052]
与现有技术相比,采用本专利可达到以下技术效果:
[0053]
1.第一步结合人工智能领域对不规则小矩阵的计算需求,有针对性地设计了三种矩阵乘法。
[0054]
2.第二步基于人工智能领域对不规则小矩阵的计算需求,对计算内核进行重新设计,并使用手工汇编代码进行实现。
[0055]
3.第三步基于寄存器分配策略,结合飞腾2000 的硬件特点,计算并确定了最优的矩阵分块策略。
[0056]
4.第四步针对每种计算内核,进行数据重排操作。
[0057]
5.本发明基于飞腾2000 处理器对gemm函数进行研究与优化,结果表明本专利实现的gemm对比当前主流的径源blas库与数学计算库,计算速度明显提升。
附图说明
[0058]
图1为本发明的总流程图;
[0059]
图2为4
×
4内核寄存器分配示意图;
[0060]
图3为4
×
16内核寄存器分配示意图;
[0061]
图4为chgemm寄存器分配示意图;
[0062]
图5为schgemm寄存器分配示意图;
[0063]
图6为矩阵分块示意图;
[0064]
图7为整数gemm矩阵分块示意图;(这个图里面字母看不清楚,需要写清楚,或者删除)
[0065]
图8为整数gemm矩阵数据重排示意图;
[0066]
图9为峰值测试核心汇编代码图。
具体实施方式
[0067]
以下通过具体实施方式对本发明的技术方案作具体说明。
[0068]
一种基于飞腾2000 体系结构的整数矩阵乘法内核优化方法,这种优化方法能有效提升整数矩阵乘法的计算效率。
[0069]
本发明基于人工智能领域大型矩阵乘法的背景,通过矩阵数据重排,更合理的优化了缓存及寄存器的分配,结合自己编写的汇编代码,在大规模矩阵与小规模矩阵之间进行折中处理,在尽量小的影响大规模矩阵运算性能的前提下,有效提升了矩阵的运算性能。
[0070]
本发明的具体技术方案为:
[0071]
第一步,根据输入和输出矩阵数据长度的不同,对子函数的设计内容加以区分。
[0072]
本文设计并实现了三种类型的整数矩阵乘法。第一种矩阵乘法:矩阵a的数据为有符号int16,矩阵b的数据为有符号int16,矩阵c的数据为有符号int32;第二种矩阵乘法:矩阵a的数据为有符号int8,矩阵b的数据为有符号int8,结果矩阵c的数据为有符号int32。第三种矩阵乘法:矩阵a的数据为无符号int8,矩阵b的数据为无符号int8,结果矩阵c的数据为有符号int32。
[0073][0074]
表1.三种函数接口
[0075]
第二步,基于指定目标,同时结合飞腾2000 体系结构,确定计算内核规模及内核寄存器分配策略。
[0076]
飞腾2000 芯片所使用的ftc662处理器核心基于armv8架构。同时该处理器拥有32个128位的向量寄存器。为了使计算访存比最大化,应该使用尽量多的向量寄存器。sgemm使用的内核结构有以下几种:4
×
4内核、4
×
8内核、8
×
8内核、8
×
16内核和4
×
16内核。
[0077]
本发明的目标是在大规模矩阵与小规模矩阵之间进行折中处理,在尽量小的影响大规模矩阵运算性能的前提下,提升小规模矩阵的运算性能。
[0078]
基于该目标,同时结合飞腾2000 体系结构,我们选择4
×
4内核作为我们的计算内
核。当要处理大矩阵的时候,可以通过跳步读取矩阵b的元素组成4
×
16的内核。相比于原始4
×
16内核,额外开销为跳步读取矩阵b数据产生的开销,对性能的影响不会过大。当要处理小矩阵的时候,使用4
×
4内核相比于使用4
×
16内核能够进行更大的循环展开以及进行更少的分支预测。这样做对指令的流水线设计更有利。
[0079]
三种整数矩阵乘法的内核寄存器分配策略如下:
[0080]
2.1fastblas_sigemm
[0081]
因为缓存一行有64个字节,同时在64位的armv8体系结构中,每个浮点寄存器可以保存8个int16的数据。因此,最好将mr和nr设置为8的倍数。故本发明考虑选取mr=8,nr=8。
[0082]
实际上我们最后一层循环每次取的是8
×
nr和mr×
8。所以我们将使用全部32个寄存器。其中v0-v7这8个寄存器将存储矩阵ar的数据。v8-v15这8个寄存器将存储矩阵br的数据。v16-v31这16个寄存器将存储矩阵cr的数据。
[0083]
2.2fastblas_chgemm
[0084]
由于fastblas chgemm中矩阵数据类型为int8,其中矩阵a为无符号int8,矩阵b为无符号int8。所以一个128位向量寄存器能够存储16个矩阵a或者矩阵b的数据。fastblas chgemm的寄存器分配如图4所示。由于在计算过程中会使用2个寄存器来存储中间结果。所以使用这种寄存器分配策略会使用30个寄存器。
[0085]
2.3fastblas_schgemm
[0086]
在数据重排之后,我们会通过neon向量访存指令ldr,每次读取矩阵a连续地址中的64个int8类型的数据存入向量寄存器v0,v1,v2,v3中,同时读取矩阵b连续地址中的64个int8类型的数据存入向量寄存器v4,v5,v6,v7中。使用16个向量寄存器保存规模为4
×
4的矩阵c的16个元素。
[0087]
另一方面,在本次计算过程中,会将下次计算需要的矩阵b的32个元素读取到寄存器v8,v9,v10,v11中,将下次计算所需要的矩阵a的32个元素继续存储在寄存器v0,v1,v2,v3中。寄存器v12,v13,v14,v15用来保存计算所需要的中间结果。使用这种寄存器分配策略会使用到全部32个向量寄存器。具体如图5所示。
[0088]
第三步、基于寄存器分配策略,计算确定矩阵分块策略
[0089]
本发明将根据goto等人的论文所提出分块方法,从提高缓存利用率角度分析goto等人提出的一系列方法中哪仪种是术适合飞腾2000 的矩阵分块方法。
[0090]
如图6所示,矩阵分块总的来说共有自上而下6种方法。第4种和第5种切分方式会在矩阵规模很大时,受限于cpu缓存的容量,而难以将矩阵a的完整一行和矩阵b的完整一列都保存在缓存中;第6种方式在l1 cache中对c矩阵进行重排,操作的复杂性远大于在寄存器中对c矩阵进行重排;而第2种和第3种方式原理相似。
[0091]
综上,本发明考虑使用前两种分块方式。相较而言,第1种切分方式和第1种切分方式的区别为第1种切分方式处理小的子矩阵时是按照列进行处理。如果数据存储方式是按照列主序进行存储,则用第1种方式是最优选择。第二种切分方式处理较小的子矩阵时是按照行进行处理,如果数据存储方式是按照行主序进行存储的话,选择第2种是最优选择。
[0092]
基于图6所示参数,三种整数矩阵乘法的分块参数如下:
[0093]
3.1fastblas_sigemm
[0094]
由于规模为kc×
nr的矩阵br被重复使用。因此矩阵br要一直存储在l1缓存中。同时
规模为mr×
kc的矩阵ar要从l2缓存中加载到l1缓存。并且计算完成后需要更新矩阵规模为mr×
nr的矩阵cr,并且要将结果从寄存器中存储到计算机内存层次结构中。此时数据计算量为2mrnrkc。那么此时的计算访存比为:
[0095][0096]
虽然我们不可能在计算时隐藏掉加载矩阵c元素到寄存器的开销。但是我们可以隐藏掉矩阵c数据存储到内存中的这个过程的开销。所以只要mr和nr的值确定了,那么毫无疑问为了使计算访存比变得更大,kc的值也是越大越好。
[0097]
另一方面,受限于l1缓存,kc受到如下限制:
[0098][0099]
基于上一步中所述,nr=8,element_size=2,并且飞腾2000 中l1缓存大小为32kb。根据上式,我们可以得到kc=1024。
[0100]
同理可得公式:
[0101][0102]
kc=1024,element_size=2,并且飞腾2000 中l2缓存大小为2mb。根据上式,我们可以得到mc=512。
[0103]
由于飞腾2000 的处理器并没有l3缓存,本发明选取经验值nc=10240。
[0104]
综上,我们得到fast_sigemm的全部参数。mr=8,nr=8,kc=1024,mc=
[0105]
512,nc=10240。
[0106]
3.2fastblas_chgemm
[0107]
同理可计算得到fast_chgemm的全部参数。mr=4,nr=4,kc=4096,mc=
[0108]
1024,nc=10240。
[0109]
3.3fastblas_schgemm
[0110]
同理可计算得到fast_schgemm的全部参数。mr=4,nr=4,kc=4096,mc=
[0111]
1024,nc=10240。
[0112]
第四步,确定矩阵数据重排策略。
[0113]
由于计算机访存局部性原理的存在,访问连续内存位置(也称为跨步访问)通常要比访问非连续内存快。当我们进行到layer2时,我们对矩阵b进行分块处理,我们需要将分块后的得到的子矩阵bc进行数据的重新排序。并且当我们进行到layer3时,我们对矩阵a进行分块处理,我们也靟要将分块后的得到的子矩阵ac进行数据的重新排序。通过这两步操作,我们可以确保这两个矩阵的元素能够在后续micro kernel处理时能够以跨步访问的方式被读取。
[0114]
本发明中,考虑将block a子矩阵中的数据根据后续矩阵切分规模mr×
kc按行主序进行数据重排,同时每个mr×
kc中的数据按照列主序进行重排;将panelb子矩阵中的数据根据后续矩阵切分规模kc×
nr按列主序进行数据重排,同时每个kc×
nr中的数据按照行主序进行重排。示意图如图8所示。
[0115]
第五步,实验测试浮点峰值。
[0116]
飞腾2000 有一个端口可以发射乘加指令,同时飞腾2000 单核的时钟频率为2.2ghz。并且飞腾2000 的向量寄存器为128位,也就是一个向量寄存器可以存4个浮点数。所以飞腾2000 的单核理论浮点峰值为17.6g flops。
[0117]
同时我们通过代码实测了飞腾2000 的峰值。核心代码设计如图9所示。
[0118]
设置一个简单的循环,并且循环次数足够多,保证每次循环发射7条无数据依赖的fmla指令。每次循环发射7条无数据依赖的fmla指令的原因是循环过程中发射7条fmla指令,浮点吞吐刚好达到最大值。朂终实测得到的结果为17.593480gflops。与理论峰值17.6gflops几乎一致。
[0119]
第六步,实验结果对比及其讨论。
[0120]
6.1 fastblas_sigemm
[0121]
调研过程中发现没有开源库实现了int 16整数矩阵乘法,所以无法进行对比实验,只能与处理器峰值进行比较,比较的同样是单核单线程数据。具体如下表所示:
[0122][0123]
表2.sigemm峰值占比
[0124]
从表中可以发现当矩阵规模足够大时,fastblas sigemm计算峰值能达到浮点峰值的91%。
[0125]
6.2 fastblas_chgemm
[0126][0127]
表3.chgemm性能比较(方阵)
[0128]
可见本发明提出的fastblas在小矩阵情况下的计算性能与gemmlowp持平,同时随着矩阵规模的不断增大fastblas的计算优势也不断增大。
[0129]
6.3 fastblas_schgemm
[0130][0131]
表4.schgemm性能比较(方阵)
[0132]
可见本发明提出的方法在小矩阵的情况有优势明显。
[0133]
上述仅为本发明的一个具体导向实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明的保护范围的行为。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。