1.本发明属于三维重构和点云压缩领域,具体涉及一种基于隐式神经网络的点云压缩方法。
背景技术:
2.近年来,点云数据的获取和应用领域变得越来越多样,如自动驾驶,vr和ar等领域都有点云数据的身影。相比于mesh或者voxel,点云没有复杂的拓扑结构,可以通过雷达传感器直接获取,但点云通常有海量的数据,直接存储和传输需要耗费大量的内存资源和网络带宽,因此,高效的点云压缩方案十分必要的。
3.传统的主流点云压缩方法基于mpeg提出的两种基本压缩框架,一种是vpcc,一种是gpcc。vpcc借鉴视频的压缩技术,用来对动态点云序列进行实时压缩,而gpcc是对点云的一些几何属性进行压缩,如颜色,法线等,通常用来压缩静态点云。深度学习的发展使得点云压缩有了新的前景,相较于传统方法,现有的深度学习方法很多都是基于vae框架,首先对原始通过多层卷积层进行点云下采样到隐式空间,再结合不同的熵模型,在训练过程中得到隐空间的概率分布,对 encoder之后的信息进行量化和熵编码得到比特流,解码端通过比特流和decoder进行上采样过程最终可以重构出新的点云。利用深度学习方法进行点云压缩,压缩率和精度各方面的效果都比传统的方法有了进一步的提高。但现有的深度学习的方法网络参数比较大,而且只能在固定分辨率下进行压缩和重建,导致可扩展性较差。
4.自2019来,隐函数神经网络在3d形状表示领域引起了广泛关注,隐函数的主要思想是通过给定原始形状的观察信息和查询点的位置,判断出空间中查询点是在形状的内外部,由多层感知机构成的网络通过学习拟合出隐式曲面,最终可以通过marching cube算法来重构出新的形状。
5.隐式网络是定义在整个输入的连续域上,比离散表示更加高效,可以处理各种拓扑结构的输入,如体素,mesh和点云。隐式网络不仅是空间连续的,而且理论上可以不限制分辨率输出。相比与现有的深度学习方法,隐式网络的整体结构更为简单,无需多层的上采样操作,具有良好的可扩展性和泛化能力。因此,考虑将隐式网络应用到点云压缩领域,对未来点云压缩的进一步发展有着十分重要的意义。
技术实现要素:
6.本发明针对现有技术的不足,提出一种基于隐式神经网络的点云压缩方法。
7.本发明包括以下步骤:
8.步骤1:给定shapenet数据集中的某一类别形状,划分为训练集和测试集两个部分。
9.步骤2:对原始的数据集中的mesh模型进行预处理,得到sdf 值。
10.步骤3:设计一个基于auto-decoder并融合熵模型的整体框架,输入为观察信息和经过熵模型量化的隐变量,输出为查询点的sdf 估计值,通过sdf值构造l1损失,并设计隐
变量的正则化项增加泛化能力,最终整个网络的损失如下:
[0011][0012][0013]
其中f
θ
是训练集共享参数的隐式网络,sj是输入点的真实sdf值, l是l1损失函数,是经过熵模型处理后的隐变量,xj是采样点。是熵模型的压缩损失,是网络学习出的隐变量的概率分布函数,,其中σ,λ都是超参数。
[0014]
步骤4:将预处理后的训练集中的扰动点作为隐式网络的输入x,同时随机初始化固定维度的隐变量,将隐变量经过熵模型后和输入x 拼接,作为隐式网络的输入并进行训练,学习到这一类别输入的共同特征。
[0015]
步骤5:推断阶段,将解码器decoder部分的隐式网络权重固定,通过少量的迭代过程优化随机初始化的隐变量,得到最终表示单个形状的隐变量,解码端可以通过隐变量和网络权重得到重构后的形状。
[0016]
步骤6:对测试阶段的隐变量进行量化和算术编码,将隐变量压缩为二进制字符串,进一步增加压缩率,并将压缩后的字符串传输给解码端。
[0017]
本发明的有益效果:本发明能够在特定类别的数据集上实现可观的压缩率,通过隐函数网络得到表示原始输入的隐变量信息,对隐变量进行量化压缩,整体的网络不需要通过复杂的3d卷积对3d形状进行处理,通过简单的mlp表示隐式网络,结构更加简单。
附图说明
[0018]
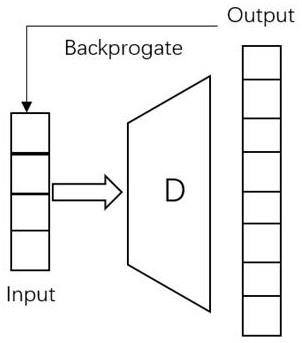
图1为auto-decoder网络的组成图;
[0019]
图2为本发明的整体网络框架图;
[0020]
图3为不同隐变量维度的网络测试得到不同的重构损失和压缩比特率图。
具体实施方式
[0021]
以下结合附图,对本发明进一步说明:
[0022]
步骤1:针对shapenet中的某一个类别的形状划分为训练集和测试集,利用同一个类别的形状是为了保证训练集和测试集都有类似的形状特征。
[0023]
步骤2:对原始的数据集中的mesh模型进行预处理,将mesh模型归一化到单位球,接着在mesh模型表面采样固定的点数并加上扰动得到空间任意位置的扰动点,计算空间中的扰动点离mesh模型表面采样点的距离和符号,即sdf值,将sdf值和对应扰动点的坐标保存到新的文件中。
[0024]
步骤3:设计整体的网络框架,输入为观察信息和经过熵模型量化后的隐变量,输出为查询点的sdf估计值。其中的auto-decoder 原理如图1所示,在encoder-decoder的通用框架上去掉了解码器 encoder部分,直接使用中间层的隐变量作为解码器decoder部分的输入,反向传播时同时更新解码器decoder的参数和隐变量的值,推断阶段时,没有编码器encoder部分的冗余,使得输出精度更高。
[0025]
在auto-decoder的基础上融合熵模型部分,以实现对隐变量的进一步处理,如图2所示,p是初始的观察点信息,z是随机初始化的一个维度的隐变量;训练过程中,首先将隐变量通过量化器q输入到一个全分解的熵模型entorpy model中,通过全分解的熵模型 entropy model预测隐变量的概率分布,y是隐变量,是量化后的值, ae是算术编码器,ad是算术解码器,是经过熵模型处理后的隐变量,d是解码器decoder。
[0026]
本发明用多层的全连接网络来训练网络参数θ,训练集中的所有单个形状si都在同一个隐式网络上学习共有的特性。传统的方法网络框架中的解码器decoder部分是将中间的隐变量利用3d卷积等方式进行多层上采样,而隐式网络则是通过利用隐变量在隐式网络学习拟合表示形状的隐式曲面,所需的网络参数更少,可扩展性也更好。
[0027]
为了学习的参数θ,对于包含n个形状的数据集,针对每个特定形状si,准备了k个采样点和采样点的sdf值,以及对应的隐变量zi,训练时通过计算网络输出sdf值和输入点的真实sdf 值sj之间的l1损失,同时最大限度地提高所有训练形状的联合对数后验,即对隐向量增加一个l2正则化项,再加上熵模型的损失:
[0028][0029]
其中f
θ
是训练集共享参数的隐式网络,sj是输入点的真实sdf值, l是l1损失函数,是经过熵模型处理后的隐变量,xj是采样点。是熵模型的压缩损失,是网络学习出的隐变量的概率分布函数,σ,λ都是超参数。
[0030]
步骤4:将预处理后的训练集中的扰动点作为隐式网络的输入x,同时随机初始化一个固定维度的隐变量,将隐变量经过熵模型的处理后和x拼接,作为隐式网络的输入并进行训练,训练过程中,通过反向传播更新熵模型和隐式网络的权重,由于训练集的数据都有一定程度上的相似性,所以整个隐式网络可以学习到这些数据的共同特征。
[0031]
步骤5:在推断阶段,由于训练后已经得到解码器decoder的网络参数,固定解码器decoder的网络权重,使用类似的损失函数微调每个新形状的隐变量z的值:
[0032][0033]
步骤6:得到最终表示单个形状的隐变量后,由于训练时熵模型已经学习到了隐空间的概率分布,结合概率分布对隐变量进行量化和算术编码,将隐变量压缩为二进制字符串,传输给解码端,解码端通过隐变量和网络参数进行解压。
[0034]
实施例:
[0035]
实验结果如图3所示,具体包括:
[0036]
步骤1:使用shapenet数据集中的凳子数据集进行训练和测试,对训练集和测试集进行预处理,实验中使用学习率为0.0005的adam 优化器,batch_size设置为12,训练60个epoch。
[0037]
步骤2:通过控制初始隐变量的维度来控制最终形状重构的效果,选取隐变量的维度有8,16,32,64,128,256,不同维度的初始化隐变量结合解码器decoder和熵模型分别进行单独训练。
[0038]
步骤3:测试阶段,将测试集的数据分别通过训练好的不同隐变量维度的网络进行测试,得到不同的重构损失和压缩比特率,如图3 所示,本发明的bpp(bit per point)变化为0.0898,0.1172,0.1563, 02383,0.3672,0.6055,重构损失变化为0.0835,0.0382,0.0405,0.0316, 0.0250,0.0220,由实验结果可以看出,与同样使用shapenet进行压缩的深度学习方法比较,本发明基于隐式函数网络的压缩方法具有更高的精度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。