1.本公开涉及一种声音信号处理领域,尤其涉及一种声音信号处理系统、方法、设备和智能音箱。
背景技术:
2.随着语音交互和互联网技术的发展,可利用语音功能进行信息获取、音乐播放和物联网设备管理的智能音箱得到普及。在家庭使用环境中,用户通常会购置一个智能音箱并将其布置在日常活动最频繁的区域,例如,客厅。进一步地,为了提供全域的语音交互功能,还可以在作为中心节点的客厅智能音箱之外,布置其他的语音交互设备,例如,其他的智能音箱,或是功能更为简单的语音交互设备,例如智能语音贴或智能语音开关等。
3.上述智能语音交互设备,能够方便用户进行语音交互,但尚缺乏智能家庭对家庭成员的关怀功能。
4.为此,需要一种改进的声音信号处理方案。
技术实现要素:
5.本公开要解决的一个技术问题是提供一种声音信号处理方案,该方案尤其可由智能音箱(或结合智能语音贴)实现,用于监控特定范围(例如,5至8米)内的婴幼儿啼哭声,并向监护人提供警告提示,以方便监护人进行快速响应。
6.根据本公开的第一个方面,提供了一种声音信号处理系统,包括:环境音采集模块,用于采集环境音信号;啼哭检测模块,用于基于啼哭检测模型,判断所述环境音信号中是否包含啼哭声;以及通知模块,用于基于环境音信号中包含啼哭声的判断,通知监护人。
7.根据本公开的第二个方面,提供了一种声音信息处理方法,包括:采集环境音;基于啼哭检测模型,判断采集的所述环境音中是否包含啼哭声;以及基于环境音中包含啼哭声的判断,通知监护人。
8.根据本公开的第三个方面,提供了一种智能音箱,包括:麦克风,用于采集环境音信号;啼哭检测模块,包括内置的啼哭检测模型,用于基于所述啼哭检测模型的输出,判断所述环境音信号中是否包含啼哭声;以及通知单元,用于基于所述啼哭检测模块对所述环境音信号中包含啼哭声的判断,通知监护人。
9.根据本公开的第四个方面,提供了一种声音信息处理设备,包括:低功率麦克风,用于采集环境音信号;啼哭检测模块,用于基于啼哭检测模型,判断所述环境音信号中是否包含啼哭声;以及近距离通信模块,用于传输所述环境音信号中包含啼哭声的判断。
10.根据本公开的第五个方面,提供了一种智能设备,包括:通信单元,用于接收来自第一方面所述的系统或第三方面所述的智能音箱的基于环境音信号中包含啼哭声的判断而发出的通知;以及显示单元,用于基于默认或是用户设置,显示所述通知。
11.由此,本发明的声音信号处理方案尤其可以结合现有的智能音箱,甚至进一步结合现有家庭物联网(iot)系统,实现对婴儿啼哭的实时监测。优选地,上述监测可由低功耗
麦克风实时采集环境音,由本地低功耗芯片进行初步判定,并结合云端或边缘计算进行二次判定来进行确认,并据此通知监护人,以方便监护人进行快速响应。
附图说明
12.通过结合附图对本公开示例性实施方式进行更详细的描述,本公开的上述以及其它目的、特征和优势将变得更加明显,其中,在本公开示例性实施方式中,相同的参考标号通常代表相同部件。
13.图1示出了根据本发明一个实施例的声音处理系统的组成示意图。
14.图2示出了常见环境音经特定处理聚类后的二维分布示意图。
15.图3示出了根据本发明一个实施例的声音信息处理方法的示意性流程图。
16.图4示出了根据本发明一个实施例的智能音箱的组成示意图。
17.图5示出了实施本发明的智能音箱的硬件框架例。
18.图6示出了根据本发明一个实施例可用于实现上述声音信息处理方法的计算设备的结构示意图。
具体实施方式
19.下面将参照附图更详细地描述本公开的优选实施方式。虽然附图中显示了本公开的优选实施方式,然而应该理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
20.随着语音交互和互联网技术的发展,可利用语音功能进行信息获取、音乐播放和物联网设备管理的智能音箱得到普及。在家庭使用环境中,用户通常会购置一个智能音箱并将其布置在日常活动最频繁的区域,例如,客厅。进一步地,为了提供全域的语音交互功能,还可以在作为中心节点的客厅智能音箱之外,布置其他的语音交互设备,例如,其他的智能音箱,或是功能更为简单的语音交互设备,例如智能语音贴或智能语音开关等。
21.上述智能语音交互设备,尚且只能方便用户进行语音交互,缺乏智能家庭对家庭成员的关怀功能。有婴幼儿的家庭中,用户会希望对婴幼儿的行为状态进行监控,例如智能设备及时发现婴幼儿的啼哭并通知监护人。现有技术中,虽然可以通过安装摄像头来观察婴幼儿的行为,但这需要监护人对监控视频的实时关注,并且通常无法在第一时间通知婴幼儿行为的变化。
22.为此,本发明提供一种声音信号处理方案,该方案尤其可由智能音箱(或结合智能语音贴)实现,用于监控特定范围(例如,5至8米)内的婴幼儿啼哭声,并向监护人提供警告提示,以方便监护人进行快速响应。
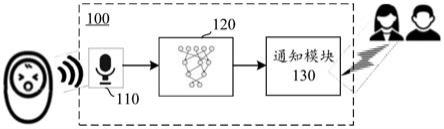
23.图1示出了根据本发明一个实施例的声音处理系统的组成示意图。如图所示,系统100可以包括环境音采集模块110、啼哭检测模块120和通知模块130。
24.环境音采集模块110,可以如图所示实现为麦克风(例如下文所述的低功率麦克风),用于采集环境音信号,例如图示的婴儿啼哭声。啼哭检测模块120可以基于啼哭检测模型,判断所述环境音信号中是否包含啼哭声。随后,通知模块130可以基于啼哭检测模块120对环境音信号中包含啼哭声的判断,通知监护人,例如婴儿的父母、或是托育机构的工作人
员。
25.在本发明中,啼哭检测模块120可以内置有啼哭检测模型。该模型可以是基于深度学习训练得到的模型。在此,深度学习是人工智能的一个分支。人工智能亦称机器智能,指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序来呈现人类智能的技术。
26.在人工智能领域中,存在利用仿生模型进行任务处理的深度学习分支。例如,人工神经网络(ann,也可简称nn)是一种从信息处理角度对人脑神经元网络进行抽象,进行分布式并行信息处理的数学计算模型。
27.在神经网络中存在着大量彼此连接的、被称为“神经元”的节点。每个神经元通过特定的输出函数计算来自其它相邻神经元的加权输入值。各神经元之间的信息传递强度用“权值”定义,算法会不断自我学习,调整这个加权值。早期的神经网络只有输入和输出层两层。由于无法处理复杂的逻辑,其实用性受到很大限制。深度神经网络(dnn)通过在输入和输出层之间添加隐藏的中间层,大大提升了神经网络处理复杂逻辑的能力。
28.在神经网络中,神经元的连接关系在数学上可以表示为一系列矩阵。经过训练后的网络虽然预测准确,但其矩阵都是稠密的,随着神经网络变得愈发复杂,稠密矩阵的计算会消耗大量的存储和计算资源。近年来的研究通过对神经元的剪枝(移除不重要的连接)和重训,压缩模型并尽可能的确保精度。
29.人工神经网络包括深度神经网络(dnn)、循环神经网络(rnn)与卷积神经网络(cnn)。典型的dnn由一系列有序运行的层组成。dnn神经网络由输入层、输出层和多个隐藏层串联组成。dnn的第一层读取输入值,例如输入的音频信息,并输出一系列的激活值。下面的层读取由上一层产生的激活值,并输出新的激活值。最后一个分类器(classifier)输出该输入音频信息可能属于的每一类别的概率。
30.在使用dnn进行推理(例如,音频分类)之前,首先需要对dnn进行训练。通过训练数据的大量导入,确定神经网络模型各层的参数,例如权重和偏移量。随后,可以将输入音频信息送入经训练的dnn模型,给出音频信息的分类概率。
31.在本发明中,啼哭检测模块120内置的啼哭检测模型尤其可以实现为如图1模块120中示出的经剪枝的dnn模型。应该理解的是,图示模型仅仅示出了剪枝的神经网络,而非对本发明所采音啼哭检测模型结构的精确表示。啼哭检测模块120可以接收采集模块110采集的环境音信号,例如,经过特定处理的环境音信号,将其送入经训练的啼哭检测模型,并由模型给出环境音信号包括啼哭声的概率。在一个实施例中,可以简单基于上述概率的取值来确定是否要通知监护人。例如,在概率大于0.5(即,50%)时通知监护人。在其他实施例中,啼哭检测模型可以具有更为复杂的输出,或者也可以基于更为复杂的原理来确定是否通知监护人。但无论何种情况下,通知模块130是否对监护人进行通知(以及如何进行通知),都需要考虑啼哭检测模型的输出。
32.在本发明的一个实现中,系统100可以实现为一个完整的独立设备,例如如下将结合图4描述的智能音箱,其智能音箱内部包括例如内置的麦克风作为环境音采集模块,包括例如单独的低功率芯片来实现啼哭检测功能,并且包括例如位于主平台上的通知模块,主平台可以在低功率芯片触发的情况下被唤醒,并进行使用通知模块在内的模块进行监护人通知的操作。
33.在另一个实现中,系统100可以由彼此通信的多个独立设备组成这些设备可以组成家用语音交互系统,甚至可以由家用iot系统实现。此时,环境音采集模块110模块可以实现为与所述啼哭检测模块进行短距离无线通信的分立环境音采集设备,例如,相比于智能音箱具有更简单构造的智能语音贴。智能语音贴是具有更为简单的语音识别功能,体积更为小巧,造价更为低廉,且更容易安装和布置的语音交互设备。该设备内可以设置有用于进行语音交互的麦克风和扬声器,唤醒词识别模块,以及短距离通信模块(例如,蓝牙模块)。该设备可被唤醒词唤醒,并将后续获取的用户语音输入短距离传送至具有更高处理能力的设备(例如,传送至蓝牙音箱,或是由蓝牙音箱转发至云端)。该智能语音贴可以安装在儿童房内,或是婴儿睡觉的房间内,以方便对婴儿啼哭声音的监测和采集。
34.在不同的实现中,可以在上述分立的环境音采集设备内实现啼哭检测模块120。例如,智能语音贴内可以布置有专门的啼哭检测低功率芯片(下文将详述),以实现上述啼哭检测模块的功能。上述啼哭检测模块120也可以在与上述分立的环境音采集设备通信的中心节点(或是相对中心的节点)内实现,此时环境音采集设备可以仅作为一个外置的环境音采集模块。上述中心节点可以是智能音箱,例如用作家庭智能交互中心的智能音箱,并且也可以在主平台之外额外包括一颗专用的啼哭检测低功率芯片(下文将详述),以实现上述啼哭检测模块的功能。
35.在分立的环境音采集设备仅采集环境音的情况下,该设备可以经由短距离通信模块,例如,低功耗蓝牙,传输采集的环境音。在分立的环境音采集设备还包括啼哭检测功能的情况下,该设备则可以直接将啼哭检测的结果,或是相关音频信息,经由诸如低功耗蓝牙的短距离通信模块传递给能够与监护人通信的设备,例如,智能音箱。智能音箱可被啼哭检测信号触发而从休眠中唤醒,并引发相应的啼哭功能,例如,按照默认设置或是用户偏好,向监护人的通信设备发送通知,或是直接经由tts(语音合成)模块进行啼哭警告的语音播报。
36.在本发明中,在将采集的环境音送入啼哭检测模型进行判断之前,可以对环境音进行一定的处理,以方便模型的检测和/或符合模型对输入信号的要求。在一个实施例中,该系统还可以包括音源分离单元,用于对采集的环境音信号进行音源分离。该单元可以设置在环境音采集模块和啼哭检测模型之间,例如可以作为啼哭检测模块的一部分,以对输入啼哭检测模型的信号进行音源分离。在此,“音源分离”指代从一堆混合的音频信号中分离出来自不同音源的信号。常见的应用包括识别同时翻译音频中的歌词(如卡拉ok)。音源分离的操作通常包括加载音频文件、计算时频变换得到频谱图,利用源分离算法(例如,非负矩阵分解)获得时频掩蔽,将时频掩蔽和频谱图相乘,再将结果转换回时域,从而得到经音源分离的信号。
37.虽然如上所述,在一个实施例中,深度学习的啼哭检测模型可以直接将经处理的环境音作为输入并输出环境音中包括啼哭的概率。但在其他实施例中,啼哭检测模型可以利用更为复杂的原理来进行啼哭检测。为此,啼哭检测模块可以用于:将采集的环境音信号与参考声学模型相比较;所述啼哭检测模型基于比较结果,生成有效内容加强的环境音信号;以及基于所述有效内容加强的环境音信号,判断所述环境音信号中是否包含啼哭声。进一步地,可以将将效内容加强的环境音信号反馈用于与参考声学模型相比较;以及迭代进行所述啼哭检测模型基于比较结果的有效内容加强的环境音信号的生成。
38.此时,该系统100还可以包括参考音源存储单元,用于存储参考声学模型。类似地,该单元同样可以作为啼哭检测模块的一部分。例如,参考音源存储单元中可以存储例如拉抽屉、敲击键盘等场景的室内环境音作为参考声学模型,并且啼哭检测模块可以依据存储的这些参考音源,进行与环境音的比对,以方便深度学习的啼哭检测模型能够生成有效内容加强的环境音信号。
39.为了提高对啼哭的正确检测率,系统100还可以包括带通滤波器,用于对采集的环境音进行带通滤波。上述带通滤波可以是针对特定信号的带通滤波,例如,针对易混淆的其他声音来设置带滤波的范围,由此避免其他信号对啼哭检测模型正确率的干扰。类似地,上述带通滤波器同样可以设置作为啼哭检测模块的一部分。图2示出了常见环境音经特定处理聚类后的二维分布示意图。如图所示,图中呈现为淡灰色雾状的婴儿啼哭声与咳嗽声有所交集。为了避免咳嗽声的干扰,可以针对咳嗽声特定的频率分布,通过添加带通滤波器来进行信号处理,从而提升啼哭检测模块的啼哭检测正确率。
40.除了借助啼哭检测模块120及其内置的啼哭检测模型进行基于采集环境音的本地推理之外,作为补充或是替换,还可以借助本地的其他设备或是远程算力来对啼哭进行进一步的判定。
41.在一个实施例中,系统100还可以包括传输单元。该传输单元可以是远程传输单元,用于基于所述啼哭检测模块的判断,向服务器(也可以是边缘计算设备)上的二次啼哭检测模型传输所述环境音信号和/或所述啼哭检测模型的输出,并接收所述二次啼哭检测模型的判断。通知模块130则可基于二次啼哭检测模型对环境音中包含啼哭声的判断,通知监护人。在某些实施例中,传输单元可以包括在通知模块130内,或是在通知模块130的控制下向监护人的设备进行啼哭警告信息传输。
42.在不同的实现中,云端的二次判断可由不同的条件触发。例如,在啼哭检测模块120的啼哭检测模型以较高概率(例如,80%的概率)判定采集环境音中包括啼哭声时,可以直接进行针对监护人的通知。而在啼哭检测模型的判定概率不高时,例如,50%的概率,则可启动二次判断流程,由此借助云端更为强大的算力和更为复杂的啼哭检测模型来提高最终通知的置信度。此时,可以借助传输单元(例如,wifi模块)向服务器传输所述环境音信号和/或所述啼哭检测模型的输出。服务器上可以存储有更为精确且需要更多计算量的啼哭检测模型(此处称为二次啼哭检测模型),因此可以进行置信度更高的啼哭判定。通过与服务器二次判定的结合,可以在本地布置更为轻量的啼哭检测模型,例如更为轻量的经训练dnn模型,从而在保证正确率的同时,降低本地的计算和存储需求(更轻量的模型意味着更少的参数存储和更少的输出计算)。
43.在一个实现中,可以在每次本地啼哭检测模型判定啼哭时,开启云端的二次检测,由此防止假阳性(将其他环境音误报为啼哭)通知的出现。在其他实现中,可以动态调整二次检测的触发条件。例如可以在夜间时段(例如,00:00~06:00,或由用户设置)本地啼哭检测模型判定啼哭时,开启云端的二次检测,由此防止假阳性通知对例如婴儿父母的睡眠打扰。也可以例如根据假阳性和假阴性(没有识别出环境音中的啼哭)的反馈,动态调整二次检测的触发条件,和/或本地模型进行通知的概率阈值。
44.另外,由于婴儿的不同啼哭声可以在一定程度上反映其不同的身体状况,例如,由于饥饿引起的哭声通常较短较低沉,由于疼痛引起的哭声则通常较高亢尖利等。因此在某
些实施例中,可以采用更为复杂的细分模型(通常实现为云端模型)和/或结合其他判定条件(例如,当前时间,拍摄图像,以及细分的啼哭参考音源等)来进行啼哭类型的分类。例如,当模型将啼哭声分类为因饥饿引起的啼哭时,可以在通知监护人发生啼哭的同时,给出响应意见,比如“宝宝在哭,是不是该喂奶了?”。
45.进一步地,为了提升通知准确率,或是向用户提供更为直观的信息,系统100还可以引入状态监控设备。状态监控设备可以用于监控对象的当前状态。在不同的实现中,状态监控设备可以自行开启监控,也可以在啼哭模型判定啼哭时被激活监控。由状态监控设备获取的监控对象(例如,婴幼儿)的当前状态信息可用于判定监控对象的啼哭状态,也可以直接由通知模块130作为通知信息(经由传输单元)发送给监护人。
46.为此,在搭建有家用iot(物联网)的情况下,可以通过使得其他iot设备参与啼哭检测来提升检测准确性。
47.在一个实施例中,状态监控设备可以包括摄像头,例如安装在婴幼儿房间内的摄像头。当啼哭检测模块120判定用户啼哭时,可以启动摄像头的拍摄,和/或直接将摄像头拍摄的视频或是图片发送至监护人设备,或是以其他方式向监护人呈现。此外,摄像头拍摄的视频也可用于系统进行啼哭行为的识别。例如,当啼哭检测模块120判定用户啼哭时,可以启动摄像头的拍摄,并将拍摄图像上传至云端服务器。服务器可以根据基于图片的经训练啼哭检测模型来进行基于图像的啼哭判断。在某些实施例中,服务器上也可以存储有基于音频和视频信息的联合啼哭判定模型,由此提升对婴幼儿啼哭判定的准确性。
48.作为替换或是补充,状态检测设备也可以是可穿戴设备,和/或智能床铺设备。可穿戴设备或是智能床铺设备(例如,带有传感器的婴儿床)可以通过自带的传感器来检测婴幼儿的当前体征信号或是其他运动信号,并从当前信号状态中进行啼哭判定。例如,可穿戴设备检测到表征婴儿醒来的信号变化等。在其他实施例中,上述状态检测设备还可以包括其他能够收集检测对象图像、体征或是运动状态的设备(例如,包含各类传感器的设备)。
49.在本发明中,通知模块130用于将婴儿啼哭通知给监护人,在不同的实施例中,通知模块130可以经由约定的各种途径向监护人提供不同形式的婴儿啼哭信息。在一个实施例中,通信模块130基于用户设置,确定通知监护人的通知内容和形式。例如,通知模块130可以基于啼哭检测模块120的判定,或是结合如上所述的状态监控设备或是云端二次检测的信息,生成啼哭警告信息,并将上述信息通知给监护人。
50.在此,“通知监护人”可以指代以各种方式将婴幼儿正在啼哭或是大概率正在啼哭这一事件告知监护人。通知可以采取各种可行的方式,并且可以根据设置而进行调整。例如,在监护人和检测对象位于室内的不同房间时,例如,宝宝在卧室睡觉,妈妈在厨房做饭时,可由位于卧室的环境音采集模块进行环境音采集,基于本地或是云端的深度学习模型判定,直接经由位于客厅的智能音箱或是位于厨房的智能语音贴播报上述啼哭警告,例如“宝宝在哭”,从而直观地直接从听觉上进行啼哭通知。作为替换或是补充,还可以将表征婴幼儿当前状态的信息直接提供给监护人。例如,在播报完“宝宝在哭”之后,直接切换播放采集设备当前采集的环境音。进一步地,在智能音箱或是语音贴具有屏幕并且卧室中布置有摄像头的情况下,也可以将摄像头的图像直接切换至屏幕上进行显示。
51.在其他情况下,例如监护人远离检测对象时,则可以将上述啼哭警告或是相关音视频发送至监护人所使用的设备上,例如监护人佩戴的智能移动设备,或是其他设备。例
如,可以将啼哭警告发送至监护人的手机上,并以通知的形式在待机屏幕上显示,并且可以给出诸如震动或是提示音等的其他提示。另外,也可以向监护人的电脑或是其他设备(可穿戴设备,例如,智能手表)发送啼哭警告和/或检测对象的当前音视频信息,状态传感器的度数等。
52.在此,监护人可以是对检测对象负有监护责任的对象,例如,婴幼儿的父母,(外)祖父母等。在某些实施例中,监护人也可以是托育机构,或是托育机构中的工作人员。此时,可以将啼哭警告或是相关信息直接传输至托育机构的公屏上。可以通过设备的关联设置或是监护人当前状态来选择通知方式。例如,在智能音箱感知到用户在家(例如,处于被激活的状态)时直接进行语音提醒,而在用户外出时,选择向用户随身携带的智能设备发送啼哭警告。
53.另外,所述通知模块130还可以基于其他的参数,并结合模型判断结果,来确定是否通知监护人和/或通知监护人的形式。上述参数包括但不限于:监控对象的作息时间;监护人的作息时间;监护人的当前位置;和/或监护人的当前状态。具体地,例如,可以在监控对象(即,婴幼儿)的预定睡眠时间段,提升啼哭判断时的通知强度,例如,监护人手机响铃并且震动。例如,可以在监护人的工作时段内仅进行震动提示,在监护人与婴儿处于相同位置时免于提示,或是在监护人a处于睡眠状态(例如,由佩戴智能手表判断)时,不对监护人a进行通知,而是通知当前醒着的监护人b等等。
54.在不同的实施例中,可以使用不同的硬件来实现本发明的上述系统。例如,可以使用智能音箱现有的麦克风阵列作为环境音采集模块110,也可以在智能音箱的主平台中并入啼哭检测功能。在优选实施例中,由于啼哭检测需要持续进行,因此可以在低功耗芯片上实现如上所述的啼哭检测模块。包括啼哭检测模块的低功率芯片可以结合低功率麦克风进行持续的环境音采集和啼哭判断操作,并且在判断环境音中包含啼哭声时,可以触发主平台使其控制的所述通知模块通知监护人,例如,可由低功耗芯片触发中断,以使得主平台被唤醒以进行默认的啼哭通知流程。
55.为了优化啼哭检测的准确率,可以对啼哭检测模型以及检测模块中包括的其他元件的参数进行设置。为此,啼哭检测模块可以用于:基于获取的判断反馈和/或采集的环境音,调整所述啼哭检测模型中的参数。换句话说,可以对啼哭检测模块进行升级,例如ota(空中)升级,以给出更为准确的参数设置。
56.在某些实施例中,可以基于来自海量用户的数据,即,大数据,来进行参数优化。例如,服务器可以收集大量设备实际采集的包含婴幼儿啼哭声或是其他干扰环境音的音频数据,根据这些数据来优化啼哭检测模型,例如,对深度模型进行重训,由此得到优化的模型参数,并可以将这些参数通过例如ota来更新至本地的啼哭检测模型。另外,也可以结合用户的反馈进行上述重训与更新。
57.在另外一些实施例中,可以仅基于本机用户的数据,来进行参数优化。例如,服务器可以收集来自特定设备或特定用户id关联设备采集的包含婴幼儿啼哭声或是其他干扰环境音的音频数据,根据这些数据来优化啼哭检测模型,例如,对深度模型进行重训,由此得到优化的模型参数,并可以将这些参数通过例如ota来更新至本地的啼哭检测模型。由于不同的婴幼儿哭声不同,因此通过针对个体的训练,能够优化啼哭检测结果。
58.进一步地,可以随着检测对象啼哭声音的变化,调整本地啼哭检测模块的参数。在
本发明中,啼哭检测的检测对象可以是婴儿的啼哭声。随着家中孩子的成长,最初的婴儿会成长为幼儿,并且幼儿的啼哭声与婴儿的啼哭声有所不同。在不同的实施例中,可以啼哭检测模型的检测对象可以仅包括婴儿啼哭声,也可以包括婴幼儿的啼哭声,也可以根据服务器收集的啼哭声进行更新。例如,在用户开启了智能音箱的啼哭检测和通知功能(默认不开启)之后,智能音箱可以采集环境音,并在检测到婴儿啼哭时进行监护人通知。另外,智能音箱也可以上传采集的婴儿啼哭声,用于本地啼哭检测模型的重训和参数下发。随着家中儿童的成长,啼哭声会有所变化。为了对更大的婴儿或是幼儿的啼哭进行准确检测,可以周期性地持续上传采集的啼哭声,并据此进行模型重训和参数下发,以实现本地模块基于轻量级神经网络的准确啼哭识别。
59.如上结合图1描述了根据本发明的声音信息处理系统。本发明的啼哭检测和通知方案还可以实现为一种声音信息处理方法,该方法可由如上系统100,或是单独的智能语音设备,例如智能音箱,或是更为简单的语音设备结合中心节点来实现。
60.图3示出了根据本发明一个实施例的声音信息处理方法的示意性流程图。在步骤s310,采集环境音。在步骤s320,基于啼哭检测模型,判断采集的所述环境音中是否包含啼哭声。在步骤s330,基于环境音中包含啼哭声的判断,通知监护人。
61.在一个实施例中,可以对采集的环境音进行带通滤波操作和音源分离操作。随后,可以将经过上述操作的环境音送入啼哭检测模型进行啼哭判定,由此提升检测正确率,并能够降低对模型的复杂度要求。
62.具体地,基于啼哭检测模型,判断采集的所述环境音中是否包含啼哭声可以包括:将采集的环境音信号与参考声学模型相比较;所述啼哭检测模型基于比较结果,生成有效内容加强的环境音信号;以及基于所述有效内容加强的环境音信号,判断所述环境音信号中是否包含啼哭声。
63.进一步地,可以将有效内容加强的环境音信号反馈用于与参考声学模型相比较;以及迭代进行所述啼哭检测模型基于比较结果的有效内容加强的环境音信号的生成。
64.作为本地检测的补充,还可以涉及云端的二次检测。为此,该方法还可以包括基于所述啼哭检测模块的判断,向服务器上的二次啼哭检测模型传输所述环境音和/或所述啼哭检测模型的输出;以及接收所述二次啼哭检测模型对所述环境音中是否包含啼哭声的判断。
65.进一步地,还可以利用例如iot网络中的其他设备采集的信息来帮助对啼哭进行判定。在一个实施例中,可以在模型判定啼哭之后,采集状态信息做出补充判定。为此,该方法还可以包括:基于环境音中包含啼哭声的判断,采集监控对象的当前状态信息;以及基于所述当前状态信息,判断所述对象的啼哭状态。在另一个实施例中,则可以直接采集状态信息,并结合模型输出进行判断。为此,该方法还可以包括:采集监控对象的当前状态信息;以及基于所述啼哭检测模型的输出以及所述当前状态信息,判断所述对象的啼哭状态。
66.进一步地,可以如上所述收集针对所述判断的反馈和/或采集的环境音,并基于收集的所述反馈和/或所述环境音,调整所述啼哭检测模型中的参数。
67.进一步地,本发明的啼哭检测和通知方案尤其可由智能音箱实现。图4示出了根据本发明一个实施例的智能音箱的组成示意图。如图所示,智能音箱可以包括麦克风410、啼哭检测模块420和通知单元430。
68.麦克风410可以用于采集环境音信号。啼哭检测模块420可以包括内置的啼哭检测模型,用于基于所述啼哭检测模型的输出,判断所述环境音信号中是否包含啼哭声。通知单元430用于基于所述啼哭检测模块对所述环境音信号中包含啼哭声的判断,通知监护人。
69.在此,麦克风410可以是智能音箱内置的,用于与用户进行语音交互和环境音采集的麦克风阵列,也可以是专门用于持续收音以进行啼哭信号检测的低功率麦克风。优选地,麦克风包括脉冲密度调制器,用于将采集到的环境音信号作为脉冲密度调制(pdm)信号进行输出,由此提升啼哭检测模块的检测准确度。
70.进一步地,啼哭检测模块420可以包括:带通滤波器,用于对采集的环境音信号进行有针对性的带通滤波,例如针对易混淆环境音(例如,图2所示分布的咳嗽声)的带通滤波。
71.进一步地,啼哭检测模块420可以包括:比较单元,用于将采集的环境音信号与参考声学模型相比较;生成单元,用于将比较结果送入所述啼哭检测模型,并生成有效内容加强的环境音信号;以及判定单元,用于基于所述有效内容加强的环境音信号,判断所述环境音信号中是否包含啼哭声。优选地,可以将所述生成单元的输出馈入所述比较单元,以迭代进行所述啼哭检测模型基于比较结果的有效内容加强的环境音信号的生成。此时,智能音箱还可以包括参考音源存储单元,用于存储参考音源信息。这些参考音源信息可以用作与采集的环境音相比较的上述参考声学模型。
72.为了对监护人进行通知,智能音箱的处理单元可以生成啼哭警告,并经由恰当的手段进行通知。为此,通知单元430可以包括第一通信单元(例如,wifi单元),用于基于所述啼哭检测模块对所述环境音信号中包含啼哭声的判断,向所述监护人的对应设备发送啼哭警告。作为替换或者补充,通知单元430可以直接利用扬声器,以基于所述啼哭检测模块对所述环境音信号中包含啼哭声的判断,输出语音合成的啼哭警告。
73.进一步地,智能音箱400还可以包括第二通信单元,用于获取状态监控设备采集的监控对象的当前状态信息,所述当前状态信息由所述通知单元发送给所述监护人和/或用于判断所述监控对象的啼哭状态。在此第二通信单元可以实现为短距离通信单元,例如蓝牙通信单元,以从如上所述的摄像头、可穿戴设备等获取婴儿的当前状态信息,用以作为对啼哭进行补充判定。进一步地,设置于婴儿房间的专用语音贴可以作为环境音采集设备,也可以作为状态监控设备来采集婴儿房间的环境音,以便更为真切的获取婴儿发出的声音。
74.为了进行持续的采集和处理,啼哭检测模块420可以在低功耗芯片实现,麦克风410则可由低功耗麦克风实现。智能音箱400还可以包括用于采集用户语音的麦克风阵列。此时,通知单元430可以位于主平台上,所述主平台基于所述啼哭检测模块对所述环境音信号中包含啼哭声的判断被激活,并指示所述通知单元进行所述通知。进一步地,主平台可以通过第一通信单元向服务器上的二次啼哭检测模型传输所述环境音信号和/或所述啼哭检测模型的输出,并接收所述二次啼哭检测模型的判断,并且通知模块可以基于所述二次啼哭检测模型对环境音中包含啼哭声的判断,通知监护人。
75.进一步地,主平台可以通过所述第一通信单元向所述服务器上次针对所述判断的反馈,接收基于所述反馈更新的针对所述啼哭检测模型的参数;并基于所述参数调整所述啼哭检测模型。
76.图5示出了实施本发明的智能音箱的硬件框架例。如图所示,智能音箱可以在常规
的主平台530之外,布置一颗低功耗芯片,例如mcu(微处理单元)530,其功耗可以低至几毫瓦,由此可以实现24小时低功耗运行。在实际操作中,低功耗数字麦克风510可以配合该低功耗芯片520进行声音信号收集工作。
77.麦克风510采集的pdm信号可以首先通过一个数字带通滤波器521进行滤波,以滤除易混淆的其他环境音,例如咳嗽声。上述带通滤波器可以具有特殊结构的空间物理表面滤波器,以便更为高效地接收有效信号。随后,数据被送入啼哭检测模型524进行运算(即,由经训练的模型进行推理),上述推理运算可以结合包括了滤波器522和放大器523的音源分离模块进行音源信号分离、识别,同时可以根据信号质量进行深度学习补充缺失的数据,再输出到反馈环进行有用信号部分加强,最后得到婴儿啼哭声强相关的声学模型。
78.具体地,在数据进行了滤波和放大之后,可以送入结合了啼哭检测算法的模型524内。啼哭检测算法可以对环境音数据进行声波能量谱分析,根据有效信号的强度做特定频点的切片,将其转换为声学特征码。声学特征码可以与现有的声学模型相比对,例如,存储在低功率芯片520的存储单元内的参考音源(也可成为参考声学模型)。比对后的结果可以送入深度学习的神经网络(即,啼哭检测模型),模型能够重建新的声场模型,即生成有效内容加强的环境音信号。进一步地,新的声场模型可以馈入啼哭检测算法以进行声学模式匹配以及神经网络的数据补缺,由此经过若干次迭代后,生成最终的声学参数。这些声学参考可以用来判定环境音中是否包括啼哭声。
79.mcu可以经由接口与外部通信,例如,经由接口525与主平台通信。例如,如果检测到有效的婴儿啼哭声,低功耗mcu会通过中断(例如,图示的io控制)唤醒主cpu平台。主平台530被唤醒后,可以进行婴儿啼哭事件的处理,以发送警示信号,例如主平台可以发送tts提示音、电话、邮件通知监护人(例如,父母)进行快速响应。
80.另外,为了提升低功耗音频520的音频处理质量,主平台530还可以向mcu 520提供aec参考信号。aec(声学回声消除)参考信号可以通过主平台530获取的麦克风收音减取喇叭音来生成。
81.进一步地,mcu 520还可以在主平台530的要求下直接提供其记录的音频输出。该音频输出可以用于后续处理,例如,直接发送给监护人,上传云端用于二次检测或是模型训练等等。
82.本发明也可以由更为简单的设备,例如智能语音贴实施,或是参与实施。为此,本发明可以实现为一种声音信息处理设备,包括:低功率麦克风,用于采集环境音信号;啼哭检测模块,用于基于啼哭检测模型,判断所述环境音信号中是否包含啼哭声;以及近距离通信模块,用于传输所述环境音信号中包含啼哭声的判断。具体地,近距离通信模块可以用于:传输采集的环境音信号;和/或接收更新的所述啼哭检测模型的参数。
83.具体地,相比于图5的智能音箱实现,上述声音信息处理设备不包括主平台,而是直接实现为包括低功率麦克风和低功率啼哭检测芯片的更为小型、紧凑的设备,例如,智能语音贴。上述设备可以采用近距离通信模块代替图5中的接口525,并直接通过近距离通信模块进行io信号的收发、aec参考信号的接收和音频数据的发送。
84.在一个实施例中,本发明还可以实现为一种智能设备,例如,监护人的智能手机或是佩戴的智能手表等,并且该设备可以包括:通信单元,用于接收来自如上所述的系统或是智能音箱的基于环境音信号中包含啼哭声的判断而发出的通知;以及显示单元,用于基于
默认或是用户设置,显示所述通知。具体地,可以由智能设备中安装的智能家庭专用或关联app接收所述通知并发起所述显示。例如,监护人可以在手机内安装智能家庭app,开启啼哭监测功能,并设定具体通知形式,从而在系统判定婴儿啼哭时得到通知。
85.图6示出了根据本发明一个实施例可用于实现上述声音信息处理方法的计算设备的结构示意图。
86.参见图6,计算设备600包括存储器610和处理器620。该设备600可以实现图3所示方法,以及图4或5所示的智能音箱或是更为简单的声音信息处理设备,并且可以还可以包括麦克风和上述专门用于进行啼哭检测mcu。
87.处理器620可以是一个多核的处理器,也可以包含多个处理器。在一些实施例中,处理器620可以包含一个通用的主处理器以及一个或多个特殊的协处理器,例如图形处理器(gpu)、数字信号处理器(dsp)等等。在一些实施例中,处理器620可以使用定制的电路实现,例如特定用途集成电路(asic,application specific integrated circuit)或者现场可编程逻辑门阵列(fpga,field programmable gate arrays)。
88.存储器610可以包括各种类型的存储单元,例如系统内存、只读存储器(rom),和永久存储装置。其中,rom可以存储处理器620或者计算机的其他模块需要的静态数据或者指令。永久存储装置可以是可读写的存储装置。永久存储装置可以是即使计算机断电后也不会失去存储的指令和数据的非易失性存储设备。在一些实施方式中,永久性存储装置采用大容量存储装置(例如磁或光盘、闪存)作为永久存储装置。另外一些实施方式中,永久性存储装置可以是可移除的存储设备(例如软盘、光驱)。系统内存可以是可读写存储设备或者易失性可读写存储设备,例如动态随机访问内存。系统内存可以存储一些或者所有处理器在运行时需要的指令和数据。此外,存储器610可以包括任意计算机可读存储媒介的组合,包括各种类型的半导体存储芯片(dram,sram,sdram,闪存,可编程只读存储器),磁盘和/或光盘也可以采用。在一些实施方式中,存储器610可以包括可读和/或写的可移除的存储设备,例如激光唱片(cd)、只读数字多功能光盘(例如dvd-rom,双层dvd-rom)、只读蓝光光盘、超密度光盘、闪存卡(例如sd卡、min sd卡、micro-sd卡等等)、磁性软盘等等。计算机可读存储媒介不包含载波和通过无线或有线传输的瞬间电子信号。
89.存储器610上存储有可执行代码,当可执行代码被处理器620处理时,可以使处理器620执行上文述及的啼哭检测方法。
90.上文中已经参考附图详细描述了根据本发明的声音信号处理方案。本发明的声音信号处理方案尤其可以结合现有的智能音箱,甚至进一步结合现有家庭物联网(iot)系统,实现对婴儿啼哭的实时监测。优选地,上述监测可由低功耗麦克风实时采集环境音,由本地低功耗芯片进行初步判定,并结合云端或边缘计算进行二次判定来进行确认,并据此通知监护人,以方便监护人进行快速响应。
91.此外,根据本发明的方法还可以实现为一种计算机程序或计算机程序产品,该计算机程序或计算机程序产品包括用于执行本发明的上述方法中限定的上述各步骤的计算机程序代码指令。
92.或者,本发明还可以实施为一种非暂时性机器可读存储介质(或计算机可读存储介质、或机器可读存储介质),其上存储有可执行代码(或计算机程序、或计算机指令代码),当所述可执行代码(或计算机程序、或计算机指令代码)被电子设备(或计算设备、服务器
等)的处理器执行时,使所述处理器执行根据本发明的上述方法的各个步骤。
93.本领域技术人员还将明白的是,结合这里的公开所描述的各种示例性逻辑块、模块、电路和算法步骤可以被实现为电子硬件、计算机软件或两者的组合。
94.附图中的流程图和框图显示了根据本发明的多个实施例的系统和方法的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或代码的一部分,所述模块、程序段或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标记的功能也可以以不同于附图中所标记的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
95.以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。