1.本发明涉及文字识别技术领域,尤其涉及一种基于神经网络文字图片识别方法及系统。
背景技术:
2.国家在不断发展交流过程中,走向世界学习不同的外语,外国人来访中国,也需要学习中文,以及各地方言,第二语言的学习、阅读,以及第一语言的手写稿阅读,成为了年轻人生活的一部分,但实践中,由于知识储备关系,特别是手写稿文字,潦草,连笔字导致字迹不清晰,外行人不容易看懂,现有的文字识别算法或者技术,如:densnet ctc,crnn ctc,resnet ct等,他们的损失函数统一,提取的特征层不一样,对于手写体体,无规律的结构文字,很难去提取特征关键,导致提取识别的文字会出现错误。
技术实现要素:
3.本发明主要针对现有技术所存在的缺陷和不足,提供一种基于神经网络文字图片识别的方法及系统。
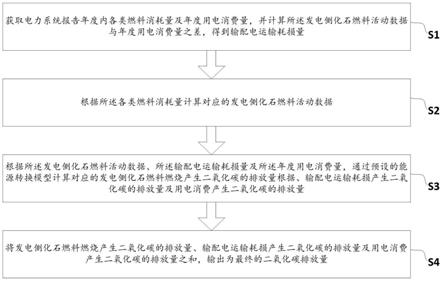
4.本发明公布的一种基于神经网络文字识别图片识别方法,包括以下步骤:s1:获取待识别文本图片,进行转换,形成训练样本图片。
5.s2:对s1中的训练样本图片,通过预处理识别提取特征,得到可编辑文本图片;分析所述可编辑文本图片,分析每一个元素,如:文字、数字、标题、图表、形状、公式、表格、英文、英文等。
6.s3:将所述可以编辑文本图片分析出的每个元素切割成单个模块。
7.s4:将每个模块的信息,输入已经训练好的卷积神经网络模型中,识别出该模块详细的文本内容,得到含有错误字符的待纠错文本;其中所述含错误字符的文本至少含有一个散串的字符,所述散串字符为不满足所述文本的单个字符;若该模块是图片,则只对该模块的位置信息进行记录;若该模块是图表或表格,则需要识别模块中的内容,得到纠错文本。
8.s5:将所述纠纠错文本,合并相邻散落的字符拼凑为组合字符,例如:分别上下组合,左右组合。
9.s6:通过神经网络模型,将所述组合字符与字符文本库进行对比,根据预设的自然语言概率统计模型,从所述候选文本中,选择概率最大的语句替换所述带纠错文本中的错误字符。
10.s7:更新替换字符后的纠错文本,合并各个模块的内容,保存识别后的文本内容。
11.本发明还提供一种基于神经网络文字识别图片识别系统,包括:转换模块:获取待识别文本图片,进行转换,形成训练样本图片。
12.识别分析模块:对转换模块中的训练样本图片,通过预处理识别提取特征,得到可编辑文本图片;分析所述可编辑文本图片,分析每一个元素,如:文字、数字、标题、图表、形
状、公式、表格、英文、英文等。
13.切割模块:将所述可以编辑文本图片分析出的每个元素切割成单个模块;纠错分析模块:将每个模块的信息,输入已经训练好的卷积神经网络模型中,识别出该模块详细的文本内容,得到含有错误字符的待纠错文本。
14.其中,所述含错误字符的文本至少含有一个散串的字符,所述散串字符为不满足所述文本的单个字符;若该模块是图片,则只对该模块的位置信息进行记录;若该模块是图表或表格,则需要识别模块中的内容,得到纠错文本。
15.合并字符模块:将所述纠纠错文本,合并相邻散落的字符拼凑为组合字符,例如:分别上下组合,左右组合。
16.字符替换模块:通过神经网络模型,将所述组合字符与字符文本库进行对比,根据预设的自然语言概率统计模型,从所述候选文本中,选择概率最大的语句替换所述带纠错文本中的错误字符。
17.合并输出模块:更新替换字符后的纠错文本,合并各个模块的内容,保存识别后的文本内容。
18.本发明提供的一种基于神经网络文字图片识别方法及系统,通过对识别文字图片的分析,提取特征,纠正提取后的文本内容,通过神经网络识别替换错误的字符以及文本内容,得到更加简单、准确的文本内容。
附图说明
19.图1示出了本发明的一种基于神经网络文字图片识别方法流程图。
20.图2示出了本发明的一种基于神经网络文字图片识别系统流程图。
具体实施方式
21.为了使本发明实施例的目的,技术方案和有点更加清楚,下面结合附图,对本发明实施例中的技术方案进行清晰、完整的描述,所述实施例仅仅是本发明的一部分,而不是全部的实施例,基于本发明中的实施例,本领域普通的技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
22.本发明的输入是一张图片,格式是jpg或png,所述识别系统也提供摄像头功能,可以拍摄或者获取所需的jpg或png图片。
23.参照图1,本发明提供一种基于神经网络文字图片识别方法,所述方法包括:s1:获取待识别文本图片,进行转换,形成训练样本图片。
24.s2:对s1中的训练样本图片,通过预处理识别提取特征,得到可编辑文本图片;分析所述可编辑文本图片,分析每一个元素,如:文字、数字、标题、图表、形状、公式、表格、英文、英文等。
25.s3:将所述可以编辑文本图片分析出的每个元素切割成单个模块。
26.s4:将每个模块的信息,输入已经训练好的卷积神经网络模型中,识别出该模块详细的文本内容,得到含有错误字符的待纠错文本;其中所述含错误字符的文本至少含有一个散串的字符,所述散串字符为不满足所述文本的单个字符;若该模块是图片,则只对该模块的位置信息进行记录;若该模块是图表或表格,则需要识别模块中的内容,得到纠错文
本。
27.s5:将所述纠纠错文本,合并相邻散落的字符拼凑为组合字符,例如:分别上下组合,左右组合。
28.s6:通过神经网络模型,将所述组合字符与字符文本库进行对比,根据预设的自然语言概率统计模型,从所述候选文本中,选择概率最大的语句替换所述带纠错文本中的错误字符。
29.s7:更新替换字符后的纠错文本,合并各个模块的内容,保存识别后的文本内容。
30.本发明还提供一种基于神经网络文字识别图片识别系统,包括:转换模块:获取待识别文本图片,进行转换,形成训练样本图片。
31.识别分析模块:对转换模块中的训练样本图片,通过预处理识别提取特征,得到可编辑文本图片;分析所述可编辑文本图片,分析每一个元素,如:文字、数字、标题、图表、形状、公式、表格、英文、英文等。
32.切割模块:将所述可以编辑文本图片分析出的每个元素切割成单个模块。
33.纠错分析模块:将每个模块的信息,输入已经训练好的卷积神经网络模型中,识别出该模块详细的文本内容,得到含有错误字符的待纠错文本。
34.其中,所述含错误字符的文本至少含有一个散串的字符,所述散串字符为不满足所述文本的单个字符;若该模块是图片,则只对该模块的位置信息进行记录;若该模块是图表或表格,则需要识别模块中的内容,得到纠错文本。
35.合并字符模块:将所述纠纠错文本,合并相邻散落的字符拼凑为组合字符,例如:分别上下组合,左右组合。
36.字符替换模块:通过神经网络模型,将所述组合字符与字符文本库进行对比,根据预设的自然语言概率统计模型,从所述候选文本中,选择概率最大的语句替换所述带纠错文本中的错误字符。
37.合并输出模块:更新替换字符后的纠错文本,合并各个模块的内容,保存识别后的文本内容。
38.以上所述,仅仅是本发明技术方案的说明,并非用于限定本发明的保护范围,凡在本发明内容包含内所作的任何修改,等同替换,改进都在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。