1.本发明涉及一种基于对抗性干扰的联邦学习成员推理攻击防御方法,旨在对联邦学习场景下参与者协同训练机器学习模型时受到的成员推理攻击进行防御,实现参与者本地数据的隐私保护,属于机器学习中的联邦学习隐私保护技术领域。
背景技术:
2.机器学习主要研究如何利用计算机模拟或实现人类活动,是人工智能领域的研究热点之一。经过几十年的发展,机器学习已经被广泛应用于数据挖掘、计算机视觉、自然语言处理、医学诊断等领域,具有优异的表现。
3.近些年,信息技术的迅速发展促进了数据的指数级增长。为实现支持高性能、大规模训练数据的机器学习模型的训练,利用多节点协作训练模型的分布式机器学习进入了技术人员的视野。由于用户隐私越发受到重视,美国google公司于2016年提出了一种特殊的分布式机器学习技术即联邦学习,该技术通过将用户数据保留在本地,解决了用户本地数据的隐私保护问题。
4.联邦学习,是一种实现多个参与者在保护本地数据隐私的前提下协同训练机器学习模型的分布式机器学习技术。联邦学习包含服务器和多个参与者(即客户端),其具体流程为:服务器将全局模型分发给多个参与者,每个参与者用本地数据训练模型并将模型参数发送给服务器,服务器将所有收到的模型参数进行聚合并利用聚合后的模型参数更新全局模型,重复以上步骤直至训练终止。由于参与者无需暴露本地数据,只需上传模型参数,因此,联邦学习保护了参与者本地数据隐私。
5.然而,虽然参与者不必再上传本地数据,但参与者与服务器之间交互的模型参数中包含与训练数据有关的信息,这导致联邦学习容易受到成员推理攻击。
6.成员推理攻击可以推断数据是否在训练模型时被使用,一旦攻击者攻击成功,参与者隐私便具有被泄露的风险。例如,当利用多家医院的医疗数据协同训练模型时,若攻击者掌握了判断数据是否在训练模型时被使用的能力,则可能会推测出患者的健康状况。因此,有必要研究如何防御成员推理攻击。
7.为了能够同时满足联邦学习场景中用户数据隐私保护和协同训练高性能模型的需求,必须采用合适的技术方法,在保护用户数据隐私的同时训练出具有高性能的模型。
技术实现要素:
8.本发明的目的是为了解决现有联邦学习易受到成员推理攻击从而泄露用户本地数据隐私的技术问题,根据联邦学习的流程以及成员推理攻击的特点,创造性地提出了一种基于对抗性干扰的联邦学习成员推理攻击防御方法。
9.本发明的创新点在于:建立了一种联邦学习成员推理攻击防御机制,在每次参与者上传利用本地数据训练好的模型参数之前,向模型参数中添加精心设计的对抗性干扰,使攻击者针对使用此种防御机制训练出来的模型进行成员推理攻击后得到的攻击准确率
尽可能趋近50%(攻击结果趋近于随机猜测的攻击结果)并尽可能降低对目标模型性能的影响,从而同时满足联邦学习场景中用户数据隐私保护和协同训练高性能模型的需求。
10.本发明采用以下技术方式实现。
11.本方法,基于联邦学习成员推理攻击防御模型,该模型包括联邦学习训练模型成员推理攻击防御模型和模型数据
12.其中,联邦学习训练模型是参与联邦学习本地模型训练的参与者的集合和参与联邦学习模型聚合与分发的服务器的并集,即,的并集,即,的并集,即,为中参与者个数。联邦学习训练模型中的参与者与服务器,基于平均聚合的算法,共同合作训练机器学习模型。其中,平均聚合是指服务器对接收的全部模型参数求平均值,并将该平均值作为新的全局模型的模型参数。
13.成员推理攻击防御模型是攻击模型噪声生成器和噪声优化器的并,即,其中,攻击模型是为了进行成员推理攻击而训练的模型,它通过对参与者训练的本地模型进行成员推理攻击来推断该模型被成员推理攻击成功的概率,即,受到成员推理攻击的风险;噪声生成器负责与攻击模型进行交互,首先根据本地模型参数值初始化噪声,并将其加入参与者训练好的本地模型中,然后使用攻击模型攻击该加噪声模型,当攻击模型对加噪声模型进行攻击得到的攻击准确率较高时,噪声生成器增大生成的噪声,当攻击模型对加噪声模型进行攻击得到的攻击准确率较低时,噪声生成器减小生成的噪声,噪声生成器根据攻击模型的反馈修改生成的噪声,从而得到精心设计的对抗噪声,最终实现训练的目标模型在最大化降低成员推理攻击准确率的同时尽量降低模型准确率的损失。
14.由于每个参与者都在本地生成的模型参数上添加噪声并发送给服务器,如果服务器直接对这些模型参数进行平均聚合会造成噪声的累加,意味着全局模型中的噪声将会随着参与者数量的增多而呈线性增加的趋势,从而影响最终训练的目标模型的模型准确率。因此,使用噪声优化器对噪声进行优化,即确定每个参与者在本地模型参数上所加噪声的缩放因子,使聚合的全局模型中的噪声与参与者数量无关,进而保证目标模型的模型准确率。
15.攻击模型噪声生成器和噪声优化器的关系为:参与者训练使和不断进行交互,最终使生成抵御成员推理攻击的最小噪声,之后利用确定噪声的缩放因子,最后将缩放后的噪声加入本地模型参数并将加噪声参数发送给服务器。
16.联邦学习训练模型和成员推理攻击防御模型的关系为:参与者和服务器根据进行联邦学习模型训练,每个参与者利用本地数据训练好本地模型后使用构造精心设计的噪声并对噪声进行优化,服务器使用根据参与者数量计算缩放因子并随机发送给各个参与者,参与者根据缩放因子缩放噪声并添加到本地模型参数中,然后按照继续执行联邦学习模型训练(即参与者上传加噪声的本地模型参数,服务器对模型参数进行聚合并更新全局模型),此为联邦学习的一个轮次,之后按照以上流程重复多轮次直至
模型训练终止。
17.其中,模型数据的数据集合为其中,模型数据的数据集合为集合中的元素代表着每条数据的序号;数据集中共有条数据,包括用于参与者本地训练模型的训练数据集和用于测试模型的测试数据集即即即是训练数据集中的数据数量,是测试数据集中的数据数量。
18.模型数据与联邦学习训练模型的关系具体为:参与者集合中第i个参与者拥有的训练数据集合表示为测试集合表示为集合是的子集,集合是的子集,即模型数据中的训练数据集被平均分成份并分别被个参与者所拥有,模型数据中的测试数据集被平均分成份并分别被个参与者所拥有,即且且且i大于等于1且小于等于
19.一种基于对抗性干扰的联邦学习成员推理攻击防御方法,包括以下步骤:
20.步骤1:根据参与者数量将训练数据集和测试数据集平均划分成份,得到和将划分后的数据分配给各个参与者每个参与者使用自己拥有的数据训练本地模型并得到模型参数。
21.步骤2:参与者训练攻击模型,让噪声生成器和攻击模型不断进行交互,得到可以使攻击模型对加噪声的本地模型攻击准确率尽可能趋近50%(使攻击结果趋近于随机猜测的攻击结果)的最小噪声,使攻击模型无法区别某一条数据是否是训练本地模型时使用的训练数据,从而保护参与者本地隐私。
22.具体地,步骤2可以包括以下步骤:
23.步骤2.1:利用信噪比snr(signal noise ratio),根据式1、式2和式3生成符合高斯分布的噪声向量。
24.首先,设置最小信噪比snr
min
和最大信噪比snr
max
,其中,snr
min
使生成的噪声为0,snr
max
使生成的噪声接近本地模型的参数。
25.然后,取并使用此信噪比根据式1、式2和式3生成一个初始化噪声。
[0026][0027][0028][0029]
其中,n为本地模型参数,snr是控制生成的噪声大小的信噪比,ps代表原始信号强
度,pn代表噪声信号强度,指根据信噪比生成的噪声noise符合均值为0,标准差为的高斯分布的噪声,n表示高斯分布。
[0030]
步骤2.2:将初始化噪声加入本地模型参数中,使用ml_privacy_meter工具训练攻击模型。
[0031]
具体地,每个参与者从本地拥有的条训练数据中选择条数据,从条测试数据中选择条数据,将包括数据集和加噪声模型、攻击模型训练数据和测试数据的划分比例、成员推理攻击使用加噪声模型选定层的选定信息(例如,成员推理攻击使用加噪声模型的最后一层的输出标签、最后两层的梯度)在内的配置信息,输入到ml_privacy_meter工具;
[0032]
该工具把条数据输入加噪声模型,从模型指定层得到的信息作为特征,标签为1,从而得到成员数据集;把条数据输入加噪声模型,将从模型指定层得到的信息作为特征,标签为0,从而得到非成员数据集;
[0033]
然后,按照训练数据和测试数据的划分比例,从成员数据集和非成员数据集中分别选择设定比例的数据汇总到一起,作为攻击模型的训练数据集,将剩余数据汇总到一起,作为攻击模型的测试数据集,从而对加噪声模型训练攻击模型并进行成员推理攻击,得到攻击准确率。攻击准确率(成员推理风险)是攻击模型正确预测的数据占总预测数据的百分比。
[0034]
步骤2.3:使用攻击模型攻击该加噪声模型后,根据攻击模型反馈不断修改snr,使最终攻击模型的攻击准确率尽可能趋近50%。
[0035]
具体地,步骤2.3可以包括以下步骤:
[0036]
步骤2.3.1:当使用攻击模型攻击该加噪声的本地模型,得到该模型受到成员推理攻击的风险(即攻击准确率)之后,对该风险值进行判断。
[0037]
如果该风险大于0.5 ε,则说明生成的噪声太小,此时噪声生成器增大最小信噪比snr
min
,snr的值越小,生成的噪声的范数越大。
[0038]
如果该风险小于0.5
‑
ε,则生成的噪声太大,此时噪声生成器减小最大信噪比snr
max
。
[0039]
其中,ε是设置的攻击模型准确率偏离0.5的阈值,该阈值的设置使攻击模型对添加了最终噪声的本地模型的攻击准确率能够尽可能接近50%。
[0040]
步骤2.3.2:取使用此更新后的信噪比,根据式1、式2和式3生成新的噪声;
[0041]
步骤2.3.3:重复步骤2.3.1至步骤2.3.2,不断根据攻击模型的反馈修改最小信噪比snr
min
和最大信噪比snr
max
,使逼近想要的取值,直至达到设置的轮次。
[0042]
步骤3:服务器利用噪声优化器根据式4和式5得到噪声的缩放因子,并随机发送给各个参与者。参与者利用缩放因子缩放噪声,将噪声加入本地模型参数并发送给服务器:
[0043][0044][0045]
其中,m为参与者数量,γ1,γ2,
…
,γ
m
分别是m个参与者产生的噪声的缩放因子;x为一个变量,根据参与者数量m计算得到。
[0046]
步骤4:服务器接收所有参与者发送的模型参数,并对这些模型参数求平均值,将平均后的模型参数作为新的全局模型参数。
[0047]
步骤5:服务器将全局模型参数发送给所有参与者,使参与者更新本地模型,至此,完成了联邦学习模型训练的一个轮次。
[0048]
重复步骤1至步骤5,直到达到设置的指定训练轮次,从而完成可防御成员推理攻击的联邦学习模型训练,利用该模型实现防御成员推理攻击。
[0049]
有益效果
[0050]
本方法,通过在参与者上传的模型参数中添加对抗性干扰,实现对基于梯度的成员推理攻击的防御,从而保护参与者本地数据隐私。能够在保护用户本地数据隐私的同时,尽量不降低训练得到的模型的性能。
[0051]
对比现有技术,本方法具有以下优点:
[0052]
1.本发明适用于联邦学习成员推理攻击的防御,保护了参与者的本地数据隐私;
[0053]
2.本发明考虑了在联邦学习训练模型过程中参与者训练好本地模型后向服务器发送模型参数时造成的隐私泄露问题,通过向模型参数中添加精心构造的噪声,使基于对抗性干扰的成员推理攻击防御方案适用于防御基于梯度的成员推理攻击的场景;
[0054]
3.本发明针对构造噪声这一问题提出了使用噪声生成器和噪声优化器的方案,使构造的噪声能够防御成员推理攻击的同时尽可能降低目标模型的模型准确率损失,即降低噪声对最终训练得到的目标模型的性能的影响,从而同时满足了联邦学习场景中用户数据隐私保护和协同训练高准确率模型的需求;
[0055]
4.通过大量数据证明,本方法对联邦学习本地训练的模型参数中添加精心设计的噪声,能够实现接近50%的成员推理攻击准确率,同时降低了目标模型的准确率损失。
附图说明
[0056]
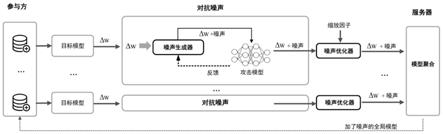
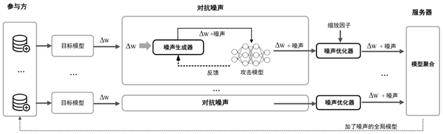
图1是本发明方法的学习成员推理攻击防御模型示意图。
具体实施方式
[0057]
下面结合附图和实施例,具体说明本发明“一种基于对抗性干扰的联邦学习成员推理攻击防御方法”的过程,并阐述其优点。应当指出,本发明的实施不限于以下实施例,对本发明所做任何形式上的变通或改变将落入本发明保护范围。
[0058]
实施例1
[0059]
本实施例中,建立了一种基于对抗性干扰的联邦学习成员推理攻击防御方法所依托的联邦学习成员推理攻击防御模型,如图1所示。
[0060]
图1描述了以下联邦学习成员推理攻击防御场景。
[0061]
该场景中共有100个参与者,1个服务器;参与者训练本地模型并上传参数,服务器对参数进行聚合并更新全局模型为联邦学习训练过程的一个轮次,该场景下共进行100个联邦学习轮次;每个参与者每次训练本地模型时迭代5个轮次;设置联邦学习的参数batch size=128,learning rate=0.1,momentum=0.9,milestones=[60,90],其中batch size为批处理大小即参与者训练本地模型时一次训练时的数据数量,learning rate为学习率,momentum为动量即表示要在多大程度上保留原来的更新方向,milestones表示学习率更新的起止区间,[60,90]表示在联邦学习的前60个轮次学习率不改变,在60到90个轮次学习率缩小为0.01,在90到100个轮次学习率缩小为0.001;目标模型为带有四个大小为1024、512、256、128的隐藏层的全连接网络,使用relu激活函数和sgd优化器,为当前gpu设置随机种子seed=117以保持稳定的性能;攻击模型将目标模型的最后两层的损失梯度和输出作为输入的特征,将输入特征展平为一维向量,并使用具有100个大小为(1,100)的卷积核的卷积神经网络来提取输入特征,最大池化大小为(1,2),两个全连接层的大小分别为128和64,攻击模型使用relu激活函数和adam优化器,学习率为0.001;在执行联邦学习模型训练过程中,参与者和服务器均是半诚实的并且两者可能相互勾结,这意味着执行成员推理攻击的攻击者拥有三种能力,一是可以获得与参与者拥有的数据集具有相似分布的辅助数据集,二是可以获得参与者训练的本地模型的模型参数,三是可以获得目标模型的模型结构,即可以发起白盒成员推理攻击。
[0062]
依托于上述图1中的模型,具体实施本发明所述方法时,包括以下步骤:
[0063]
步骤1:根据参与者数量将训练数据集和测试数据集平均划分成份得到和将划分后的数据分配给各个参与者每个参与者使用自己拥有的数据训练本地模型并得到模型参数。
[0064]
具体到本实施例,模型数据集是purchase100数据集(https://www.kaggle.com/c/acquire
‑
valued
‑
shoppers
‑
challenge/data),它包含数千名在线客户的购物记录,根据购物的相似性,购物记录被分成100类,其主要任务是识别每个用户的购买类别;数据集包含联邦学习模型训练需要的训练数据集和测试数据集,共有条数据,其中包括训练数据条,测试数据条;100个参与者每轮都参与模型训练,模型数据中的训练数据集和测试数据集被平均分成份并分别被个参与者所拥有,即每个参与者拥有100条训练数据和100条测试数据;每个参与者使用自己拥有的数据训练本地模型并得到模型参数。
[0065]
步骤2:参与者训练攻击模型,让噪声生成器和攻击模型不断进行交互得到可以使攻击模型对加噪声的本地模型攻击准确率尽可能趋近50%(使攻击结果趋近于随机猜测的攻击结果)左右的最小噪声,使攻击模型无法区别某一条数据是否是训练本地模型时使用的训练数据,从而保护参与者本地隐私,具体为:
[0066]
步骤2.1:设置最小信噪比snr
min
和最大信噪比snr
max
,其中,snr
min
使生成的噪声为0,snr
max
使生成的噪声接近本地模型的参数,得到使生成的噪声接近本地模型的参数,得到然后利用该信
噪比snr根据式1、式2和式3生成符合高斯分布的初始化噪声向量。
[0067]
步骤2.2:将初始化噪声加入本地模型参数中,使用ml_privacy_meter工具训练攻击模型;具体到本实施例,分别从和中选择5000条数据用于构建攻击模型的训练集和测试集;具体到每个参与者来说,每个参与者从本地拥有的条训练数据中选择条数据,从条测试数据中选择条数据,并将两个数据集和加噪声模型、攻击模型训练数据和测试数据的划分比例10%、成员推理攻击使用加噪声模型最后两层的损失梯度和输出这些配置信息输入ml_privacy_meter。
[0068]
该工具把条数据输入加噪声模型,将模型最后两层的损失梯度和输出作为特征,标签为1,从而得到成员数据集;把条数据输入加噪声模型,将模型最后两层的损失梯度和输出作为特征,标签为0,从而得到非成员数据集;然后按照训练数据和测试数据的划分比例10%从成员数据集和非成员数据集中分别选择90%的数据汇总到一起作为攻击模型的训练数据集,剩下的10%数据汇总到一起作为攻击模型的测试数据集,从而对加噪声模型训练攻击模型并进行成员推理攻击得到攻击准确率。
[0069]
步骤2.3:使用攻击模型攻击该加噪声模型后,根据攻击模型反馈不断修改snr,使最终攻击模型的攻击准确率尽可能趋近50%。
[0070]
具体到本实施例,根据攻击模型的反馈即攻击准确率不断调整信噪比snr并得到信噪比snr=15,从而使根据式1、式2和式3生成符合高斯分布的噪声向量满足抵抗成员推理攻击的要求。
[0071]
步骤3:服务器利用噪声优化器根据式4和式5,得到100个参与者生成的100个噪声的缩放因子并随机发送给各个参与者,参与者利用缩放因子缩放噪声,将噪声加入本地训练的模型参数并发送给服务器。
[0072]
步骤4:服务器接收所有参与者发送的模型参数并对这些模型参数求平均值,将平均后的模型参数作为新的全局模型参数。
[0073]
步骤5:服务器将全局模型参数发送给所有参与者,使参与者更新本地模型,至此完成了联邦学习模型训练的一个轮次,之后重复步骤1、2、3、4、5直到达到100个轮次,完成可防御成员推理攻击的联邦学习模型训练。
[0074]
使用攻击模型攻击最终训练得到的目标模型并计算攻击准确率a
att
=0.51,使用最终训练得到的目标模型对训练数据集数据进行预测并计算训练准确率a
train
=0.96,对测试数据集数据进行预测并计算测试准确率a
test
=0.91,计算a
train
和a
test
的差值得到泛化误差e
gen
=0.05。
[0075]
重复以上步骤(跳过步骤2和步骤3的噪声优化部分)进行无防御的联邦学习模型训练,模型参数及模型数据均与加防御的联邦学习模型训练相同,使用攻击模型攻击最终训练得到的目标模型并计算攻击准确率a
′
att
=0.73,使用最终训练得到的目标模型对训练数据集数据进行预测并计算训练准确率a
′
train
=0.98,对测试数据集数据进行预测并计算测试准确率a
′
test
=0.93,计算a
′
train
和a
′
test
的差值得到泛化误差e
′
gen
=0.05。
[0076]
结果表明,在使用purchase100数据集、四层全连接神经网络作为目标模型时,攻
击模型对不加防御方法训练得到的目标模型的攻击准确率为73%,对加防御方法训练得到的目标模型的攻击准确率为51%,即使用防御方法训练出的目标模型大幅度提高了对成员推理攻击的防御能力,攻击准确率从73%下降到了51%,趋近于随机猜测的攻击结果;而且,不加防御方法训练得到的目标模型的训练准确率与加防御方法训练得到的目标模型的训练准确率相比仅下降了2%,测试准确率也是如此,这代表目标模型的性能并没有因防御方法的使用而受到显著影响,除此以外,不加防御方法训练得到的目标模型的泛化误差与加防御方法训练得到的目标模型的泛化误差相同;这些结果表明防御方法的使用在保证目标模型的性能的前提下有效地防御了成员推理攻击,同时满足了联邦学习场景中用户数据隐私保护和协同训练高性能模型的需求。
[0077]
实施例2
[0078]
本实施例是将本发明所述方法在多种场景下的结果进行对比,验证本发明的防御方法适用于多种数据集和目标模型结构。对于purchase100数据集,使用全连接神经网络作为目标模型;对于cifar10数据集(http://www.cs.toronto.edu/~kriz/cifar.html),使用用于图像分类的alexnet模型作为目标模型;对于cifar100数据集(http://www.cs.toronto.edu/~kriz/cifar.html),分别使用alexnet模型和densenet12模型作为目标模型,densenet12对应为densenet
‑
bc(深度l=100,每个网络层输出的特征图数量k=12);使用不同的数据集与目标模型结构进行不加防御(跳过步骤2和步骤3的噪声优化部分)和加防御的联邦学习模型训练时,由于cifar100数据集的限制需将cifar100
‑
densenet12中的参与者数量设置为20以外,其余涉及的参数值保持一致。
[0079]
不同数据集和目标模型结构下不加防御和加防御方法训练的模型性能结果如表1所示。
[0080]
首先,四种不同的数据集
‑
目标模型结构下训练的加防御方法均可大幅降低攻击准确率并且攻击准确率均尽可能接近50%,趋近于随机猜测的攻击结果,这表明该防御方法适用于多种数据集和目标模型结构下的成员推理攻击防御,并且具有优越的防御效果;其次,四种不同的数据集
‑
目标模型结构下不加防御方法训练得到的目标模型的训练准确率与加防御方法训练得到的目标模型的训练准确率相比没有显著变化,测试准确率也是如此,这表明该防御方法在多种数据集和目标模型结构下均可保证目标模型的性能不会因防御方法的增加而变差;最后,四种不同的数据集
‑
目标模型结构下不加防御方法训练得到的目标模型的泛化误差与加防御方法训练得到的目标模型的泛化误差相比没有显著变化,这说明该防御方法在多种数据集和目标模型结构下均可保证目标模型的泛化性能不受影响;总的来说,这些结果表明该防御方法在多种不同的数据集
‑
目标模型结构下能够在保证目标模型的性能的同时有效地防御成员推理攻击,同时满足了联邦学习场景中用户数据隐私保护和协同训练高性能模型的需求,即该防御方法适用于多种数据集和目标模型结构。
[0081]
表1不同数据集和目标模型结构下不加防御和加防御方法训练的模型性能
[0082][0083]
实施例3
[0084]
本实施例是将本发明所述方法与多种联邦学习成员推理攻击防御方法进行对比,验证本发明的防御方法与其他防御方法相比具有更好的成员推理攻击防御效果并且能够保持更低的性能损失。
[0085]
使用cifar10作为数据集和alexnet模型作为目标模型;不使用防御方法训练得到的目标模型具有79%的攻击准确率、95%的训练准确率、0.1%的训练损失;本发明提出的防御方法具有的53%的攻击准确率、95%的训练准确率、0.1%的训练损失。
[0086]
对比的第一种防御方法(https://dl.acm.org/doi/abs/10.1145/3243734.3243855)是一种基于对抗性正则化的联邦学习成员推理攻击防御方法ad
‑
reg;设置ad
‑
reg的对抗性正则化因子λ=2,ad
‑
reg具有59%的攻击准确率、99%的训练准确率以及0.5%的训练损失;结果显示本发明的防御方法与ad
‑
reg相比具有更低的攻击准确率以及更小的训练损失。
[0087]
对比的第二种防御方法(https://www.ndss
‑
symposium.org/wp
‑
content/uploads/2019/02/ndss2019_03a
‑
1_salem_paper.pdf)通过分别使用l2正则化和dropout来防止模型过拟合从而实现对成员推理攻击的防御;l2正则化是在损失函数中加入l2正则化项,dropout是随机地使一些神经元失效;l2泛化因子和dropout率分别设置为0.001和0.5,使用l2正则化的防御方法具有60%以上的攻击准确率、90%的训练准确率和0.2%的训练准确率损失,使用dropout的防御方法具有60%以上的攻击准确率、83%的训练准确率和0.38%的训练损失;结果显示本发明的防御方法与第二种防御方法相比具有更低的攻击准确率以及更小的训练损失。
[0088]
对比的第三种防御方法(https://dl.acm.org/doi/abs/10.1145/2976749.2978318)是基于差分隐私的联邦学习成员推理攻击防御方法dpsgd,该种方法通过在参与者训练的本地模型参数中加入符合高斯分布的差分隐私噪声来防御成员推理攻击;设置δ=0.00001,ε=2,dpsgd具有63%的攻击准确率、94%的训练准确率以及10%的测试损失,而本发明的防御方法只有1%的测试损失;结果显示本发明的防御方法与ad
‑
reg相比具有更低的攻击准确率以及更小的测试损失。
[0089]
以上结果表明,本发明的防御方法与其他防御方法相比能够在保持目标模型的性
能的同时实现更好的成员推理攻击防御效果。
[0090]
实施例4
[0091]
本实施例是将本发明所述方法在多种场景下的结果进行对比,验证本发明的防御方法适用于多种参与者数量的场景,即参与者数量的变化不会影响本防御方法的防御效果以及仍旧能够保持较低的性能损失。
[0092]
设置不同数据集和目标模型结构以及参与者数量,使用本发明的防御方法训练模型并计算目标模型的攻击准确率和泛化误差,结果如表2所示。结果显示,在不同数据集和目标模型结构以及参与者数量(分别为50、100以及150人)下,目标模型的攻击准确率均可接近50%,且泛化误差并没有显著变化;总的来说,当参与者数量变化时,本发明的防御方法仍旧可以在保持目标模型的性能的同时实现优越的成员推理攻击防御效果。
[0093]
表2不同数据集和目标模型结构以及参与者数量下本发明防御方法训练的模型性能
[0094][0095]
实施例5
[0096]
本实施例从模型梯度的角度评估了本发明的防御方法在防御数据重建攻击中的可移植性,验证了本发明的防御方法对于防御数据重建攻击具有可移植性。数据重建攻击是指重建训练模型时使用的训练数据,这就意味着一旦数据重建攻击成功,攻击者可以同时实现成员推理攻击,因为攻击者已经掌握了训练数据,只要在训练数据中的数据便是成员数据,反之为非成员数据;zhu等人提出了一种基于梯度的数据重建攻击方法(https://link.springer.com/chapter/10.1007/978
‑3‑
030
‑
63076
‑
8_2):假设虚拟输入和标签并计算虚拟梯度,通过优化虚拟梯度和真实梯度之间的距离,使虚拟数据靠近原始数据,从而实现数据的重建;为评估本发明的防御方法对于数据重建攻击的可移植性,需要将本发明的防御方法根据不同信噪比snr生成的噪声添加到梯度中,然后再进行数据重建攻击;数据集使用该数据重建攻击方法提供的数据集。
[0097]
结果显示,当不加入本发明的防御方法生成的噪声,直接进行数据重建攻击时,该攻击可以恢复原始数据;将信噪比snr分别设置为25、20和15并将根据信噪比生成的噪声添加到梯度中,然后分别进行数据重建攻击时发现,随着信噪比的减小,数据重建攻击效果逐渐变弱,当snr=15时,该攻击已经无法重建原始数据,即攻击失败;该结果表明,本发明的防御方法对于防御数据重建攻击具有可移植性,即本发明的防御方法生成的对抗性干扰可以用于防御基于梯度的数据重建攻击。
[0098]
以上所述结合附图和实施例描述了本发明的实施方式,但是对于本领域技术人员
来说,在不脱离本专利原理的前提下,还能够做出若干改进,这些也是为属于本专利的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。