用于确定rna序列的方法和设备
技术领域
1.本发明涉及用于借助于所学会的策略确定rna序列的方法、训练设备、计算机程序和机器可读存储介质。
背景技术:
2.因为已经表明许多功能性rna分子参与用于转录、表观遗传学和翻译的调节过程,所以rna分子的设计最近引起了医学、合成生物学、生物技术和生物信息学的兴趣。由于rna的功能取决于其结构特性,因此rna设计问题在于找到满足给定结构约束的rna序列。
3.出版物runge等人的learning to design rna(in international conference on learning representations, 2019。可在线检索:)公开一种用于在使用“深度强化学习(deep reinforcement learning)”情况下的rna设计问题的算法,用于训练策略网络,顺序地设计对应于预给定目标结构的整个rna序列。
技术实现要素:
4.发明优点然而,rna设计的所有当前表达均强烈地约束其解空间,其方式是所述表达对整个分子或至少对期望的分子的完整形式需要结构优先级。
5.与此相比,本发明具有以下优点:可以探索更大的搜索空间,也即可以产生/找到之前在计算技术上未能找到的具有实际相关性的多样化得多的候选序列。到目前为止,无法处理不平衡的括号和部分结构。利用本发明,可以在
‘
设计任务(design task)’之内进行定义并且找到解决方案。
6.此外,该方法能够将所学会的知识转移到以前rna设计表达的任务。由此可以更高效地找到rna序列。根据本发明的部分rna设计可以被理解为逆rna设计和具有序列预设的逆rna设计的超级问题。
7.发明的公开内容在第一方面中,本发明涉及一种用于创建策略()的计算机实现的方法,所述策略被设立用于根据预给定二级结构的片段来确定核苷酸在一级rna结构内的定位。
8.所述方法包括以下步骤:对策略进行初始化。例如,可以通过神经网络来实现该策略。于是为此可以对策略初始化,其方式是例如随机地调整神经网络的权重。
9.接着是提供任务表示(),其中所述任务表示()包括二级rna结构的结构约束()和一级rna结构的顺序约束()。接着是根据所述任务表示()借助于所述策略()确定一级候选rna序列(),其中借助于所述策略(),利用所述策略()的所确定的核苷酸逐渐地占据所述候选rna序列()的一级rna结构的位点。接着是针对所述顺序约束()确
定所述候选rna序列()的序列损失();将(rna)折叠算法(faltungsalgorithmus)f应用于所述候选rna序列()。接着是确定在折叠的结构()和预给定结构约束()之间的结构损失();根据所述序列损失()和所述结构损失()确定总损失()。
10.接着是借助于强化学习算法对所述策略()进行适配,使得优化所述总损失()。
11.提出,该片段与参数有关,其中所述参数在对所述策略进行优化时一起被优化。
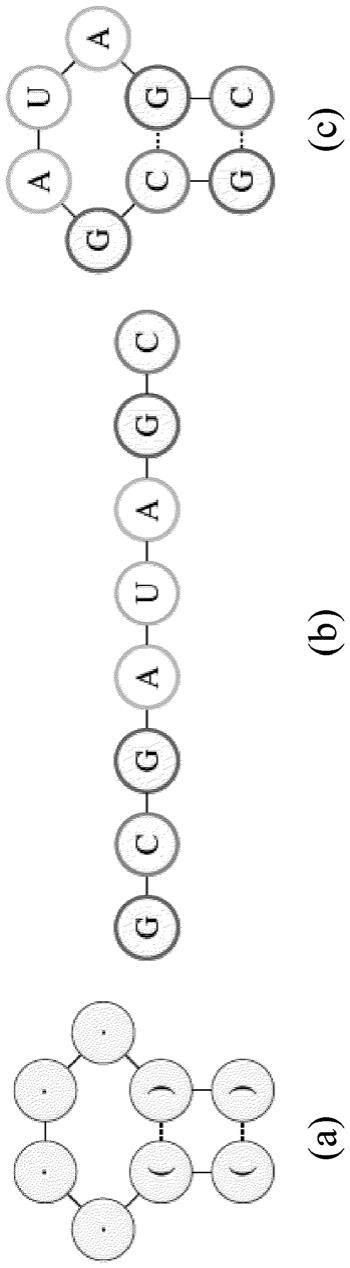
12.在第二方面中,本发明涉及一种用于借助于所学习的根据前述权利要求中任一项所述的策略()确定给定rna的部分二级结构和部分一级结构的rna序列()的方法,所述策略被设立用于根据二级结构的片段来确定rna的核苷酸的定位,所述方法包括以下步骤:提供所述任务表示()并且根据所述任务表示()的片段借助于策略逐渐地确定候选rna序列()。
13.在其他方面中,本发明涉及分别被设立用于执行上述方法的设备以及计算机程序,以及在其上存储有该计算机程序的机器可读存储介质。
附图说明
14.下面参照所附附图更详细地阐述本发明的实施方式。在附图中:图1示出rna设计问题的示意图;图2示意性地示出本发明实施方式的实施例;图3示出强化学习算法的超参数优化的示意图;图4示出具有可能超参数的表格;图5示出训练设备的可能结构。
具体实施方式
15.rna在其最基本的结构形式中是四个核苷酸腺嘌呤(a)、鸟嘌呤(g)、胞嘧啶(c)和尿嘧啶(u)的序列。该核苷酸序列被称为rna序列或一级结构。
16.在rna序列用作构建图期间,通过折叠来确定rna分子的功能结构,所述折叠将rna序列转化为其3d三级结构。该序列的固有热力学特性确定所得出的折叠。在两个相对应的核苷酸之间构成的氢桥键表示热力学模型中的驱动力之一,并且强烈影响三级结构。包括这些氢桥键的结构通常被称为rna的二级结构。
17.找到折叠成期望的二级结构的rna序列的问题已知为rna设计问题(英语:rna design problem)或rna逆折叠(英语:rna inverse folding)。
18.图1示意性地示出在使用折叠算法f和点括号记法(punkt-klammer-notation)情况下对rna设计问题的图解。鉴于以点括号记法(a)表示的期望的rna二级结构,任务在于设计rna序列(b),所述rna序列(b)折叠成期望的二级结构(c)。
19.在下面,应该定义“部分rna设计”并且阐述本发明的一种实施方式,以便不仅将序列特征而且将结构特征集成到简单、共同的任务表示中,以尤其是支持跨越不同的rna设计任务的知识传递。
20.rna设计考虑两个搜索空间:序列空间包括核苷酸链,而结构空间由典型的二级结构特征的序列组成。应该注意的是,在这里使用根据ivo hofacker、walter fontana、peter stadler、sebastian bonhoeffer、manfred tacker和peter schuster的fast folding and comparison of rna secondary structures(化学月刊)125:167
–
188, 02 1994的常用点括号记法。
21.rna折叠算法f通过将长度为的rna序列映射成其相对应的二级结构在这些空间之间进行转化。
22.rna设计致力于相反的过程:给定二级结构特征的序列,目标是找到rna序列,使得所述rna序列满足方程。
23.可以使用附加的序列限制来排除解空间的部分,这使rna设计成为np难题,参见https://www.liebertpub.com/doi/full/10.1089/cmb.2019.0420。
24.部分rna设计通过允许结构空间中不受约束的域来扩展该表达,这可能导致包含非均衡括号的rna设计任务,并且通过计算机辅助方法打开用于勘测的大门。形式上可以如下定义部分rna设计:是rna折叠算法,并且是长度为的结构限制序列,其将有效rna二级结构的空间限制到,并且表示核苷酸限制序列,其将有效rna序列的空间限制到,于是部分rna设计的目标在于找到rna序列,所述rna序列满足以下方程:。
25.由于目标是为每种任意结构和序列特征设定(包括部分和完全定义的结构限制在内)预测合理的rna序列,所以在下面应该使用rna设计任务的简单的、但一般的表示,以便能够实现在不同rna设计任务之间的知识转移。因此,结构和序列约束的两个序列被组合成共同的表示。共同的表示在下面也被称为任务表示,参见图2。
26.附加地,定义函数,该函数将rna序列的每个点(在下面也被称为位点(stelle))从约束以唯一一个表示映射到(对于和)或者在所有
其他情况下映射到。
27.附加地,可以实施预处理步骤,所述预处理步骤使用配对位点,其中仅一个对于相互作用的核苷酸是已知的,用其互补配对伙伴(根据沃森-克里克碱基配对方案(watson-crick-basenpaarungsschema))填充。可以跳过不能以微不足道的方式确定配对伙伴的位点,并且在下一配对位点处继续。
28.在强化学习(英语:reinforcement learning,rl)中,代理经由感知和动作利用动态的环境来行动。在交互的每个步骤时,代理获得对环境的当前状态的指示,并且根据该观察选择行动。行动改变环境的状态,并且该过渡的值作为标量奖励信号被通知给代理。代理的最终目标是最大化奖励信号的长期度量。由于动作可能影响状态过渡并且从而影响所有后续奖励,因此实现最优行为可能是非常困难的任务。尤其是,代理未被告知:从长远来看哪个动作将会关系到其最佳利益,并且因此该代理以由多个不同的算法、诸如时间差学习(td)、q学习或者策略梯度方法(英语:policy gradient methods)引导的方式通过系统试验进行搜索。
29.用于逆rna折叠的rl算法已由runge等人提出(参见上面背景技术段落),其用作本发明的基础。在rl情况下,使代理的策略(英语:policy,)与人工神经网络近似,所述人工神经网络例如输出关于行动的分布。而环境可以完全由决策过程定义,所述决策过程提供一系列可用行动、一系列状态、奖励函数和状态过渡概率矩阵。为了将部分rna设计建模为加强学习问题,参考由runge等人描述的方案:状态的表达基于所提供的分子特征,并且行动对应于核苷酸的定位。一旦核苷酸被分派给所有位点,环境就根据汉明距离计算奖励,所述汉明距离被通知给所述代理用于更新其模型。于是然后借助于rl算法调整策略,使得所述策略最小化汉明距离。决策过程的精确表达和策略网络的架构可以与其他参数一起共同地被优化。
30.大多数逆rna折叠算法使用结构损失函数来量化目标结构与由rna序列的折叠得出的结构之间的差。最优候选结构(也称为最小化器(minimierer))具有损失函数的最小值,并且对应于用于预给定目标结构的逆rna折叠问题的解。
31.常见的损失函数是汉明距离。对于部分rna构造,期望的结构可以仅部分地是已知的,并且解空间附加地在序列空间中可以是受约束的。因此,runge等人的先前提出的损失表达被适配,以便仅考虑所设计的候选解的位点,所述位点要么在结构空间中、在序列空间中要么这两者都受约束。只要站点不受限制,该站点就从间距的计算中被排除,并且从而从损失函数的计算中被排除。这可以借助于指示符函数被形式化,如果位点受约束,则所述指示符函数对于长度的约束c的序列返还值1,而如果位点不受约束,则返还0。
32.于是,部分定义的约束的损失可以通过对核苷酸约束序列的受约束位点与所设计的候选解的相对应位点之间;以及在结构约束的序列的受约束位点与折叠
的相对应位点之间的汉明距离求和来表述。在长度的核苷酸边界条件的序列情况下,这导致序列损失:与此相对应地,结构损失可以被如下表达:特定rna任务表示和所设计的特定候选解的总损失于是可以被定义为:最小化器于是通过:给出可以通过不同的方式实现包含序列约束。因此,为用于共同的配置空间中的候选解的生成设计的三种不同方案设置了维度,所述方案在以下段落中予以描述。
33.单纯方案:对于单纯方案,代理预告针对rna设计任务的每个位点的核苷酸,包括序列部分在内。
34.替换方案(
‘
替换’):替换方案遵循与单纯方案相同的策略,但是一旦所有位点被核苷酸占据,在所设计的rna序列被奖励之前,任务表示的序列部分替换候选解的相对应的预测部分。
35.部分方案(
‘
部分’):在第三方案情况下,任务表示的序列域被完全忽略,并且代理仅预告用于结构部分和不受约束位点的核苷酸。
36.使用rl学习来确定策略的神经网络(polciy网络))的参数。这些网络的精确架构与决策过程的表达、训练超参数、训练数据分布、训练课程和用于拟定序列所使用的算法一起被优化。使用策略梯度方法、即近端策略优化(ppo),用于更新给定策略网络的参数。runge等人迄今已经表明:rna设计策略的元学习在速度和精度方面胜过其他学习策略,其中本发明现在适配这种策略用于解决部分rna设计问题。尤其是,每个所采样的rl算法首先跨越数千个局部rna拟定任务(交替序列和结构模体)学习rna拟定策略。于是,对于新的、迄今未见过的设计任务,在无其他参数更新的情况下从策略中对候选解进行取样。
37.实施rl学习方法可以对关于代理参数、环境和训练参数的决策非常敏感地作出反应,并且对于新问题表达rl算法是困难且漫长的过程;因为对于哪些设计决策可以带来最佳结果没有经验。rl表达的自动化可以急剧节省这个过程。为了解决该问题,提出自动加强学习方案(autorl),该自动加强学习方案由于丰富的配置空间而自动选择用于加强的最佳学习环境来解决部分rna设计问题。尤其是,定义元学习过程来共同地优化rl算法的表达:在外循环中,迭代元学习采样定义配置,所述配置定义rl算法,然后使用所述配置用于在内
循环中学习rna设计规则。从中得出的规则在验证数据组处被评估,并且元学习器观察验证损失,以便相对应地更新其自身的模型。元学习器的目标是使验证损失最小化,其方式是所述元学习器学习利用每个观察试验更好的配置,而学习者试图对于验证集的每个任务最大化其奖励。更正式地,本发明的方案可以如下列来表达。
38.a是用于生成性rna序列设计的算法的集合,e是rl学习环境的集合,n是rl学习代理的集合,d
train
是一系列训练数据,并且c是定义配置空间的训练课程的集合:。
39.整个验证组的特定配置的成本函数于是可以被写成:。
40.现在,目标是对于部分rna设计在训练数据(训练数据 验证集)上训练元学习器l,使得所述元训练器找到最优配置,所述最优配置使成本函数最小化:。
41.因此,搜索空间表示runge等人的扩展配置空间并且包含五个新维度。
42.配置空间包括四个分量:关于代理的决策、环境、训练数据和用于序列设计的在下面描述的算法。图4中的表格给出概览。
43.代理子空间:代理子空间a的每个代理通过策略网络的特定架构和一系列训练超参数的所选择的值来定义,所述训练超参数调节优化和正则化。除了细微的变化外,使代理子空间主要适配于在runge等人下描述的参数。架构子空间如下来构建:(1)任务表示要么被编码,其中在配对位点、未配对位点和具有特定核苷酸或通配符的位点之间进行区分,要么由可选的嵌入层来处理,所述嵌入层将基于符号的表示转换成对于每一方可学习的数字表示。此外,可以在嵌入层上选择(2)具有最多两个层的可选cnn,所述可选cnn由(3)具有最多三个层的可选lstm跟随。最后,添加(4)具有一个或两个层的平面网络,输出关于动作的分布。这种参数化涵盖可能的神经架构的广泛范围,并且使搜索空间的维度保持得相对小。在绘图4中示出用于策略网络的神经架构的搜索空间。绘图4的图表中的每个路径均对应于特定的架构。神经网络的性能强烈地取决于超参数的选择。优选地,ppo的参数中的一些用于构造网络所使用的参数被记录到共同的配置空间中:学习率、批量大小和熵正则化的强度。
44.环境子空间:环境子空间e通过选择参数化决策过程的值来定义。决策过程的参数的特有值与配置空间的其他参数共同地被优化。尤其是,状态表达通过以当前位点为中心对称的、具有状态半径以及关于单独的状态组成的每个状态的准确组成的位点的数量来优化。此外,可以利用行动语义参数来分析配对预测的影响和用于拟定奖励的参数。最后,过渡动力学与不同子空间的多个参数决策有关并且相对应地被定义。
45.训练数据子空间:训练数据确定:在训练期间访问哪些任务分布以及关于哪些状态进行勘测。优选地,将不同任务分布的三个训练组记录在共同的配置空间中,所述训练组
经由训练数据参数可达。由于不同的课程可导致特定ml算法的不同性能,因此可以此外引入训练课程参数,以便关于任务长度在训练数据的随机课程或排序课程之间进行选择。
46.算法选择子空间:在这里可以在上面阐述的方案之间进行选择:单纯方案、替换方案和部分方案。
47.在该章节中更精确地描述该行为来从共同的配置空间中为部分rna设计自动地选择最佳rl算法。优选地对于元学习、尤其是作为根据图3的元学习器使用优化器bohb。因为bohb可以处置混合的离散/连续搜索空间,使用并行资源并且此外可以有益地评估目标函数的近似来加速优化,所以选择了bohb。这些所谓的低保真近似(low-fidelity-approximation)可以通过不同的方式实现,例如通过限制训练时间、评价的独立重复(repitierungen)的次数或通过仅使用可用数据的一小部分来实现。用于所采样的rl算法的训练时间优选地被限制。
48.数据集:当前方案的最终目标是为序列和结构空间中的每种类型的约束设定设计rna候选,其方式是在不同的rna设计任务之间转移知识。为了正确地优化与该目标有关的所列出的拟定决策,需要培训和验证数据组,包括包含不平衡括号的任务在内。
49.目标函数:虽然rl众所周知地在各个优化运行中提供嘈杂的或不可靠的结果,但优选地仅使用唯一一个元优化运行和唯一一个验证组。为了考虑优化过程的有噪声的结果,优选地事先研究用于优化方法的三个损失表达:(1)未解决的目标的数量、(2)平均距离的总和、以及(3)最小距离的总和。基于临时结果,已经证明变体(3)、即最小距离的总和作为用于优化的目标是有利的。然而,变体(1)也可以导致良好的结果。在元优化过程期间未解决的目标的数量特别优选地根据变体(1)被最小化。
50.预算:已经发现有利的是,为来自具有所规定的参数的所学习的rna设计指南中的验证组的100个迄今未见过的局部rna设计任务使用候选解。为了以不同的可靠性来近似性能,可以限制用于训练进程的挂钟时间。于是借助于验证组的任务在60秒内对每个rl算法进行评价。最后,选择了所建立的配置用于评价不同的测试集。
51.参数重要性:为了分析各个参数的重要性,使用基于随机森林(英语:random forrest)的泛函anova(fanova)架构。在元优化情况下的最重要的五个参数是算法选择参数、行动语义学参数、lstm层面的数量、学习率和状态半径(按其重要性排序)。
52.总体而言,拟定决策得出19维的拟定空间,所述拟定空间包括神经架构的宽谱来表达代理(包括递归神经网络(rnn)和神经卷积网络(cnn)的元素在内)、多种不同的环境表达、三种不同的训练数据分布、两种训练课程、用于生产性设计rna序列和训练超参数的三种不同的算法。在图4中列举出参数的完整列表、其类型、范围和先验。
53.可以使用高效的贝叶斯优化方法来优化rl表达,参见例如stefan falkner、aaron klein和frank hutter的bohb: robust and efficient hyperparameter optimization at scale(in jennifer dy and andreas krause, editors, proceedings of the 35th international conference on machine learning, volume 80 of proceedings of machine learning research, 1437
–
1446页, 斯德哥尔摩博览会, 斯德哥尔摩,瑞典, 2018年7月10-15日. pmlr)可在线检索: http://proceedings.mlr.press/v80/falkner18a.html。
54.在rl情况下,代理的策略由人工深度神经网络近似,所述人工深度神经网络输出
关于可能行动的分布,其中当前状态的表示。而环境可以完全通过表达决策过程来定义,所述决策过程包括一系列状态s、一系列可用行动a、已经在上面介绍的奖励函数r和状态过渡概率矩阵p。以下段落描述将部分rna设计建模为决策过程的不同分量。
55.如下表示状态空间。在每个时间步t=0;1;2;::::;t,其中t是代理与环境之间情节交互的终端时间步,环境提供状态st,其在学习策略时指导代理。为了给代理提供本地信息,可以使用克(gramm),其以任务表示的第t个位点为中心,其中是称为状态半径的超参数。为了能够在所有部位处构建该居中的n克,可以在任务表示的开头和结尾添加填充符号(“#”)。
56.行动空间由四个可用的核苷酸组成。可设想的是,对于任务代表中的配对位点也使用沃森-克里克碱基对(watson-crick basenpaar)(au、ua、gc、cg)。
57.状态过渡动力学可以如下建模。在每个时间步t中,状态被设置为固定的克,并且随后的状态通过在任务表示的各个位点上的确定性过渡来定义。根据行动语义的选择和用于生成候选解的所选算法以及状态组成的选择,过渡动力学可变化并且相对应地得以实现。
58.图5示意性地示出包括提供者71的训练设备141,所述提供者从训练数据组中提供训练序列e。所述训练序列被馈送给要训练的监控单元61,所述监控单元从中确定总损失a。总损失a和训练序列e被馈送给评估器74,所述评估器确定策略的参数,所述参数被传送给参数存储器p并且在那里替换参数。
59.由训练设备141执行的方法可以以实现为计算机程序的方式存放在机器可读存储介质146上并且可以由处理器145执行。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。