1.本说明书实施例涉及信息处理技术领域,尤其涉及一种标签分类系统及标签分类模型的训练系统。
背景技术:
2.在互联网信息大爆炸的时代,为了能够从互联网的海量信息中快速获取所需信息,会对互联网信息进行分类并标注相应分类的标签(tag),这种标签通常采用与信息关联性很强且便于识别的关键特征来表示,以便于用户进行检索和筛选。
3.目前,互联网信息的标签标注通常采用人工分类和自动分类两种方式。其中,人工方式成本高、效率低,无法满足互联网信息的增长速度。自动分类方式前期需要采用大量的训练数据对标签分类模型进行训练,并且现有的标签分类模型结构泛化能力弱、通用性差,导致标签分类预测结果的准确率较低。
技术实现要素:
4.有鉴于此,本说明书实施例提供了一种标签分类系统及标签分类模型的训练系统,能够提高标签分类预测结果的准确率。
5.本说明书实施例提供了一种标签分类系统,包括:
6.待处理数据获取模块,适于获取待处理数据,所述待处理数据包括待处理语料;
7.语义提取模块,适于提取所述待处理数据的语义特征;
8.逻辑运算模块,适于将提取得到的语义特征和所述待处理数据进行逻辑运算处理,得到所述待处理数据的融合特征;
9.数值计算模块,适于根据所述待处理数据的融合特征,计算各候选类别标签的数值,以表征各候选类别标签与所述待处理语料的关联程度;
10.标签获取模块,适于根据各候选类别标签的数值,获取数值符合预设的第一选取条件的候选类别标签,得到类别标签预测集合。
11.本发明实施例还提供了一种标签分类系统,包括:
12.待处理数据获取模块,适于获取待处理数据,所述待处理数据包括待处理语料;
13.标签分类预测模块,适于采用预设的标签分类模型提取所述待处理数据的语义特征,并将提取得到的语义特征和所述待处理数据进行逻辑运算处理,得到所述待处理数据的融合特征,以及基于所述待处理数据的融合特征,计算各候选类别标签用于标注所述待处理语料的数值,获取数值符合预设的第一选取条件的候选类别标签,得到类别标签预测集合。
14.本发明实施例还提供了一种标签分类模型的训练系统,包括:
15.训练数据获取模块,适于获取训练数据和所述训练数据的类别标签真实集合,所述训练数据包括训练语料;
16.模型训练模块,适于将所述训练数据和所述类别标签真实集合输入初始的标签分
类模型,以提取所述训练数据的语义特征,并将提取得到的语义特征和所述训练数据进行逻辑运算,得到所述训练数据的融合特征,以及基于所述融合特征,计算各候选类别标签的数值,以表征各候选类别标签与所述训练语料的关联程度,获取数值符合预设的第一选取条件的候选类别标签,得到所述训练数据的类别标签预测集合;
17.误差计算模块,适于将所述类别标签真实集合和所述类别标签预测集合进行误差计算,得到结果误差值;
18.匹配模块,适于根据所述结果误差值,确定所述标签分类模型是否符合训练完成条件,并在所述标签分类模型符合训练完成条件时,确定所述标签分类模型完成训练;
19.模型参数调整模块,适于在所述标签分类模型不符合训练完成条件时,对所述标签分类模型的参数进行调整。
20.采用本说明书实施例的标签分类方案,在获取待处理数据后,通过将提取得到的所述待处理数据的语义特征和所述待处理数据进行逻辑运算,可以融合待处理数据中的原始语义信息和语义特征中经过提取的语义信息,从而避免语义特征提取错误或关键语义信息缺失对标签分类预测结果带来的影响,使得融合后的特征包含丰富的语义信息,可以表征内容复杂或来源多变的待处理数据,有利于灵活处理单标签任务或多标签分类任务,并且能够更加准确地计算各候选类别标签的数值,获取正确的候选类别标签来表示待处理语料中存在的分类信息,故而提高标签分类结果的准确率。
附图说明
21.图1是本说明书实施例中一种标签分类系统的结构示意图;
22.图2是本说明书实施例中另一种标签分类系统的结构示意图;
23.图3是本说明书实施例中一种标签分类模型的结构示意图;
24.图4是本说明书实施例中一种迭代层的结构示意图;
25.图5是本说明书实施例中另一种标签分类模型的结构示意图;
26.图6是本说明书实施例中另一种标签分类模型的结构示意图;
27.图7是本说明书实施例中另一种标签分类模型的结构示意图;
28.图8是本说明书实施例中一种标签分类模型的训练系统的结构示意图;
29.图9是本说明书实施例中另一种标签分类模型的结构示意图。
具体实施方式
30.如前所述,在互联网信息大爆炸的时代,为了能够从互联网的海量信息中快速获取所需信息,会对互联网信息进行分类并标注相应分类的标签(tag)。目前,互联网信息的标签标注通常采用人工和机器学习两种方式。
31.其中,人工方式成本高、效率低,无法满足互联网信息的增长速度。机器学习方式前期需要采用大量的训练数据对标签分类模型进行训练。
32.然而,现有的标签分类模型结构泛化能力弱、通用性差,只能对网络信息进行单一的标签分类,无法高效处理更加复杂的多标签分类(multi-label classification)任务。
33.这是因为在多标签分类任务中,需要用多个类别标签表征图片或文档的内容信息。所以,预设的类别标签集合之间并非完全独立,而是存在一定的依赖关系或者互斥关
系。但由于多标签分类任务往往涉及的标签数量较多,构成了类别标签之间的复杂关联,从而导致多标签分类任务相对于单标签分类任务而言更加难以分析,增加了标签分类模型的构建难度和训练难度,导致标签分类预测结果的准确率较低。
34.针对上述问题,本说明书实施例提供一种标签分类方案,在获取待处理数据后,通过提取所述待处理数据的语义特征,以及将提取得到的语义特征和所述待处理数据进行逻辑运算处理,可以得到所述待处理数据的融合特征,从而可以根据所述待处理数据的融合特征计算各候选类别标签的数值,得到用于表示待处理语料中的分类信息的类别标签预测集合。
35.为使本领域技术人员更加清楚地了解及实施本说明书实施例的构思、实现方案及优点,以下参照附图,通过具体应用场景进行详细说明。
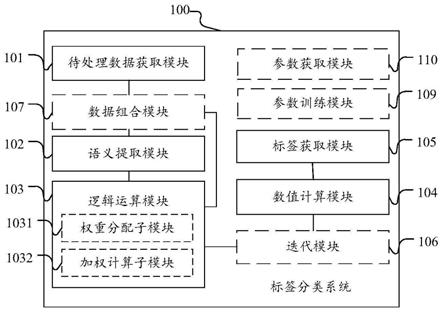
36.参照图1所示的一种标签分类系统的结构示意图,在本说明书实施例中,标签分类系统100可以包括:
37.待处理数据获取模块101,适于获取待处理数据,所述待处理数据包括待处理语料;
38.语义提取模块102,适于提取所述待处理数据的语义特征;
39.逻辑运算模块103,适于将提取得到的语义特征和所述待处理数据进行逻辑运算处理,得到所述待处理数据的融合特征;
40.数值计算模块104,适于根据所述待处理数据的融合特征,计算各候选类别标签用于标注所述待处理语料的数值,以表征各候选类别标签与所述待处理语料的关联程度;
41.标签获取模块105,适于根据各候选类别标签的数值,获取数值符合预设的第一选取条件的候选类别标签,得到类别标签预测集合。
42.在具体实施中,根据实际情况,待处理数据可以包括不同语言种类的待处理语料。例如,所述待处理数据可以包括中文待处理语料、英文待处理语料等。
43.其中,待处理语料可以是人工输入的文本数据,也可以是从公共网络上获取的文本数据,还可以是通过光学字符识别(optical character recognition,ocr)技术从图片中获取的文本数据。
44.实际应用时,待处理数据可以理解为属于人类能够理解的实际意义空间,获取的待处理数据对于计算机而言是一组字符串,计算机无法直接理解待处理数据所要传达的语言信息,因此,可以将待处理数据转换为计算机可以理解并处理的数字数据,使得原本属于实际意义空间的待处理数据映射到计算机所处的数字空间中。
45.在具体实施中,语义提取模块根据预设的特征提取参数,可以对待处理数据中部分或全部数据进行组合、排序、筛选等操作,得到能够表征待处理数据中语义信息的特征,即语义特征,使得计算机能够理解待处理数据所要传达的语言信息。逻辑运算模块再根据预设的逻辑运算参数,可以将提取得到的语义特征和所述待处理数据通过逻辑运算进行结合,得到语义信息融合的特征,即融合特征。
46.其中,根据实际情景设置的特征提取参数和逻辑运算参数,得到语义特征和融合特征的数量可以是一个,也可以是多个。
47.可以理解的是,根据实际设置的逻辑运算方式,语义特征的数量与融合特征的数量可以不一致。例如,当存在多个语义特征时,逻辑运算模块可以将各语义特征分别与待处
理数据进行逻辑运算,得到多个融合特征,也可以将各语义特征与待处理数据一起进行逻辑运算,得到一个融合特征;又例如,当存在一个语义特征时,逻辑运算模块可以将所述语义特征分别与待处理数据中的部分数据进行逻辑运算,得到多个融合特征,也可以将所述语义特征与待处理数据进行逻辑运算,得到一个融合特征。
48.在具体实施中,可以预设一候选类别标签集合,包括表征分类信息的各候选类别标签,根据所述待处理数据的融合特征,可以计算各候选类别标签与所述待处理语料的关联程度。由于各候选类别标签表征分类信息,因此,候选类别标签的数值越高,表明所述候选类别标签表征的分类信息与所述待处理语料存在的分类信息之间关联性越强,所述候选类别标签更适于标注所述待处理语料。
49.在具体实施中,所述第一选取条件可以根据实际情景进行设定。
50.例如,所述第一选取条件可以为:数值大于预设阈值。即标签获取模块选取数值大于预设阈值的候选类别标签,得到类别标签预测集合,所述类别标签预测集合用于标注所述待处理语料,以表征所述待处理语料的分类信息。
51.又例如,所述第一选取条件可以为:数值最大。即标签获取模块选取数值最大的候选类别标签,得到类别标签预测集合,所述类别标签预测集合用于标注所述待处理语料,以表征所述待处理语料的分类信息。
52.通过选取数值大于预设阈值的候选类别标签,标签分类系统可以进行多标签分类任务,而通过选取数值最大的候选类别标签,可以进行单标签分类任务,由此,本说明书实施例所述的标签分类系统可适用于单标签分类任务和多标签分类任务。根据预设的选取条件可以进行相应的分类任务。
53.在实际应用时,第一选取条件可以包括:预先设定的单标签分类任务的选取条件和预先设定的多标签分类任务的选取条件。标签获取模块通过接收到的分类指令,可以获取相应的标签分类任务的选取条件。如接收到单标签分类指令,标签获取模块可以获取单标签分类任务的选取条件,从而实现单标签分类处理;接收到多标签分类指令,标签获取模块可以获取多标签分类任务的选取条件,从而实现多标签分类处理。
54.采用上述方案,通过将提取得到的所述待处理数据的语义特征和所述待处理数据进行逻辑运算,可以融合待处理数据中的原始语义信息和语义特征中经过提取的语义信息,从而避免语义特征提取错误或关键语义信息缺失对标签分类预测结果带来的影响,使得融合后的特征包含丰富的语义信息,可以表征内容复杂或来源多变的待处理数据,有利于灵活处理单标签任务或多标签分类任务,并且能够更加准确地计算各候选类别标签的数值,获取正确的候选类别标签来表示待处理语料中存在的分类信息,故而提高标签分类结果的准确率。
55.在具体实施中,语义提取模块根据预设的特征提取参数可以提取所述待处理数据的语义特征,通过一组特征提取参数可能无法提取得到所有的语义特征,且由于提取范围有限,语义提取模块提取到的语义特征可能无法体现待处理数据中包含的所有语义信息,为了能够增加语义特征的数量,可以预设多组用于提取待处理数据的特征提取参数,语义提取模块根据预设的各组特征提取参数,分别提取所述待处理数据的语义特征,得到各组的基于待处理数据的语义特征,然后,逻辑运算模块可以对各组的基于待处理数据的语义特征和所述待处理数据进行逻辑运算,得到融合特征。
56.在本说明书一实施例中,可以预设有三组特征提取参数,语义提取模块根据预设的各组特征提取参数,可以分别获得将所述待处理数据映射为语义特征的特征提取函数,即特征提取函数f1、f2和f3。基于特征提取函数f1,f2和f3,可以分别获得所述待处理数据的语义特征a1=f1(x)、a2=f2(x)和a3=f3(x),其中,x表述待处理数据。基于预设的逻辑运算参数,逻辑运算模块对各组的语义特征a1、a2和a3以及所述待处理数据x进行逻辑运算,得到融合特征。
57.采用上述方案,通过设置不同的特征提取参数,可以从待处理数据中提取出不同粒度的语义特征,使提取的语义特征具有多样性和广泛性,通过不同粒度的语义特征可以传递更多待处理数据中包含的语义信息,增强融合特征表征内容复杂或来源多变的待处理数据的能力,提高对不同待处理数据进行准确预测的泛化能力和通用性。
58.在具体实施中,融合特征在数字空间上传递的语义信息与待处理数据包含的语义信息越接近,说明融合特征表征待处理数据的能力越强、精确度越高。在各组语义特征和所述待处理数据进行逻辑运算时,逻辑运算模块通过设置不同的权重系数和偏移系数,对各组的语义特征和所述待处理数据进行加权逻辑运算,其中,权重系数可以根据实际情景进行设定,可以得到不同的融合特征。
59.在一可选示例中,如图1所示,所述逻辑运算模块1103可以包括:
60.权重分配子模块1031,适于为各组语义特征和所述待处理数据设置不同的权重系数和偏移系数;
61.加权计算子模块1032,适于根据分配的权重系数,将各组的语义特征和所述待处理数据进行加权逻辑运算。
62.由此,通过加权逻辑运算,可以控制各种语义特征和待处理数据在逻辑运算中的重要程度,提高逻辑运算结果的准确性,增强融合特征表征待处理数据的精确度,提高标签分类预测结果的可靠性。
63.在具体实施中,为了能够快速可靠地获取权重系数,权重分配子模块可以将至少一组语义特征输入预设的非线性函数中进行非线性映射处理,并根据处理结果为其他组的语义特征和所述待处理数据分配权重系数,加权计算子模块再根据分配的权重系数,将所述其他组的语义特征和所述待处理数据进行加权逻辑运算。
64.例如,语义提取模块获得三组语义特征a1、a2和a3,权重分配子模块将语义特征a1输入非线性函数f4可以得到计算结果f4(a1),将f4(a1)输入权重系数计算函数f5、f6和f7,得到权重系数a1=f5[f4(a1)]、a2=f6[f4(a1)]和a3=f7[f4(a1)],加权计算子模块再基于分配的权重系数a1、a2和a3获得将语义特征映射为融合特征的融合特征计算函数f8,为其他组的语义特征a2和a3以及所述待处理数据x分配权重系数a1、a2和a3,将其他组的语义特征a2和a3以及所述待处理数据x输入融合特征计算函数f8进行加权逻辑运算f8(a
1 x,a2a2,a3a3),得到融合特征。
[0065]
由此,通过语义特征获取权重系数,能够提高权重获取的效率,可以增加权重系数的可靠性。
[0066]
在具体实施中,为了可以突显关键语义信息,便于后续进行数值计算,可以对融合特征进行迭代优化,如图1所示,所述标签分类系统100还可以包括:
[0067]
迭代模块106,所述迭代模块位于逻辑运算模块103和数值计算模块104之间,适于
在确定满足预设的迭代条件后,获取本轮的融合特征,并提取所述融合特征的语义特征,以及将所述融合特征提取得到的语义特征和所述融合特征进行逻辑运算,得到迭代后的融合特征;在确定不满足所述迭代条件后,将迭代后的融合特征作为所述待处理数据的融合特征,用以确定各候选类别标签的数值。
[0068]
其中,迭代条件可以设置为迭代次数阈值,也可以设置为其他条件。第一轮获取的融合特征为经过逻辑运算模块处理得到的融合特征,在确定满足预设的迭代条件后,后续获取的融合特征为经过迭代模块处理得到的融合特征。
[0069]
可以理解的是,用于迭代模块的特征提取参数可以与用于语义提取模块的特征提取参数相同,也可以不相同;同样地,用于迭代模块的逻辑运算参数可以与用于逻辑运算模块的逻辑运算参数相同,也可以不相同,本说明书实施例对此不作限制。
[0070]
采用上述方案,通过对融合特征进行语义提取和逻辑运算,可以使迭代后的融合特征更加突显关键语义信息,从而增强融合特征的表征能力,提高标签分类结果的准确率。
[0071]
在具体实施中,可以预设多组用于提取融合特征的特征提取参数,迭代模块根据各组特征提取参数,分别提取所述融合特征的语义特征,得到各组的基于融合特征的语义特征,然后,对各组的基于融合特征的语义特征和所述融合特征进行逻辑运算,得到迭代后的融合特征。
[0072]
在具体实施中,迭代模块可以对各组的基于融合特征的语义特征和所述融合特征进行加权逻辑运算,其中,权重系数的获取方法可以参照上述相关实施例,在此不再赘述。
[0073]
在具体实施中,为了将待处理数据转换为计算机可以识别的信息,待处理数据获取模块可以在提取所述待处理数据的语义特征之前,将待处理数据进行划分处理,得到相应的待处理序列。其中,根据不同的应用情景和不同的语言种类,待处理数据可以采用不同的划分方法,得到相应的数据序列。为了便于说明,可以将按照预设要求能够划分的最小成分称为划分单元。由此,划分处理可以将待处理数据x划分为n个划分单元x1,x2……
x
n
。
[0074]
例如,所述待处理数据包括中文的待处理语料:{你们好。},待处理数据获取模块可以采用文字和标点符号的划分方式,将待处理语料划分为{你/们/好/。},其中,“你”、“们”、“好”、“。”均为待处理语料的划分单元;待处理数据获取模块也可以采用词语和标点符号的划分方式,将待处理语料划分为{你们/好/。},其中,“你们”、“好”、“。”均为待处理语料的划分单元。
[0075]
可以理解的是,符号“/”仅用于示例说明划分后的效果,并不是划分后实际存在的符号,在划分后也可以采用其他的符号间隔划分单元,本说明实施例对于间隔划分单元的符号不做具体限制。
[0076]
需要说明的是,本文中“{}”仅用于限定举例的内容范围,并不是在表示训练语料的内容时必不可少的一部分,本领域技术人员可以用其他不容易混淆的符号来限定训练语料的内容范围,以下“{}”均同上所述。
[0077]
在具体实施中,待处理数据包含越丰富的序列信息,越可以精确地提取语义特征。因此,在进行待处理数据的语义特征提取之前,基于所述待处理语料的语义结构,待处理数据获取模块可以识别所述待处理语料的属性信息,从预设的候选属性标签集合中获取所述属性信息对应的候选属性标签,得到属性标签序列,由此,所述待处理数据还可以包括:属性标签序列,所述属性标签序列的划分单元可以为属性标签。
[0078]
其中,所述属性信息可以包括:所述待处理语料中各划分单元的位置信息和所述待处理语料的语法信息中至少一种;所述语法信息可以包括:词性信息和标点符号信息中至少一种。相应地,通过待处理语料获得的属性标签序列可以包括:位置标签序列和语法标签序列中至少一种;所述语法标签序列可以包括:词性标签和标点符号标签中至少一种。
[0079]
以下通过几个具体实施例进行详细说明。
[0080]
在本说明书一实施例中,预设一个候选位置标签集合,其中可以包括:各位置信息相应的位置标签。待处理数据获取模块对所述待处理语料进行划分后,识别待处理语料中存在的位置信息,得到各划分单元的位置信息,并根据划分单元在所述待处理语料中的分布位置,在各划分单元处标注相应的位置标签,由此得到位置标签序列。例如,待处理语料为:{你们好。},相应的位置标签序列可以为:{1 2 3 4},其中,“1”、“2”、“3”和“4”为分别表示第一、二、三、四位置信息的位置标签。
[0081]
在本说明书另一实施例中,预设一个候选语法标签集合,其中可以包括:各语法信息相应的语法标签。待处理数据获取模块在识别待处理语料中存在的语法信息后,可以得到各划分单元的语法信息,并根据各划分单元的语法信息,可以在各划分单元处标注相应的语法标签。
[0082]
所述语法标签进一步可以包括:标点符号标签和词性标签。其中,标点符号标签可以标注于标注标点符号信息相应的标点符号处;词性标签可以包括:各词性信息的起始位置标签和非起始位置标签,各词性信息的起始位置标签标注于词性信息相应的起始分词单元处,各词性信息的非起始位置标签标注于该词性信息相应的非起始单元分词处。
[0083]
通过各词性信息的起始位置标签和非起始位置标签这种标签组合,可以均匀标注待处理语料,得到该词性信息在待处理语料中的起始位置和结束位置,结合标点符号标签,使待处理语料的各划分单元均标注有相应标签,由此得到的语法标签序列能够充分体现待处理语料的语法信息。
[0084]
例如,待处理练语料可以为:{《离开》是由张宇谱曲、演唱。}
[0085]
则根据所述候选语法标签集合,可以得到以下语法标签序列:
[0086]
{w-b nw-b nw-i w-b v-b p-b nr-b nr-i v-b v-i w-b v-b v-i w-b}。
[0087]
其中,“w-b”表示标点符号标签;“nw-b”和“nw-i”分别表示作品名词的起始位置标签和非起始位置标签;“p-b”表示介词的起始位置标签;“nr-b”和“nr-i”分别表示人名的起始位置标签和结束位置标签;“v-b”和“v-i”分别表示动词的起始位置标签和结束位置标签。
[0088]
采用上述方案,根据处理语料中存在的属性信息,可以获得相应的属性标签序列,并且由于待处理语料和属性标签序列的共现特性,增加的属性标签序列不会破坏待处理语料的语义信息,且可以丰富待处理数据中包含的序列信息。
[0089]
在具体实施中,为了可以更精确地提取待处理数据的语义特征,如图1所示,所述标签分类系统100还可以包括:数据组合模块107,在获取属性序列标签后,所述数据组合模块107可以将所述待处理语料和属性标签序列进行组合处理,得到组合后的待处理数据,用以提取语义特征和进行逻辑运算处理。其中,可以采用concat函数进行组合处理。
[0090]
采用上述方案,将待处理语料和属性标签序列进行组合后可以提取属性维度的语义信息,也使得后续处理的特征中包含属性维度的语义信息,拓展语义特征和融合特征中
语义信息的维度,结合多维度的语义信息,可以更加准确地计算各候选类别标签的数值。
[0091]
在具体实施中,融合特征根据预设的逻辑运算参数,可以通过数值、向量或者矩阵来表示,与预设的候选类别标签集合无法一一对应。
[0092]
为了解决上述问题,如图1所示,数值计算模块104适于根据所述待处理数据的融合特征,生成融合特征向量,所述融合特征向量的维度与预设的候选类别标签集合中候选类别标签的总数一致,所述融合特征向量中各元素的数值表征相应的候选类别标签与所述待处理语料的关联程度。
[0093]
例如,预设的候选类别标签集合为lb={lb1,lb2,lb3},则通过特征向量生成函数得到的融合特征向量为rx={rx1,rx2,rx3},其中,融合特征向量的维度为3,与预设的候选类别标签集合中候选类别标签的总数一致。融合特征向量中的元素rx1,rx2,rx3分别表征候选类别标签lb1,lb2,lb3用于标注所述待处理语料的数值。
[0094]
相应地,标签获取模块105适于确定所述融合特征向量中符合预设的第一选取条件的元素所处的分布位置,获取预设的候选类别标签集合中对应分布位置的候选类别标签,得到所述类别标签预测集合。
[0095]
采用上述方案,生成维度与候选类别标签的总数一致的融合特征向量,便于与各候选类别标签的分布位置对应,有利于准确获取候选类别标签集合中符合第一选取条件的候选类别标签。
[0096]
在具体实施中,在根据所述待处理数据的融合特征,生成融合特征向量时,所述数值计算模块通过对所述融合特征进行维度变换处理,可以实现降维,并将降维后的向量进行转换处理,可以将向量中各元素的数值转换至指定区间,便于设置第一选取条件以及选取符合条件的候选类别标签。
[0097]
具体而言,数值计算模块通过预设的特征向量生成参数组成的特征向量生成函数,将所述融合特征输入到特征向量生成函数中,通过所述特征向量生成函数对所述融合特征进行数据维度变换处理,可以得到q维特征变换向量,其中q为候选类别标签的总数。
[0098]
作为一可选示例,数值计算模块通过对q维特征变换向量进行非线性转换处理,能够将q维特征变换向量中各元素的数值转换至指定数值区间内,从而将非线性转换处理后的特征变换向量作为融合特征向量,所述融合特征向量的维度与预设的候选类别标签集合中候选类别标签的总数一致,并且所述融合特征向量中的元素表征各候选类别标签用于标注所述待处理语料的数值。
[0099]
其中,数值计算模块可以采用sigmoid等数值计算函数对特征变换向量进行非线性转换处理。sigmoid数值计算函数可以将q维特征变换向量中各元素的数值转换至数值区间[0,1]内,q维特征变换向量中各元素的数值单独计算,非线性转换处理后的特征变换向量可以用于多标签分类任务。
[0100]
作为另一可选示例,数值计算模块可以对q维特征变换向量进行概率转换处理,将q维特征变换向量中各元素的数值转换至指定概率区间内,从而将概率转换处理后的特征变换向量作为融合特征向量,所述融合特征向量的维度与预设的候选类别标签集合中候选类别标签的总数一致,并且所述融合特征向量中的元素表征各候选类别标签用于标注所述待处理语料的数值。
[0101]
其中,数值计算模块可以采用softmax等数值计算函数对特征变换向量进行概率
转换处理。softmax数值计算函数可以将q维特征变换向量中各元素的数值转换至概率区间[0,1]内,q维特征变换向量中各元素的数值互相约束,概率转换处理后的特征变换向量中各元素的数值之和为1,可以用于单标签分类任务。
[0102]
在具体实施中,若通过标签分类系统识别所述待处理语料中存在的属性信息,并在所述待处理语料的各划分单元处标注相应的候选属性标签时,所述处理参数还可以包括:属性识别参数。
[0103]
在具体实施中,为了将待处理数据转换为计算机可以识别的信息,待处理数据获取模块还可以在提取所述待处理数据的语义特征之前,对所述待处理数据进行嵌入(embedding)处理,将待处理数据的划分单元进行向量化。具体而言,可以将待处理语料中各划分单元和属性标签序列中各候选属性标签分别采用向量的方式表征,由此,待处理语料和属性标签序列均可以通过矩阵的方式表征。所述处理参数还可以包括:用于实现嵌入处理的嵌入处理参数。
[0104]
采用上述方案,通过将各划分单元和各候选属性标签向量化,可以得到更高精确度的矩阵,矩阵形式的待处理语料和属性标签序列便于后续特征提取和逻辑运算,提高数据处理效率。
[0105]
在具体实施中,通过嵌入处理后的得到的向量为静态向量,静态向量不具有多意性,故而待处理数据获取模块还可以对待处理数据进行编码处理,将静态向量转化为动态向量,由此可以根据语料的上下文信息进行变化,具有多意性,再将编码后的待处理数据进行语义特征提取。所述处理参数还可以包括:编码处理参数。
[0106]
在具体实施中,如图1所示,所述标签分类系统100还可以包括:参数获取模块110,适于获取预设的处理参数,并根据所述处理参数配置所述标签分类系统的模块。
[0107]
例如,所述处理参数可以包括:特征提取参数、逻辑运算参数和数值计算参数,参数获取模块根据所述处理参数可以配置语义提取模块、逻辑运算模块和数值计算模块。在具体实施中,如图1所示,所述标签分类系统100还可以包括:参数训练模块109,适于通过预设的训练数据、所述训练数据的类别标签真实集合和预设的损失函数(loss function)调整初始的处理参数,将调整完成的处理参数作为预设的处理参数;所述损失函数基于所述训练数据的标签分类预测结果建立,所述训练数据包括:训练语料,所述训练数据的类别标签真实集合包括:实际用于标注所述待处理语料的候选类别标签。
[0108]
采用上述方案,通过训练调整处理参数,使处理参数的数值收敛至理想状态,提高标签分类预测结果的准确率。
[0109]
在具体实施中,参数训练模块获取的训练数据会形成一个训练数据集合,可以将训练数据集合分成多批次对处理参数进行训练,执行标签分类预测操作,且每一批次可以包含一段训练语料,即一个句子列表,列表的大小由实际情况决定。或者,也可以根据预设的句尾标点符号集合,将所述训练数据集合划分为句子级别的训练数据,并按照划分结果,将句子级别的训练数据分成多次对处理参数进行迭代训练,分别执行标签分类预测操作。
[0110]
在具体实施中,所述训练数据还可以包括:所述训练语料的属性标签序列,所述训练语料的属性标签序列可以通过人工标注各划分单元的属性标签的方式获得,还可以通过预设的属性标注模型识别所述训练语料中存在的属性信息,并在所述训练语料的各划分单元处标注相应的候选属性标签。
[0111]
其中,基于所述训练语料的语义结构,其属性信息可以包括:训练语料中各划分单元的位置信息和训练语料的语法信息中至少一种,所述语法信息可以包括:词性信息和标点符号信息中至少一种。相应地,通过训练语料获得的属性标签序列可以包括:位置标签序列和语法标签序列中至少一种;所述语法标签序列可以包括:词性标签和标点符号标签中至少一种。
[0112]
对于包括属性标签序列的训练数据的处理过程,可具体参阅上述待处理数据的相关部分的描述,在此不再赘述。
[0113]
在具体实施中,通过嵌入处理后的得到的向量为静态向量,静态向量不具有多意性,故而参数训练模块可以对训练数据进行编码处理,将静态向量转化为动态向量,由此可以根据语料的上下文信息进行变化,具有多意性。
[0114]
为了确定训练数据是否进行了准确地编码处理并得到正确的编码后的训练数据,参数训练模块可以对编码后的训练数据进行解码处理,根据对编码后的训练数据进行预测,验证编码处理结果是否准确。
[0115]
在具体实施中,可以采用条件随机场网络(conditional random field,crf)对编码后的训练数据进行解码处理。
[0116]
条件随机场网络可以预设有一个状态转换矩阵[a]
a,b
和发射矩阵[a]
a,b
表示两个时间步长从第a个状态到第b个状态的状态转换转移概率,表示矩阵输入后第t个位置输出为候选标签[v]
t
的观测概率,其中θ包含了处理参数。当条件随机场分数最高时,得到预测序列。而且,条件随机场子模型可以采用维特比(viterbi)方法计算得出的最佳路径,从而可以获取最佳路径对应的预测序列。
[0117]
由此,参数训练模块可以根据标签分类预测结果和编码处理结果联合建立损失函数,多维度地对初始的处理参数进行调整,可以使初始的处理参数快速收敛,提高调参效率。
[0118]
以编码后的属性标签序列为例,为了区分编码处理前和解码处理后的属性标签序列,可以将进行编码处理前的属性标签序列视为属性标签真实序列,将进行解码处理预测得到的属性标签序列视为属性标签预测序列。
[0119]
根据预设的候选属性标签集合,排列组合后可以得到多个候选属性标签标注序列,根据编码处理后的属性标签序列,采用条件随机场网络预测候选属性标签标注序列中各候选属性标签用于标注所述编码处理后的属性标签序列中相应划分单元的概率,从而得到各候选属性标签标注序列的概率值,获取概率值符合预设的第二选取条件的候选属性标签标注序列,作为属性标签预测序列。
[0120]
通过匹配属性标签真实序列和属性标签预测序列,可以确定编码处理结果是否准确。
[0121]
可以理解的是,上述实施例仅为示例说明,在应用中,可以根据实际情景选择相应的编码后的训练数据进行解码,例如,可以选择编码后的语法标签序列、位置标签序列和训练语料等。
[0122]
还可以理解的是,在实际应用中,根据标签分类系统包含的模块、子模块,参数获取模块获取的处理参数还可以包括:嵌入处理参数、编码处理参数、属性识别参数、用于迭代的特征提取参数和用于迭代的逻辑运算参数等,这些参数也可以通过预设的训练数据、所述训练数据的类别标签真实集合和预设的损失函数调整得到,本说明书实施例对于处理参数包括的具体参数类型不做限制。
[0123]
可选的,所述参数获取模块可以在提取所述待处理数据的语义特征之前配置标签分类系统的模块,也可以在其他时机触发并对标签分类系统的模块进行配置,例如,处理参数调整后,触发参数获取模块对标签分类系统的模块重新进行配置。
[0124]
在具体实施中,在获取待处理数据后,可以通过预设的标签分类模型得到所述待处理数据的类别标签预测集合。
[0125]
具体而言,参照图2所示另一种标签分类系统的结构示意图,在本说明书实施例中,标签分类系统20可以包括:
[0126]
待处理数据获取模块21,适于获取待处理数据,所述待处理数据包括待处理语料;
[0127]
标签分类预测模块22,适于采用预设的标签分类模型提取所述待处理数据的语义特征,并将提取得到的语义特征和所述待处理数据进行逻辑运算处理,得到所述待处理数据的融合特征,以及基于所述待处理数据的融合特征,计算各候选类别标签用于标注所述待处理语料的数值,获取数值符合预设的第一选取条件的候选类别标签,得到类别标签预测集合。
[0128]
采用上述标签分类方案,在获取待处理数据后,通过预设的标签分类模型,可以融合待处理数据中的原始语义信息和语义特征中经过提取的语义信息,从而避免语义特征提取错误或关键语义信息缺失对标签分类预测结果带来的影响,使得融合后的特征包含丰富的语义信息,可以表征内容复杂或来源多变的待处理数据,有利于更加准确地计算各候选类别标签的数值,获取正确的候选类别标签来表示待处理语料中存在的分类信息,故而提高标签分类结果的准确率。
[0129]
在具体实施中,如图2所示,所述标签分类预测模块22可以包括:模型构建子模块221,通过获取的预设的处理参数,模型构建子模块221可以构建标签分类模型,如图3所示,所述标签分类模型30可以包括输入层31、编码层32、特征提取层33、特征融合层34、解码层35和输出层36。其中,特征提取层33,适于提取所述待处理数据的语义特征。
[0130]
作为一可选示例,特征提取层33可以采用卷积神经网络架构。所述特征提取参数包括:卷积神经网络参数,通过相关的特征提取参数,所述卷积神经网络可以为普通的卷积神经网络(convolutional neural network,cnn)或其变种。
[0131]
在本说明书一实施例中,通过设置特征提取参数中的膨胀率(dilation rate)参数,所述标签分类模型可以通过卷积神经网络的变种,即膨胀卷积神经网络(dilated convolution neural network,dcnn)来提取所述待处理数据的语义特征。
[0132]
其中,所述特征提取层33可以包括至少一个膨胀卷积神经网络,各卷积神经网络参数可以分别进行设置,且各膨胀卷积神经网络的维度可以为一维或多维,当各膨胀卷积神经网络的卷积核(kernel)、窗口(window)和膨胀率等参数数值相同时,各膨胀卷积神经网络的感受野相同。
[0133]
例如,膨胀卷积神经网络的维度为一维,即膨胀卷积神经网络为一维膨胀卷积神
经网络,当卷积核大小为3,膨胀率为2时,各膨胀卷积神经网络的感受野为7
×
1。
[0134]
又例如,膨胀卷积神经网络的维度为二维,即膨胀卷积神经网络为二维膨胀卷积神经网络,当卷积核大小为3,膨胀率为4时,各膨胀卷积神经网络的感受野为15
×
15。
[0135]
采用上述方案,通过膨胀卷积神经网络提取所述待处理数据的语义特征,可以在不增加参数数量和未对待处理数据进行无效字符剔除预处理的情况下,从待处理语料中提取更远距离的语义信息,从而使语义特征包含更加广泛的语义信息。
[0136]
在具体实施中,如图3所示,标签分类模型30还可以包括特征融合层34,分别与特征提取层33和编码层32建立连接,适于将提取得到的语义特征和所述待处理数据进行逻辑运算处理,得到所述待处理数据的融合特征,其中,特征融合层34可以采用任意一种能够实现逻辑运算的神经网络架构,例如,感知神经网络(perception neural networks)架构,通过逻辑运算参数可以设置特征融合层的参数。
[0137]
可以理解的是,在描述本说明实施例时,为了便于描述各神经网络之间的数据交互关系,可以将独立实现相应功能的神经网络视为标签分类模型中的一个子模型,例如,一个能够独立实现提取所述待处理数据的语义特征的功能的卷积神经网络,可以视为语义特征提取子模型;一个能够独立实现逻辑运算处理功能的神经网络,可以视为逻辑运算子模型。
[0138]
在实际应用中,基于预设的各组特征提取参数,可以得到各语义特征提取子模型。各语义特征提取子模型分别提取所述待处理数据的语义特征,得到各组的基于待处理数据的语义特征,然后,逻辑运算子模型可以对各组的基于待处理数据的语义特征和所述待处理数据进行逻辑运算,得到融合特征。
[0139]
采用上述方案,通过设置不同的特征提取参数,可以从待处理数据中提取出不同粒度的语义特征,使提取的语义特征具有多样性和广泛性,通过不同粒度的语义特征可以传递更多待处理数据中包含的语义信息,增强融合特征表征内容复杂或来源多变的待处理数据的能力,提高对不同待处理数据进行准确预测的泛化能力和通用性。
[0140]
在具体实施中,基于预设的逻辑运算参数,所述逻辑运算子模型可以对各组的语义特征和所述待处理数据进行加权逻辑运算。
[0141]
由此,通过加权逻辑运算,可以控制各种语义特征和待处理数据在逻辑运算中的重要程度,提高逻辑运算结果的准确性,增强融合特征表征待处理数据的精确度,提高标签分类预测结果的可靠性。
[0142]
在具体实施中,为了能够快速可靠地获取权重系数,逻辑运算子模型可以将至少一组语义特征输入预设的非线性函数中进行非线性映射处理,并基于处理结果为其他组的语义特征和所述待处理数据分配权重系数,再基于分配的权重系数,将所述其他组的语义特征和所述待处理数据进行加权逻辑运算。其中,可以采用sigmoid、tanh、relu等非线性函数对至少一组语义特征进行非线性映射处理。
[0143]
在本说明书一实施例中,两个语义特征提取子模型分别输出提取的语义特征,逻辑运算子模型可以采用sigmoid非线性函数,通过预设的神经网络对一组语义特征进行非线性映射处理sigmoid(e1),并和另一组语义特征e2以及所述待处理数据x进行加权逻辑运算,得到融合特征y。
[0144]
作为一可选示例,可以采用以下公式进行加权逻辑运算:
[0145][0146]
其中,σ=sigmoid(e1),为张量积运算符号。
[0147]
可以理解的是,上述说明书实施例仅为示例说明,在实际应用中,可以根据实际情景,选择不同数量的语义特征提取子模型、非线性函数和逻辑运算公式,本说明实施例对此不做限制。
[0148]
由此,通过语义特征获取权重系数,能够提高权重获取的效率,可以增加权重系数的可靠性。
[0149]
在具体实施中,如图3所示,作为一可选示例,所述标签分类模型30还可以包括位于特征融合层34和解码层35之间的迭代层37,适于在确定满足预设的迭代条件后,获取本轮的融合特征,并提取所述融合特征的语义特征,以及将所述融合特征提取得到的语义特征和所述融合特征进行逻辑运算,得到迭代后的融合特征;在确定不满足所述迭代条件后,将迭代后的融合特征作为所述待处理数据的融合特征,用以确定各候选类别标签的数值。
[0150]
其中,用于提取所述融合特征的语义特征的语义特征提取子模型与用于提取所述待处理数据的语义特征的语义特征提取子模型可以采用相同的神经网络架构,根据膨胀率可以为普通的卷积神经网络或膨胀卷积神经网络,用于提取所述融合特征的语义特征的语义特征提取子模型的参数可以与用于提取所述待处理数据的语义特征的语义特征提取子模型的参数相同,也可以不相同;同样地,用于迭代处理融合特征及其语义提取特征的逻辑运算子模型与用于处理所述待处理数据及其融合特征的逻辑运算子模型可以采用相同的神经网络架构。
[0151]
可以理解的是,在描述本说明实施例时,为了便于区分用于提取所述融合特征的语义特征的语义特征提取子模型与用于提取所述待处理数据的语义特征的语义特征提取子模型,可以将用于提取所述待处理数据的语义特征的语义特征提取子模型称为第一语义特征提取子模型,将用于提取所述融合特征的语义特征的语义特征提取子模型称为第二语义特征提取子模型。同样地,可以将用于处理所述待处理数据及其融合特征的逻辑运算子模型称为第一逻辑运算子模型,将用于迭代处理融合特征及其语义提取特征的逻辑运算子模型称为第二逻辑运算子模型。
[0152]
在实际应用时,根据预设的迭代次数阈值,所述迭代层可以预设有一个或多个子层,多个子层之间可以串联形成多次迭代关系,第一个子层接收输入的融合特征,并提取所述融合特征的语义特征,以及将所述融合特征提取得到的语义特征和所述融合特征进行逻辑运算,得到一次迭代后的融合特征;第二个子层接收一次迭代后的融合特征并提取所述一次迭代后的融合特征的语义特征,以及将所述融合特征提取得到的语义特征和所述融合特征进行逻辑运算,得到二次迭代后的融合特征,以此类推,经过多个子层的之后可以得到多次迭代后的融合特征。
[0153]
采用上述方案,通过对融合特征进行语义提取和逻辑运算,可以使迭代后的融合特征更加突显关键语义信息,从而增强融合特征的表征能力,提高标签分类结果的准确率。
[0154]
在具体实施中,可以预设多组用于提取融合特征的特征提取参数,基于各组特征提取参数,分别提取所述融合特征的语义特征,得到各组的基于融合特征的语义特征,然后,对各组的基于融合特征的语义特征和所述融合特征进行逻辑运算,得到迭代后的融合特征。
[0155]
例如,在本说明书一实施例中,参照图4所示,所述迭代层40可以包括两个子层,即第一子层41和第二子层42,第一子层41可以包括:第二语义特征提取子模型411和412,以及第二逻辑运算子模型413,所述第二语义特征提取子模型411和412的输入与第二逻辑运算子模型413的输入相连接,且所述第二语义特征提取子模型411和412的输出还与第二逻辑运算子模型413的输入相连接;第二子层42可以包括:第二语义特征提取子模型421和422,以及第二逻辑运算子模型423,所述第二语义特征提取子模型421和422的输入与第二逻辑运算子模型423的输入相连接,且所述第二语义特征提取子模型421和422的输出还与第二逻辑运算子模型423的输入相连接。
[0156]
将融合特征x
400
作为第一子层41的输入特征,分别输入第二语义特征提取子模型411、第二语义特征提取子模型412以及第二逻辑运算子模型413,通过第二语义特征提取子模型411和第二语义特征提取子模型412得到第一子层41的语义特征x
411
和x
412
,将第一子层的语义特征x
411
和x
412
以及融合特征x
400
通过第二逻辑运算子模型413进行逻辑运算,得到第一子层41的融合特征,即一次迭代后的融合特征x
413
。
[0157]
将一次迭代后的融合特征矩阵x
413
作为第二子层42的输入特征,分别输入第二语义特征提取子模型421、第二语义特征提取子模型422以及第二逻辑运算子模型423,通过第二语义特征提取子模型421和第二语义特征提取子模型422得到第二子层42的语义特征x
421
和x
422
,将第二子层42的语义特征x
421
和x
422
以及一次迭代后的融合特征矩阵x
413
通过第二逻辑运算子模型423进行逻辑运算,得到第二子层42的融合特征,即二次迭代后的融合特征x
423
。
[0158]
可以理解的是,上述实施例仅为示例说明,迭代层可以根据实际情况设置子层数量和各子层中包括的语义特征提取子模型和逻辑运算子模型的数量,本说明书实施例对此不作限制。
[0159]
在具体实施中,各第二语义特征提取子模型的参数可以分别进行设置,且同一子层的各第二语义特征提取子模型的参数可以相同,也可以不相同。例如,迭代层可以包括三个子层。其中,第一子层的膨胀率可以为2,第二子层的膨胀率可以为4,第三子层的膨胀率可以为1。
[0160]
在具体实施中,继续参考3,所述标签分类模型30还可以包括:输入层31。输入层31适于在提取所述待处理数据的语义特征之前,将待处理数据进行划分处理,得到相应的待处理数据序列。待处理数据序列可以包括一个或多个划分单元,所述划分单元为待处理数据按照预设要求可以划分的最小单元。
[0161]
作为一可选示例,由于待处理数据的划分单元表现形式多样,为了提高语义特征的提取效率,在通过所述标签分类模型中的语义提取层提取所述待处理数据的语义特征之前,可以对所述待处理数据进行嵌入处理,将待处理数据的划分单元进行向量化。具体而言,可以将待处理语料中各划分单元和属性标签序列中各候选属性标签分别采用向量的方式表征,由此,待处理语料和属性标签序列均可以通过矩阵的方式表征。
[0162]
例如,可以采用字典映射的方法进行嵌入处理。通过预设的映射字典,获取待处理数据中划分单元在所述映射字典中的索引值,得到字典映射处理后的待处理数据。由于字典映射处理后的待处理数据包括各划分单元的索引值,故而字典映射处理后的待处理数据可以通过向量的方式表征。
[0163]
在具体实施中,继续参考3,所述标签分类模型30还可以包括:编码层32。适于对所述待处理数据中的划分单元进行编码处理,得到编码后的待处理数据。其中,基于预设的编码处理参数,可以结合待处理数据的上下文信息,对各划分单元进行编码,得到各划分单元的编码特征向量,编码特征向量的维度通过预设的编码处理参数决定,编码后的待处理数据由各划分单元的编码特征向量组成,因此,编码处理后的待处理数据可以通过矩阵的方式表征。
[0164]
作为一可选示例,所述编码层32可以采用以下任意一种编码处理方式,对所述待处理数据进行编码:
[0165]
1)采用时间序列神经网络子模型;
[0166]
2)采用预设的映射矩阵。
[0167]
其中,所述时间序列的神经网络子模型可以包括:具有自注意力机制(self-attention)的转换器(transformer)网络模型、双向长短时记忆(bi-directional long short-term memory,简称bilstm)网络模型、gru(gated recurrent unit)网络模型等。所述映射矩阵中的行向量总数或列向量总数不小于所述待处理数据中的划分单元的总数。
[0168]
在具体实施中,当所述编码层包括时间序列神经网络子模型时,可以在对所述待处理数据进行编码之前,对其中的时间序列神经网络子模型进行预训练,使得预训练的时间序列神经网络子模型能够深度捕获待处理数据中的上下文信息。以下通过下述两种方法示例说明:
[0169]
方法一、采用语言模型(language model,lm)训练方法进行预训练。
[0170]
具体地,从预训练语料集合中获取随机的预训练语料,并输入初始的时间序列神经网络子模型,所述时间序列神经网络子模型在给定上文信息的条件下预测所述预训练语料的下一个分词单元,当预测准确的概率达到预设的预训练阈值时,确定已预训练好,得到预训练的时间序列神经网络子模型。否则,在调整所述通过所述时间序列神经网络子模型的参数后,通过预训练语料继续进行预训练,直至预测准确的概率达到预设的预训练阈值。
[0171]
方法二、屏蔽语言模型(mask language model,mlm)训练方法进行预训练。
[0172]
从预训练语料集合中获取随机掩盖预设比例部分的预训练语料,并输入所述时间序列神经网络子模型,所述时间序列神经网络子模型在给定上下文信息的条件下预测被掩盖的预设比例部分,当预测准确的概率达到预设的预训练阈值时,确定已预训练好,得到预训练的时间序列神经网络子模型。否则,在调整所述通过所述时间序列神经网络子模型的参数后,通过预训练语料继续进行预训练,直至预测准确的概率达到预设的预训练阈值。
[0173]
可以理解的是,上述预训练方法仅为示例说明,在实际应用中,可以根据使用场景选择上述方法或者其他预训练方法,本说明书实施例对此不做限制。
[0174]
在本说明书一实施例中,预训练的时间序列神经网络子模型可以为预训练的bert(bidirectional encoder representations from transformers,代表transformers的双向编码器)子模型,在待处理数据输入标签分类模型之前,可以根据bert子模型的输入规则,对待处理数据做预处理,具体可以为:在待处理数据的起始位置之前添加首位标签cls,在待处理数据的结束位置之前添加末尾标签sep。
[0175]
采用上述方案,首位标签cls在经过编码、特征提取、特征融合后,具有了整个待处理数据的语义信息,有利于标签分类模型获取丰富的语义信息。
[0176]
作为一可选示例,当待处理数据分成多批次输入标签分类模型中进行处理时,可以为所述标签分类模型预设一长度阈值,若一批次的待处理数据的长度不满足长度阈值时,可以对待处理数据进行填充(padding)处理。
[0177]
由此,通过预训练时间序列神经网络子模型对所述待处理数据进行编码,可以提高编码效率和编码结果准确性。
[0178]
在具体实施中,为了提高标签分类模型处理效率,可以对标签分类模型中的特征进行降维处理。例如,可以对融合特征进行降维处理。
[0179]
在具体实施中,待处理数据包含越丰富的序列信息,越可以精确地提取语义特征。因此,在进行待处理数据的语义特征提取之前,基于所述待处理语料的语义结构,可以识别所述待处理语料的属性信息,从预设的候选属性标签集合中选取相应的候选属性标签,得到属性标签序列,由此,所述待处理数据还可以包括:属性标签序列,所述属性标签序列的划分单元可以为属性标签。
[0180]
其中,所述属性标签序列可以通过标签分类模型或者预设的属性标注模型得到,属性标签序列获取方法可参考上述标签分类系统中相关的实施例,在此不再赘述。
[0181]
采用上述方案,根据处理语料中存在的属性信息,可以获得相应的属性标签序列,并且由于待处理语料和属性标签序列的共现特性,增加属性标签序列不会破坏待处理语料的语义信息,且可以丰富待处理数据中包含的序列信息。
[0182]
在具体实施中,如图5所示,作为一可选示例,所述标签分类模型30可以包括:位于编码层32和特征提取层33之间的组合层38,与图3的区别在于:所述编码层32不与所述特征融合层34建立连接,而所述组合层与所述特征融合层34建立连接。所述组合层38适于在获取属性序列标签后,可以将所述待处理语料和属性标签序列进行组合处理,得到组合后的待处理数据,用以提取语义特征和进行逻辑运算处理。
[0183]
采用上述方案,将待处理语料和属性标签序列进行组合后可以提取属性维度的语义信息,也使得后续处理的特征中包含属性维度的语义信息,拓展语义特征和融合特征中语义信息的维度,结合多维度的语义信息,可以更加准确地计算各候选类别标签的数值。
[0184]
在具体实施中,由于编码后的待处理语料和编码后的属性标签序列可以用矩阵方式表征,故而可以采用行向量或列向量的拼接方法,将按照行向量或列向量进行组合处理,得到组合后的待处理数据,组合后的待处理数据也可以用矩阵方式表征。
[0185]
例如,可以采用concat函数,将编码后的待处理语料中n个m1维行向量分别和编码后的属性标签序列中相应分布位置的n个m2维行向量进行组合处理,得到n个(m1 m2)维的行向量,由此得到组合后的待处理数据。其中,n、m1和m2为自然数,且m1和m2可以相等,也可以不相等。
[0186]
或者,还可以采用矩阵运算的拼接方法,将编码后的待处理语料和编码后的属性标签序列进行矩阵运算处理,由此得到组合后的待处理数据。
[0187]
例如,可以将编码后的待处理语料中n个m维行向量分别和编码后的属性标签序列中相应的n个m维行向量进行相加运算处理,得到n个m维的行向量,其中,n和m为自然数。
[0188]
在具体实施中,如图3或4所示,所述标签分类模型30还可以包括解码层35,适于根据所述待处理数据的融合特征,计算各候选类别标签的数值,以表征各候选类别标签与所述待处理语料的关联程度,并根据各候选类别标签的数值,获取数值符合预设的第一选取
条件的候选类别标签,得到类别标签预测集合。
[0189]
在实际应用时,融合特征根据预设的逻辑运算参数,可以通过数值、向量或者矩阵来表示,与预设的候选类别标签集合无法一一对应。由此,所述解码层35可以基于所述待处理数据的融合特征,生成融合特征向量,其中,所述融合特征向量的维度与预设的候选类别标签集合中候选类别标签的总数一致,所述融合特征向量中各元素的数值表征相应的候选类别标签与所述待处理语料的关联程度。
[0190]
再根据融合特征向量,确定所述融合特征向量中符合预设的第一选取条件的元素所处的分布位置,获取预设的候选类别标签集合中对应分布位置的候选类别标签,得到所述类别标签预测集合。
[0191]
作为一可选示例,通过预设的特征向量生成参数组成特征向量生成函数,将所述融合特征输入到特征向量生成函数中,通过所述特征向量生成函数对所述融合特征进行数据维度变换处理,得到q维特征变换向量,其中q为候选类别标签的总数。
[0192]
其中,可以采用reshape函数、resize函数、swapaxes函数、flatten函数unsqueeze函数、expand函数等现有的数据维度变换方法;或者,也可以自定义数据维度变换方法,将所述融合特征按预设的数据维度变换规则,转换为融合特征向量。
[0193]
作为一可选示例,若融合特征通过矩阵来表示,即融合特征矩阵,所述对所述融合特征进行数据维度变换处理,具体可以为:对所述融合特征矩阵中各元素按预设排序进行位置转换,得到位置转换向量,并对位置转换向量进行降维处理,使位置转换向量的维度降低至预设的候选类别标签集合中候选类别标签的总数一致,将降维后的位置转换向量作为特征变换向量,得到的特征变换向量的维度与预设的候选类别标签集合中候选类别标签的总数一致。
[0194]
其中,可以采用神经网络架构对位置转换向量进行降维处理,例如,可以采用多层感知(multi layerperceptron,mlp)神经网络架构,对位置转换向量进行降维处理。
[0195]
作为一可选示例,通过对q维特征变换向量进行非线性转换处理,能够将q维特征变换向量中各元素的数值转换至指定数值区间内,从而将非线性转换处理后的特征变换向量作为融合特征向量,所述融合特征向量的维度与预设的候选类别标签集合中候选类别标签的总数一致,并且所述融合特征向量中的元素表征各候选类别标签用于标注所述待处理语料的数值。
[0196]
其中,可以采用sigmoid等数值计算函数对特征变换向量进行非线性转换处理。sigmoid数值计算函数可以将q维特征变换向量中各元素的数值转换至数值区间[0,1]内,q维特征变换向量中各元素的数值单独计算,非线性转换处理后的特征变换向量可以用于多标签分类任务。
[0197]
作为一可选示例,可以对q维特征变换向量进行概率转换处理,将q维特征变换向量中各元素的数值转换至指定概率区间内,从而将概率转换处理后的特征变换向量作为融合特征向量,所述融合特征向量的维度与预设的候选类别标签集合中候选类别标签的总数一致,并且所述融合特征向量中的元素表征各候选类别标签用于标注所述待处理语料的数值。
[0198]
其中,可以采用softmax等数值计算函数对特征变换向量进行概率转换处理。softmax数值计算函数可以将q维特征变换向量中各元素的数值转换至概率区间[0,1]内,q
维特征变换向量中各元素的数值互相约束,概率转换处理后的特征变换向量中各元素的数值之和为1,可以用于单标签分类任务。
[0199]
为使本领域技术人员更好地理解和实现上述方案,以下结合附图及具体实施例进行阐述。
[0200]
在本说明书一实施例中,如图6所示,为本说明另一种标签分类模型的结构示意图。
[0201]
所述标签分类模型60包括:
[0202]
(1)输入层61,适于对接收的数据进行预处理,具体可以包括:将待处理语料s进行划分处理,得到划分单元组成的待处理语料序列{s1,s2…
s
m
},并根据预设的映射字典进行映射,分别获取待处理语料序列中各划分单元在映射字典中的索引值,将待处理语料序列中的划分单元转换为对应的数值,得到字典映射处理后的待处理语料,即待处理语料向量sid={sid1,sid2…
sid
m
},其中,s1,s2…
s
m
为待处理语料序列s中的划分单元,m为待处理语料s中的各划分单元之和。
[0203]
(2)编码层62,适于对接收的数据进行属性识别和编码,具体可以包括:
[0204]
(2.1)在第一区域621中,将待处理语料向量sid输入到预设的第一时间序列神经网络子模型进行编码处理,得到待处理语料s中各划分单元相应的第一编码特征向量,并组成语料特征矩阵其中,其中,中各第一编码特征向量es1,es2…
es
m
均可以为k维的稠密向量,k的值由所述时间序列神经网络子模型的参数决定。
[0205]
(2.2)在第二区域622中,通过待处理语料向量sid,使第一属性标注子模型识别所述待处理语料s的语法信息,并在待处理语料s的各划分单元处标注相应的语法标签,得到语法标签序列,对所述语法标签序列进行字典映射处理,得到语法标签序列向量pld={pid1,pid2…
pid
m
}。
[0206]
(2.3)在第二区域622中,将语法标签序列向量pid输入到预设的第二时间序列神经网络子模型进行编码处理,得到语法标签序列中各划分单元相应的第二编码特征向量,并组成语法标签特征矩阵其中,其中,中各第二编码特征向量ep1,ep2…
ep
m
均可以为j维的稠密向量,j的值由第二时间序列神经网络子模型的参数决定。
[0207]
(2.4)在第三区域623中,通过待处理语料向量sid,使第二属性标注子模型识别所述待处理语料s的位置信息,并在待处理语料s的各划分单元处标注相应的位置标签,得到位置标签序列,对所述位置标签序列进行字典映射处理,得到位置标签序列向量qid={qid1,qid2…
qid
m
}。
[0208]
(2.5)在第三区域623中,将位置标签序列向量qid输入到预设的映射矩阵进行编码处理,得到语法标签序列中各划分单元相应的第三编码特征向量,并组成位置标签特征矩阵其中,其中,中各第三编码特征向量ep1,ep2…
ep
m
均可以为h维的稠密向量,h的值由映射矩阵的参数决定。
[0209]
(3)组合层63,适于对接收的数据进行组合处理,具体可以包括:对语料特征矩阵语法标签特征矩阵和位置标签特征矩阵进行组合处理,得到组合特征
矩阵其中,组合特征矩阵的各组合特征向量可以由语料特征矩阵语法标签特征矩阵和位置标签特征矩阵中相应分布位置的特征编码向量拼接而成,例如,e
i
={es
i
,ep
i
,eq
i
},i为自然数,且i∈[1,m],且中各组合向量e1,e2…
e
m
均可以为h j k维的稠密向量。
[0210]
(4)第一全连接层64,适于对接收的数据进行降维处理,具体可以包括:采用第一多层感知机子模型641,可以对组合特征矩阵中各组合特征向量e1,e2…
e
m
进行降维处理,从而得到降维处理后的组合特征矩阵其中,降维处理后的组合特征向量e1′
,e2′…
e
m
′
的维度可以为p=(h j k)/2
d
,d为自然数,且2
d
为(h j k)的约数。
[0211]
(5)特征提取层65,适于对接收的数据进行语义特征提取,具体可以包括:通过两个膨胀卷积子模型651和652,可以分别对降维处理后的组合特征矩阵进行语义特征提取处理,得到两个语义特征矩阵和其中,中各语义特征向量均可以为p维的稠密向量,中各语义特征向量均为p维的稠密向量。
[0212]
(6)特征融合层66,适于对接收的数据进行逻辑运算处理,具体可以包括:将语义特征矩阵和以及降维处理后的组合特征矩阵进行逻辑运算处理,得到融合特征矩阵其中,其中,中各融合特征向量d1,d2…
d
m
均可以为p维的稠密向量。
[0213]
(7)迭代层67,适于对接收的数据进行迭代处理,具体可以包括:通过四个子层,对融合特征矩阵进行四次迭代,得到四次迭代后的融合特征矩阵其中,迭代后的融合特征矩阵中的各迭代后的融合特征向量的维度可以为p维,各第一子层的膨胀率可以为2,第二子层的膨胀率可以为4,第三子层的膨胀率可以为8,第四子层膨胀率可以为1。
[0214]
(8)解码层68,适于对接收的数据进行预测,得到类别标签预测集合,具体可以包括:
[0215]
(8.1)对四次迭代后的融合特征矩阵中各元素按预设排序进行位置转换处理,得到位置转换向量f={a1,a2...a
m
×
p
},其中,位置转换向量f可以为(m
×
p)维的稠密向量,a1,a2...a
m
×
p
为融合特征向量f中的元素。
[0216]
(8.2)采用第二多层感知机子模型681,可以对位置转换向量f进行降维处理,从而得到降维后的位置转换向量f
′
={a1′
,a2′
...a
q
′
},其中,降维后的位置转换向量f
′
的维度为q,q为预设的候选类别标签集合中候选类别标签的总数,a1′
,a2′
...a
q
′
为降维后的融合特征向量f
′
中的元素,将所述降维后的位置转换向量f
′
作为特征变换向量。
[0217]
(8.3)对位置转换向量f
′
进行非线性转换处理,得到非线性转换处理后的特征变换向量f
″
,将所述非线性转换处理后的特征变换向量f
″
作为融合特征向量,确定所述融合特征向量f
″
中符合预设的第一选取条件的元素所处的分布位置,获取预设的候选类别标签集合中对应分布位置的候选类别标签,得到所述类别标签预测集合y1。
[0218]
(9)通过输出层69输出所述待处理数据的类别标签预测集合y1。
[0219]
在本说明书一实施例中,如图7所示,为本说明另一中标签分类模型的示意图。所述标签分类模型70与图6中的标签分类模型60区别在于:输入层71和编码层72。
[0220]
具体而言,在获取待处理语料s后,通过预设的属性标注模型获得语法标签序列po和位置标签序列qo,然后,待处理语料s、语法标签序列po和位置标签序列qo作为待处理数
据输入标签分类模型70。
[0221]
输入层71将待处理语料s进行划分处理,得到划分单元组成的待处理语料序列{s1,s2...s
m
},并根据预设的映射字典进行映射,分别获取待处理语料序列、语法标签序列和位置标签序列中各划分单元在映射字典中的索引值,将各划分单元转换为对应的数值,得到字典映射处理后的待处理语料、语法标签序列、位置标签序列和分类标签序列,即待处理语料向量sid={sid1,sid2...sid
m
}、语法标签序列向量pid={pid1,pid2...pid
m
}和位置标签序列向量qid={qid1,qid2...qid
m
},其中,s1,s2…
s
m
为待处理语料序列s中的划分单元,m为待处理语料s中的各划分单元之和。
[0222]
编码层72由于无需进行属性信息的识别和标注,因此,可以对接收的数据直接进行编码。
[0223]
在第一区域721中,将待处理语料向量sid输入到预设的第一时间序列神经网络子模型进行编码,得到待处理语料s中各划分单元相应的第一编码特征向量,并组成语料特征矩阵其中,其中,中各第一编码特征向量es1,es2…
es
m
均可以为k维的稠密向量,k的值由所述时间序列神经网络子模型的参数决定。
[0224]
在第二区域722中,将语法标签序列向量pid输入到预设的第二时间序列神经网络子模型进行编码处理,得到语法标签序列中各划分单元相应的第二编码特征向量,并组成语法标签特征矩阵其中,其中,中各第二编码特征向量ep1,ep2…
ep
m
均可以为j维的稠密向量,j的值由第二时间序列神经网络子模型的参数决定。
[0225]
在第三区域723中,将位置标签序列向量qid输入到预设的映射矩阵进行编码处理,得到语法标签序列中各划分单元相应的第三编码特征向量,并组成位置标签特征矩阵其中,其中,中各第三编码特征向量ep1,ep2…
ep
m
均可以为h维的稠密向量,h的值由映射矩阵的参数决定。
[0226]
所述标签分类模型70的其余部分可参阅上述对于图6的标签分类模型60的相关描述,再次不再赘述。
[0227]
在实际应用中,可以根据具体需求设置候选类别标签集合的类型,从而上述标签分类系统可以应用于相应类型的识别领域。
[0228]
例如,可以设置关系类型的候选类别标签集合,候选类别标签集合中可以包括:同事标签、朋友标签、夫妻标签、演唱标签、国籍标签、居住地标签、著作标签等候选类别标签。由此,上述标签分类系统可以应用于关系识别领域。
[0229]
又例如,可以设置情感类型的候选类别标签集合,候选类别标签集合中可以包括:高兴标签、平静标签、愤怒标签、疑问标签等候选类别标签。由此,上述标签分类系统可以应用于情感识别领域。
[0230]
候选类别标签集合中相关类型的候选类别标签覆盖范围越广泛,标签分类系统可以进行越丰富的识别。以关系识别领域为例,待处理语料为:
[0231]
{小明,2020年出生,陕西三原人,汉族。};
[0232]
执行上述相关实施例所述的标签分类系统,可以得到类别标签预测集合:{出生地,出生日期,民族,国籍}。
[0233]
在具体实施中,为了提高标签分类预测结果的准确率,可以对初始的标签分类模型进行训练,通过预设的训练数据、所述训练数据的类别标签真实集合和预设的损失函数可以调整标签分类模型的模型参数,使标签分类模型收敛至理想状态,完成模型训练,将完成训练的标签分类模型作为预设的标签分类模型,从而实施标签分类系统。为使本领域技术人员更加清楚地了解及实施本说明书实施例,下面将结合本说明书实施例中的附图进行描述。
[0234]
参照图8所示的一种标签分类模型的训练系统的结构示意图,在本说明书实施例中,所述标签分类模型的训练系统80可以包括:
[0235]
训练数据获取模块81,适于获取训练数据和所述训练数据的类别标签真实集合,所述训练数据包括训练语料;
[0236]
模型训练模块82,适于将所述训练数据和所述类别标签真实集合输入初始的标签分类模型,以提取所述训练数据的语义特征,并将提取得到的语义特征和所述训练数据进行逻辑运算,得到所述训练数据的融合特征,以及基于所述融合特征,计算各候选类别标签的数值,以表征各候选类别标签与所述训练语料的关联程度,获取数值符合预设的第一选取条件的候选类别标签,得到所述训练数据的类别标签预测集合;
[0237]
误差计算模块83,适于将所述类别标签真实集合和所述类别标签预测集合进行误差计算,得到结果误差值;
[0238]
匹配模块84,适于根据所述结果误差值,确定所述标签分类模型是否符合训练完成条件,并在所述标签分类模型符合训练完成条件时,确定所述标签分类模型完成训练;
[0239]
模型参数调整模块85,适于在所述标签分类模型不符合训练完成条件时,对所述标签分类模型的参数进行调整。
[0240]
在具体实施中,所述训练语料可以包含但不仅限于中文和中文标点符号,并且可以根据标签分类模型实际预测的语言种类,选取相应语言种类的训练语料。
[0241]
其中,可以获取不同领域的训练数据,使得训练数据的来源更加广泛,也可以获取经过校对的训练数据,使得训练数据的格式较为统一、规范。并且所述训练数据可以是人工整理的数据,也可以是从公共网络上获取的数据。
[0242]
在具体实施中,在经过标签分类模型预测后,可以获得所述训练语料的类别标签预测集合,误差计算模块通过预设的损失函数可以计算得到所述类别标签真实集合和所述类别标签预测集合之间的结果误差值。
[0243]
可选的,通过预设一结果误差阈值和误差符合次数阈值,能够确定所述标签分类模型的参数是否进行调整。
[0244]
具体而言,当结果误差值大于结果误差阈值时,匹配模块确定所述标签分类模型不符合第一预设条件,模型参数调整模块可以对所述标签分类模型的参数进行调整。当结果误差值小于结果误差阈值时,误差符合次数加一,匹配模块确定误差符合次数是否大于或等于误差符合次数阈值,若是,则匹配模块确定所述标签分类模型符合第一预设条件,所述标签分类模型完成训练,否则,匹配模块确定所述标签分类模型不符合第一预设条件,模型参数调整模块可以对所述标签分类模型的参数进行调整。
[0245]
其中,模型参数调整模块可以采用梯度下降方法和反向传播方法中一种对所述标签分类模型的参数进行调整。
[0246]
在具体实施中,为了验证调整后的标签分类模型是否完成训练,模型训练模块可以将训练数据和训练数据的标签标注真实序列再次输入调整后的标签分类模型,调整后的标签分类模型再次执行标签分类预测操作,直至标签分类模型符合完成训练的条件。
[0247]
由上述方案可知,通过将提取得到的所述训练数据的语义特征和所述训练数据进行逻辑运算,可以融合训练数据中的原始语义信息和语义特征中经过提取的语义信息,保留融合特征中语义信息的多样性,使标签分类模型可以从融合特征中获得更丰富的特征信息,增强标签分类模型的泛化能力和通用性,提高标签分类预测结果的准确率。
[0248]
在具体实施中,所述训练数据还可以包括:所述训练语料的属性标签序列,所述训练语料的属性标签序列可以通过人工标注各划分单元的属性标签的方式获得,还可以通过所述标签分类模型或预设的属性标注模型识别所述训练语料中存在的属性信息,并在所述训练语料的各划分单元处标注相应的候选属性标签。
[0249]
其中,基于所述训练语料的语义结构,其属性信息可以包括:所述待处理语料中各划分单元的位置信息和所述待处理语料的语法信息中至少一种;所述语法信息可以包括:词性信息和标点符号信息中至少一种。相应地,通过待处理语料获得的属性标签序列可以包括:位置标签序列和语法标签序列中至少一种;所述语法标签序列可以包括:词性标签和标点符号标签中至少一种。对于包括属性标签序列的训练数据的处理过程,可具体参阅标签分类系统相关部分的描述,在此不再赘述。
[0250]
在具体实施中,在获得所述训练数据的类别标签预测集合后,误差计算模块可以通过预设的损失函数计算所述类别标签真实集合和所述类别标签预测集合之间的误差。且所述损失函数可以根据标签分类模型的全局或局部预测结果建立。
[0251]
例如,可以基于所述标签分类预测结果建立以下第一损失函数loss1,误差计算模块将第一损失函数loss1计算得到的数值作为标签标注预测序列和标签标注真实序列之间的结果误差值:
[0252][0253]
其中,y
i
表示所述类别标签真实集合对应的标签分类真实向量y中第i个元素,表示所述类别标签预测集合对应的融合特征向量中第i个元素。
[0254]
进一步可选的,所述类别标签真实集合对应的标签分类真实向量可以通过以下方式获得:
[0255]
根据训练语料中实际存在的分类信息,以及实际用于标注所述训练语料的候选类别标签在预设的候选类别标签集合中的分布位置,可以生成真实类别标签向量。例如,候选类别标签集合可以为{出生地朋友出生日期演唱国籍居住地民族},分类信息对应的实际用于标注所述训练语料的候选类别标签可以为{出生地,出生日期,国籍,民族},则标签分类真实向量可以为{1 0 1 0 1 0 1}。
[0256]
其中,“1”可以表示相应位置的候选类别标签有效,即相应位置的候选类别标签实际用于标注所述训练语料,“0”可以表示相应位置的候选类别标签无效,即相应位置的候选类别标签实际不用于标注所述训练语料。可以理解的是,在具体实施时,也可以采用其他数值来表示有效位和无效位,本说明书实施例对此不作限制。
[0257]
又例如,为了确定训练数据是否进行了准确地编码处理并得到正确的编码后的属性标签序列,标签分类模型可以对编码后的训练数据进行解码处理,根据对编码后的训练
数据进行预测,验证编码处理结果是否准确。由此,可以根据标签分类预测结果和编码处理结果联合建立损失函数,多维度地对初始的处理参数进行调整,可以使初始的处理参数快速收敛,提高调参效率。
[0258]
在本说明书一实施例中,所述标签分类模型的训练系统可以执行以下操作:
[0259]
1)获取训练数据和所述训练数据的类别标签真实集合,所述训练数据包括训练语料和属性标签序列。
[0260]
2)将所述训练数据和所述类别标签真实集合输入初始的标签分类模型,以对所述训练数据进行编码处理,提取所述训练数据的语义特征,并将提取得到的语义特征和所述训练数据进行逻辑运算,得到所述训练数据的融合特征。
[0261]
3)基于所述融合特征,计算各候选类别标签的数值,以表征各候选类别标签与所述训练语料的关联程度,获取数值符合预设的第一选取条件的候选类别标签,得到所述训练数据的类别标签预测集合。
[0262]
4)基于编码后的属性标签序列,所述标签分类模型计算各候选属性标签标注序列的概率值,获取概率值符合预设的第二选取条件的候选属性标签标注序列,得到所述训练数据的属性标签预测序列。
[0263]
5)计算所述类别标签真实集合和所述类别标签预测集合之间的第一误差,以及计算所述属性标签序列和所述属性标签预测序列之间的第二误差,并将所述第一误差和第二误差进行计算得到结果误差值。
[0264]
6)基于所述结果误差值,确定所述标签分类模型是否符合训练完成条件,并在所述标签分类模型不符合训练完成条件时,对所述标签分类模型的参数进行调整。
[0265]
7)将所述训练数据和所述训练数据的类别标签真实集合输入调整后的标签分类模型,直至所述标签分类模型符合训练完成条件。
[0266]
在具体实施中,可以基于标签分类模型输出的预测结果以及解码处理结果联合建立损失函数,并基于预设的联合建立的损失函数,采用梯度下降方法或反向传播方法对所述标签分类模型的参数进行调整。
[0267]
可选的,标签分类模型采用条件随机场网络对编码后的属性标签序列进行解码处理,得到属性标签预测序列。
[0268]
其中,条件随机场网络可以预设有一个状态转换矩阵[a]
a,b
和发射矩阵[a]
a,b
表示两个时间步长从第a个状态到第b个状态的状态转换转移概率,表示编码后的属性标签序列(即属性标签特征矩阵)输入后第t个位置输出为候选属性标签的观测概率,其中θ包含了整个标签分类模型的参数。当条件随机场分数场分数最高时,得到属性标签预测序列。而且,条件随机场子模型可以采用维特比方法计算得出的最佳路径,从而可以获取最佳路径对应的候选属性标签标注序列,作为属性标签预测序列。
[0269]
基于所述标签分类预测结果建立的第一损失子函数loss
label
,以及基于所述解码处理预测结果建立的第二损失子函数loss
classify
,联合建立第二损失函数loss2,第二损失函数loss2具体可以包括:
[0270]
loss2=λ1loss
label
λ2loss
classify
;
[0271]
其中,其中,表示包含有t个属性标签特征向量的属性标签特征矩阵,表示包含有t个候选属性标签的属性标签预测序列;表示包含有t个候选属性标签的属性标签预测序列;λ1和λ2为正数
[0272]
可以理解的是,上述说明书实施例仅为示例说明,损失函数可以根据实际情景进行建立。
[0273]
在具体实施中,在联合建立损失函数后,模型训练模块可以调整各损失子函数的权重系数,由此可以自动控制模型的调参方向和调参力度,例如,若损失函数为loss2=λ1loss
label
λ2loss
classify
,当λ1大于λ2时,控制梯度下降方法和反向传播方法倾向于调整分类标签预测的参数,当λ1小于λ2时,控制梯度下降方法和反向传播方法倾向于调整属性标签预测的参数。
[0274]
为使本领域技术人员更好地理解和实现上述方案,以下结合附图及具体实施例进行阐述。
[0275]
在本说明书一实施例中,如图9所示,为本说明的另一种标签分类模型的结构示意图。与图6和图7所示的标签分类模型的区别在于:解码层91和输出层92。
[0276]
具体而言,将训练数据输入标签分类模型得到迭代后的融合特征矩阵[d
train
]后,解码层91可以对迭代后的融合特征矩阵中各元素按预设排序进行位置转换处理,得到位置转换向量f
train
,采用第二多层感知机子模型101,解码层91还可以位置转换向量f
train
进行降维处理,从而得到降维后的位置转换向量f
train
′
,作为特征变换向量,对特征变换向量f
train
′
进行非线性转换处理,得到非线性转换处理后的特征变换向量f
train
″
,作为融合特征向量。
[0277]
基于编码后的属性标签序列,即属性标签特征矩阵[et],解码层91可以采用条件随机场子模型912计算各候选属性标签标注序列的概率值,获取概率值符合预设的第二选取条件的候选属性标签标注序列,得到所述训练数据的属性标签预测序列。
[0278]
然后,解码层91可以根据预设的损失函数,计算所述类别标签真实集合和所述类别标签预测集合之间的误差,得到结果误差值loss。输出层92可以输出结果误差值loss,以此判断标签分类模型是否完成训练。其中,采用的损失函数可以参照上述相关实施例,在此不再赘述。
[0279]
可以理解的是,标签分类模型根据训练数据获得相应融合特征矩阵和属性标签特征矩阵的过程可参考上述标签分类系统部分相关实施例的描述,在此不再赘述。
[0280]
在实际应用中,可以根据具体需求设置候选类别标签集合的类型,从而采用上述训练系统完成训练的标签分类模型可以应用于相应类型的识别领域。
[0281]
例如,可以设置关系类型的候选类别标签集合,候选类别标签集合中可以包括:同事标签、朋友标签、夫妻标签、演唱标签、国籍标签、居住地标签、著作标签等候选类别标签。由此,完成训练的标签分类模型可以应用于关系识别领域。
[0282]
又例如,可以设置情感类型的候选类别标签集合,候选类别标签集合中可以包括:高兴标签、平静标签、愤怒标签、疑问标签等候选类别标签。由此,完成训练的标签分类模型可以应用于情感识别领域
[0283]
候选类别标签集合中相关类型的候选类别标签覆盖范围越广泛,完成训练的标签分类模型可以进行越丰富的识别。
[0284]
需要说明的是,在实际应用中,标签分类系统、标签分类模型的训练系统所包含的各模块、子模块均可以采用相应的硬件电路或器件、模组等进行实施。例如,待处理数据获取模块、模型训练模块等可以通过单片机、fpga等数据处理芯片执行。这几个模块、子模块可以通过同一处理器件进行控制,也可以通过不同的处理器件执行,所述不同的处理器可以分布于同一硬件设备上,也可以分布于不同的硬件设备上。
[0285]
可以理解的是,为使描述方便可以采用“第一”、“第二”等名词前缀作为区分。且本文中的“第一”、“第二”、“第三”等名词前缀仅用于区分不同作用的名词,并不代表顺序、大小或重要性等。
[0286]
虽然本公开实施例披露如上,但本公开实施例并非限定于此。任何本领域技术人员,在不脱离本公开实施例的精神和范围内,均可作各种更动与修改,因此本公开实施例的保护范围应当以权利要求所限定的范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。