1.本发明涉及机器学习技术领域,具体涉及一种基于区块链的神经网络模型托管训练系统。
背景技术:
2.神经网络是由大量的、简单的处理单元,称为神经元,广泛地互相连接而形成的复杂网络系统,是一个高度复杂的非线性动力学习系统。神经网络模型包含三个部分:输入层、中间层或隐藏层、输出层。神经元是一个多输入单输出的信息处理单元,而且是非线性的。工程中把神经元抽象为一个简单的数学模型,即将前一级神经元的输出值经过加权求和作为阈值,将阈值代入激活函数,得出神经元的输出。神经网络具有大规模并行、分布式存储和处理、自组织、自适应和自学能力,特别适合处理需要同时考虑许多因素和条件的、不精确和模糊的信息处理问题。设计合理并经过良好训练的神经网络模型在处理这些复杂问题时具有良好的效果。神经网络技术已经在自动控制领域、处理组合优化问题、模式识别、图像处理、信号处理、机器人控制及卫生保健医疗等领域获得广泛的应用。目前神经网络模型的理论得到快速的发展,但也遇到了在实际应用中,缺乏足够优质的数据对建立起的神经网络模型进行训练的问题。受制于竞争关系、隐私保护,企业和机构之间并不能直接进行数据的交换。导致建立和使用神经网络模型的单位,缺乏训练神经网络的数据。
3.中国专利cn112801292a,是与本技术最为接近的现有技术,其公开日为2021年5月14日,记载了一种基于区块链智能合约的神经网络训练方法及系统,方法包括:接收组织用户提交的原始数据集和奖金;将原始数据集划分为训练数据集和测试数据集,并将训练数据集划分为a个训练数据子集,a≥2;响应于b个参与用户发送的训练数据获取请求消息,分别向b个参与用户发送a个训练数据子集,b≥2;分别接收b个参与用户发送的c个训练子结果,并对c个训练子结果进行汇总,获得训练结果;通过测试数据集对训练结果进行校验,若训练结果通过校验,则向b个参与用户支付奖金。其通过设计的数据分发和奖金分配方案可以避免各节点的欺诈行为。但该技术方案仅能够解决神经网络训练的算力分散,提高神经网络训练效率,但不能解决神经网络缺乏训练数据的问题。
技术实现要素:
4.本发明要解决的技术问题是:目前缺乏适合多数据源的神经网络模型训练方法的技术问题。提出了一种基于区块链的神经网络模型托管训练系统,本系统能够融合多个数据源的数据,对目标神经网络模型进行托管训练。
5.为解决上述技术问题,本发明所采取的技术方案为:一种基于区块链的神经网络模型托管训练系统,包括:接收节点,接收目标神经网络模型、测试数据集和数据源方按批次上传的数据行,为数据行分配批次编号和行编号,将数据行的字段关联行编号并公开;若干个数据存储节点,与接收节点连接,所述接收节点将数据行分散存储在若干个数据存储节点上;托管节点,与接收节点连接,获取目标神经网络模型,获得目标神经网络模型的输
入字段和输出字段,获得含有目标神经网络模型输入字段和输出字段的数据行的行编号,向若干个数据存储节点请求调用相应行编号的数据行,并生成账单,使用测试数据集获得目标神经网络模型的准确度,若准确度符合预设准确度要求,则将账单发送给用户,用户将账单对应的代币转账到托管节点的虚拟账户后,所述托管节点将训练后的神经网络模型提供给用户,将代币转账到数据源方的虚拟账户,若准确度不符合预设准确度要求,则等待接收节点接收到新的含有目标神经网络模型输入字段和输出字段的数据行。
6.作为优选,所述托管节点为目标神经网络模型建立有历史记录表,所述历史记录表记录代入目标神经网络模型进行训练的数据行的行哈希值,所述托管节点将新的数据行代入目标神经网络模型前,提取新的数据行的行哈希值,并在历史记录表查询,若行哈希值已存在于历史记录表中,则跳过该数据行且不计入账单,若行哈希值在历史记录表中不存在,则将数据行代入目标神经网络模型进行训练,将行哈希值加入历史记录表,并计入账单。
7.作为优选,所述接收节点为目标神经网络模型分配有模型编号,所述数据存储节点建立有调用记录表,所述托管节点向所述数据存储节点调用数据时,向所述数据存储节点发送行编号和模型编号,所述数据存储节点收到调用请求时,将行编号和模型编号关联时间戳记录到调用记录表中,所述数据存储节点周期性将调用记录表新增的记录一起提取哈希值并上传到区块链存储,所述托管节点周期性将历史记录表的哈希值关联模型编号上传区块链存储。
8.作为优选,所述托管节点代入批次数据行前,将当前目标神经网络模型备份,并记录当前神经网络模型的准确度,当批次数据的数据行输入神经网络训练后,使用测试数据集获得目标神经网络模型的准确度,若准确度增加,则丢弃备份的目标神经网络模型,若准确度降低,则将目标申请网络模型退回到备份。
9.作为优选,所述托管节点将数据行代入目标神经网络模式训练时,周期性生成备份点,使用测试数据集获得备份点目标神经网络模型的准确度,若当前备份点对应的准确度低于上一个备份点,则将目标神经网络模型退回到上一个备份点。
10.作为优选,所述接收节点接收到数据行时,为数据行建立若干个副本,副本数量与数据存储节点数量匹配,将数据行中的非数值字段转换为数值字段,将数值字段的真实值拆分为若干个加数,加数的数量与副本数量匹配,将若干个加数分配给若干个副本存储,所述托管节点请求调用相应行编号的数据行时,所述数据存储节点将对应的数据行提交给所述托管节点,所述托管节点复原数据行代入目标神经网络模型后,销毁复原数据行。
11.作为优选,所述接收节点接收到数据行时,为数据行建立若干个副本,副本数量与数据存储节点数量匹配,将数据行中的非数值字段转换为数值字段,将数值字段的真实值拆分为若干个加数,加数的数量与副本数量匹配,将若干个加数分配给若干个副本存储,所述托管节点请求调用相应行编号的数据行时,将数据行的行编号以及目标神经网络模型的神经元的输入数直接涉及数据行字段的输入数计算式发送给若干个数据存储节点,所述数据存储节点将存储的加数代入输入数计算式,将获得的输入数发送给托管节点,所述托管节点将收到的全部输入数求和作为神经元的最终输入数,将输入数代入激活函数,得出神经元的输出,所述托管节点继续求解目标神经网络模型的输出。
12.本发明的实质性效果是:通过接收节点和数据存储节点,接收数据源提供的数据,
提供用于训练神经网络模型的数据积累,托管节点自行寻找符合要求的数据并代入目标神经网络模型进行训练,使目标神经网络的训练能够自动进行,具备自动撮合目标神经网络模型和数据的效果;神经网络训练完成后,仅将训练好的神经网络模型导出,不会泄露数据源的数据,有效保护数据的隐私;能够在训练数据并不在同一时间准备好的情况下,自动等待和寻找训练数据,不需要人工值守;对数据具有分辨能力,避免同样的数据多次计费;通过备份保证神经网络模型的训练效果;通过多个数据存储节点进行改进的多方计算,能够更加有效保护数据的隐私。
附图说明
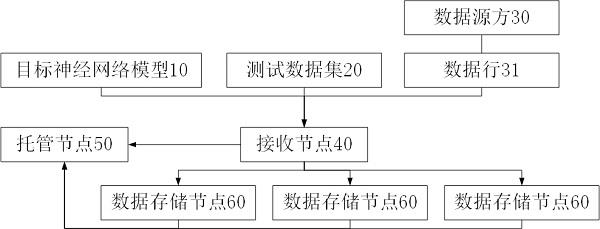
13.图1为实施例一神经网络模型托管训练系统结构示意图。
14.图2为实施例一历史记录集示意图。
15.图3为实施例一数据行存储示意图。
16.其中:10、目标神经网络模型,20、测试数据集,30、数据源方,31、数据行,32、替代数表,33、加数,34、副本,40、接收节点,50、托管节点,51、历史记录表,52、行哈希值,53、模型编号,60、数据存储节点,61、调用记录表,62、时间戳。
具体实施方式
17.下面通过具体实施例,并结合附图,对本发明的具体实施方式作进一步具体说明。
18.实施例一:一种基于区块链的神经网络模型托管训练系统,请参阅附图1,本实施例包括:接收节点40,接收目标神经网络模型10、测试数据集20和数据源方30按批次上传的数据行31,为数据行31分配批次编号和行编号,将数据行31的字段关联行编号并公开;若干个数据存储节点60,与接收节点40连接,接收节点40将数据行31分散存储在若干个数据存储节点60上;托管节点50,与接收节点40连接,获取目标神经网络模型10,获得目标神经网络模型10的输入字段和输出字段,获得含有目标神经网络模型10输入字段和输出字段的数据行31的行编号,向若干个数据存储节点60请求调用相应行编号的数据行31,并生成账单,使用测试数据集20获得目标神经网络模型10的准确度,若准确度符合预设准确度要求,则将账单发送给用户,用户将账单对应的代币转账到托管节点50的虚拟账户后,托管节点50将训练后的神经网络模型提供给用户,将代币转账到数据源方30的虚拟账户,若准确度不符合预设准确度要求,则等待接收节点40接收到新的含有目标神经网络模型10输入字段和输出字段的数据行31。本实施例使用的代币是稳定币,即与法币的兑换比例固定的代币。可以新建专用区块链并使用稳定币,也可以在已经存在的且使用稳定币的区块链上,进行本实施例的实施。使用稳定币的区块链上有至少一个兑换节点,支持随时进行代币和法币的兑换业务。本实施例的最佳实施方式是托管用户建立好神经网络的结构、损失函数和梯度函数,赋予权系数初值后,交由本实施例进行托管训练。本实施例中的托管节点50会主动寻找满足条件的数据行31,代入神经网络模型,获得损失函数值和梯度值,并根据梯度值更新神经网络模型的权系数。代入一定量的数据行31训练后,神经网络模型将具有满足预设条件的准确度。即可交付给托管用户,完成托管训练的任务。
19.如银行甲建立的客户流失预警模型,该神经网络模型用于判断客户是否存在流失
风险,以提醒银行职员及时联系客户,了解业务状态,挽回客户流失。本实施例中,客户流失指的是客户在该行所有业务终止并销号。但是具体业务部门可单独定义在该部门的全部业务或某些业务上,客户的终止行为。本实施例以信用卡客户的流失预警为例,进行举例说明。由于信用卡存在年费,一旦客户不再使用某一银行的信用卡时,通常会较为及时的对信用卡进行销户。因而本实施例中认定信用卡销卡客户为流失客户。本神经网络的输入字段有:客户的年龄、性别、学历、居住城市、信用卡交易的平均间隔时间、信用卡交易平均金额、信用卡促销活动参与次数、是否有本行借记卡和上一次信用卡交易距当前时长。银行甲、银行乙和银行丙均具有覆盖上述输入字段的数据。
20.银行甲由于开展信用卡业务年限较短,信用卡用户数据较少,难以有效进行客户流失预警模型的训练。因而建立好目标神经网络模型10的结构,确定初始的权系数、损失函数和梯度函数后,将目标神经网络模型10提交给托管节点50,并将自身已有的部分信用卡客户数据作为测试数据提交给托管节点50。若银行甲不提交测试数据,则托管节点50从数据源方30指定若干个数据行31,进行目标神经网络的准确度测试。托管节点50分析目标神经网络,获得其输入字段和输出字段,输出字段即用户是否销户的结果。银行乙将其数据上传到接收节点40,以共享其数据,同时赚取收益。对于单条数据行31的使用定价,本实施例不做讨论。接收节点40收到银行乙提交的数据后,将数据的字段结构和行编号公开。托管节点50查询字段结构,发现银行乙提交的数据可以用于目标神经网络的训练。并通过公开的行编号,能够准确指定数据行31。托管节点50请求调用行编号的数据行31,将行编号发送给数据存储节点60。若干个数据存储节点60将分散存储的银行乙提供的信用卡用卡数据复原,代入目标神经网络模型10,获得神经网络模型的输出。与数据行31中客户是否销户的结果对比,获得损失函数值,进而获得梯度值。借助梯度值更新目标神经网络模型10的权系数。而后再次指定下一个数据行31的行编号,再次向数据存储节点60发起调用请求。如此不断,则目标神经网络将不断得到训练和优化。当银行乙提供的数据被全部代入后,进行测试,发现仍然不足以达到预设的准确度,即需要更多的数据进行训练。
21.此后,等待一段时间后,银行丙上传了一批信用卡客户的用卡数据,同样包含了目标神经网络模型10的全部字段。托管节点50按照前述的方式,同样进行了数据的调用训练。银行丙提交的数据全部调用后,进行准确度的测试,发现符合预设的准确度要求。于是将目标神经网络模型10交付给托管用户。托管用于想要继续托管训练,以进一步提高预测准确度,则托管节点50可以继续等待新的符合条件的数据被提交到接收节点40。
22.训练过程中产生的费用,托管用户通过兑换代币,将代币转账到托管节点50的虚拟账户。托管节点50和接收节点40对账后,自动进行支付。
23.托管节点50为目标神经网络模型10建立有历史记录表51,请参阅附图2,历史记录表51记录代入目标神经网络模型10进行训练的数据行31的行哈希值52,托管节点50将新的数据行31代入目标神经网络模型10前,提取新的数据行31的行哈希值52,并在历史记录表51查询,若行哈希值52已存在于历史记录表51中,则跳过该数据行31且不计入账单,若行哈希值52在历史记录表51中不存在,则将数据行31代入目标神经网络模型10进行训练,将行哈希值52加入历史记录表51,并计入账单。接收节点40为目标神经网络模型10分配有模型编号53,数据存储节点60建立有调用记录表61,托管节点50向数据存储节点60调用数据时,向数据存储节点60发送行编号和模型编号53,数据存储节点60收到调用请求时,将行编号
和模型编号53关联时间戳62记录到调用记录表61中,数据存储节点60周期性将调用记录表61新增的记录一起提取哈希值并上传到区块链存储,托管节点50周期性将历史记录表51的哈希值关联模型编号53上传区块链存储。
24.如一段时间后,银行乙再次提交了数据,这些数据与上一次提交的数据,即有重叠,也有新的数据行31。同时银行乙自行对某些数据字段进行统计和归一化,但仍然包含客户流失预警模型的全部字段。接收节点40为银行乙再次提交的数据行31分配了行编号。但其中部分数据是重复的,但具有不同的行编号。因而托管节点50在调用时,通过对比数据行31的哈希值,判断该条数据已经被调用过,且支付过费用,因而跳过该数据行31。
25.本实施例中,银行乙提交的数据行31可能因增加了字段,或者客户流失预警模型不需要使用的字段的值发生了改变,导致数据行31哈希值不同。然而,客户流失预警模型需要使用的字段的值却并未发生变化。虽然同样的样本数据两次代入目标神经网络模型10,仍然能够产生损失函数值和梯度值,但本实施例为交易公平,主动避免同样的数据付费两次。因而本实施例中,托管节点50存储的数据行31哈希值,是仅提取所需要使用的字段一起提取的哈希值。调用新的数据行31时,也仅将需要使用的字段一起提取哈希值进行对比。
26.托管节点50代入批次数据行31前,将当前目标神经网络模型10备份,并记录当前神经网络模型的准确度,当批次数据的数据行31输入神经网络训练后,使用测试数据集20获得目标神经网络模型10的准确度,若准确度增加,则丢弃备份的目标神经网络模型10,若准确度降低,则将目标申请网络模型退回到备份。当一批数据行代入目标神经网络模型10训练后,最终结果反而降低了目标神经网络模型10在目标测试集上的准确度,则应该退回到备份。本实施例中,该批次数据将不收费。实际实施时,可以变更为收费或者折扣收费。
27.作为替代实施方式,托管节点50将数据行31代入目标神经网络模式训练时,周期性生成备份点,使用测试数据集20获得备份点目标神经网络模型10的准确度,若当前备份点对应的准确度低于上一个备份点,则将目标神经网络模型10退回到上一个备份点。实际上,只有优质的数据才能提高目标神经网络模型10的准确度。然而如何在训练前就判断数据是否优质,目前还缺乏较为准确的方法。本实施例则采用了代入后验证的方式进行判断。若目标神经网络模型10代入了较差的数据进行训练,导致目标神经网络模型10的准确度不升反降,则退回到备份点。
28.请参阅附图3,接收节点40接收到数据行31时,为数据行31建立若干个副本34,副本34数量与数据存储节点60数量匹配,建立替代数表32,替代数表32记录非数值型字段和替代数的映射关系,对于文本型字段,如备注、详细地址等,对神经网络的训练的作用不大,本实施例忽略这种没有一定取值范围的文本型字段,将数据行31中的非数值字段转换为数值字段,将数值字段的真实值拆分为若干个加数33,加数33的数量与副本34数量匹配,将若干个加数33分配给若干个副本34存储,托管节点50请求调用相应行编号的数据行31时,数据存储节点60将对应的数据行31提交给托管节点50,托管节点50复原数据行31代入目标神经网络模型10后,销毁复原数据行31。将数据行31拆分成副本34进行存储,能够有效提高数据存储节点60在存储数据过程中的安全性,适合长期存储数据行31,有助于数据存储节点60积累大量的数据,方便后续神经网络模型的训练。
29.本实施例的有益技术效果是:通过接收节点40和数据存储节点60,接收数据源提供的数据,提供用于训练神经网络模型的数据积累,托管节点50自行寻找符合要求的数据
并代入目标神经网络模型10进行训练,使目标神经网络的训练能够自动进行,具备自动撮合目标神经网络模型10和数据的效果;神经网络训练完成后,仅将训练好的神经网络模型导出,不会泄露数据源的数据,有效保护数据的隐私;能够在训练数据并不在同一时间准备好的情况下,自动等待和寻找训练数据,不需要人工值守;对数据具有分辨能力,避免同样的数据多次计费;通过备份保证神经网络模型的训练效果;通过多个数据存储节点60进行改进的多方计算,能够更加有效保护数据的隐私。
30.实施例二:一种基于区块链的神经网络模型托管训练系统,本实施例在实施例一的基础上,对托管节点50调用数据行31的方式进行了进一步的改进。在本实施例中,接收节点40接收到数据行31时,为数据行31建立若干个副本34,副本34数量与数据存储节点60数量匹配,将数据行31中的非数值字段转换为数值字段,将数值字段的真实值拆分为若干个加数33,加数33的数量与副本34数量匹配,将若干个加数33分配给若干个副本34存储,托管节点50请求调用相应行编号的数据行31时,将数据行31的行编号以及目标神经网络模型10的神经元的输入数直接涉及数据行31字段的输入数计算式发送给若干个数据存储节点60,数据存储节点60将存储的加数33代入输入数计算式,将获得的输入数发送给托管节点50,托管节点50将收到的全部输入数求和作为神经元的最终输入数,将输入数代入激活函数,得出神经元的输出,托管节点50继续求解目标神经网络模型10的输出。
31.客户的年龄、性别、学历、居住城市、信用卡交易的平均间隔时间、信用卡交易平均金额、信用卡促销活动参与次数、是否有本行借记卡和上一次信用卡交易距当前时长在另一个目标神经网络模型10中,第一层神经元中的一个连接输入层的三个神经元,所连接的输入层神经元分别对应客户的年龄、信用卡交易的平均间隔时间和信用卡交易平均金额,激发函数为sigmod函数,权系数以a11、a12和a13表示,偏移量以b1表示,则其输出y等于sigmod(x),其中第一层神经元为全连接,则x= a11*年龄 a12*平均间隔时间 a13*交易平均金额 b1。
32.储户在银行甲的存款数据具体为:年龄33,平均间隔时间10天,交易平均金额260元。
33.为储户年龄33生成4个加数33分别为:33=
‑
12 13 14 18,4个副本34分配到的数值分别为:
‑
12、13、14、18。平均间隔时间10天生成4个加数33,分别4个副本34保存:10=
‑
3 2 5 6,4个副本34分配到的数值分别为:
‑
3、2、5、6。为交易平均金额260生成加数33为:260=20 50 80 110,4个副本34分配到的数值分别为:20、50、80、110。打乱顺序分配给4个副本34后,假设第一个副本34存储的数据为:
‑
12,
ꢀ‑
3,20。
34.第一个数据存储节点60存储的副本34数据为:
‑
12,
ꢀ‑
3,20,则第一个数据存储节点60计算的和为:a11*
‑
12 a12*
‑
3 a13*20,以此类推。全部4个数据存储节点60发送的和,再求和,所得结果为:a11*(
‑
12 13 14 18) a12*(
‑
3 2 5 6) a13*(20 50 80 110)。即为:a11*33 a12*10 a13*260,加上偏移值b1,即获得x的值,代入sigmod(x)函数即得到神经元的输出y。在计算过程中,原始的真实值混杂在多个加数33中,从而得以隐藏,难以被准确发现,提高了数据的隐私性和安全性。
35.相对于实施例一,本实施例对数据行31的调用过程中,不需要恢复出原始的数据行31,就可以完成将数据行31代入目标神经网络模型10进行训练,获得损失函数值和梯度
值。由于不需要恢复原始的数据行31,因而极大的提高了数据行31的安全性和隐私性。
36.以上的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。