1.本发明提出一种基于知识引导深度注意力网络的场景文字视觉问答方法(scene
‑
textvisual questionanswering)。核心方法为提出知识引导深度注意力网络,通过建模物体对象和文本对象间的相对空间关系特征、前预测词和文本对象的相对语义关系特征,得到先验知识关系,以此获得更加丰富的信息,并在场景文本视觉问答这一深度学习任务中能够更准确的生成答案,验证了该模型的优越性。本方法首次提出建模物体对象和文本对象间的相对空间关系特征,由此获得对象间更丰富的空间关系。同时,本方法也首次提出建模前预测词和文本对象的相对语义关系特征,能够进一步获得前预测词和文本对象更深层次的语义关系。在场景文本视觉问答实验中,将多模态特征和上述的先验知识关系输入到模型中,在推理模块(reasoning module)中完成了多模态特征的深层交互,在生成模块(generation module)中完成了前预测词和文本对象的深层理解,进而得到了更好的实验结果。
背景技术:
2.视觉问答(visual questionanswering)是一种涉及计算机视觉和自然语言处理的学习任务,它以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,经过视觉问答系统,输出一条自然语言作为答案。因此,需要让机器对图片的内容、问题的含义和意图以及相关的常识有一定的理解。
3.场景文本视觉问答是视觉问答的一个子任务。与视觉问答任务一样,场景文本视觉问答任务同样也有一张图片和一个对应的问题作为输入,但它在视觉问答的基础上新增了光学字符识别(optical characterrecognition)部分,用于获取图片中的文本信息,场景文本视觉问答也需要同视觉问答一样,融合不同模态的数据。相比之下,场景文本视觉问答更侧重于图片中的文本信息,它的问题主要围绕图片中的文本信息,它的回答也需要用到图片中的文本信息。一个场景文本视觉问答算法需要学习下列条件:
①
意识到这是个关于文字的问题;
②
检测出包含文字的区域;
③
把包含文字的区域转化为文本形式;
④
将文本和视觉内容结合起来,确立它们之间的关系;
⑤
确定是否将检测到的文本直接确定为答案还是要对文本进行处理。
4.场景文本视觉问答的正确答案来自不同的回答者,具有较高的自由度。同时,自然场景下的图片载体主题多样,内容复杂富于变化,图像中物体和文本可能具有较高的差异性,而这使得场景文本视觉问答面临巨大的挑战。
5.在场景文本视觉问答任务中,主要涉及到物体检测(object detection)、光学字符识别、词嵌入(word embedding)、多模态融合等技术。其中多模态融合是近年来科研机构、工业界研究的重点,有效的融合能够获取让模型获取足够丰富且有效的信息,利于模型预测出更准确的答案。在多模态融合中,主要的模型分为两类,一类是基于图神经网络的模型,另一类是基于注意力机制的模型。由于场景文本视觉问答需要建立在对多模态信息的充分利用的基础上,因此有效挖掘多模态之间的关系显得尤为重要,通过建模物体对象和
文本对象间的相对空间关系特征、前预测词和文本对象的相对语义关系特征,得到先验知识关系,有助于模型获得更深层的理解,进而得到了更好的实验结果。
6.在实际应用方面,场景文本视觉问答任务的未来应用潜力巨大,比如面向视觉障碍用户。
7.我国的残障人群数量接近9000万,其中视障人群数量达到1800万,相当于在我国每90人中就有一名视障人士。我国是全世界视障人士数量最多的国家,也是盲人群体最大的国家。而视觉系统是人类感知环境信息的主要途径,80%以上的信息都是通过眼睛来获取。在当下的中国,视障人士占据残疾人士较大比例的情况下,他们在日常生活中的视觉信息感知与交互需求难以得到充分满足正成为一个亟待解决的问题。未来可以与语音技术相结合,视障用户可以通过上传一张图像,并向系统提出问题,算法可以根据用户的输入信息,进行理解,最后通过语音播报的形式向用户解答,在一定程度上提高视觉障碍人群的生活质量,具有较大的市场应用价值和社会效益。
8.综上所述,场景文本视觉问答是一个值得深入研究的课题,本专利拟从该任务中几个关键点切入展开探讨,解决目前方法存在的难点和重点,形成一套完整的场景文本视觉问答系统。
技术实现要素:
9.本发明提供了一种基于知识引导深度注意力网络的的场景文字视觉问答方法。本发明主要包含两点:
10.1、通过建模物体对象和文本对象间的相对空间关系特征,输入到关系自注意力网络,以充分发掘对象之间的相对空间关系,获取更丰富的信息。
11.通过建模前预测词和文本对象的相对语义关系特征,充分理解答案与文本对象之间的语义关系,结合动态指针网络的输出结果,获取更深层次的表达。
12.本发明解决其技术问题所采用的技术方案包括如下步骤:
13.步骤(1)、数据集的划分
14.对数据集进行划分;
15.步骤(2):构建问题的语言特征
16.一个问题由k个单词组成,针对每个单词k,使用预先训练好的词向量模型将其转换为包含语义信息的词向量其中d
ques
指的是问题单词的词向量维数;将一个问题中k个单词的词向量拼接成一个完整问题的语言特征,再经过线性变换映射至d维空间,得到特征
17.步骤(3):构建图像的物体综合特征
18.对于一张输入图像,使用训练好的目标检测网络计算出图像中包含物体的m个候选框;针对每一个候选框m,获得其空间特征将该候选框在图像中对应的区域输入到目标检测网络中,并提取网络的某一层的输出作为该候选框的视觉特征使用可学习的线性变换将视觉特征和空间特征投影到d维空间,得到该候选框m的综合特征将一张图像中所有物体的综合特征拼接成总的物体综合特征为
19.步骤(4):获取图像的文本综合特征
20.对于一张输入图像,使用离线的ocr系统获取图像中包含文本的n个文本信息,包括候选框信息和框内字符信息;针对每一个候选框信息n,获得其空间特征将该候选框在图像中对应的区域输入到训练好的目标检测网络中并提取网络的某一层的输出作为该候选框的视觉特征针对每一个框内字符信息n使用fasttext算法获得一个文本字符特征使用phoc算法获得另一个文本字符特征利用线性变换将获得的空间特征视觉特征文本字符特征和投影到d维空间,得到该文本信息n的文本综合特征将一张图像中所有文本综合特征拼接成总的文本综合特征为
21.步骤(5):构建前预测词的特征
22.模型通过从ocr文本或固定词汇表中选择单词来迭代解码生成答案,在迭代自回归的解码过程中,将第t次解码时预测单词的特征、来源、位置,构建得到前一个预测词的综合特征并将作为第t 1次解码的输入;一个完整的答案由t次解码预测的单词组成,将所有前预测词的特征拼接成完整的前预测词特征
23.步骤(6):构建相对空间关系特征
24.针对图像中的任意两个对象i,j来生成相对空间关系特征针对图像中的任意两个对象i,j来生成相对空间关系特征将一张图像中所有的对象,共计m n个,都构建成总相对空间关系特征所述的对象包括物体和文本;
25.步骤(7):构建相对语义关系特征
26.在迭代自回归的解码过程中,第t次解码时,将第t
‑
1次解码得到的预测单词c和图像中的字符信息n,利用余弦相似度计算得到单词c和字符信息n之间的相对语义关系特征一个完整的答案由t次解码预测的单词组成,将答案中所有预测单词和图像中所有文本对象的相对语义关系特征拼接成总相对语义关系特征对象的相对语义关系特征拼接成总相对语义关系特征
27.步骤(8):构建深度神经网络
28.将问题的语言特征q、图像的物体综合特征x
obj
、图像的文本综合特征x
ocr
、前预测词的特征x
dec
拼接成特征将特征i和相对空间关系特征f
sp
输入到推理模块中,产生融合各模态信息的向量第t次解码时,将输出z
t
对应的文本特征和前预测词特征输入到动态指针网络中,动态指针网络的输出结合相对语义关系特征f
se
,预测得到文本中单词的答案概率和固定词汇表中单词的答案概率将拼接成从中选择概率最大的单词作为第t次解码的预测答案,并迭代预测下一个单词,直至结束;
29.步骤(9):损失函数
30.将步骤(8)中输出的预测答案同对应的正确答案一起输入到损失函数中,计算得到损失值;
31.步骤(10):训练模型
32.根据步骤(8)中的损失函数产生的损失值利用反向传播算法对步骤(8)中的深度神经网络模型参数进行梯度回传,不断优化,直至整个网络模型收敛;
33.步骤(11):网络预测值计算
34.根据步骤(8)中输出的从中选择概率最大的单词作为第t次解码的预测答案,并迭代预测下一个单词,直至结束,生成最终的答案。
35.进一步的,步骤(2)所述的构建问题的语言特征,具体如下:
36.使用预先训练好的词向量模型将问题中的每个单词k转换为包含语义信息的词向量其中d
ques
指的是问题单词的词向量维数;.将k个单词组成的问题拼接成一个完整问题的语言特征,再经过线性变换映射至d维空间,具体公式如下:
[0037][0038]
其中,linear是线性变换。
[0039]
进一步的,步骤(3)所述的构建图像的物体综合特征具体如下:
[0040]
对于每一个候选框m,其空间位置坐标为(x
min
,y
min
,x
max
,y
max
),(x
min
,y
min
)表示候选框的左上角点的位置坐标,(x
max
,y
max
)表示候选框的右下角点的位置坐标,其空间特征表示为具体公式如下:
[0041][0042]
其中,w、h分别是图像的宽、高;
[0043]
对于每一个候选框m,视觉特征为使用可学习的线性变换将视觉特征、空间特征投影到d维空间,得到该候选框i的综合特征具体公式如下:
[0044][0045]
其中w1、w2是可学习的映射矩阵,ln是层标准化;
[0046]
每张图像选取包含物体的m个候选框,将每张图像中所有的候选框拼接成总的物体综合特征具体公式如下:
[0047][0048]
进一步的,步骤(4)所述的构建图像的文本综合特征具体如下:
[0049]
对于每一个候选框n,其空间位置坐标为(x
min
,y
min
,x
max
,y
max
,),(x
min
,y
min
)表示候选框的左上角点的位置坐标,(x
max
,y
max
)表示候选框的右下角点的位置坐标,其空间特征表示为具体公式如下:
[0050][0051]
对于每一个候选框n,视觉特征为一个字符特征为另一个字符特征为利用线性变换将空间特征、视觉特征、字符特征投影到d维空间,得到该候选框n的文本综合特征具体公式如下:
[0052][0053]
其中w3、w4、w5是可学习的映射矩阵,ln是层标准化;
[0054]
将每张图像中所有文本综合特征拼接成总的文本综合特征为具体公式如下:
[0055][0056]
进一步的,步骤(5)所述的构建前预测词的特征,具体如下:
[0057]
在迭代自回归的解码过程中,将第t次解码时预测单词的特征、来源、位置,构建得到前一个预测词的综合特征并将作为第t 1次解码的输入,其中第1次解码的输入是一个特殊字符’<s>’;一个完整的答案由t次解码预测的单词组成,将所有前预测词的特征拼接成完整的前预测词特征具体公式如下:
[0058][0059]
进一步的,步骤(6)所述的构建相对空间关系特征,具体如下:
[0060]
通过任意两个候选框之间的相对位置进行建模来生成相对空间关系特征;将第i个对象的空间位置定义为(x
i
,y
i
,w
i
,h
i
),该四维坐标分别表示对象的中心点横纵坐标、宽、高;第i个对象和第j个对象之间的相对空间关系特征表示为具体公式如下:
[0061][0062]
将每张图像中的所有对象关系对特征拼接成总相对空间关系特征为具体公式如下:
[0063][0064]
其中,p=m n。
[0065]
进一步的,步骤(7)所述的构建相对语义关系特征,具体如下:
[0066]
使用预先训练好的词向量模型分别将先前预测的单词c、图像中文本的单词n转换
为包含语义信息的词向量为包含语义信息的词向量利用余弦相似度计算先前预测的单词c与图像中文本的单词n之间的相对语义关系特征其中第1次预测时,先前预测的单词是一个特殊字符’<s>’,具体公式如下:
[0067][0068]
一个完整的答案由t个单词组成,图像中有n个文本单词,将答案中所有预测单词和图像中所有文本单词的相对语义关系特征拼接成成总相对语义关系特征具体公式如下:
[0069][0070]
进一步的,步骤(8)所述的构建深度神经网络,具体如下:
[0071]8‑
1.融合问题的语言特征、图像的物体综合特征、图像的文本综合特征、前预测词的特征;
[0072]
问题的语言特征q、图像的物体综合特征x
obj
、图像的文本综合特征x
ocr
、前预测词的特征x
dec
是来自各模态的特征,经过线性映射,可以映射到相同纬度d,并且拼接上述四种特征为i∈具体公式如下:
[0073]
i=[q,x
obj
,x
ocr
,x
dec]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式13)
[0074]8‑
2.构建知识增强自注意力网络ksa
[0075]
将特征i和相对空间关系特征f
sp
作为ksa的输入,输出具体公式如下:
[0076]
b'=ln(i kmsa(i,i,i,f
sp
))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式14)
[0077]
b=ln(b' ffn(b'))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式15)
[0078]
其中,kmsa是知识增强多头自注意力网络,是ksa网络的一部分,它的输入是i和f
sp
,输出是富含多模态信息的特征向量,输出是富含多模态信息的特征向量具体公式如下:
[0079]
q=linear[i]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式16)
[0080]
k=linear[i]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式17)
[0081]
v=linear[i]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式18)
[0082][0083]
其中q、k、分别由i经过全连接层映射得到;以避免下溢问题;
[0084]
其中,mlp是两层感知机,具体公式如下:
[0085][0086]
其中,relu是激活函数,fc1、是全连接层;
[0087]
其中,ffn结构的输入是b',具体公式如下:
[0088]
ffn(b')=fc
d
(drop(relu(fc
4d
(b'))))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式21)
[0089]8‑
3.深度堆叠ksa网络
[0090]
以融合后的特征i和相对空间关系特征f
sp
作为输入,深度堆叠ksa网络[ksa
(1)
,ksa
(2)
,
…
,ksa
(e)
];将第e层ksa
(e)
的输出特征和相对空间关系特征f
sp
作为第e 1层ksa
(e 1)
的输入,迭代往复,公式如下:
[0091]
i
(e 1)
=ksa
(e 1)
(i
(e)
,f
sp
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式22)其中,i
(0)
=i,对不同层的ksa,关系特征f
sp
保持不变;
[0092]8‑
4.多头注意力的特征融合
[0093]
将步骤8
‑
3的输出i
(e 1)
作为输入,经过全连接层,输出单头z
u
,公式如下:
[0094]
z
u
=linear(i
(e 1)
)linear(i
(e 1)
)
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式23)
[0095]
多头注意力z由u个相互独立的单头组成,进一步提高注意特征的表征能力,具体公式如下:
[0096]
z=[z1,z2,
…
,z
u
,
…
,z
u
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(公式24)
[0097]8‑
5迭代解码计算概率
[0098]
第t次解码时,将步骤8
‑
4的第t次输出z
t
对应的文本特征对应的文本特征和前预测词特征输入到动态指针网络中,预测得到原始的ocr文本单词的答案概率具体公式如下:
[0099][0100]
其中,w
ocr
、b
ocr
、
[0101]
将与相对语义关系特征相结合,形成最终的ocr文本单词的答案概率具体公式如下:
[0102][0103]
通过计算得到固定词汇表中单词的答案概率具体公式如下:
[0104][0105]
其中,将拼接成具体公式如下:
[0106][0107]
从中选择概率最大的单词作为第i次解码的答案,并迭代预测下一个单词,直至结束。
[0108]
进一步的,步骤(9)所述的损失函数,具体如下:
[0109]
计算预测答案与真实标签之间的差距,这里使用二元交叉熵损失(binary cross
‑
entropy loss),具体公式如下:
[0110][0111]
进一步的,步骤(10)所述的训练模型,具体如下:
[0112]
根据步骤(9)中的损失函数产生的损失值利用反向传播算法对步骤(8)中神经网络的模型参数进行梯度回传,不断优化,直至整个网络模型收敛。
[0113]
本发明有益效果如下:
[0114]
本发明提出一种基于知识引导深度注意力网络的的场景文字视觉问答方法,通过建模物体对象和文本对象间的相对空间关系特征、前预测词和文本对象的相对语义关系特征,得到先验知识关系,并深度堆叠知识增强自注意力网络层数来获得更加丰富的信息,相比于先前基于卷积神经网络和构建对象间浅层关系的方法性能有了很大提升。
附图说明
[0115]
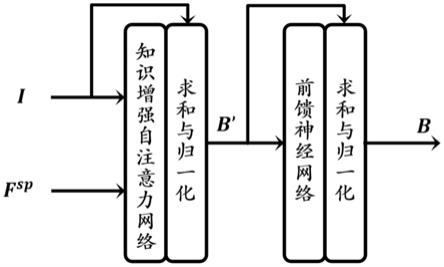
图1:知识增强自注意力模块
[0116]
图2:知识引导深度注意力网络架构
具体实施方式
[0117]
下面对本发明的详细参数做进一步具体说明。
[0118]
如图1和2所示,本发明提供一种基于知识引导深度注意力网络的的场景文字视觉问答方法。
[0119]
步骤(1)具体实现如下:
[0120]
划分数据集:训练集由21953张图片,34602个问题组成;
[0121]
验证集由3166张图片,5000个问题组成;测试集由3289张图片,5734个问题组成。
[0122]
步骤(2)所述的构建问题的语言特征,具体如下:
[0123]
一个问题由k个单词组成,针对每个单词k,使用预先训练好的词向量模型将其转换为包含语义信息的词向量其中d
ques
指的是问题单词的词向量维数;将一个问题中k个单词的词向量拼接成一个完整问题的语言特征,再经过线性变换映射至d维空间,得到特征
[0124]
步骤(3)所述的构建图像的物体综合特征,具体如下:
[0125]
对于一张输入图像,使用训练好的目标检测网络计算出图像中包含物体的m个候
选框;针对每一个候选框d,获得其空间特征将该候选框在图像中对应的区域输入到目标检测网络中,并提取网络的某一层的输出作为该候选框的视觉特征使用可学习的线性变换将视觉特征和空间特征投影到d维空间,得到该候选框m的综合特征将一张图像中所有物体的综合特征拼接成总的物体综合特征为
[0126]
步骤(4)所述的构建图像的文本综合特征,具体如下:
[0127]
对于一张输入图像,使用离线的ocr系统获取图像中包含文本的n个文本信息,包括候选框信息和框内字符信息;针对每一个候选框信息n,获得其空间特征将该候选框在图像中对应的区域输入到训练好的目标检测网络中并提取网络的某一层的输出作为该候选框的视觉特征针对每一个框内字符信息n使用fasttext算法获得一个文本字符特征使用phoc算法获得另一个文本字符特征利用线性变换将获得的空间特征视觉特征文本字符特征和投影到d维空间,得到该文本信息n的文本综合特征将一张图像中所有文本综合特征拼接成总的文本综合特征为
[0128]
步骤(5)所述的构建前预测词的特征,具体如下:
[0129]
模型通过从ocr文本或固定词汇表中选择单词来迭代解码生成答案,在迭代自回归的解码过程中,将第t次解码时预测单词的特征、来源、位置,构建得到前一个预测词的综合特征并将作为第t 1次解码的输入;一个完整的答案由t次解码预测的单词组成,将所有前预测词的特征拼接成完整的前预测词特征
[0130]
其中第1次解码的输入是一个特殊字符’<s>’。
[0131]
步骤(6)所述的构建相对空间关系特征,具体如下:
[0132]
针对图像中的任意两个对象i,j来生成相对空间关系特征针对图像中的任意两个对象i,j来生成相对空间关系特征将一张图像中所有的对象,共计m n个,都构建成总相对空间关系特征所述的对象包括物体和文本;
[0133]
步骤(7)所述的构建相对语义关系特征,具体如下:
[0134]
使用预先训练好的词向量模型分别将先前预测的单词c、图像中文本的单词n转换为包含语义信息的词向量为包含语义信息的词向量利用余弦相似度计算先前预测的单词c与图像中文本的单词n之间的相对语义关系特征其中第1次预测时,先前预测的单词是一个特殊字符’<s>’;
[0135]
一个完整的答案由t个单词组成,图像中有n个文本单词,将答案中所有预测单词和图像中所有文本单词的相对语义关系特征拼接成成总相对语义关系特征
[0136]
步骤(8)所述的构建深度神经网络,具体如下:
[0137]8‑
1.融合问题的语言特征、图像的物体综合特征、图像的文本综合特征、前预测词的特征;
[0138]
问题的语言特征q、图像的物体综合特征x
obj
、图像的文本综合特征x
ocr
、前预测词的特征x
dec
是来自各模态的特征,经过线性映射,可以映射到相同纬度d,并且拼接上述四种特征为征为
[0139]8‑
2.构建知识增强自注意力网络ksa
[0140]
将特征i和相对空间关系特征f
sp
作为ksa的输入,输出其中,kmsa是知识增强多头自注意力网络,是ksa网络的一部分,它的输入是i和f
sp
,输出是富含多模态信息的特征向量其中q、k、分别由i经过全连接层映射得到;以避免下溢问题;
[0141]8‑
3.深度堆叠ksa网络
[0142]
以融合后的特征i和相对空间关系特征f
sp
作为输入,深度堆叠ksa网络[ksa
(1)
,ksa
(2)
,
…
,ksa
(e)
];将第e层ksa
(e)
的输出特征和相对空间关系特征f
sp
作为第e 1层ksa
(e 1)
的输入,迭代往复。其中,i
(0)
=i,对不同层的ksa,关系特征f
sp
保持不变;
[0143]8‑
4.多头注意力的特征融合
[0144]
将步骤8
‑
3的输出i
(e 1)
作为输入,经过全连接层,输出单头z
u
;多头注意力z由u个相互独立的单头组成,进一步提高注意特征的表征能力。
[0145]8‑
5迭代解码计算概率
[0146]
第t次解码时,将步骤8
‑
4的第t次输出z
t
对应的文本特征对应的文本特征和前预测词特征输入到动态指针网络中,预测得到原始的ocr文本单词的答案概率
[0147]
将与相对语义关系特征相结合,形成最终的ocr文本单词的答案概率
[0148]
通过计算得到固定词汇表中单词的答案概率
[0149]
将拼接成从中选择概率最大的单词作为第i次解码的答案,并迭代预测下一个单词,直至结束。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。