1.本发明属于水质评价技术领域,尤其涉及一种基于多源数据融合的水质评价方法。
背景技术:
2.水资源是人类赖以生存的基础,随着经济的不断发展,对水资源需求日益增多的同时,也带来了生态环境的破坏,造成许多水体的大面积污染,人类与水资源的矛盾日渐突出。如何保护水资源,保护我们赖以生存的生态环境,是站在全人类面前的一道难题。水质评价作为水体状况的定性或定量描述,可以准确反映当前的水质和污染状况,对水资源保护起着决定性作用,是解决水资源问题必不可少的环节。
3.水质评价方法的研究已经取得丰硕成果,但是发展至今还不够完善,需要进一步深入研究。常见的水质评价方法大致包括单因子评价法、水质指数法、模糊数学评价法、神经网络评价法以及数据融合评价法等。单因子评价方法的机制是利用水质最差单指标分类确定综合水质分类,方法简单清晰,但评价结果过于保守并不能得到综合评价,而且评价结果的准确性较差。水质指数模型(wqi)是应用较为广泛的综合评价方法,wqi模型虽易于理解,但其大多是针对特定研究水域,通用性较差,并且wqi的计算过程尤其是参数权重的判定会增加模型的不确定性。然而根据水环境监测数据多源、异构、不确定性、非线性等特点,数据融合技术在水质综合评价中得到广泛应用。数据融合技术充分利用多个水质传感器观测数据,把多传感器在空间或时间上冗余或互补的信息依据某种准则来进行合成,从而获得对水质的一致性解释或描述。
4.但是,上述方法无法解决水质评价结果准确性差的问题。
技术实现要素:
5.有鉴于此,本发明实施例提供了一种基于多源数据融合的水质评价方法,以解决现有技术中评价结果的准确性差的问题。
6.本发明实施例提供了一种基于多源数据融合的水质评价方法,包括:
7.将预处理后的水质评价指标输入到预设的神经网络模型,得到水质类别;
8.对水质类别进行归一化处理,得到基本概率分配函数;
9.将基本概率分配函数输入到预设的d
‑
s证据理论模型,得到目标融合评价结果。
10.在一种可能的实现方式中,预设的神经网络模型包括反向传播神经网络模型、径向基神经网络模型和极限学习机网络模型;
11.将预处理后的水质评价指标输入到预设的神经网络模型,得到水质类别,包括:
12.将预处理后的水质评价指标分别输入到反向传播神经网络模型、径向基神经网络模型和极限学习机网络模型,得到反向传播神经网络模型对应的第一水质类别、径向基神经网络模型对应的第二水质类别和极限学习机网络模型对应的第三水质类别。
13.在一种可能的实现方式中,对水质类别进行归一化处理,得到基本概率分配函数,
包括:
14.分别将第一水质类别、第二水质类别和第三水质类别进行归一化处理,得到第一水质类别对应的第一基本概率分配函数、第二水质类别对应的第二基本概率分配函数和第三水质类别对应的第三基本概率分配函数。
15.在一种可能的实现方式中,将基本概率分配函数输入到预设的d
‑
s证据理论模型,得到目标融合评价结果,包括:
16.根据第一基本概率分配函数、第二基本概率分配函数和第三基本概率分配函数,确定第一融合评价结果;
17.利用预设迭代方法对第一融合评价结果、第一基本概率分配函数、第二基本概率分配函数和第三基本概率分配函数进行n次迭代计算,确定目标融合评价结果,其中,n为大于或等于1的整数。
18.在一种可能的实现方式中,根据第一基本概率分配函数、第二基本概率分配函数和第三基本概率分配函数,确定第一融合评价结果,包括:
19.将第一基本概率分配函数作为第一证据、将第二基本概率分配函数作为第二证据以及将第三基本概率分配函数作为第三证据,并计算第一证据对应的第一权重、第二证据对应的第二权重和第三证据对应的第三权重;
20.分别根据第一权重和预设权重的大小、第二权重和预设权重的大小以及第三权重和预设权重的大小,确定第四证据、第五证据和第六证据;
21.按照预设的组合规则对第四证据、第五证据和第六证据进行合成,得到第一融合评价结果。
22.在一种可能的实现方式中,计算第一证据对应的第一权重、第二证据对应的第二权重和第三证据对应的第三权重,包括:
23.计算第一证据与第二证据间的第一概率距离和第一冲突因子、第二证据与第三证据间的第二概率距离和第二冲突因子,以及第一证据与第三证据间的第三概率距离和第三冲突因子;
24.分别根据第一概率距离与第一冲突因子、第二概率距离与第二冲突因子以及第三概率距离与第三冲突因子,确定第一证据与第二证据间的第一冲突程度、第二证据与第三证据间的第二冲突程度以及第一证据与第三证据间的第三冲突程度;
25.分别根据第一冲突程度、第二冲突程度以及第三冲突程度,确定第一相似度、第二相似度和第三相似度;
26.分别根据第一相似度与第三相似度、第一相似度与第二相似度以及第二相似度与第三相似度,确定第一证据对应的第一支持度、第二证据对应的第二支持度以及第三证据对应的第三支持度;
27.在第一支持度、第二支持度和第三支持度中选取最大支持度,并分别基于第一支持度与最大支持度的比值、第二支持度与最大支持度的比值以及第三支持度与最大支持度的比值,确定第一权重、第二权重和第三权重。
28.在一种可能的实现方式中,将预处理后的水质评价指标输入到预设的神经网络模型,得到水质评价指标对应的水质类别之前,还包括:
29.利用训练集对初始神经网络模型进行训练,得到预设的神经网络模型;
30.对原始水质评价指标进行预处理,得到预处理后的水质评价指标。
31.在一种可能的实现方式中,利用训练集对初始神经网络模型进行训练,得到预设的神经网络模型,包括:
32.在原始样本数据中选取多个样本数据作为训练集;
33.将训练集输入初始神经网络模型,待迭代次数达到预设次数,确定预设的神经网络模型。
34.在一种可能的实现方式中,对原始水质评价指标进行预处理,得到预处理后的水质评价指标,包括:
35.利用预设函数对原始水质评价指标进行归一化处理,得到预处理后的水质评价指标。
36.在一种可能的实现方式中,原始水质评价指标包括:溶解氧、高锰酸盐指数、五日生化需氧量、氨氮和总磷。
37.本发明实施例与现有技术相比存在的有益效果是:
38.本发明实施例的一种基于多源数据融合的水质评价方法,通过将预处理后的水质评价指标输入到预设的神经网络模型,得到水质类别,然后对水质类别进行归一化处理,得到基本概率分配函数,最后将基本概率分配函数输入到预设的d
‑
s证据理论模型,得到目标融合评价结果。本发明依次采用预设的神经网络模型和预设的d
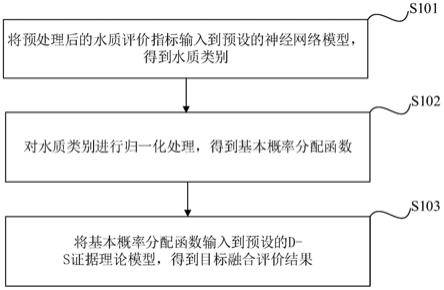
‑
s证据理论模型对水质指标进行处理,确定目标融合评价结果,提高了评价结果的准确性。
附图说明
39.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
40.图1是本发明一实施例提供的一种基于多源数据融合的水质评价方法的实现流程示意图;
41.图2本发明实施例提供的预设的神经网络模型的结构示意图;
42.图3是本发明另一实施例提供的一种基于多源数据融合的水质评价方法的实现流程示意图;
43.图4本发明实施例提供的改进d
‑
s证据理论的融合评价流程图。
具体实施方式
44.以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、技术之类的具体细节,以便透彻理解本发明实施例。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、装置、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
45.针对上述问题,本技术提出一种基于多源数据融合的水质评价方法。
46.为了说明本发明的技术方案,下面通过具体实施例来进行说明。
47.图1是本发明一实施例提供的一种基于多源数据融合的水质评价方法的实现流程
示意图。如图1所示,该实施例的一种基于多源数据融合的水质评价方法包括:
48.步骤s101:将预处理后的水质评价指标输入到预设的神经网络模型,得到水质类别;
49.步骤s102:对水质类别进行归一化处理,得到基本概率分配函数;
50.步骤s103:将基本概率分配函数输入到预设的d
‑
s证据理论模型,得到目标融合评价结果。
51.具体地,地表水水质评价指标为《地表水环境质量标准》(gb
‑
2002)中除水温、总氮、粪大肠菌群以外的21项指标,而考虑到评价模型的复杂度和水质指标测量的便捷性,实际的水质评价只会选取若干项影响度高的指标。根据研究水域的水质特征和主要污染物,选取溶解氧、高锰酸盐指数、五日生化需氧量、氨氮、总磷五项水质评价指标。水质评价标准依据《地表水环境质量标准》(gb
‑
2002),按ⅰ、ⅱ、ⅲ、ⅳ、
ⅴ
、劣
ⅴ
六个类别进行水质评价,如表1所示。
52.表1水质评价指标与水质类别的对应关系表
[0053][0054]
其中,结合图2,基于预设神经网络的结构图可知,将预处理后的水质评价指标输入到预设的神经网络模型,得到水质类别。每个评价指标对应的水质类别如表1所示,例如溶解氧对应的类别ⅰ的数值为7.5、类别ⅱ的数值为6、类别ⅲ的数值为5、类别ⅳ的数值为3以及类别
ⅴ
的数值为2,系统内会设置溶解氧的预设条件,将上述满足预设条件的类别作为溶解氧的类别,其他不再赘述。
[0055]
在一实施例中,步骤s101,包括:
[0056]
将预处理后的水质评价指标分别输入到bp(back propagation,反向传播)神经网络模型、rbf(径向基)神经网络模型和极限学习机网络模型,得到bp神经网络模型对应的第一水质类别、rbf神经网络模型对应的第二水质类别和极限学习机网络模型对应的第三水质类别。
[0057]
上述三种神经网络的输入层神经元个数由选取的水质评价指标决定,输出层神经元个数由水质类别个数决定,且水质类别值采用二进制编码,如:100000代表ⅰ类水,000001代表劣
ⅴ
类水。神经网络训练测试数据根据《地表水环境质量标准》(gb 3838
‑
2002)进行均匀随机插值产生。
[0058]
具体地,水质评价本质上是一个基于地表水环境质量标准的模式识别问题,神经网络的输入层神经元个数由选取的水质评价因子的个数决定(五个水质评价指标为溶解
氧、高锰酸盐指数、五日生化需氧量、氨氮、总磷),输出层神经元个数为水质类别数(ⅰ、ⅱ、ⅲ、ⅳ、
ⅴ
、劣
ⅴ
),模型结构如图2所示。特别地,水质类别值采用二进制编码如表2所示。
[0059]
表2水质类别编码
[0060][0061]
bp神经网络结构设计:选取单隐层的三层网络结构,隐含层神经元个数没有明确的选取规则,本文采用常用的经验公式确定为11。利用matlab r2018a工具箱函数实现神经网络编码,采取feedforword函数构建bp神经网络,网络中隐含层激活函数选取s型正切函数tansig,输出层激活函数选取线性函数purelin,训练方法为trainlm,即lm(levenberg
‑
marquardt)算法,学习率设定为0.05,期望误差为0.001,网络最大训练次数为1000次。
[0062]
rbf神经网络结构设计:采用newrb函数创建径向基网络,期望误差为0.001,径向基函数扩展速度spread值为0.35,其它参数为默认值。创建rbf神经网络是一个不断尝试的过程,通过不断增加隐含层径向基神经元个数,直至满足期望误差。
[0063]
极限学习机网络结构设计:编写函数创建极限学习机网络,期望误差为0.001,隐含层神经元个数为180,激活函数选取sigmoid函数。
[0064]
得到上述三种网络结构后,需要采用训练集对原始神经网络进行训练,得到预设的神经网络,再经测试集确定预设神经网络的输出结果,其中,输出结果分别为第一子水质类别值、第二子水质类别值和第三子水质类别值。其中,神经网络训练测试数据根据《地表水环境质量标准》(gb 3838
‑
2002)利用rand函数进行均匀随机插值产生。每一类水质生成300组数据,共生成1800组数据,按照7:3的比例划分训练集和测试集。数据集采用mapminmax函数进行归一化。
[0065]
在一实施例中,步骤s102包括:
[0066]
分别将第一水质类别、第二水质类别和第三水质类别进行归一化处理,得到第一水质类别对应的第一基本概率分配函数、第二水质类别对应的第二基本概率分配函数和第三水质类别对应的第三基本概率分配函数。
[0067]
具体地,结合图3,将预处理后的水质评价指标输入到预设的神经网络模型后,并对输出结果进行归一化处理,得到基本概率分配函数。由于预设的神经网络模型包括bp神经网络模型、rbf神经网络模型和极限学习机网络模型,因此,经上述三种神经网络输出每种神经网络对应的数值类别值,即第一水质类别、第二水质类别和第三子水质类别。再将上
述第一水质类别、第二水质类别和第三水质类别进行归一化处理,得到每种水质类别对应的基本概率分配函数,即第一基本概率分配函数m1、第二基本概率分配函数m2和第三基本概率分配函数m3。
[0068]
在一实施例中,步骤s103包括:
[0069]
步骤s201:根据第一基本概率分配函数、第二基本概率分配函数和第三基本概率分配函数,确定第一融合评价结果。
[0070]
具体地,将第一基本概率分配函数作为第一证据、将第二基本概率分配函数作为第二证据以及将第三基本概率分配函数作为第三证据,并计算第一证据对应的第一权重、第二证据对应的第二权重和第三证据对应的第三权重;分别根据第一权重和预设权重的大小、第二权重和预设权重的大小以及第三权重和预设权重的大小,确定第四证据、第五证据和第六证据;按照预设的组合规则对第四证据、第五证据和第六证据进行合成,得到第一融合评价结果。
[0071]
在一实施例中,计算第一证据对应的第一权重、第二证据对应的第二权重和第三证据对应的第三权重,包括:
[0072]
计算第一证据与第二证据间的第一概率距离和第一冲突因子、第二证据与第三证据间的第二概率距离和第二冲突因子,以及第一证据与第三证据间的第三概率距离和第三冲突因子;
[0073]
分别根据第一概率距离与第一冲突因子、第二概率距离与第二冲突因子以及第三概率距离与第三冲突因子,确定第一证据与第二证据间的第一冲突程度、第二证据与第三证据间的第二冲突程度以及第一证据与第三证据间的第三冲突程度;
[0074]
分别根据第一冲突程度、第二冲突程度以及第三冲突程度,确定第一相似度、第二相似度和第三相似度;
[0075]
分别根据第一相似度与第三相似度、第一相似度与第二相似度以及第二相似度与第三相似度,确定第一证据对应的第一支持度、第二证据对应的第二支持度以及第三证据对应的第三支持度;
[0076]
在第一支持度、第二支持度和第三支持度中选取最大支持度,并分别基于第一支持度与最大支持度的比值、第二支持度与最大支持度的比值以及第三支持度与最大支持度的比值,确定第一权重、第二权重和第三权重。
[0077]
具体地,d
‑
s证据理论是建立在一个非空集合θ上的理论,用θ表示n个互不相容的基本命题组成的辨识框架,即θ={θ
(1)
,θ
(2)
,...,θ
(n)
}。2
θ
称为θ的幂集,问题域中所有的子命题都属于幂集2
θ
。
[0078]
在θ上定义基本概率分配函数m:2
θ
∈[0,1];m满足m(φ)=0;m(a)表示对命题a发生的支持程度。设m1和m2为识别框架θ上的两个基本概率分配函数,d
‑
s证据理论的组合规则表示如下:
[0079]
[0080]
其中,为冲突因子,k值越大表示证据间冲突越大。多个证据的组合实则为证据间两两组合,组合规则符合结合律和交换律。
[0081]
改进d
‑
s证据理论具体步骤包括:计算证据间冲突程度,获得各个证据的折扣因子即权重;修正冲突证据;利用d
‑
s合成规则融合各个证据,迭代修正融合结果。具体流程图如图4所示。
[0082]
1、冲突程度衡量与折扣因子获取
[0083]
m为识别框架θ上的基本概率分配,与m对应的pignistic函数betp
m
:θ
→
[0,1]为:
[0084][0085]
将betp
m
扩展到θ的幂集2
θ
上,则betp
m
为:
[0086][0087]
其中,|a|为集合a的势。
[0088]
根据betp
m
函数定义两个基本概率分配m1和m2间的pignistic概率距离difbetp为:
[0089][0090]
证据间冲突程度的衡量:
[0091]
证据间相似度:s
ij
=1
‑
conf
ij
ꢀꢀ
(6)
[0092]
证据间支持度:
[0093]
对证据间支持度进行排序,具有最大支持度的证据为关键证据,折扣因子(权重)为所求证据的支持度与关键证据支持度的比值:
[0094][0095]
2、修正冲突证据
[0096]
冲突证据的修正是本发明改进方法的核心,为了充分利用原始证据的有效信息,故对没有冲突的证据不予修正,只修正存在冲突的证据。所谓的冲突证据定义为权重小于平均证据权重的证据,即当时。
[0097]
冲突证据的修正公式如下:
[0098][0099]
3、首次融合过程如下:
[0100]
(1)根据式(8)求出首次证据合成的权重
[0101]
(2)将权重代入式(9)修正冲突证据;
[0102]
(3)将修正后的证据代入式(1)进行合成,得到首次融合结果(初始融合评价结果)r0。
[0103]
步骤s202:利用预设迭代方法对第一融合评价结果、第一基本概率分配函数、第二基本概率分配函数和第三基本概率分配函数进行n次迭代计算,确定目标融合评价结果,其中,n为大于或等于1的整数。
[0104]
具体地,计算每条证据与第一融合评价结果之间的冲突程度、相似度、支持度得到新的权重,利用新的权重修正证据并合成第二融合评价结果,当第一融合评价结果与第二融合评价结果的间距小于指定阈值,则迭代完成。需要说明的是,当第一融合评价结果与第二融合评价结果的间距不小于指定阈值,则需继续计算下一融合评价结果,直至下一融合评价结果与上一融合评价结果的间距小于指定阈值,迭代才结束。
[0105]
结合图4,计算原始证据与第k
‑
1次合成的结果r
k
‑1的冲突程度、相似度、支持度,确定新的证据权重,之后根据权重重新修正冲突证据,再计算第k次融合结果r
k
;最后,判断迭代收敛条件,当时迭代完成并输出r
k
,否则继续迭代。
[0106]
在一实施例中,步骤s102之前,还包括:利用训练集对初始神经网络模型进行训练,得到预设的神经网络模型;对原始水质评价指标进行预处理,得到预处理后的水质评价指标。其中,利用训练集对初始神经网络模型进行训练,得到预设的神经网络模型,包括:在原始样本数据中选取多个样本数据作为训练集;将训练集输入初始神经网络模型,待迭代次数达到预设次数,确定预设的神经网络模型。
[0107]
基于上述方法,对仿真实验进行评估,具体步骤如下:
[0108]
采用仿真软件matlab r2018a版验证本发明的方法,利用中国环境监测总站发布的2021年4月份冀南地区(邯郸市、邢台市)地表水水质数据,选取岳城水库出口、曲周、东武仕出口、后西吴桥、艾辛庄五个监测断面进行实验验证。表3为五个监测断面传感器实际的监测数据。
[0109]
表3冀南地区监测断面数据
[0110][0111]
[0112]
采用不同方法分别对五个监测断面的水质情况进行评价,结果如表4所示。
[0113]
表4不同方法水质评价结果
[0114][0115]
通过表4的水质评价结果可以发现,单因子评价法过于保守,无法充分利用各个水质监测指标提供的信息。不同的神经网络由于参数选择、学习算法等不同,判断结果也具有差异性。岳城水库出口的五个水质指标全部在ⅰ类水范围内,各种方法均可以准确判断水质等级;曲周的两个指标属于ⅰ类水,两个指标属于ⅲ类,一个属于ⅳ类,综合评价结果为ⅲ类水质更合理;东武仕出口包含三个ⅰ类水质指标,且其余两个ⅱ类指标较为接近ⅰ类标准值,故判定为ⅰ类水;后西吴桥的三个指标为ⅰ类水,两个指标为ⅲ类水,结果为ⅱ类水较为合理;同样地,艾辛庄的水质判定为ⅲ类也是合适的。综上,单因子评价法最为保守,三种神经网络方法结果相对合理,本发明的评价方法综合性高,结果最为合理。
[0116]
三种神经网络的水质评价结果并不完全一致,即使得到相同的结果,但其水质类别对应的神经网络输出值不一致,而且没有达到理想的输出值1,因此评价结果存在不确定性,精确性有待提高。本发明提出的方法利用d
‑
s证据理论融合三种神经网络输出,最终得到一个确定的评价结果。
[0117]
以艾辛庄为例,详细描述具体的融合过程。首先构建证据体,水质评价的识别框架为六类水质,ⅰ类(a1)、ⅱ类(a2)、ⅲ类(a3)、ⅳ类(a4)、
ⅴ
类(a5)、劣
ⅴ
类(a6)。对艾辛庄对应的神经网络输出结果归一化处理,得到基本概率分配函数m1、m2和m3,分别代表bp神经网络、rbf神经网络和极限学习机的评价结果,如下所示。
[0118]
艾辛庄的基本概率分配函数:
[0119]
m1:0.1468 0.3500 0.4635 0.0336 0.0057 0.0004
[0120]
m2:0.0233 0.1298 0.6012 0.0169 0.0302 0.1986
[0121]
m3:0.1153 0.0422 0.0055 0.5868 0.2108 0.0394
[0122]
艾辛庄的证据3与证据1、证据2存在明显冲突,证据3支持a4,证据1、证据2均支持a3但支持度较低,不利于决策判断。经d
‑
s证据理论融合后,其结果如表5所示。
[0123]
表5艾辛庄水质融合结果
[0124][0125]
对比分析本发明方法、murphy法和传统d
‑
s证据理论,表5中传统证据理论的融合结果与其它两种方法不一致,主要在于融合的三个证据存在冲突,无法得出正确的结果。相反,其它两种方法均能够有效处理证据间的冲突,从而做出正确决策,并且容易发现本发明方法的识别精度更高。
[0126]
应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
[0127]
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
[0128]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
[0129]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。