一种基于cv
‑
lstm组合模型的地连墙变形动态预测方法
技术领域
1.本发明涉及一种地连墙变形预测方法,尤其是涉及一种基于cv
‑
lstm组合模型的地连墙变形动态预测方法。
背景技术:
2.目前,我国正处于轨道交通建设的快速发展阶段,由此出现了大量的车站基坑工程,基坑的开挖规模和深度也在不断加大。例如某市地铁某号线某车站的最大开挖深度达到了29 m。基坑工程是一种包含土体和支护结构的空间体系,受到地质条件、施工质量和周边环境等诸多内在和外在因素的影响。现场实测变形数据是施工过程中各种影响综合作用的体现。因此,分析研究现场变形监测数据成为人们认识基坑变形特性的有效途径。
3.在不同土体性质和不同支护类型下的基坑地连墙变形规律预测方面的研究,预测方法主要分为以下三种:经验法、数值模拟法和机器学习。经验法需要大量的监测数据, 且局限于用差分方程来建立离散的随机模型, 不便于描述系统变化过程的本质和内在规律;数值法具有数学方法上的精确性, 但由于基坑地连墙变形影响因素的复杂性、物理机制的模糊性以及参数的多变和不确定性, 使得在使用该方法时过分概化, 降低了实用价值。目前,机器学习法大多采用较多的是经典的bp神经网络,这种反向传播的神经网络结构相对简单,但无法准确处理输入时间上关联性且在处理长序列数据时误差较大;另外一种处理序列数据的lstm算法,优点是方便序列建模,具备长时记忆的能力,但也存在着泛化能力较差的不足。
技术实现要素:
4.本发明针对现有技术存在的不足,提供一种基于cv
‑
lstm组合模型的地连墙变形预测方法,其组合模型具有更高的稳定性,适用于地连墙变形的长期、动态预测,且具有较高的预测精度和更好的泛化能力。
5.实现本发明目的的技术方案是提供一种基于cv
‑
lstm神经网络算法的地连墙变形动态预测方法,包括以下步骤:步骤一:选取监测点,采集基坑工程地连墙的变形历史监测数据,将每个监测点采集的变形观测值记录为,表示测点i在第t天的变形值,形成观测值的时间序列;将监测数据整理形成监测表;步骤二:(1)利用pytorch框架包中xlrd 模块读入步骤(1)形成的监测表,用tensor函数将数据存储为张量结构,得到一个数据集;(2)采用k折交叉验证法和lstm神经网络算法建立预测组合模型,预测组合模型的输入层为,输出层为,其中,n为输入信息长度,m为预测时
间跨度;所述的预测组合模型,采用k折交叉验证法,将数据集划分为k个子集,轮流将其中k
‑
1个子集作为训练集样本,用于训练,剩余的1个子集作为测试集样本,用于测试;所述的预测组合模型,采用lstm神经网络算法对训练集样本进行学习,设定超参数,包括训练轮数epoch、学习率lr、隐藏层神经元的数量hidden_size,通过调整超参数,训练得到最优模型;所述的调整超参数的方法为:采用adam算法对迭代更新公式中的网络参数w进行调整,其迭代更新公式为:调整,其迭代更新公式为:调整,其迭代更新公式为:;其中,w为待训练的网络参数;为学习率;dw为梯度;为一阶矩衰减系数;为二阶矩衰减系数;v为原始梯度的指数加权平均值;s为梯度平方的指数加权平均值;为梯度的归一化处理;步骤三:将训练得到的最优模型对测试集样本进行变形预测,得到地连墙变形预测值。
6.本发明技术方案中,lstm神经网络算法的前向传播公式分别为:第一个模块为“忘记门”,用以计算上一时刻神经元状态信息的遗忘比例:第二个模块为“输入门”,用以新信息写入神经元状态的比例:,用以新信息写入神经元状态的比例:,用以新信息写入神经元状态的比例:第三个模块为“输出门”,将决定被当成隐状态输出的信息:,将决定被当成隐状态输出的信息:其中,c
(t)
和h
(t)
分别代表t时刻的神经元状态和隐状态;f
(t)
,i
(t)
和o
(t)
分别代表t时刻的遗忘门、输入门和输出门;w,b分别是各个门控模块中的权重矩阵和偏置向量;s表示sigmoid激活函数;tanh表示双曲正切激活函数。
7.本发明所述的一种基于cv
‑
lstm神经网络算法的地连墙变形动态预测方法,一个优选的方案是:,, 。
8.本发明采集基坑工程地连墙的变形历史监测数据,包括通过埋设于墙体混凝土内的活动式测斜仪监测的地连墙水平位移;监测频率为每天1次,开挖深度超过20 m后增加到
2次/天,变形异常时为2~3次/天。
9.本发明测量地连墙各监测点的变形真实值
ŷ
i
,依据步骤三得到地连墙变形预测值y
i
和真实值
ŷ
i
,以mse、mae和mape为损失函数,分别计算精度评价指标mse、mae和mape,对预测组合模型进行预测精度评价,其计算公式如下: ,,。
10.与现有技术相比,本发明具有以下优点:1. 本发明针对监测数据具有周期长以及非线性的特点,采用cv
‑
lstm组合模型的预测模型方法,克服了传统神经网络出现过拟合和梯度爆炸的不足。
11.2. 本发明提供的组合模型由于其处理长序列数据的优势,对于地连墙变形的长期预测具有较高的精度。
12.3. 本发明提供的组合模型表现出更好的稳定性和更高的预测精度,更适用于地连墙变形的动态预测。
13.4.本发明提供的地连墙变形预测方法具有更好的泛化能力。
附图说明
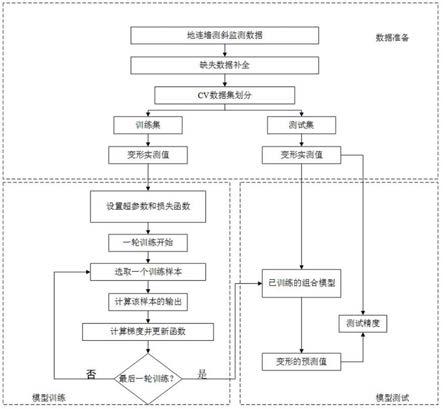
14.图1为本发明实施例用于地连墙变形预测的基坑平面及测斜点布置示意图;图2为本发明实施例用于地连墙变形预测的基坑标准段的断面设计示意图;图3为本发明实施例提供的变形预测组合模型流程图;图中,
①
杂填土、
③
粉质黏土、
④
粉土夹粉砂、
⑤
粉土夹粉质黏土、
⑥
粉质黏土、
⑦
粉砂夹粉土。
具体实施方式
15.下面结合附图和具体实施例对本发明进行详细说明。
16.实施例1本发明应用在某城市轨道交通某地铁车站深基坑工程的工程实例中。
17.参见附图1,为本实施例用于地连墙变形预测的基坑平面及测斜点布置示意图;该地铁车站站基坑呈东西向,基坑北侧离已有建筑物最近距离仅1.7 m。基坑围护结构采用1.0 m厚地下连续墙。基坑标准段采用6道内支撑,子基坑b总长约103.0 m,标准段宽23.1 m,开挖深度24.16 m。选取了b基坑主体结构cx10~cx19监测点自2018年8月8日至2019年7月9日共计2329组地连墙测斜监测数据作为原始样本进行预测训练,地连墙水平位移通过埋设于墙体混凝土内的活动式测斜仪进行监测。
18.参见附图2,为本实施例用于地连墙变形预测的基坑标准段的断面设计示意图;场地自上而下依次分布有
①
杂填土、
③
粉质黏土、
④
粉土夹粉砂、
⑤
粉土夹粉质黏土、
⑥
粉质黏土和
⑦
粉砂夹粉土,稳定水位埋深为1.20~1.90 m。场地内分布的粉质黏土层主要呈软塑状,具有压缩性高、灵敏性高、抗剪强度低等特点,而且有显著的流变性,是影响工程建设
的主要软弱土层。b基坑标准段竖向设6道内支撑。
19.参见附图3,为本实施例提供的变形预测组合模型流程图;获取数据集,补全缺失数据,采用cross
‑
validation交叉验证法划分数据集。利用lstm神经网络对训练集样本进行学习,设定训练轮数(epoch)、学习率(lr)、隐藏层神经元的数量(hidden_size)等超参数。将训练好的最优模型对测试集样本进行变形预测,获得地连墙短期变形预测值和长期变形预测值,并计算精度评价指标。
20.具体实施步骤如下:步骤一:选取监测点,采集基坑工程地连墙的变形历史监测数据,地连墙测斜监测频率原则上为每天1次,开挖深度超过20 m后增加到2次/天,变形异常时为2~3次/天,监测数据整理形成监测日报,由于施工过程中监测点存在遮挡压盖等情况,造成部分缺失数据,以线性插值补全,将每个监测点采集的变形观测值记录为,表示测点i在第t天的变形值,形成变观测值的时间序列,将监测数据整理形成监测表。
21.步骤二:利用pytorch框架包中xlrd 模块读入监测日报中的数据,并用tensor函数将监测数据存储为张量结构。预测组合模型的输入层为,预测组合模型的输出层为,其中n输入信息长度,m表示预测时间跨度。
22.采用cross
‑
validation交叉验证法划分数据集,针对地连墙测斜变形原始样本中的cx10~cx19测斜点采用10折交叉验证法,每个测点都可以作为测试集被预测过一次,从而相对客观地反映预测模型的泛化性。
23.采用lstm神经网络对训练集样本进行学习,设定训练轮数(epoch)、学习率(lr)、隐藏层神经元的数量(hidden_size)等超参数,其前向传播公式分别为:第一个模块为“忘记门”,用以计算上一时刻神经元状态信息的遗忘比例:第二个模块为“输入门”,用以新信息写入神经元状态的比例:,用以新信息写入神经元状态的比例:,用以新信息写入神经元状态的比例:第三个模块为“输出门”,将决定被当成隐状态输出的信息:,将决定被当成隐状态输出的信息:其中,c
(t)
和h
(t)
分别代表t时刻的神经元状态和隐状态;f
(t)
,i
(t)
和o
(t)
分别代表t时刻的遗忘门、输入门和输出门;w,b分别是各个门控模块中的权重矩阵和偏置向量;s表示sigmoid激活函数;tanh表示双曲正切激活函数。
24.lstm网络结构较深,参数更新困难,因而本实施例采用自适应矩估计算法(adam, adaptive moment estimation)进行优化。adam一方面动态地修改各参数的学习率,另一方面引入动量法,使得参数更新有更多的机会跳出局部最优解。其迭代更新公式如下:面引入动量法,使得参数更新有更多的机会跳出局部最优解。其迭代更新公式如下:面引入动量法,使得参数更新有更多的机会跳出局部最优解。其迭代更新公式如下:;其中,w为待训练的网络参数;为学习率;dw为梯度;为一阶矩衰减系数;为二阶矩衰减系数。v为原始梯度的指数加权平均值;s为梯度平方的指数加权平均值;为梯度的归一化处理;本实施例中,,,。
25.步骤三:使用训练好的最优组合模型对测试集样本进行变形预测,获得地连墙变形预测值y
i
。
26.由于输出的预测值y
i
与真实值
ŷ
i
之间都存在一定的误差,神经网络通过损失函数(loss function)评价该误差,常用的损失函数mse、mae和mape三个值越小说明组合模型拥有更好的精准度。使用训练好的最优组合模型对测试集样本进行变形预测,从而获得地连墙短期变形预测值和长期变形预测值。计算组合模型在预测任务下的评价指标mse、mae和mape值,评价cv
‑
lstm组合模型的预测精度。
27.将变形预测值和变形实测值预测值y
i
与真实值
ŷ
i
进行对比,分别计算其精度评价指标mse、mae以及mape,其计算公式如下:指标mse、mae以及mape,其计算公式如下:指标mse、mae以及mape,其计算公式如下:。
28.为了进一步验证cv
‑
lstm组合模型的有效性,选择了经典的bp神经网络进行对比,并设计了4个预测任务,反映预测模型在不同的输入信息长度和预测步长下的预测效果。
29.任务1:根据前3天的变形监测值预测1天后的变形量(n=3,m=1);任务2:根据前3天的变形监测值预测7天后的变形量(n=3,m=7);任务3:根据前15天的变形监测值预测1天后的变形量(n=15,m=1);任务4:根据前15天的变形监测值预测7天后的变形量(n=15,m=7)。
30.10折交叉验证的预测误差mse值(单位/mm2)具体结果如表1。
31.表1
。
32.表1结果表明,在所有的预测任务中cv
‑
lstm组合模型的表现全面优于bp组合模型,在测试集上都得到了较小的误差值。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。