1.本发明涉及电力工业能耗领域,更具体地,涉及一种基于支持向量回归机的水泥搅拌机能耗建模方法。
背景技术:
2.近几年来,我国经济已经由高速增长阶段转向高质量发展阶段,正处在转变发展方式、优化经济结构、转换增长动力的攻关期。国家一直大力推进供给侧结构性改革和电力需求侧管理工作,强调要合理控制能源消耗,提高能源利用效率。为积极响应国家政策,在工作目标中明确提出深化可调节负荷应用。我国工业负荷容量大、涉及工业种类多,且多处于集中管理,具体较大的工业负荷可调节潜力。如果能进一步提高工业负荷的调控能力,使其能更加积极地参与电网调度管理,将有利于新能源的推广,降低工业负荷生产成本和资源浪费。
3.作为基建大国,水泥及其相关工业在我国工业负荷占比中占据了很大一部分份额,中国发明专利申请(cn109389164a)“基于支持向量回归模型的地区单位gdp能耗预测方法”对数据进行主成分分析处理后作为支持向量回归模型的输入数据,通过训练得到地区单位gdp能耗预测模型;中国发明专利(cn105627504b)“基于支持向量机的变风量中央空调系统冷水机组能耗估计方法”对数据进行相关性分析处理后作为支持向量机模型的输入数据,通过训练得到冷水机组能耗预测模型;中国发明专利申请(cn110567101a)“一种基于支持向量机模型的冷水机组高能效控制方法”,中国发明专利申请(cn103544398a)“一种基于回归型支持向量机确定节能效果的方法及系统”;可见,现有技术中,对水泥搅拌机参与电网优化和负荷调控方面的研究,尚缺少能够可靠运行的准确的定量模型来作为依据和标准,并且能耗研究不够细致,无法对水泥搅拌机能耗进行更准确的预测。
4.近年来,电力行业响应国家战略部署,重视人工智能技术的发展,强化人工智能技术在电力领域内的应用。负荷预测技术的影响因素多种多样,传统预测技术往往面临预测精度问题,近年来基于python的人工智能等大数据分析的负荷预测方法开始崭露头角。同时,大数据技术也可以有效挖掘数据潜在的信息,进而更准确的分析数据。
5.因此,结合人工智能技术,对水泥搅拌机能耗建立相关预测模型,具有较高的应用价值。
技术实现要素:
6.为解决现有技术中存在的不足,本发明的目的在于,提供一种基于支持向量回归机的水泥搅拌机能耗建模方法,解决目前有关典型工业负荷的能耗分析问题,弥补现有的粗糙的能耗建模方式不能准确预测水泥搅拌机能耗情况以及分析与能耗相关参数的特性问题。
7.本发明采用如下的技术方案。
8.一种基于支持向量回归机的水泥搅拌机能耗建模方法包括:
9.步骤1,采集水泥搅拌机的运行过程状态数据和稳定性数据;
10.步骤2,对运行过程状态数据进行预处理,得到参数矩阵a;
11.步骤3,根据参数矩阵a,使用奇异值分解法得到新参数矩阵a
*
;
12.步骤4,将稳定性数据加入新参数矩阵a
*
,得到数据集b并作为自变量,将对应的水泥搅拌机消耗的总能耗值作为因变量,使用高斯径向基函数作为核函数,构建水泥搅拌机能耗模型。
13.优选地,步骤1中,运行过程状态数据包括:工作电流、阻抗、轴功率、桨叶排液量、压头、桨叶直径、搅拌转速、进料量、出料量、骨料平均粒径;稳定性数据包括:工作电压、工作频率。
14.优选地,步骤2包括:
15.步骤2.1,从运行过程状态数据中提取各数据的特征值;
16.步骤2.2,对特征值数据,采用z
‑
score标准化方法,以如下关系式进行归一化处理:
[0017][0018]
式中,x表示某一项数据的特征值,表示某一项数据的平均值,σ表示某一项数据的标准差,x
*
为归一化处理后得到的数据;
[0019]
步骤2.3,将归一化处理后的各数据特征值进行向量化处理,得到参数矩阵a。
[0020]
进一步,步骤2.1中,对于搅拌转速、进料量、出料量、桨叶直径,均取实际值作为特征值;对于轴功率、压头、桨叶直径、骨料平均粒径,均取平均值作为特征值;
[0021]
根据工作电流,提取搅拌机的启动峰值电流和达到电流波动不超过5%的稳定阶段所用的电流稳定时间作为特征值;
[0022]
提取桨叶排液量以及桨叶排液量的平均变化率作为特征值。
[0023]
进一步,步骤2.2中,对于以实际值作为特征值的各数据,即搅拌转速、进料量、出料量不进行归一化处理。
[0024]
进一步,步骤2.3中,向量化,即将归一化处理后的各数据特征值,按进料量、出料量、启动峰值电流、电流稳定时间、轴功率、桨叶排液量、压头、桨叶直径、搅拌转速、桨叶排液量变化率和骨料平均粒径的顺序依次放入参数矩阵a中。
[0025]
优选地,步骤3包括:
[0026]
步骤3.1,根据参数矩阵a构建第一方阵aa
t
和第二方阵a
t
a;
[0027]
步骤3.2,求解第一方阵aa
t
的第一特征值u
i
和第一特征向量、第二方阵a
t
a的第二特征值v
i
和第二特征向量;
[0028]
步骤3.3,利用第一特征向量构建维数为m
×
m的左奇异矩阵u,利用第二特征向量构建维数为n
×
n的右奇异矩阵v;
[0029]
步骤3.4,以如下关系式计算奇异值矩阵的对角元δ
i
,所得对角元δ
i
按从大到小排列组成奇异值矩阵:
[0030][0031]
步骤3.5,选取k值,使得奇异值矩阵中前k列奇异值之和与全部奇异值之和之比大
于等于95%;在右奇异矩阵v中取前k行组成新的右矩阵v
*
;
[0032]
步骤3.6,以如下关系式计算得到新参数矩阵a
*
:
[0033]
a
*
=a(v
*
)
t
[0034]
新参数矩阵a
*
是参数矩阵a的降维后结果。
[0035]
优选地,步骤4包括:
[0036]
步骤4.1,选择径向基函数作为核函数,构建支持向量回归机的模型,其中,所述径向基函数为高斯核函数,满足如下关系式:
[0037][0038]
式中,x和x
′
表示两个不同的向量,τ表示高斯滤波器带宽;
[0039]
步骤4.2,在新参数矩阵a
*
中,加入工作电压和工作频率的特征值数据,得到数据集b作为自变量,即水泥搅拌机能耗模型的输入数据集;以水泥搅拌机的总能耗作为水泥搅拌机能耗模型的输出数据集;
[0040]
步骤4.3,将输入数据集划分为训练集和测试集;
[0041]
步骤4.4,使用训练集对水泥搅拌机能耗模型进行训练;
[0042]
步骤4.5,使用测试集对训练好的模型进行测试,使得模型输出的总能耗的预测值和真实值之间的误差不大于5%。
[0043]
进一步,步骤4.2中,提取一段工作时间内工作电压和工作频率的平均值作为特征值。
[0044]
进一步,步骤4.4中,基于k折交叉验证法,将训练集分成k折;选其中一折数据作为验证集,其他k
‑
1折数据作为训练集,进行训练和验证;然后,换另一折数据作为验证集,其他k
‑
1折数据作为训练集;直到每一折数据都作过验证集后,得到训练好的模型。
[0045]
本发明的有益效果在于,与现有技术相比:
[0046]
1、能够有效分析典型工业负荷水泥搅拌机的能耗问题,方便分析各种参数对水泥搅拌机能耗产生的影响,方便电网实现工业负荷的优化调度问题。
[0047]
2、选用奇异值分解避免了使用特征值分解时在大量数据特征情况下需要计算原始数据协方差矩阵的麻烦,降低了模型的复杂度,提高模型运算效率,方便在线式监控能耗情况。
[0048]
3、使用支持向量回归机的方法,具有较好的鲁棒性,对未知数据拥有很好的泛化能力,尤其是在数据量较少的小样本情况下,相较于其他传统机器学习办法,具有更优的性能。
[0049]
4、建立一套反映其能耗表征特性的模型,可以挖掘其可调潜力,提高电网对能量资源的综合利用和对该工业负荷的运行效率,引导用户方参与电网实时供需平衡。
附图说明
[0050]
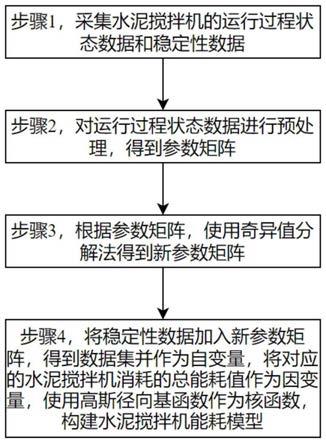
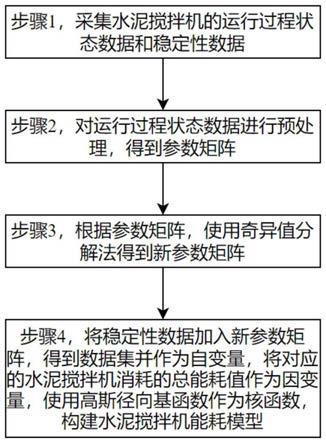
图1是本发明一种基于支持向量回归机的水泥搅拌机能耗建模方法的步骤框图;
[0051]
图2是本发明一实施例中基于支持向量回归机的水泥搅拌机能耗建模方法的流程示意图;
[0052]
图3是本发明一实施例中降维前水泥搅拌机能耗的预测值和真实值的拟合曲线
图;
[0053]
图4是本发明一实施例中降维后水泥搅拌机能耗的预测值和真实值的拟合曲线图。
具体实施方式
[0054]
下面结合附图对本技术作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本技术的保护范围。
[0055]
本发明采用如下的技术方案。
[0056]
如图1,一种基于支持向量回归机的水泥搅拌机能耗建模方法包括:
[0057]
步骤1,采集水泥搅拌机的运行过程状态数据和稳定性数据。
[0058]
具体地,步骤1中,运行过程状态数据包括:工作电流、阻抗、轴功率、桨叶排液量、压头、桨叶直径、搅拌转速、进料量、出料量、骨料平均粒径;稳定性数据包括:工作电压、工作频率。
[0059]
水泥搅拌机的原始数据包括:水泥搅拌机运行过程中产生的主要电气量,包括但不限于电压、电流、频率、阻抗;核心生产工艺参数,包括但不限于轴功率、桨叶排液量、压头、桨叶直径、搅拌转速;实际操作的参数,包括但不限于进料量、出料量、骨料平均粒径。
[0060]
其中,对于主要电气量参数而言,搅拌机由于接入电网,其电压、频率需要保持在标准值,维系产品和电网的稳定性,而阻抗和电流可以体现搅拌机的运行效率和过程,搅拌中骨料的材质、粒径和数量会影响搅拌机的阻抗,从而在电流的变化上有所体现,在启动中电流较大随搅拌过程进行电流不断减小趋于稳定,同时,当原料量增大负荷增大,工作电流也会上升;
[0061]
对于核心生产工艺参数而言,轴功率、桨叶排液量、压头、桨叶直径、搅拌转速,这些参数互相存在耦合关系,都无法单独用来描述搅拌机的工作状态,桨叶排液量与桨叶直径、转速有关,搅拌消耗的轴功率和流体比重、桨叶转速等有关,一定功率下桨叶排液量和压头又可以通过改变桨叶直径和转速来调节等,因此在考虑这些因素时要综合考虑;
[0062]
对于实际操作的参数而言,进料量、出料量、骨料平均粒径,这些因素都是可以方便人为调节,在运送搅拌原料时,可以调节搅拌的进料量来调节搅拌的负荷,改变骨料的粒径改变搅拌机运行过程的阻抗,在工作电流中有所体现,而因为粒径大多不规则,在获取数据时选择得到粒径的平均值作为数据,出料量可以体现搅拌机的运行效率。
[0063]
步骤2,对运行过程状态数据进行预处理,得到参数矩阵a。
[0064]
具体地,步骤2包括:
[0065]
步骤2.1,从运行过程状态数据中提取各数据的特征值。
[0066]
进一步,步骤2.1中,对于搅拌转速、进料量、出料量、桨叶直径,均取实际值作为特征值;对于轴功率、压头、桨叶直径、骨料平均粒径,均取平均值作为特征值;
[0067]
根据工作电流,提取搅拌机的启动峰值电流和达到电流波动不超过5%的稳定阶段所用的电流稳定时间作为特征值;
[0068]
提取桨叶排液量以及桨叶排液量的平均变化率作为特征值。
[0069]
提取数据特征值时,首先工作电压和频率变化不大用于监控水泥搅拌机的稳定性,提取一段工作时间内的平均值作为特征;对工作电流的变化提取搅拌机启动时的峰值
电流和达到电流波动不超过5%的稳定阶段所用时间来反映搅拌的负荷和搅拌的程度;桨叶直径、进料量、出料量用实际值,另外提取桨叶排液量及其平均变化率,对其他数据提取平均值作数据。
[0070]
步骤2.2,对特征值数据,采用z
‑
score标准化方法,以如下关系式进行归一化处理:
[0071][0072]
式中,x表示某一项数据的特征值,表示某一项数据的平均值,σ表示某一项数据的标准差,x
*
为归一化处理后得到的数据,其满足正态分布。
[0073]
进一步,步骤2.2中,对于以实际值作为特征值的各数据,即搅拌转速、进料量、出料量不进行归一化处理;而其他数据间量纲不同,同一数据取值范围和变化范围相差过大,影响数据分析的结果,且因为数据间存在耦合情况,因此需要进行归一化处理。
[0074]
步骤2.3,将归一化处理后的各数据特征值进行向量化处理,得到参数矩阵a。
[0075]
进一步,步骤2.3中,向量化,即将归一化处理后的各数据特征值,按进料量、出料量、启动峰值电流、电流稳定时间、轴功率、桨叶排液量、压头、桨叶直径、搅拌转速、桨叶排液量变化率和骨料平均粒径的顺序依次放入参数矩阵a中。
[0076]
步骤3,根据参数矩阵a,使用奇异值分解法得到新参数矩阵a
*
;
[0077]
具体地,步骤3包括:
[0078]
步骤3.1,根据参数矩阵a构建第一方阵aa
t
和第二方阵a
t
a;
[0079]
步骤3.2,求解第一方阵aa
t
的第一特征值u
i
和第一特征向量、第二方阵a
t
a的第二特征值v
i
和第二特征向量;
[0080]
步骤3.3,利用第一特征向量构建维数为m
×
m的左奇异矩阵u,利用第二特征向量构建维数为n
×
n的右奇异矩阵v;
[0081]
步骤3.4,以如下关系式计算奇异值矩阵的对角元δ
i
,所得对角元δ
i
按从大到小排列组成奇异值矩阵:
[0082][0083]
步骤3.5,选取k值,使得奇异值矩阵中前k列奇异值之和与全部奇异值之和之比大于等于95%;在右奇异矩阵v中取前k行组成新的右矩阵v
*
;
[0084]
值得注意的是,本发明优选实施例中,选取的k值使得奇异值矩阵中前k列奇异值之和与全部奇异值之和之比大于等于95%,这一比例数值的选取是一种非限制性的较优选择。
[0085]
步骤3.6,以如下关系式计算得到新参数矩阵a
*
:
[0086]
a
*
=a(v
*
)
t
[0087]
新参数矩阵a
*
是参数矩阵a的降维后结果。
[0088]
步骤4,将稳定性数据加入新参数矩阵a
*
,得到数据集b并作为自变量,将对应的水泥搅拌机消耗的总能耗值作为因变量,使用高斯径向基函数作为核函数,构建水泥搅拌机能耗模型。
[0089]
具体地,步骤4包括:
[0090]
步骤4.1,选择径向基函数作为核函数,构建支持向量回归机的模型,其中,所述径向基函数为高斯核函数,满足如下关系式:
[0091][0092]
式中,x和x
′
表示两个不同的向量,τ表示高斯滤波器带宽,决定着平滑程度,影响了核函数的局部作用范围。
[0093]
步骤4.2,在新参数矩阵a
*
中,加入工作电压和工作频率的特征值数据,得到数据集b作为自变量,即水泥搅拌机能耗模型的输入数据集;以水泥搅拌机的总能耗作为水泥搅拌机能耗模型的输出数据集;
[0094]
步骤4.3,将输入数据集划分为训练集和测试集。
[0095]
本发明优选实施例中,输入数据集按照7:3的比例划分为训练集和测试集,所采用的划分比例是一种非限制性的较优选择。
[0096]
步骤4.4,使用训练集对水泥搅拌机能耗模型进行训练;
[0097]
步骤4.5,使用测试集对训练好的模型进行测试,使得模型输出的总能耗的预测值和真实值之间的误差不大于5%。
[0098]
进一步,步骤4.2中,提取一段工作时间内工作电压和工作频率的平均值作为特征值。
[0099]
进一步,步骤4.4中,基于k折交叉验证法,将训练集分成k折;选其中一折数据作为验证集,其他k
‑
1折数据作为训练集,进行训练和验证;然后,换另一折数据作为验证集,其他k
‑
1折数据作为训练集;直到每一折数据都作过验证集后,得到训练好的模型。
[0100]
实施例1。
[0101]
按照图2所示的流程实施本发明提出的基于支持向量回归机的水泥搅拌机能耗建模方法,为了验证该建模方法得到的模型的有效性,收集部分水泥搅拌机的数据在python中进行了建模,绘制水泥搅拌机能耗的预测值和真实值的拟合情况曲线图。图3给出了进行降维前水泥搅拌机能耗的预测值和真实值的拟合情况。图4给出了加入降维后水泥搅拌机能耗的预测值和真实值的拟合情况,由此可见对水泥搅拌机能耗情况预测精确。同时用均方根误差作为评价模型精确程度的标准,在加入降维处理前,模型的均方根误差为0.4737,在加入降维处理后,模型的均方根误差下降为0.4507,且模型搭建的速度更快,由此可见加入降维处理能有效提高模型的运行速度和预测精度。
[0102]
本发明的有益效果在于,与现有技术相比:
[0103]
1、能够有效分析典型工业负荷水泥搅拌机的能耗问题,方便分析各种参数对水泥搅拌机能耗产生的影响,方便电网实现工业负荷的优化调度问题。
[0104]
2、选用奇异值分解避免了使用特征值分解时在大量数据特征情况下需要计算原始数据协方差矩阵的麻烦,降低了模型的复杂度,提高模型运算效率,方便在线式监控能耗情况。
[0105]
3、使用支持向量回归机的方法,具有较好的鲁棒性,对未知数据拥有很好的泛化能力,尤其是在数据量较少的小样本情况下,相较于其他传统机器学习办法,具有更优的性能。
[0106]
4、建立一套反映其能耗表征特性的模型,可以挖掘其可调潜力,提高电网对能量
资源的综合利用和对该工业负荷的运行效率,引导用户方参与电网实时供需平衡。
[0107]
本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。