1.本技术实施例涉及计算机视觉的技术领域,例如涉及一种物体姿态的检测方法、装置、计算机设备和存储介质。
背景技术:
2.在短视频、直播、自动驾驶、ar(augmented reality,增强现实)、机器人等业务场景中,通常会进行3d(3
‑
dimension,三维)目标检测,及对作为目标的物体检测物体在三维空间的信息,进行添加特效、路线规划、运动轨迹规划等业务处理。
技术实现要素:
3.本技术实施例提出了一种物体姿态的检测方法、装置、计算机设备和存储介质。
4.第一方面,本技术实施例提供了一种物体姿态的检测方法,包括:
5.获取图像数据,所述图像数据中具有目标物体;
6.将所述图像数据输入二维检测模型中,检测三维的边界框投影至所述图像数据时的二维的第一姿态信息,所述边界框用于检测所述目标物体;
7.将所述第一姿态信息映射为三维的第二姿态信息;
8.根据所述第二姿态信息检测所述目标物体的第三姿态信息。
9.第二方面,本技术实施例还提供了一种物体姿态的检测装置,包括:
10.图像数据获取模块,设置为获取图像数据,所述图像数据中具有目标物体;
11.第一姿态信息检测模块,设置为将所述图像数据输入二维检测模型中,检测三维的边界框投影至所述图像数据时的二维的第一姿态信息,所述边界框用于检测所述目标物体;
12.第二姿态信息映射模块,设置为将所述第一姿态信息映射为三维的第二姿态信息;
13.第三姿态信息检测模块,设置为根据所述第二姿态信息检测所述目标物体的第三姿态信息。
14.第三方面,本技术实施例还提供了一种计算机设备,所述计算机设备包括:
15.至少一个处理器;
16.存储器,设置为存储至少一个程序,
17.所述至少一个处理器,设置为执行所述至少一个程序以实现如第一方面所述的物体姿态的检测方法。
18.第四方面,本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的物体姿态的检测方法。
附图说明
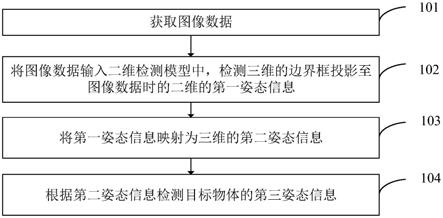
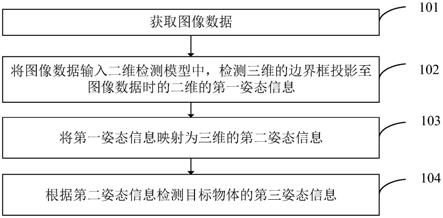
19.图1为本技术一个实施例提供的一种物体姿态的检测方法的流程图;
20.图2为本技术一个实施例提供的一种检测目标物体姿态的示例图;
21.图3为本技术另一实施例提供的一种一阶段网络的示例图;
22.图4为本技术另一实施例提供的一种两阶段网络的示例图;
23.图5是本技术另一实施例提供的一种物体姿态的检测方法的流程图;
24.图6为本技术另一实施例提供的一种物体姿态的检测装置的结构示意图;
25.图7为本技术另一实施例提供的一种计算机设备的结构示意图;
26.图8为本技术示例性实施例中的检测三维的边框投影至图像数据时的二维的第一姿态信息的流程图;
27.图9为本技术另一示例性实施例中的检测三维的边框投影至图像数据时的二维的第一姿态信息的流程图;
28.图10为本技术另一示例性实施例中的将第一姿态信息映射为三维的第二姿态信息的流程图;
29.图11为本技术另一示例性实施例中的根据第二姿态信息检测目标物体的第三姿态信息的流程图。
具体实施方式
30.相关技术中,3d目标检测方法按输入形式的不同主要可以分为如下四个大类:
31.第一类,单目图像,即输入单摄像头拍摄的一帧图像数据。
32.第二类,双目图像,即输入双目摄像头从两个方向拍摄的两帧图像数据。
33.第三类,点云,即用激光雷达采集的空间的点的数据。
34.第四类,点云和单目图像结合,即同时输入单摄像头拍摄的一帧图像数据与激光雷达采集的空间的点的数据。
35.对于移动端,双目摄像头头、激光雷达的结构较为复杂、较难移植到移动端,且成本较高,通常会使用单目图像。
36.相关技术中,基于单目图像的3d目标检测大多是基于centernet(中心网络)进行改进,直接由网络端到端地估计物体的信息,但这类方法对旋转估计比较敏感,旋转稍微有0.01误差也对物体的信息产生比较大的偏差,导致稳定性和精确度都较差。
37.为应对上述工况,本技术实施例公开了一种物体姿态的检测方法、装置、计算机设备和存储介质,提高3d目标检测的稳定性和精确度。
38.下面结合附图和实施例对本技术进行说明。
39.一个实施例
40.图1为本技术一个实施例提供的一种物体姿态的检测方法的流程图,本实施例在目标检测时,将边界框的2d(2
‑
dimension,二维)姿态映射为3d姿态,检测物体的3d姿态。本技术实施例描述的一种物体姿态的检测方法,可以由物体姿态的检测装置来执行,该物体姿态的检测装置可以由软件和/或硬件实现,可配置在作为移动端的计算机设备中,计算机设备包括,例如手机、平板电脑、智能穿戴设备,等等,智能穿戴设备包括,例如智能眼镜、智能手表等。
41.本技术实施例包括如下步骤:
42.步骤101、获取图像数据。
43.在计算机设备中,可以安装android(安卓)、ios、harmonyos(鸿蒙系统)等操作系统,用户可以在这些操作系统中安装用户所需的应用程序,例如,直播应用、短视频应用、美颜应用、会议应用,等等。
44.计算机设备可以配置有一个或多个摄像头(camera),摄像头又称相机。这些摄像头可以安装在计算机设备的正面、又称前置摄像头,也可以安装在计算机设备的背部、又称后置摄像头。
45.这些应用可以将计算机设备本地的图库、网络的图库中的图像数据作为待使用的图像数据,也可以调用摄像头采集图像数据,等等。
46.图像数据中具有作为检测目标的物体,该物体记为目标物体,该目标物体可以根据业务场景的需求而设置,例如,如图2所示的杯子201、笔记本、笔、显示屏,等等。
47.示例性地,这些应用调用摄像头面向目标物体采集视频数据,视频数据中具有多帧图像数据,通过卡尔曼滤波、光流法等方法在多帧图像数据中追踪目标物体。
48.步骤102、将图像数据输入二维检测模型中,检测三维的边界框投影至图像数据时的二维的第一姿态信息。
49.目标物体处于真实的三维空间中,可以使用三维的边界框描述目标物体在三维的空间中的姿态,其中,如图2所示,三维的边界框的形状可以包括长方体202、圆柱体、球体,等等,三维的边界框是目标物体201外接的框体,三维的边界框可用于检测目标物体201。
50.在图像数据中,目标物体表示为二维的像素点,三维的边界框也跟随目标物体以投影方式记录在图像数据中,三维的边界框以二维的像素点进行表示,此时,可以计算该三维的边界框在二维的图像数据中呈现的姿态,记为第一姿态信息。
51.在一实施例中,可以预先训练用于检测目标物体的边界框的第一姿态信息的模型,记为二维检测模型,例如,mobilenetv2、shufflenetv2,等等。
52.对于视频数据而言,可以将所有帧图像数据均输入二维检测模型进行检测,也可以每隔一定时间间隔将图像数据分别输入二维检测模型进行检测,时间间隔的预测结果可以用跟踪替代。
53.时间间隔的预测结果可以用跟踪替代,例如,为了得到每帧的结果,可以把每帧都输入模型得到结果,如此设置,每帧过模型都需要有时耗,延时较严重;也可不必每帧均过模型,比如第0帧过模型,第5帧过模型,但是每帧结果均可得到,那么第1帧的结果就可以对第0帧的结果进行跟踪得到。
54.步骤103、将第一姿态信息映射为三维的第二姿态信息。
55.例如,已知相机坐标系中的第一姿态信息,可以将求解世界坐标系中的第二姿态信息看作是pnp(perspective
‑
n
‑
point)问题,将目标物体在相机坐标系中部分的第一姿态信息通过pnp(perspective
‑
n
‑
point)、dlt(direct linear transform,直接线性变换)、epnp(efficient pnp)、upnp等位姿估计算法映射为世界坐标系中的三维的第二姿态信息。
56.在本技术的一个实施例中,第一姿态信息包括中心点、顶点、深度,可以将目标物体在图像坐标系中的顶点通过位姿估计算法映射为世界坐标系中的顶点。
57.例如,深度可指相机拍摄图片时,物体离相机的距离。
58.例如,若物体检测框是长方体,顶点可指长方体的8个顶点。
59.以epnp算法作为位姿估计算法的示例,epnp算法可以较好地处理如何从3d点
‑
2d点匹配对中求解摄像头的位姿的状况,在本实施例中,利用epnp算法把相机坐标系下的2d点(例如顶点)映射到相机坐标系中的3d点(例如顶点),利用模型预测出的中心点的深度,与epnp估出来的深度相除得到一个比例,对每一个顶点都乘以这个比例,得到真实深度的相机坐标系的3d点(例如顶点),用这个3d点(例如顶点)外乘相机的外参得到世界坐标系下的3d点(例如顶点)。
60.步骤104、根据第二姿态信息检测目标物体的第三姿态信息。
61.若确定边界框在世界坐标系下的第二姿态信息,则可以检测位于边界框内的目标物体在世界坐标系下的姿态,记为三维的第三姿态信息。
62.此外,边界框在世界坐标系下的第二姿态信息包括多个顶点,可以根据多个顶点计算目标物体在世界坐标系下的位置和方向,作为第三姿态信息。
63.第一姿态信息为二维的姿态信息,对应于边界框,处于图像坐标系下。
64.第二姿态信息为三维的姿态信息,对应于边界框,处于相机坐标系下。
65.第三姿态信息为三维的姿态信息,对应于目标物体,处于世界坐标系下。
66.本实施例中,通过将3d边界框映射到2d图像上,通过2d图像的边界框反映射回3d物体的边界框。
67.本实施例中,获取图像数据,图像数据中具有目标物体,将图像数据输入二维检测模型中,检测三维的边界框投影至所述图像数据时的二维的第一姿态信息,边界框用于检测目标物体,将第一姿态信息映射为三维的第二姿态信息,根据第二姿态信息检测目标物体的第三姿态信息,通过预测边界框在图像数据上的投影映射,从投影映射还原回3d的姿态信息,避免预测旋转角的细微误差带来的抖动,本实施例比直接预测3d的姿态信息精确度更高,效果更稳定。
68.在本技术的一个示例性实施例中,二维检测模型为一个独立、完整的网络,即一阶段网络,如图3所示,二维检测模型包括编码器310、解码器320、预测网络330,在本示例性实施例中,如图8,步骤102可以包括如下步骤1021、步骤1022和步骤1023。
69.步骤1021、在编码器中对图像数据进行编码,获得第一图像特征。
70.例如,编码器可以将整个源数据(即图像数据)读取为固定长度的编码(即第一图像特征)。
71.示例性地,如图3所示,编码器310包括卷积层(conv layer)311、第一残差网络312、第二残差网络313、第三残差网络314、第四残差网络315、第五残差网络316,其中,第一残差网络312、第二残差网络313、第三残差网络314、第四残差网络315与第五残差网络316均包括一个或多个瓶颈残差块(bottleneck residual block),瓶颈残差块的输出通道数为输入通道数的n倍,n为正整数,如4。
72.在本示例中,在卷积层311中对图像数据进行卷积处理,获得第一层级特征;在第一残差网络312中对第一层级特征进行处理,获得第二层级特征;在第二残差网络313中对第二层级特征进行处理,获得第三层级特征;在第三残差网络314中对第三层级特征进行处理,获得第四层级特征;在第四残差网络315中对第四层级特征进行处理,获得第五层级特征;在第五残差网络316中对第五层级特征进行处理,获得第六层级特征。
73.其中,在第一残差网络312、第二残差网络313、第三残差网络314、第四残差网络315与第五残差网络316中,本层瓶颈残差块的输出为下一层瓶颈残差块的输入。
74.在本示例中,第一层级特征、第二层级特征、第三层级特征、第四层级特征、第五层级特征、第六层级特征均为第一图像特征。
75.在一实施例中,如图3所示,第一残差网络312中瓶颈残差块的数量小于第二残差网络313中瓶颈残差块的数量,例如,第一残差网络312中1层瓶颈残差块,第二残差网络313中2层瓶颈残差块;第二残差网络313中瓶颈残差块的数量小于第三残差网络314中瓶颈残差块的数量,第三残差网络314中瓶颈残差块的数量小于第四残差网络315中瓶颈残差块的数量,第四残差网络315中瓶颈残差块的数量等于第五残差网络316中瓶颈残差块的数量。例如,第二残差网络313中2层瓶颈残差块,第三残差网络314中3层瓶颈残差块,第四残差网络315中4层瓶颈残差块,第五残差网络316中4层瓶颈残差块。
76.此外,第二层级特征的维度高于第三层级特征的维度,第三层级特征的维度高于第四层级特征的维度,第四层级特征的维度高于第五层级特征的维度,第五层级特征的维度高于第六层级特征的维度。例如,第二层级特征的维度为320
×
240
×
16,第三层级特征的维度为160
×
120
×
24,第四层级特征的维度为80
×
60
×
32,第五层级特征的维度为40
×
30
×
64,第六层级特征的维度为20
×
15
×
128。
77.图像数据经过多次下采样后的低分辨率信息,能够提供目标物体在整个图像数据中上下文的语义信息,该语义信息可反应目标物体和目标物体的环境之间关系的特征,第一图像特征有助于目标物体的检测。
78.步骤1022、在解码器中对第一图像特征进行解码,获得第二图像特征。
79.例如,解码器可以将编码(即第一图像特征)进行解码,以输出目标数据(即第二图像特征)。
80.示例性地,如图3所示,解码器320包括转置卷积层(transposed convolution layer)321、第六残差网络322,其中,第六残差网络322包括多个瓶颈残差块,例如,第六残差网络322包括2层瓶颈残差块。
81.如果第一图像特征包括多种特征,如第一层级特征、第二层级特征、第三层级特征、第四层级特征、第五层级特征、第六层级特征等,则可以选取至少一种特征进行上采样,将高层的语义信息与低层的语义信息相结合,提高语音信息的丰富度,增加二维检测模型的稳定性和精确度,减少了漏检误检的情况。
82.在本示例中,如图3所示,在转置卷积层321中对第六层级特征数据进行卷积处理,获得第七层级特征;将上采样得到的第五层级特征与第七层级特征拼接为第八层级特征,实现高层的语义信息与低层的语义信息相结合;在第六残差网络322中对第八层级特征进行处理,获得第二图像特征。
83.其中,在第六残差网络322中,本层瓶颈残差块的输出为下一层瓶颈残差块的输入。
84.在一实施例中,第二图像特征的维度高于第六层级特征的维度,例如,第二图像特征的维度为40
×
30
×
64,第六层级特征的维度为20
×
15
×
128。
85.步骤1023、在预测网络中将第二图像特征映射为边界框的二维的第一姿态信息。
86.第一姿态信息为与边界框对应的二维姿态信息。
87.一般情况下,二维检测模型具有多个预测网络,预测网络属于分支网络,专注于第一姿态信息中的某个数据,可以实现为较小的结构。
88.示例性地,如图3所示,预测网络330包括第一预测网络331、第二预测网络332、第三预测网络333、第四预测网络334,其中,第一预测网络331包括多个瓶颈残差块、如2层瓶颈残差块,第二预测网络332包括多个瓶颈残差块、如2层瓶颈残差块,第三预测网络333包括多个瓶颈残差块、如2层瓶颈残差块,第四预测网络334包括多个瓶颈残差块、如2层瓶颈残差块。
89.在本示例中,第一姿态信息包括中心点、深度、尺寸、顶点,分别将第二图像特征输入第一预测网络331、第二预测网络332、第三预测网络33、第四预测网络334中。
90.例如,尺寸可指真实物体的长宽高。
91.在第一预测网络331中对第二图像特征进行处理,获得边界框的高斯分布图(center heatmap),在高斯分布图中查找中心点,该中心点具有深度。
92.在第二预测网络332中对第二图像特征进行处理,获得边界框的深度(depth)。
93.在第三预测网络333中对第二图像特征进行处理,获得边界框的尺寸(scale)。
94.在第四预测网络334中对第二图像特征进行处理,获得边界框中的顶点相对于中心点偏移的距离(vertexes),在中心点的坐标的基础加上该偏移的距离,可以得到多个顶点的坐标。
95.其中,针对不同形状的边界框,顶点的数量及顶点在边界框的相对位置也有所不同,例如,若边界框为长方体,则边界框具有8个顶点,这些顶点为每一个面的角点,若边界框为圆柱体,则边界框具有8个顶点,这些顶点为底面和顶面的外接圆的交接点,等等。
96.在本实施例中,二维检测模型的层级数少、结构简单,使用的计算资源少,计算的耗时低,可以保证实时性。
97.在本技术的另一个示例性实施例中,二维检测模型包括两个相互独立的模型,即二阶段网络,如图4所示,二维检测模型包括目标检测模型410与编码模型420,目标检测模型410与编码模型420级联,即目标检测模型410的输出为编码模型420的输入,二阶段网络的结构更加复杂,可以避免在小模型上预测结果会聚到一堆的情况,使得二维检测模型更加稳定。
98.在本示例性实施例中,如图9所示,步骤102可以包括如下步骤1021'、步骤1022'和步骤1023'。
99.步骤1021'、在目标检测模型中,检测图像数据中边界框的部分的二维的第一姿态信息、目标物体在图像数据中所处的区域。
100.目标检测模型可以包括one
‑
stage(一阶段)和two
‑
stage(二阶段),one
‑
stage可以包括ssd(single shot multibox detector)、yolo(you only look once)等等,two
‑
stage包括r
‑
cnn(region with cnn features)系列,r
‑
cnn系列例如r
‑
cnn、fast
‑
rcnn、faster
‑
rcnn等等。
101.将图像数据输入目标检测模型中,目标检测模型可以检测图像数据中边界框的部分的二维的第一姿态信息、以及、目标物体在图像数据中所处的区域。
102.在一实施例中,在目标检测模型中,可以检测图像数据中边界框的深度、尺寸,作为第一姿态信息。
103.以yolov5作为目标检测模型的示例,yolov5分为三部分:骨干网络,特征金字塔网络,分支网络。骨干网络是指在不同细粒度上聚合并形成图像特征的卷积神经网络;特征金字塔网络是指一系列混合和组合图像特征的网络层,后续将图像特征传递到预测层,预测层一般是fpn(feature pyramid networks,特征金字塔网络)或者panet(path aggregation network,路径聚合网络);分支网络是指对图像特征进行预测,生成边界框和并预测目标物体的类别、目标物体的深度和尺寸。因此,yolov5的输出为nc 5 3 1。
104.其中,nc为物体的类别数。
105.其中,数字5表征存在5个变量,包括分类置信度(c)、边界框的中心点(x,y)、边界框的宽和高(w,h)一共5个变量。
106.其中,数字3表征存在3个变量,包括目标物体在3维空间中的尺寸(长宽高)。
107.其中,数字1表征存在1个变量,即目标物体在相机坐标系中的深度,即拍摄时物体离相机的距离。
108.步骤1022'、在图像数据中提取区域中的数据,作为区域数据。
109.如图4所示,目标物体在图像数据430中所处的区域属于二维的边界框,基于该区域对图像数据进行裁剪,取出该区域中的数据(像素点),实现图像数据的缩放,记为区域数据431。
110.步骤1023'、在编码模型中对区域数据进行编码,获得边界框的部分的二维的第一姿态信息。
111.如图4所示,将区域数据431输入编码模型420中进行编码,可以输出边界框剩余的二维的第一姿态信息。
112.在一实施例中,在编码模型中对区域数据进行编码,获得边界框的中心点和顶点,作为第一姿态信息。
113.可将,目标检测模块检测出的一部分的第一姿态信息、与编码模块生成的另一部分的第一姿态信息的合集,认定为二维检测模型检测出的第一姿态信息。
114.考虑到移动端的计算资源较少,编码模型通常选用结构简单、计算量少的模型,以efficientnet
‑
lite0作为编码模型的示例,efficientnet
‑
lite0包括多个1
×
1的卷积层,多个深度可分离卷积层,多个残差连接层以及多个全连接层,最后一层全连接层预估目标物体的中心点和顶点。
115.除了efficientnet
‑
lite0之外,还可以采用参数更少或者表达能力更强的轻量级网络结构作为编码模型。
116.在本实施例中,可以根据业务场景的需求选择合适的二维检测模型,如果针对用户上传视频数据的情况,一阶段网络的速度更快,二阶段网络的精度更高,如果针对用户实时拍摄的情况,二阶段网络可以增加2d检测器的跟踪(跟踪例如为,根据第一帧的位置信息,捕捉接下来帧的可能位置信息),可以不用每帧图像数据都检测,使得速度精度都更快更高。
117.在本技术的另一个示例性实施例中,如图10所示,步骤103可以包括如下步骤1031
‑
步骤1034。
118.步骤1031、分别在世界坐标系与相机坐标系下,查询控制点。
119.epnp算法引入了控制点,任何一个参考点可以表示为四个控制点的线性组合,任
何一个参考点例如顶点、中心点。
120.一般情况下,控制点可以随便选择,而本实施例可以预先通过实验选择效果较佳的点作为控制点,并记录控制点的坐标,在使用时将控制点作为超参数加载。
121.步骤1032、分别在世界坐标系与相机坐标系下,将中心点与顶点表示为控制点的加权和。
122.设上标w为世界坐标系、上标c为相机坐标系,为第i个参考点(顶点、中心点)在世界坐标系下的坐标,为第i个参考点(顶点、中心点)在投影至相机坐标系下的坐标,点、中心点)在投影至相机坐标系下的坐标,为四个控制点在世界坐标系下的坐标,为四个控制点投影至相机坐标系下的坐标。
123.对于世界坐标系中的参考点可用四个控制点表示:
[0124][0125]
其中,a
ij
为配置给控制点的齐次重心坐标(homogeneous barycentric coordinates),又称权重,属于超参数。
[0126]
对于相机坐标系中的参考点可用四个控制点表示:
[0127][0128]
其中,a
ij
为配置给控制点的齐次重心坐标,又称权重。
[0129]
对于同一参考点,在世界坐标系下的权重与在相机坐标系下的权重相同,属于超参数。
[0130]
步骤1033、构建深度、中心点与顶点在世界坐标系与相机坐标系之间的约束关系。
[0131]
其中,此处提及的约束关系可为,世界坐标系下的深度、中心点与顶点,与相机坐标系下的深度、中心点与顶点之间的约束关系。
[0132]
例如,根据投影方程,得到世界坐标系中参考点坐标(例如顶点、中心点)和相机坐标系中参考点(例如顶点、中心点)的约束关系。
[0133]
投影方程,如下:
[0134][0135]
其中,w
i
为参考点(顶点、中心点)的深度,u
i
、v
i
为参考点(顶点、中心点)在相机坐标系中的x坐标、y坐标,a为超参数,f
u
、f
v
、u
c
、u
v
为相机的内参,为参考点(顶点、中心点)在世界坐标系中的x坐标、y坐标、z坐标,共12个未知变量,带入求解。
[0136]
将控制点的权重a
ij
和为1带入约束关系,每个参考点(顶点、中心点)的约束关系可
以转换为:
[0137][0138][0139]
步骤1034、串联约束关系,获得线性方程。
[0140]
例如,每个参考点存在两个约束关系,串联约束关系可表征为将9个参考点的约束关系组成一个矩阵,按行串联。
[0141]
步骤1035、对线性方程进行求解,以将顶点映射至三维空间。
[0142]
当有n个参考点(顶点、中心点)的时候,n为正整数,如9,串联n个参考点的约束关系,可以得到如下的齐次的线性方程:
[0143]
mx=0
[0144]
其中,x表示的是控制点在相机坐标系下的坐标(x,y,z),是一个12维的向量,四个控制点总共12个未知变量,m为2n
×
12的矩阵。
[0145]
因此,x属于m的右零空间,v
i
为矩阵m的右奇异向量,v
i
对应的奇异值为0,可以通过求解m
t
m的零空间特征值得到:
[0146][0147]
解算方法为,求解m
t
m的特征值和特征向量,特征值为0的特征向量即为v
i
。其中,不论有多少个参考点,m
t
m的大小均是12
×
12。而计算m
t
m的复杂度为o(n),因此,算法的整体复杂度为o(n)。
[0148]
n与参考点的数量、控制点、相机焦距和噪声有关,β
i
是一个线性组合可通过在设定n的数量时直接优化求解或者采用近似的解法求解,得到确定的解。
[0149]
在本技术的另一个示例性实施例中,可以对第二姿态信息进行奇异值求解得到第三姿态信息。在本示例性实施例中,如图11所示,步骤104可以包括如下步骤1041
‑
1047。
[0150]
步骤1041、分别在世界坐标系与相机坐标系下,基于顶点计算新的中心点。
[0151]
对于长方体、圆柱体等形状的边界框,一般是以中心点建立坐标系的,那么,中心点就是边界框的原点。
[0152]
示例性地,在相机坐标系下计算顶点的平均值,作为新的中心点,记为:
[0153][0154]
其中,为相机坐标系下新的中心点,为相机坐标系下的顶点,n为顶点的数量,i为整数。
[0155]
在世界坐标系下计算顶点的平均值,作为新的中心点,记为
[0156][0157]
其中,为世界坐标系下新的中心点,为世界坐标系下的顶点,n为顶点的数量。
[0158]
步骤1042、分别在世界坐标系与相机坐标系下,对顶点去除新的中心点。
[0159]
在相机坐标系下对多个顶点分别减去新的中心点,实现去中心,即去除新的中心点,可记为:
[0160][0161]
其中,为相机坐标系下去中心之后的顶点,为相机坐标系下的顶点,为相机坐标系下新的中心点。
[0162]
在世界坐标系下将多个顶点分别减去新的中心点,实现去中心,即去除新的中心点,记为:
[0163][0164]
其中,为世界坐标系下去中心之后的顶点,为世界坐标系下的顶点,为世界坐标系下新的中心点。
[0165]
步骤1043、对顶点去除新的中心点之后,计算自共轭矩阵。
[0166]
在去中心完成后,可计算自共轭矩阵h,其中,自共轭矩阵h为相机坐标系下的顶点与世界坐标系下的顶点的转置矩阵之间的乘积,表示如下:
[0167][0168]
其中,n为顶点的数量,相机坐标系下去中心之后的顶点,为世界坐标系下去中心之后的顶点,t为转置矩阵。
[0169]
步骤1044、对自共轭矩阵进行奇异值分解,得到第一正交矩阵、对角阵、第二正交矩阵的转置矩阵之间的乘积。
[0170]
在本实施例中,有两个坐标系下的坐标都是已知的,即世界坐标系下顶点的坐标和相机坐标系下顶点的坐标,利用svd(singular value decomposition,奇异值分解)的思路可以求得两个坐标系的位姿变换,即,对自共轭矩阵h进行svd,可表示为:
[0171]
h=uλv
t
[0172]
其中,u为第一正交矩阵,λ为对角阵,v为第二正交矩阵,t为转置矩阵。
[0173]
步骤1045、计算第二正交矩阵与第一正交矩阵的转置矩阵之间的乘积,作为目标物体在世界坐标系下的方向。
[0174]
计算x=vu
t
,其中,u为第一正交矩阵,v为第二正交矩阵,t为转置矩阵。
[0175]
在部分情况下,r=x,r即为目标物体在世界坐标系下的方向。
[0176]
步骤1046、将世界坐标系下新的中心点按照方向旋转,获得投影点。
[0177]
步骤1047、将相机坐标系下新的中心点减去投影点,获得目标物体在世界坐标系
下的位置。
[0178]
将相机坐标系下新的中心点减去按照该方向旋转之后的世界坐标系下新的中心点,可以得到目标物体在世界坐标系下的位置,表达如下:
[0179][0180]
其中,t为目标物体在世界坐标系下的位置,为相机坐标系下新的中心点,r为目标物体在世界坐标系下的方向,为世界坐标系下新的中心点。
[0181]
另一实施例
[0182]
图5为本技术另一实施例提供的一种物体姿态的检测方法的流程图,本实施例以前述实施例为基础,增加特效处理的操作,该方法包括如下步骤:
[0183]
步骤501、获取图像数据。
[0184]
其中,图像数据中具有目标物体。
[0185]
步骤502、将图像数据输入二维检测模型中,检测三维的边界框投影至图像数据时的二维的第一姿态信息。
[0186]
其中,边界框用于检测目标物体。
[0187]
步骤503、将第一姿态信息映射为三维的第二姿态信息。
[0188]
步骤504、根据第二姿态信息检测目标物体的第三姿态信息。
[0189]
步骤505、确定与目标物体适配的、三维的素材。
[0190]
在本实施例中,服务端例如服务器可以根据业务场景的需求,预先收集与目标物体的类型适配的、三维的素材。移动端可以预先按照一定的规则(如选取基础素材、热度高的素材等)从服务端下载这些素材到本地,也可以在使用时,根据用户触发的操作,从服务端下载指定的素材到本地;或者,用户可以在移动端本地选择与目标物体适配的、三维的素材,或者,从目标物体对应的数据中提取部分数据、并对部分数据进行三维转换,作为素材,等等。
[0191]
例如,该素材可以为文本数据、图像数据、动画数据,等等。
[0192]
例如,如图2所示,如果目标物体201为某个品牌的饮料,则可以将该品牌的logo(标识)203作为素材。
[0193]
又如,如果目标物体为球类(如足球、篮球、排球、羽毛球、乒乓球等),则可以为将与球类适配的特效动画(如羽毛、闪电、火焰等)作为素材。
[0194]
再如,如果目标物体为盛放水的容器,则可以为将水生动植物(如水草、鱼、虾等)作为素材。
[0195]
步骤506、为所述素材配置第四姿态信息。
[0196]
其中,第四姿态信息适配于第一姿态信息和/或第三姿态信息。
[0197]
步骤507、在图像数据中按照第四姿态信息显示素材。
[0198]
在本实施例中,可以预设设置特效生成器,可以将第一姿态信息和/或第三姿态信息输入到特效生成器中,为该素材生成第四姿态信息,在图像数据中按照该第四姿态信息渲染素材,使得素材符合目标物体的情况,生成更加自然的特效。
[0199]
示例性地,一部分的第一姿态信息包括边界框的尺寸,第三姿态信息包括目标物体的方向、位置。
[0200]
在本示例中,可以将目标物体的位置往外偏移指定的距离,例如,以目标物体的正面为参考面偏移10厘米,将偏移后的位置作为素材的位置。
[0201]
第四姿态信息可包括素材的位置。
[0202]
将边界框的尺寸缩小至指定的比例(如10%),将缩小后的尺寸作为素材的尺寸。
[0203]
第四姿态信息可包括素材的尺寸。
[0204]
将目标物体的方向配置为素材的方向,使得素材与目标物体的朝向相同。
[0205]
第四姿态信息可包括素材的方向。
[0206]
上述第四姿态信息只是作为示例,在实施本技术实施例时,可以根据实际情况设置其它第四姿态信息,例如,将边界框的尺寸放大至指定的比例(如1.5倍),将放大后的尺寸作为素材的尺寸,将目标物体的方向旋转指定角度(如90
°
),将旋转后的方向作为素材的方向,等等。另外,除了上述第四姿态信息外,本领域技术人员还可以根据实际需要采用其它第四姿态信息。
[0207]
对于视频数据而言,用户在适配数据中添加特效完毕后,则可以发布该适配数据,如短视频、直播数据,等等。
[0208]
对于方法实施例,为了简单描述,故将实施例表述为一系列的动作组合,但是本领域技术人员应该知悉,动作顺序存在多种,因为依据本技术实施例,一部分步骤可以采用其他顺序或者同时进行。
[0209]
另一实施例
[0210]
图6为本技术另一实施例提供的一种物体姿态的检测装置的结构框图,物体姿态的检测装置可以包括如下模块:
[0211]
图像数据获取模块601,设置为获取图像数据,所述图像数据中具有目标物体;
[0212]
第一姿态信息检测模块602,设置为将所述图像数据输入二维检测模型中,检测三维的边界框投影至所述图像数据时的二维的第一姿态信息,所述边界框用于检测所述目标物体;
[0213]
第二姿态信息映射模块603,设置为将所述第一姿态信息映射为三维的第二姿态信息;
[0214]
第三姿态信息检测模块604,设置为根据所述第二姿态信息检测所述目标物体的第三姿态信息。
[0215]
在本技术的一个实施例中,所述二维检测模型包括编码器、解码器、预测网络;
[0216]
所述第一姿态信息检测模块602包括:
[0217]
编码模块,设置为在所述编码器中对所述图像数据进行编码,获得第一图像特征;
[0218]
解码模块,设置为在所述解码器中对所述第一图像特征进行解码,获得第二图像特征;
[0219]
映射模块,设置为在所述预测网络中将所述第二图像特征映射为边界框的二维的第一姿态信息。
[0220]
在本技术的一个实施例中,所述编码器包括卷积层、第一残差网络、第二残差网络、第三残差网络、第四残差网络、第五残差网络,所述第一残差网络、所述第二残差网络、所述第三残差网络、所述第四残差网络与所述第五残差网络分别包括至少一个瓶颈残差块;
[0221]
所述编码模块还设置为:
[0222]
在所述卷积层中对所述图像数据进行卷积处理,获得第一层级特征;
[0223]
在所述第一残差网络中对所述第一层级特征进行处理,获得第二层级特征;
[0224]
在所述第二残差网络中对所述第二层级特征进行处理,获得第三层级特征;
[0225]
在所述第三残差网络中对所述第三层级特征进行处理,获得第四层级特征;
[0226]
在所述第四残差网络中对所述第四层级特征进行处理,获得第五层级特征;
[0227]
在所述第五残差网络中对所述第五层级特征进行处理,获得第六层级特征。
[0228]
在本技术的一个实施例中,所述第一残差网络中所述瓶颈残差块的数量小于所述第二残差网络中所述瓶颈残差块的数量,所述第二残差网络中所述瓶颈残差块的数量小于所述第三残差网络中所述瓶颈残差块的数量,所述第三残差网络中所述瓶颈残差块的数量小于所述第四残差网络中所述瓶颈残差块的数量,所述第四残差网络中所述瓶颈残差块的数量等于所述第五残差网络中所述瓶颈残差块的数量;
[0229]
所述第二层级特征的维度高于所述第三层级特征的维度,所述第三层级特征的维度高于所述第四层级特征的维度,所述第四层级特征的维度高于所述第五层级特征的维度,所述第五层级特征的维度高于所述第六层级特征的维度。
[0230]
在本技术的一个实施例中,所述解码器包括转置卷积层、第六残差网络,所述第六残差网络包括多个瓶颈残差块;
[0231]
所述解码模块还设置为:
[0232]
在所述转置卷积层中对所述第六层级特征数据进行卷积处理,获得第七层级特征;
[0233]
将所述第五层级特征与所述第七层级特征拼接为第八层级特征;
[0234]
在所述第六残差网络中对所述第八层级特征进行处理,获得第二图像特征。
[0235]
在本技术的一个实施例中,所述第二图像特征的维度高于所述第六层级特征的维度。
[0236]
在本技术的一个实施例中,所述预测网络包括第一预测网络、第二预测网络、第三预测网络、第四预测网络,所述第一预测网络、所述第二预测网络、所述第三预测网络与所述第四预测网络分别包括多个瓶颈残差块;
[0237]
所述映射模块还设置为:
[0238]
在所述第一预测网络中对所述第二图像特征进行处理,获得边界框的中心点;
[0239]
在所述第二预测网络中对所述第二图像特征进行处理,获得边界框的深度;
[0240]
在所述第三预测网络中对所述第二图像特征进行处理,获得边界框的尺寸;
[0241]
在所述第四预测网络中对所述第二图像特征进行处理,获得边界框中的顶点相对于所述中心点偏移的距离。
[0242]
在本技术的另一个实施例中,所述二维检测模型包括目标检测模型与编码模型,目标检测模型与编码模型级联;
[0243]
所述第一姿态信息检测模块602:
[0244]
目标检测模块,设置为在所述目标检测模型中,检测所述图像数据中边界框的部分的二维的第一姿态信息、所述目标物体在所述图像数据中所处的区域;
[0245]
区域数据提取模块,设置为在所述图像数据中提取所述区域中的数据,作为区域
数据;
[0246]
区域数据编码模块,设置为在所述编码模型中,对所述区域数据进行编码,获得所述边界框的部分的二维的第一姿态信息。
[0247]
在本技术的一个实施例中,所述目标检测模块还设置为:
[0248]
在所述目标检测模型中,检测所述图像数据中边界框的深度、尺寸;
[0249]
所述区域数据编码模块还设置为:
[0250]
在所述编码模型中,对所述区域数据进行编码,获得所述边界框的中心点和顶点。
[0251]
在本技术的一个实施例中,所述第一姿态信息包括中心点、顶点、深度;
[0252]
所述第二姿态信息映射模块603包括:
[0253]
控制点查询模块,设置为分别在世界坐标系与相机坐标系下,查询控制点;
[0254]
点表示模块,设置为分别在世界坐标系与相机坐标系下,将所述中心点与所述顶点表示为所述控制点的加权和;
[0255]
约束关系构建模块,设置为构建所述深度、所述中心点与所述顶点在所述世界坐标系与所述相机坐标系之间的约束关系;
[0256]
线性方程生成模块,设置为串联所述约束关系,获得线性方程;
[0257]
线性方程求解模块,设置为对所述线性方程进行求解,以将所述顶点映射至三维空间。
[0258]
在本技术的一个实施例中,所述第三姿态信息检测模块604,包括:
[0259]
中心点计算模块,设置为分别在世界坐标系与相机坐标系下,基于顶点计算新的中心点;
[0260]
中心点去除模块,设置为分别在世界坐标系与相机坐标系下,对所述顶点去除所述新的中心点;
[0261]
自共轭矩阵计算模块,设置为计算自共轭矩阵,所述自共轭矩阵为所述相机坐标系下的顶点与所述世界坐标系下的顶点的转置矩阵之间的乘积;
[0262]
奇异值分解模块,设置为对所述自共轭矩阵进行奇异值分解,得到第一正交矩阵、对角阵、第二正交矩阵的转置矩阵之间的乘积;
[0263]
方向计算模块,设置为计算所述第二正交矩阵与所述第一正交矩阵的转置矩阵之间的乘积,作为所述目标物体在世界坐标系下的方向;
[0264]
投影点计算模块,设置为将所述世界坐标系下的所述新的中心点按照所述方向旋转,获得投影点;
[0265]
位置计算模块,设置为将所述相机坐标系下的所述新的中心点减去所述投影点,获得所述目标物体在世界坐标系下的位置。
[0266]
在本技术的一个实施例中,还包括:
[0267]
素材确定模块,设置为确定与所述目标物体适配的、三维的素材;
[0268]
第四姿态信息配置模块,设置为为所述素材配置第四姿态信息,所述第四姿态信息为适配于所述第一姿态信息和所述第三姿态信息的姿态信息;
[0269]
素材显示模块,设置为在所述图像数据中按照所述第四姿态信息显示所述素材。
[0270]
在本技术的一个实施例中,所述第一姿态信息包括所述边界框的尺寸,所述第三姿态信息包括所述目标物体的方向、位置;
[0271]
所述第四姿态信息配置模块:
[0272]
位置偏移模块,设置为将所述目标物体的位置偏移指定的距离,将偏移后的位置作为所述素材的位置;
[0273]
尺寸缩小模块,设置为将所述边界框的尺寸缩小至指定的比例,将缩小后的尺寸作为所述素材的尺寸;
[0274]
方向配置模块,设置为将所述目标物体的方向配置为所述素材的方向。
[0275]
本技术实施例所提供的物体姿态的检测装置可执行本技术任意实施例所提供的物体姿态的检测方法,具备执行方法相应的功能模块和有益效果。
[0276]
另一实施例
[0277]
图7为本技术另一实施例提供的一种计算机设备的结构示意图。图7示出了适于用来实现本技术实施方式的示例性计算机设备12的框图。图7显示的计算机设备12仅仅是一个示例。
[0278]
如图7所示,计算机设备12以通用计算设备的形式表现。计算机设备12的组件可以包括:一个或者多个处理器或者处理单元16,系统存储器28,连接不同系统组件的总线18,不同系统组件包括系统存储器28和处理单元16。
[0279]
系统存储器28也可记为内存。
[0280]
总线18表示多类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括工业标准体系结构(industry standard architecture,isa)总线,微通道体系结构(micro channel architecture,mca)总线,增强型isa总线、视频电子标准协会(video electronics standards association,vesa)局域总线以及外围组件互连(peripheral component interconnect,pci)总线。
[0281]
计算机设备12典型地包括多种计算机系统可读介质。这些介质可以是任何能够被计算机设备12访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
[0282]
系统存储器28可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(random access memory,ram)30和/或高速缓存32。计算机设备12可以包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统34可以设置为读写不可移动的、非易失性磁介质(图7未显示)。尽管图7中未示出,可以提供用于对可移动非易失性磁盘(例如软盘)读写的磁盘驱动器,以及对可移动非易失性光盘(例如cd
‑
rom,dvd
‑
rom或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线18相连。系统存储器28可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本技术多实施例的功能。
[0283]
具有一组(至少一个)程序模块42的程序/实用工具40,可以存储在例如系统存储器28中,这样的程序模块42包括操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块42通常执行本技术所描述的实施例中的功能和/或方法。
[0284]
计算机设备12也可以与一个或多个外部设备14(例如键盘、指向设备、显示器24等)通信,还可与一个或者多个使得用户能与该计算机设备12交互的设备通信,和/或与使
得该计算机设备12能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口22进行。并且,计算机设备12还可以通过网络适配器20与一个或者多个网络通信,一个或者多个网络例如局域网(local area network,lan),广域网(wide area network,wan)和/或公共网络,公共网络例如因特网。如图7所示,网络适配器20通过总线18与计算机设备12的其它模块通信。还可以结合计算机设备12使用其它硬件和/或软件模块,其它硬件和/或软件模块包括:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、磁盘阵列(redundant arrays of independent disks,raid)系统、磁带驱动器以及数据备份存储系统等。
[0285]
处理单元16通过运行存储在系统存储器28中的程序,执行多种功能应用以及数据处理,例如实现本技术实施例所提供的物体姿态的检测方法。
[0286]
另一实施例
[0287]
本技术另一实施例还提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,该计算机程序被处理器执行时实现上述物体姿态的检测方法的多个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
[0288]
其中,计算机可读存储介质例如可以包括电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质例如为,具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(read
‑
only memory,rom)、可擦式可编程只读存储器(erasable programmable read
‑
only memory,eprom)、闪存、光纤、便携式紧凑磁盘只读存储器(cd
‑
rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者结合使用。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。